Managed PostgreSQL on-prem, in the cloud, or both
Version: 12, 13, 14, 15, 16, 17, 18 License: Open Source & Enterprise (EDB)
Get managed PostgreSQL with the freedom to host it on-prem, in the cloud, or both. ClusterControl simplifies Day 2 ops for you through intelligent automation wherever you want. Simplify scaling, failover, backups, and upgrades with intelligent automation.
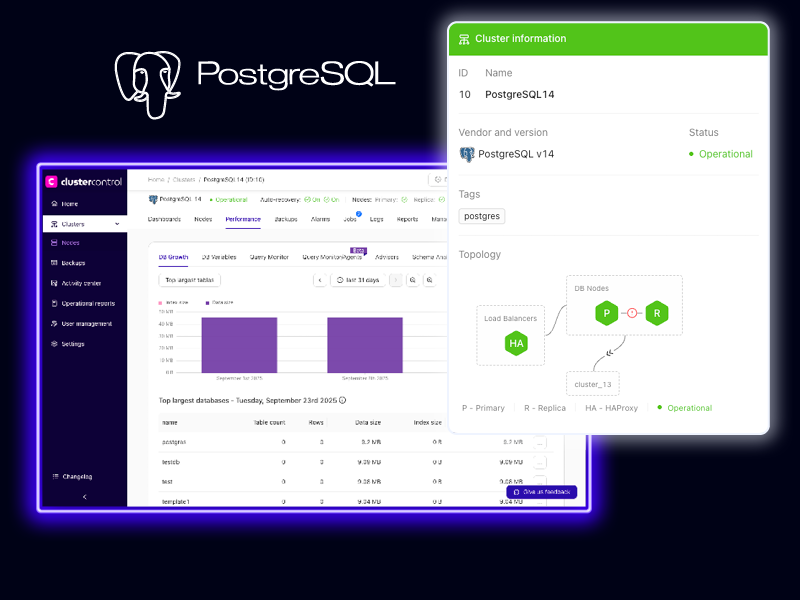
Unlock More with ClusterControl + PostgreSQL

Deploy PostgreSQL in One Click
Set up streaming or logical replication clusters with integrated HAProxy load balancing or PgBouncer connection pooling.

Monitor Deep Database Health
Track database growth, and performance, replica lag, queries, and node load via real-time Postgres-tailored dashboards and performance advisors.

Backup with Point-in-Time Recovery
Automate full, differential, and incremental backups with compression and encryption. Restore precisely using WAL-based recoveries.

Scale, Failover, & Promote Easily
Add, or reassign replicas smoothly. ClusterControl manages replication setup, failovers, and topology changes with minimal disruption.

Secure PostgreSQL at Scale
Enforce RBAC, LDAP/AD, TLS encryption, certificates management, and audit logging — delivering centralized, enterprise-grade security.

Upgrade & Extend Without Downtime
Perform in-place major version upgrades and enable advanced extensions like pgvector — all while your database stays online.
ClusterControl vs. the Alternatives
ClusterControl is a PostgreSQL cluster manager built for engineers and trusted by enterprises.
| Feature | ClusterControl | AWS RDS for PostgreSQL |
|---|---|---|
| On‑prem & hybrid support | X | |
| HA & replication automation | Managed | |
| Full operational control | Limited | |
| Lifecycle Tooling | Partial | |
| Advanced observability | Basic |
Still Managing PostgreSQL by Hand? Time to Upgrade.
ClusterControl is the PostgreSQL management platform DevOps teams actually want. Built for engineers. Trusted by enterprises. Made for your infrastructure.
ClusterControl supports your entire PostgreSQL lifecycle:
Deploy: Launch streaming or logical replication clusters with load balancers.
Observe: Monitor queries, replication, system metrics, and plugin-level extensions.
Protect: Use WAL-based PITR and encrypted, compressed backups across environments.
Scale: Seamlessly add or reconfigure replicas; manage failovers and promotion without downtime.
Automate: Upgrade PostgreSQL versions, apply extensions, and self-heal automagically.
Many of our applications that we use to deliver care to our patients rely on database backends that we host locally. Most of these systems are mission critical and uptime is of utmost importance, as is reliable backup and restoration processes to prevent data loss.

