blog
How to Migrate MySQL from Amazon EC2 to your On-Prem Data Center Without Downtime

Since its inception, there have been an increasing number of migrations to a cloud-based environment. After all, cloud computing can provide many benefits for businesses, especially those working with big data.
However, as the demand grows, so do the costs, and you might find yourself in a situation where monthly cloud expenses become too high, and the negatives soon outweigh the benefits of operating in the cloud. Or perhaps you have security or compliance requirements calling for you to have more direct control of your systems. This may ultimately make a case for you to migrate back to an on-prem environment.
AWS does provide monitoring and management tools to run our system in the cloud while having visibility and control for optimization. However, when we find ourselves ready for an on-prem solution, it can be challenging to migrate our data and recreate all the tools to manage our systems properly.
In this blog, we will discuss how you can migrate your systems from AWS to an on-premises datacenter and how ClusterControl can help streamline the process.
Concepts
Before we jump in, let’s cover some basic concepts about Amazon Cloud and ClusterControl.
AWS
Amazon Web Services (AWS) is an Infrastructure as a Service platform comprised of a large number of independent and semi-independent services. The purpose of the Infrastructure as a Service platform is to offer, on a commodity basis, services that previously required the purchase of capital-intensive infrastructure components such as high-end servers, network routers, and switches, and for larger enterprises, even their own datacenters.
RDS
Amazon Relational Database Service (RDS) makes it easy to set up, operate, and scale a relational database in the cloud. It provides cost-efficient and resizable capacity while automating time-consuming administration tasks such as hardware provisioning, database setup, patching, and backups.
Amazon RDS is available on several database instance types and provides you with six familiar database management systems to choose from, including Amazon Aurora, PostgreSQL, MySQL, MariaDB, Oracle Database, and SQL Server.
EC2
Amazon Elastic Compute Cloud (EC2) is a service that provides secure and resizable compute capacity in the cloud. It is designed to make web-scale cloud computing easier for developers.
Amazon EC2’s simple web interface lets you obtain and configure capacity with minimal friction. It provides you with complete control of your computing resources and lets you run on Amazon’s proven computing environment.
ClusterControl
ClusterControl is a comprehensive management system for open source databases that automates deployment, management functions, and health and performance monitoring from a single pane of glass.
ClusterControl supports the deployment, management, monitoring, and scaling for different database technologies in any environment.
Why Migrate to On-Prem?
As we previously mentioned, the most common reasons for migrating from AWS to an on-premise environment are costs, security, compliance, or running local applications. In AWS, you don’t know what’s happening under the hood of the infrastructure. You only know whether everything is working. If you experience poor performance or anomalies, the only solution is to get in contact with Amazon support.
Example Migration Scenario
In AWS, you have two different products related to this blog: EC2 and RDS.
The main difference between them is that in EC2, you have SSH access to the server and must manage the database yourself. RDS is a hosted database service, and you only have access to the database instance.
In RDS, as you don’t have SSH access, you need to create a dump and import it into the new server, or configure replication and promote the replica to the new primary. For both options, the process is manual. You could also add a load balancer to improve this process. We covered this task in these blogs: Part 1 and Part 2.
So, let’s focus on the migration from EC2.
