Disaster recovery
Replication between two clusters is not the same as extending a cluster across two data centers. When setting up cluster to cluster replication, you must separate the systems so that they can operate independently; replication is then used to keep them synced so that the secondary system can take over.

Disaster recovery key factors
Disaster recovery generally relies on two key factors:
- Disaster Tolerance
Business critical applications and their databases are usually deployed in two or more locations, whether on-prem, public clouds, or hybrid setups to switchover to as needed.
- Backups (and recovery)
Backing up and being able to recover an organization’s data / databases is the most important responsibility an (IT) operations team has. It’s also imperative to consistently verify that backups are in fact restorable. There are several public cases where backups have been turned out to be corrupt and un-restorable when disaster actually strikes.
Want to know how
ClusterControl can help?
How does ClusterControl support disaster recovery operations?
ClusterControl provides a complete enterprise grade backup management including verification. Backups can be taken as full, incremental or partial with offsite shipping to S3 compliant cloud storage providers. Offsite backups can be used to restore to a secondary site from scratch however it will take longer time (RTO) to provision and get the application/database back online. This is the most cost effective solution for applications that are not business critical.
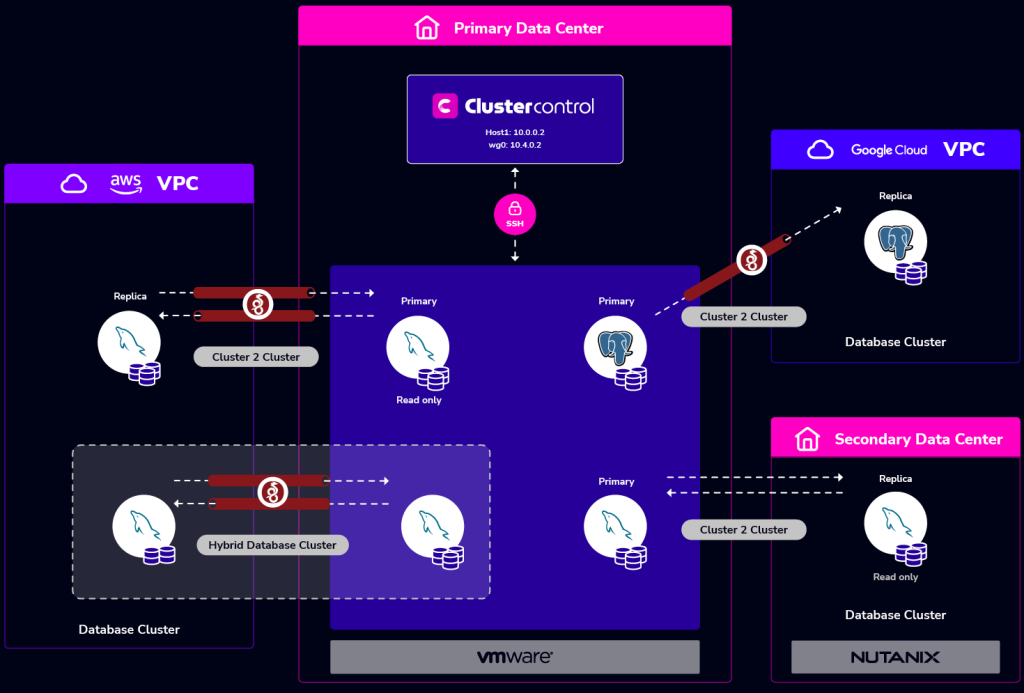
In cases where Recovery Time Objectives – RTO is critical, database resilience is achieved by replicating from the primary database cluster in one location to a secondary database cluster in another location.
ClusterControl supports the following resilience options out of the box:
- Active – Active clusters (Asynchronous Replication)
- MySQL Galera
- MySQL NDB Cluster
- Active – Active clusters (Semi-synchronous Replication)
- MySQL Galera
- Active – Standby clusters
- MySQL Galera
- MySQL Replication
- PostgreSQL
Cluster-to-Cluster replication can also be used in many other use cases such as:
- Migrating to a new datacenter
- Geo-location performance – keep data closer to a set of users for that region
- Replicating production to a dev/test environment for troubleshooting
- Replicate and test a newer version of the database before doing a switchover
- Use a secondary cluster for read-only access for reports or analytics.
Featured disaster recovery resources


How Disaster Recovery is Different in a Hybrid Cloud
Disaster recovery has many means and can be implemented in many ways. The one thing to keep in mind is that when you are designing a production environment, you should always consider how you are…

Cloud Disaster Recovery for MariaDB and MySQL
MySQL has a long tradition in geographic replication. Distributing clusters to remote data centers reduces the effects of geographic latency by pushing data closer to the user. It also provides a capability for disaster recovery….