blog
Cloud Disaster Recovery for MariaDB and MySQL

MySQL has a long tradition in geographic replication. Distributing clusters to remote data centers reduces the effects of geographic latency by pushing data closer to the user. It also provides a capability for disaster recovery. Due to the significant cost of duplicating hardware in a separate site, not many companies were able to afford it in the past. Another cost is skilled staff who is able to design, implement and maintain a sophisticated multiple data centers environment.
With the Cloud and DevOps automation revolution, having distributed datacenter has never been more accessible to the masses. Cloud providers are increasing the range of services they offer for a better price.One can build cross-cloud, hybrid environments with data spread all over the world. One can make flexible and scalable DR plans to approach a broad range of disruption scenarios. In some cases, that can just be a backup stored offsite. In other cases, it can be a 1 to 1 copy of a production environment running somewhere else.
In this blog we will take a look at some of these cases, and address common scenarios.
Storing Backups in the Cloud
A DR plan is a general term that describes a process to recover disrupted IT systems and other critical assets an organization uses. Backup is the primary method to achieve this. When a backup is in the same data center as your production servers, you risk that all data may be wiped out in case you lose that data center. To avoid that, you should have the policy to create a copy in another physical location. It’s still a good practice to keep a backup on disk to reduce the time needed to restore. In most cases, you will keep your primary backup in the same data center (to minimize restore time), but you should also have a backup that can be used to restore business procedures when primary datacenter is down.