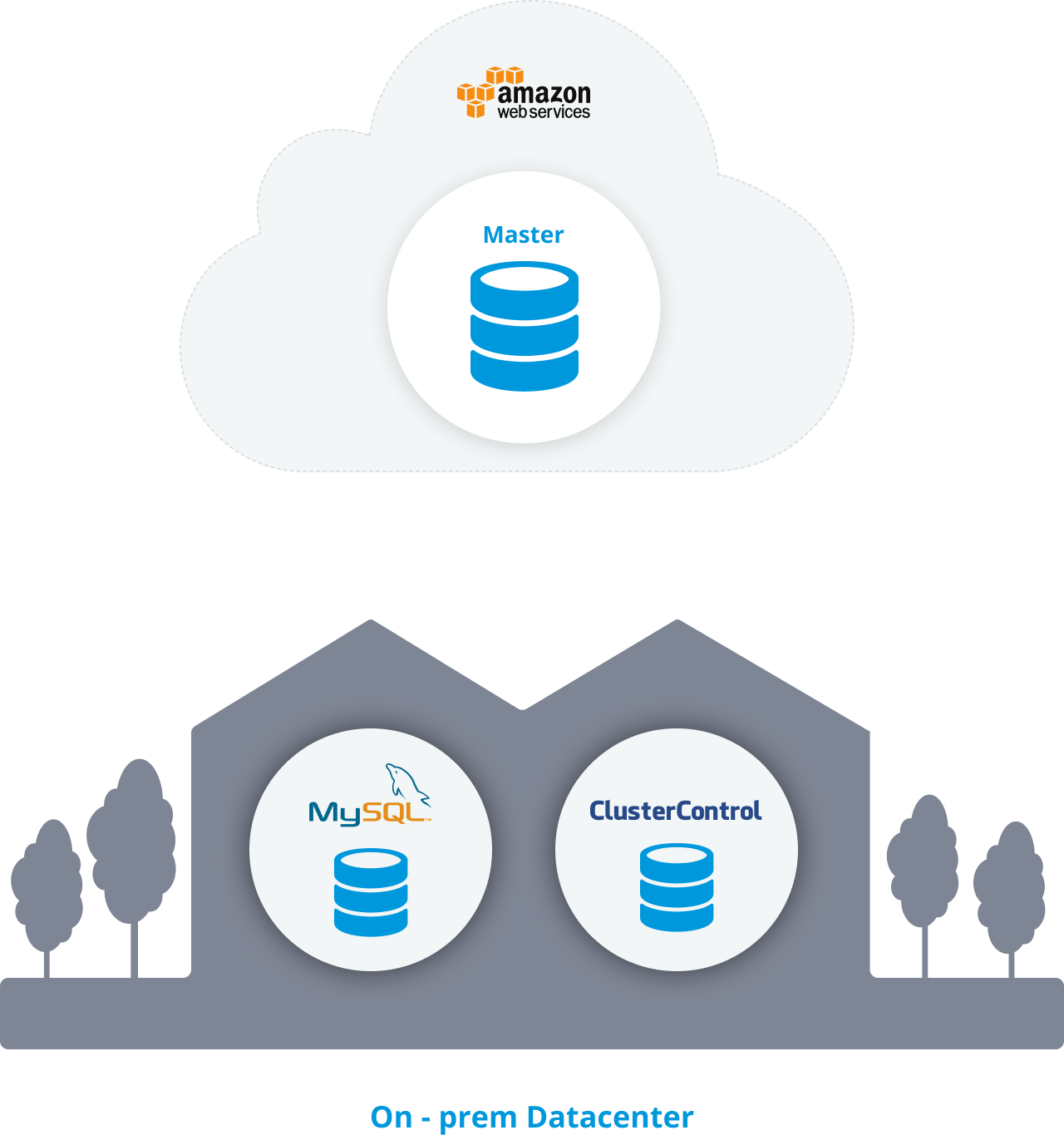
In our example, let’s see how to migrate MySQL from AWS EC2 to an on-prem data center. We will use a MySQL Replication environment, but these steps should work for other technologies like PostgreSQL.
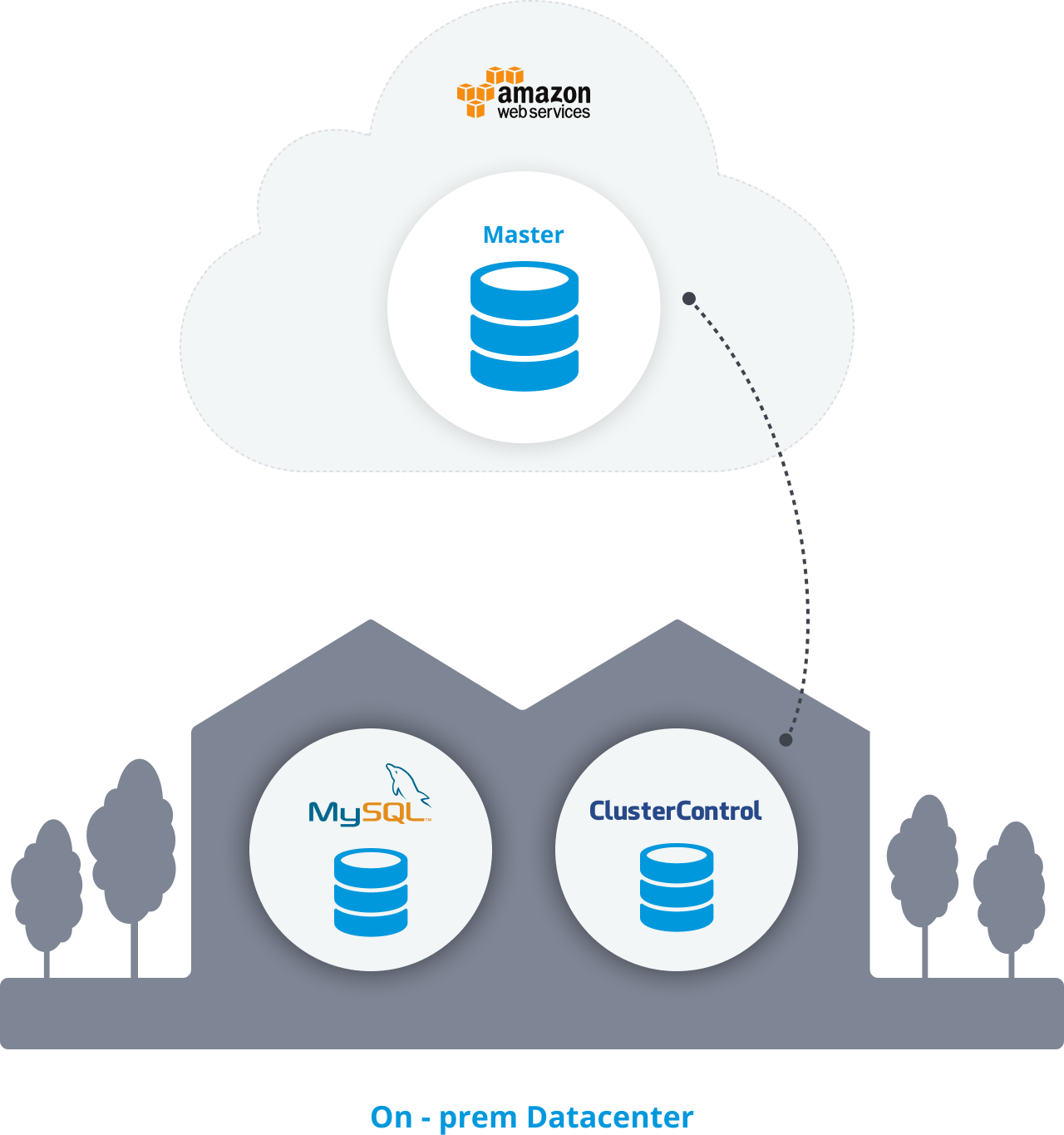
We will assume that you have your main MySQL database running on an EC2 instance. In the on-prem data center, we will also assume you