Supported PostgreSQL Configurations
Supported Distributions
ClusterControl supports open-source PostgreSQL, EnterpriseDB, and TimescaleDB across versions 12 to 18.
Broad engine support: Choose between community PostgreSQL, EDB for enterprise features, or TimescaleDB for time-series workloads.
OS compatibility: Runs on major Linux distributions, including Debian, Ubuntu, RHEL, CentOS, Rocky, and AlmaLinux.
Flexible deployment sources: Deploy from vendor-maintained repositories, PostgreSQL Global Development Group (PGDG) packages, or custom builds.
Version coverage: From long-term supported releases to the latest stable versions.
Replication & High Availability
Streaming (Physical) Replication: The PostgreSQL default: continuous streaming of WAL data from primary to standby servers for high availability and read scaling; supports synchronous or asynchronous modes. ClusterControl automates setup, monitoring, failover, backups, PITR, upgrades, and extension orchestration.
Logical Replication (Including Bi-Directional): Publishes and subscribes to data changes at the table level, enabling flexible replication workflows including bidirectional setups. ClusterControl now supports logical replication and bi-directional synchronization.
Severalnines is Enterprise Ready

Reliable
Zero-downtime operations you can count on.

Secure
Data stays protected, at rest and in transit.

Compliant
GDPR, SOC 2, ISO27001 standards.
Managed PostgreSQL features list
| Licenses | |
| Open Source | |
| Enterprise | |
| Cluster management | |
| Deploy / import | |
| Add / duplicate / remove / decommission node | |
| High availability | |
| Load balancers | |
| Automated failover | |
| Asynchronous / synchronous replication | |
| Backup / restore | |
| Full / differential / incremental backups | |
| Backup compression / encryption | |
| Local / cloud backups | |
| Observability | |
| Infrastructure / database / query monitoring | |
| Dashboarding / alerting | |
| Security / compliance | |
| Role-based access control | |
| Key management | |
| LDAP integration | |
| TLS encryption | |
| Reporting | |
| Audit log |
Choose the CC plan that fits your use case and preferred payment terms
Advanced
self-serve
Includes all features from Advanced
- Deploy 2 to 5 node clusters
- Monthly subscription
- Pay with Credit Card
- Community support
starts at€250per node, per month
€0.35per node, per hour
Advanced
Includes everything from Community
- Load balancers
- Scaling and failover
- Backup and recovery
- Monitoring and alerting
- Database user management
- Business hours support
Custom pricing
Enterprise
Includes everything from Advanced
- CC Ops Centre
- Backup verification
- Ops reports and audit logs
- RBAC & LDAP / Active Directory
- Key management, TLS encryption
- Web / email / phone 24×7 support
Custom pricing
Get the ClusterControl for PostgreSQL One-Pager
Security & compliance you can trust
ClusterControl is built with enterprise-grade security to safeguard your data and maintain compliance:
• Role-Based Access Control & Key Management
• LDAP Integration & TLS Encryption
• Comprehensive Audit Logs & Reporting

Top rated Docs
I have a specific need to create replication replicas quite often and am tired of having to tweak homegrown scripts. How have you solved this?
For creating new replicas, rebuilding, or resyncing, it’s just a click of a button, explained here.
My PostgreSQL install has just been created and had data imported from other sources. Will I have to repeat this for ClusterControl to work?
No. Just import the PostgreSQL instance into ClusterControl, and then you can add replicas as you see fit.
I’m new to PostgreSQL and HAProxy and worried about how to configure both properly. How can I do this safely?
Check out the configurations page that gives you the ability to adjust the pg_hba.conf and postgresql.conf files from the GUI.