have ClusterControl installed and a fresh database server to migrate to.
In the AWS management console, you should have something like this in the EC2 instances section:

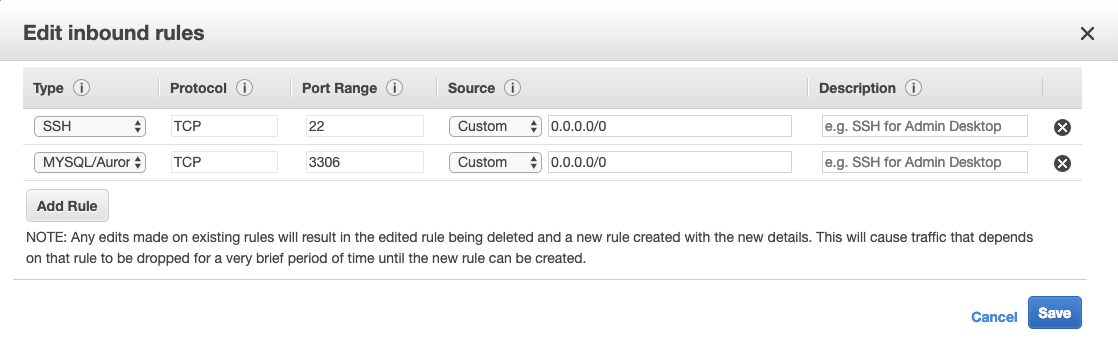
First, you’ll need to import your current primary node running on EC2 to ClusterControl. For this import process, you need to open port 3306 by editing the Security Group associated with the EC2 instance.
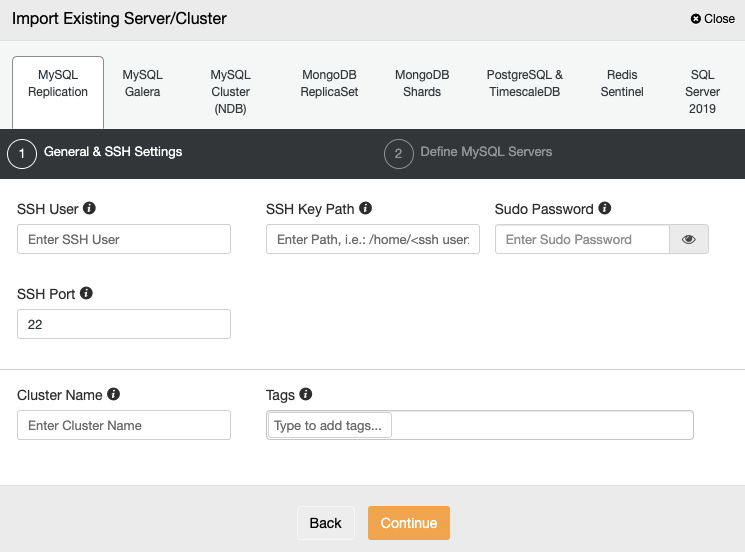
After this, within ClusterControl, go to the Import section:

There, you can choose the database technology, in this example MySQL Replication, and you must specify the User, Key or Password, and port to connect to your server via SSH You also need to provide the name of your new cluster.
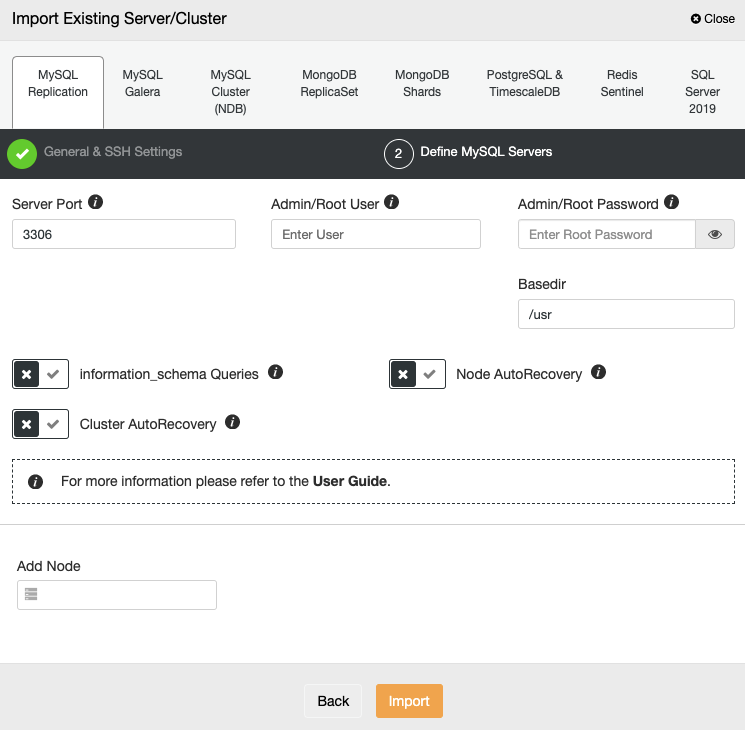
After setting up the SSH access information, you must define some database information like the database admin credentials, port, and basedir. Also, you can enable the ClusterControl Node AutoRecovery, and Cluster AutoRecovery features for the new cluster.
Then, you need to add your server by using the IP address or hostname and press Import.
Once that’s done, you can monitor the status of the import job from the ClusterControl activity monitor.
Once the task is complete, you will see your database node in the main ClusterControl screen:

Be sure to enable the binlog generation in your current master database.
Now, you can add your future new primary node as a new replica from your current primary database. For this, go to ClusterControl -> Select Cluster -> Cluster Actions -> Add Replication Slave.
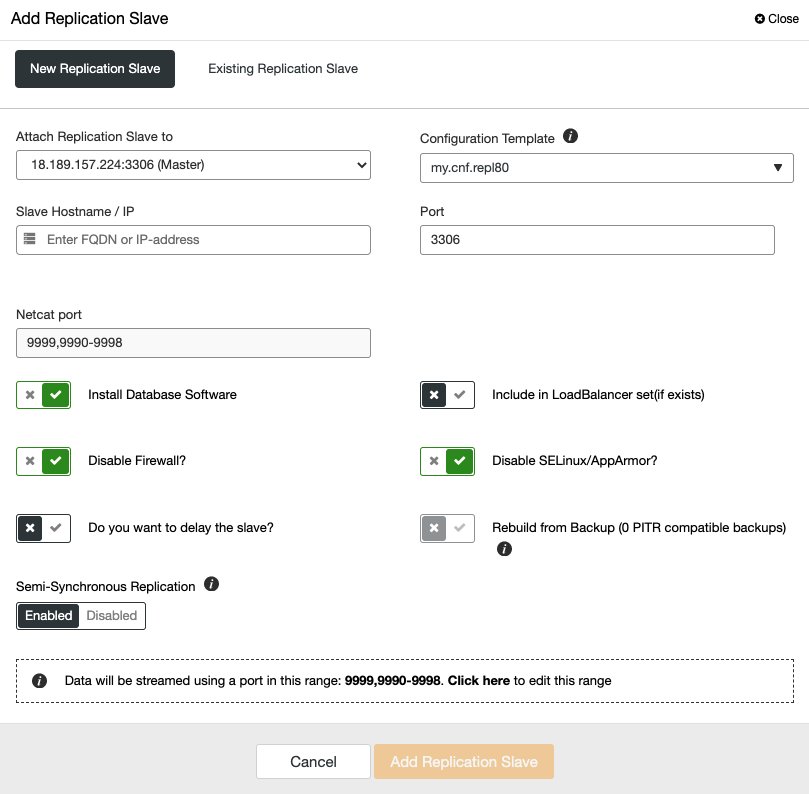
Here, you need to add the hostname or IP address of the new replica server, and if you want ClusterControl to install the software for you.
Make sure that you have connectivity from AWS to ports 3306 and 9999 in the on-prem server.
ClusterControl stages replica with data by taking a hot backup of the primary, streaming it to the replica, and restoring it there. Once restored, the replica node is connected to the primary node so it can catch up on events and get in sync. Note that for large databases running with some load, you might want to avoid the extra load of this operation on the primary node. In that case, it is possible to build the replica node first from an existing backup and then connect the replica, so it catches up with the primary node.
After this task, you should have something like this:
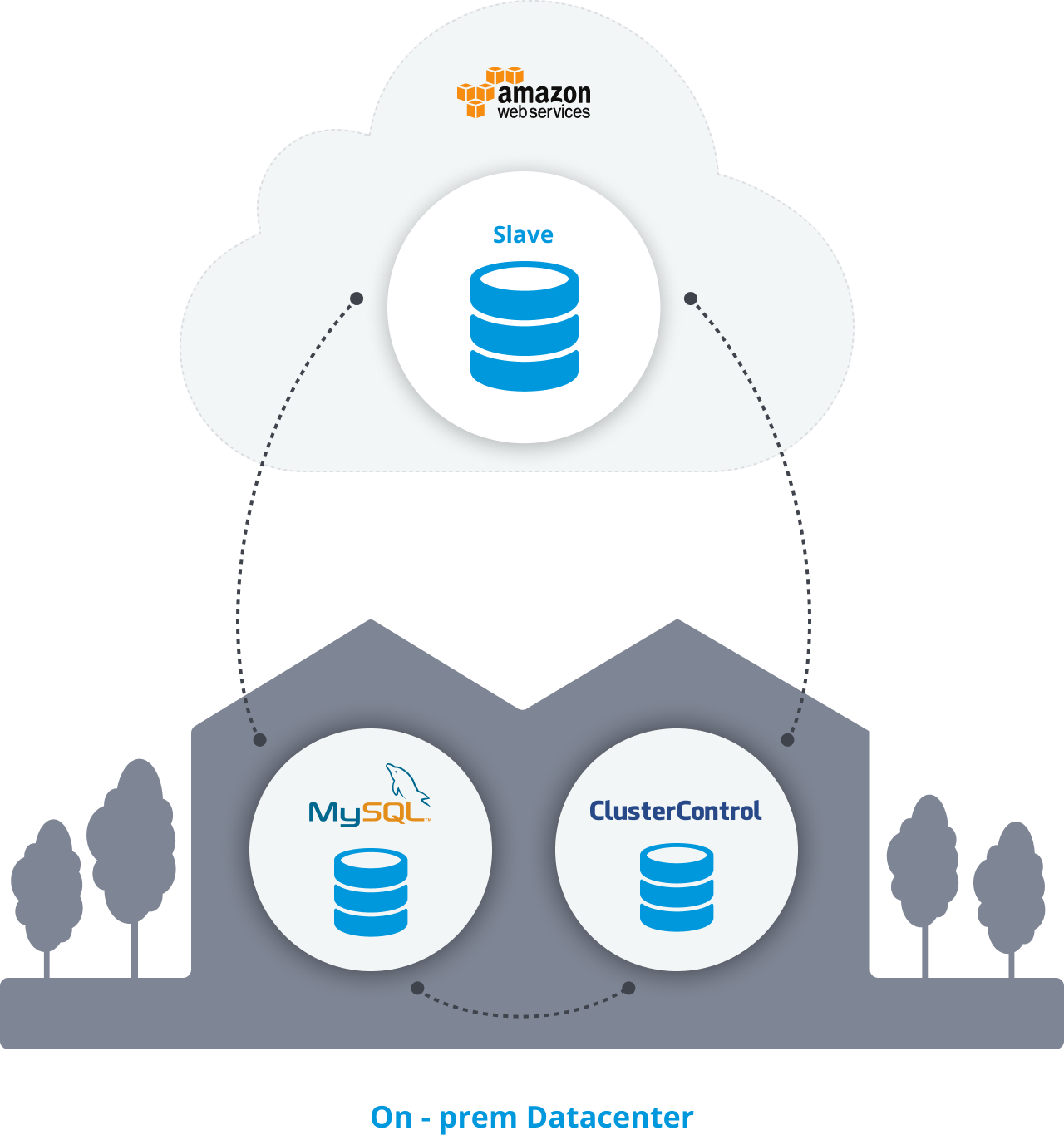
You can also verify your topology on the ClusterControl Topology section.
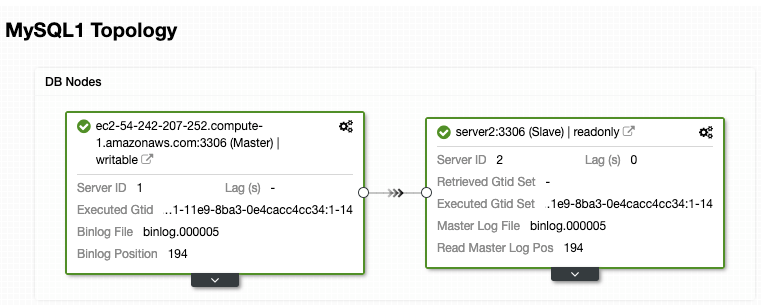
Then, you need to promote the replica to primary (ClusterControl -> Select Cluster -> Node Actions -> Promote Slave) and change the endpoint in your application.
To improve this topology, you can add a load balancer to manage the traffic from the application server to the database. When using a load balancer, you won’t need to change the endpoint from your application during the migration; the load balancer will change the primary node in a transparent way.

There are many ways to perform this task, and you should be able to adopt a strategy like this to your environment, depending on your infrastructure, security, etc.
For security reasons, you should consider using a VPN between AWS and the on-prem environment.
In the case of a multi-master topology like Galera Cluster, you only need to add the nodes that you want on-premise, but be careful with the latency. You can use, for example, different Galera segments to decrease network usage.
Considerations for Migration
Finally, here are some considerations to take into account if you want to leave AWS and start to use your own environment:
- Monitoring: Don’t forget to use a monitoring system. You need to know what is happening in your system all the time!
- Disaster Recovery Strategy: You should consider a good DRP. In general, you should have the information in three different physical places: Primary, Replica, and backup.
- High Availability: Nowadays, high availability is a must in most production environments, so you need to think about the best high availability solution depending on your infrastructure.
- Scaling: You should be able to scale if needed in the future or for a specific event.
- Rollback: If you want to migrate from AWS to an on-premise environment, keep in mind that something could go wrong (as in any type of migration), so you should have a rollback plan.
- Suppose you are after some kind of hybrid environment, with instances running on AWS and on-prem. In that case, ClusterControl is an excellent fit for monitoring, managing availability, backups, scaling, and more. Give it a try!
Wrapping Up
Sometimes, operating in the cloud just isn’t the best fit, and you may find yourself needing to migrate back to an on-premise solution. We hope this blog has provided you with some helpful information about migrating your MySQL-based data to your on-prem data center from AWS and how ClusterControl delivers the tools you need to properly manage your systems.
Once you’ve successfully completed your migration, level up your monitoring system with proactive strategies like predictive alerting. Check out our recently updated post on Database Monitoring with ClusterControl to learn more.
For more updates on database management tips and best practices, be sure to subscribe to our blog, RSS feed and follow us on LinkedIn and Twitter.