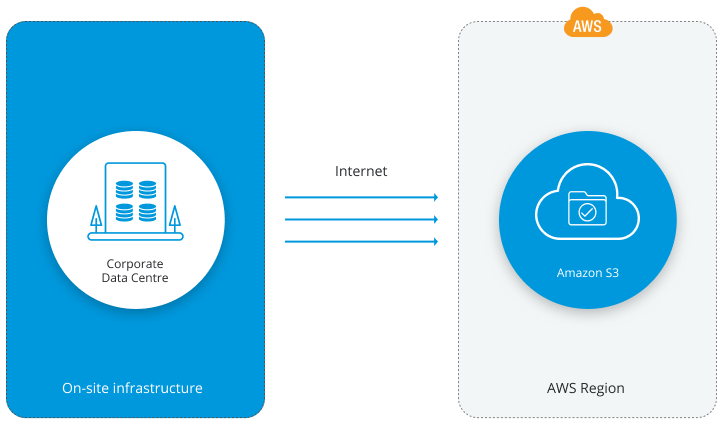
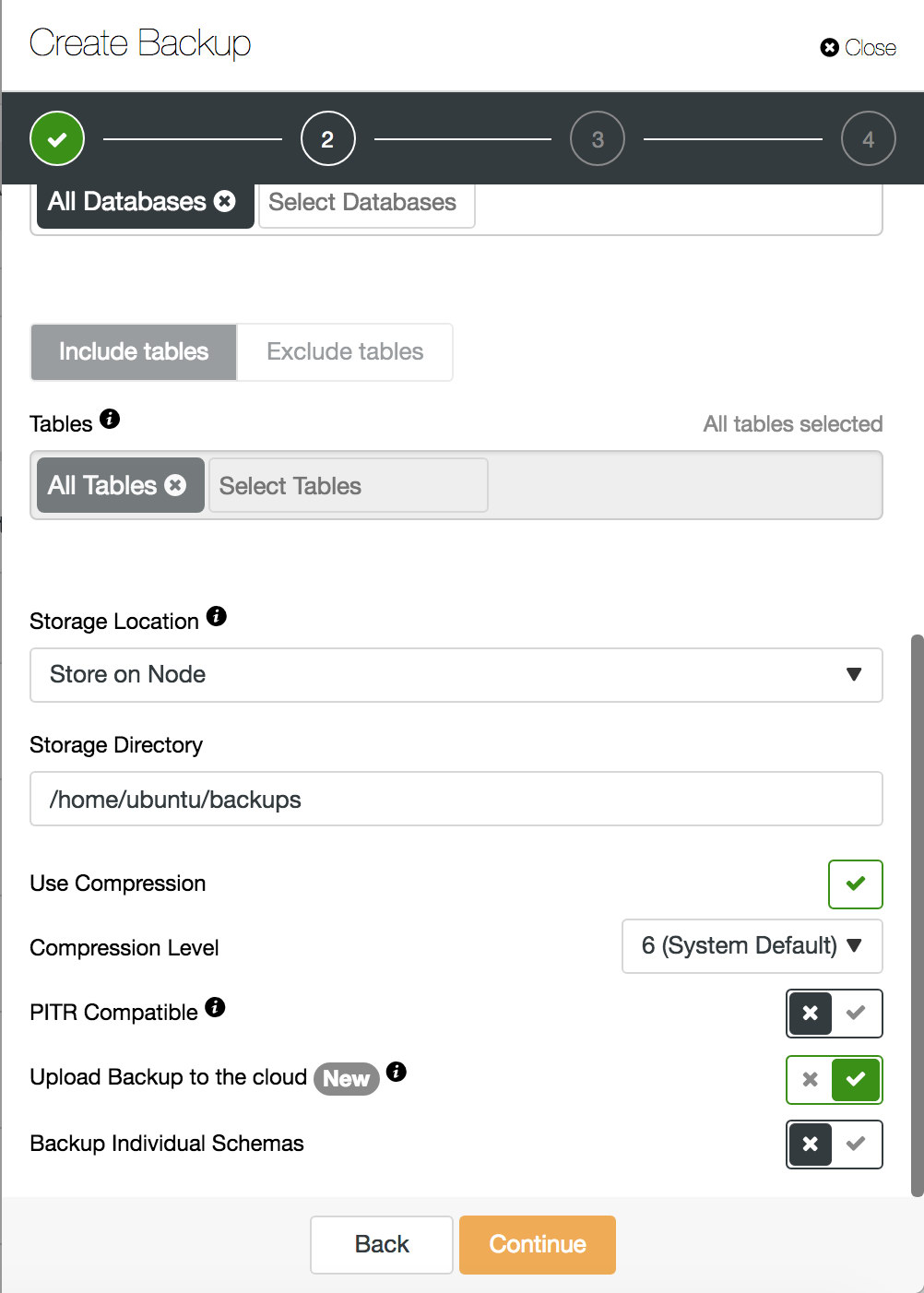
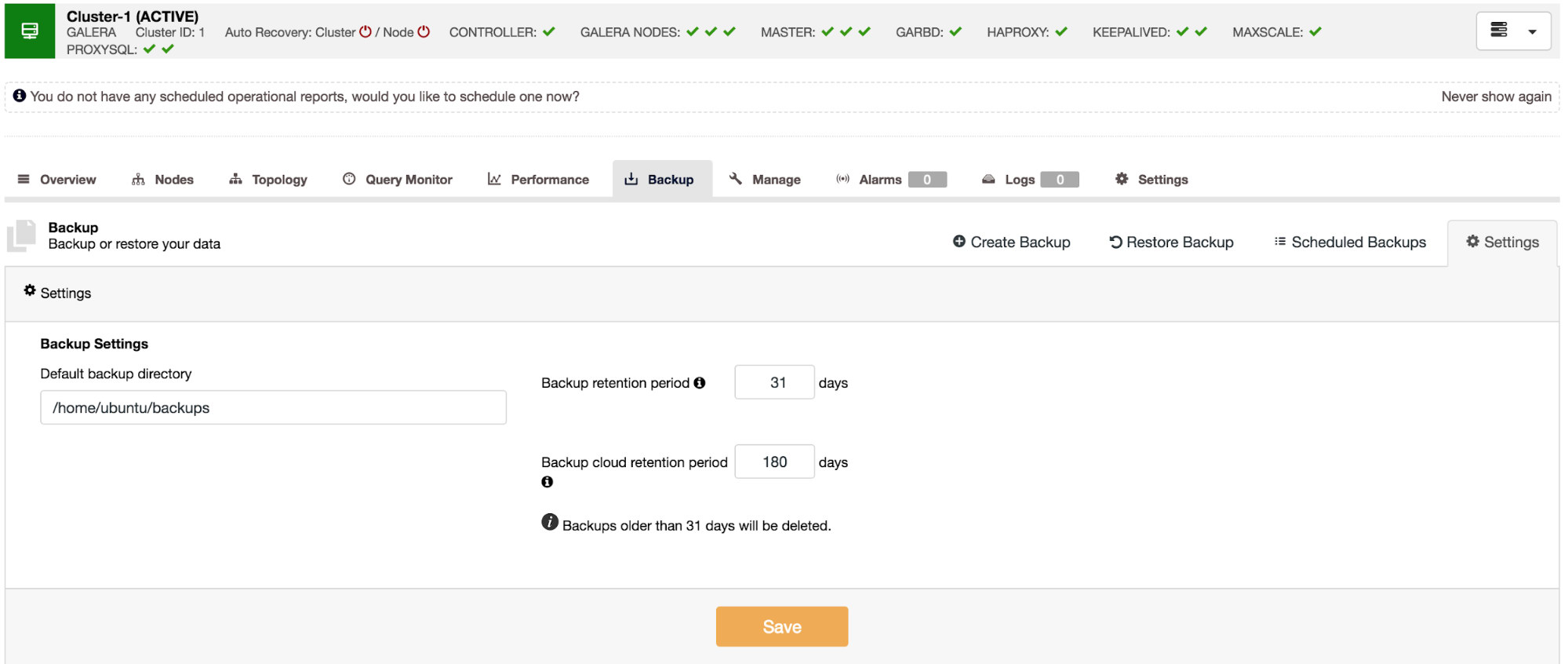
ClusterControl allows seamless integration between your database environment and the cloud. It provides options for migrating data to the cloud. We offer a full combination of database backups for Amazon Web Services (AWS), Google Cloud Services or Microsoft Azure. Backups can now be executed, scheduled, downloaded and restored directly from your cloud provider of choice. This ability provides increased redundancy, better disaster recovery options, and benefits in both performance and cost savings.
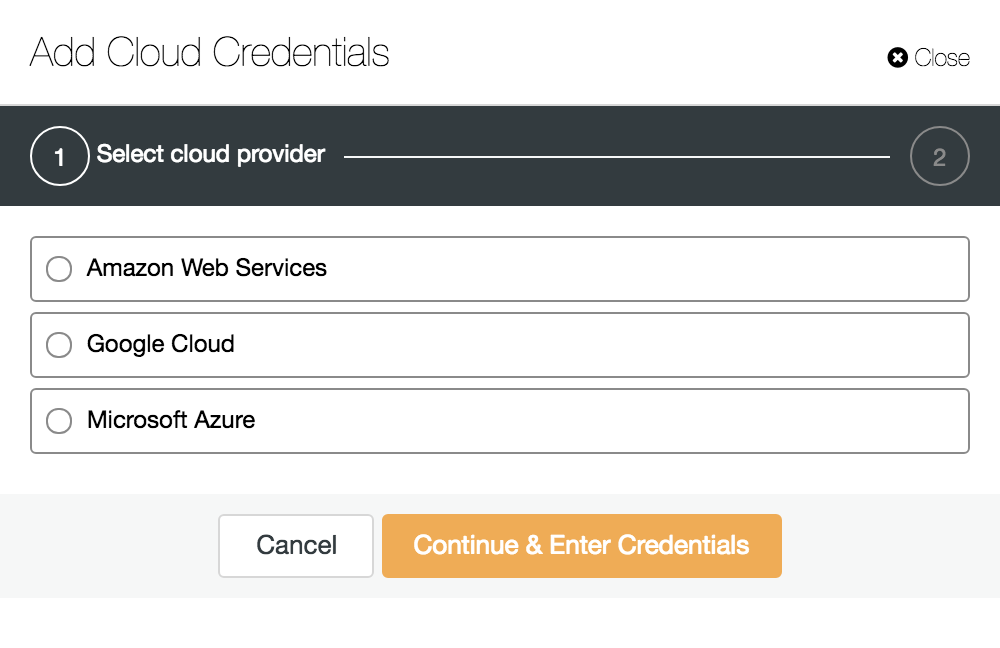
The first step to set up “data center failure – proof backup” is to provide credentials for your cloud operator. You can choose from multiple vendors here. Let’s take a look at the process set up for the most popular cloud operator – AWS.
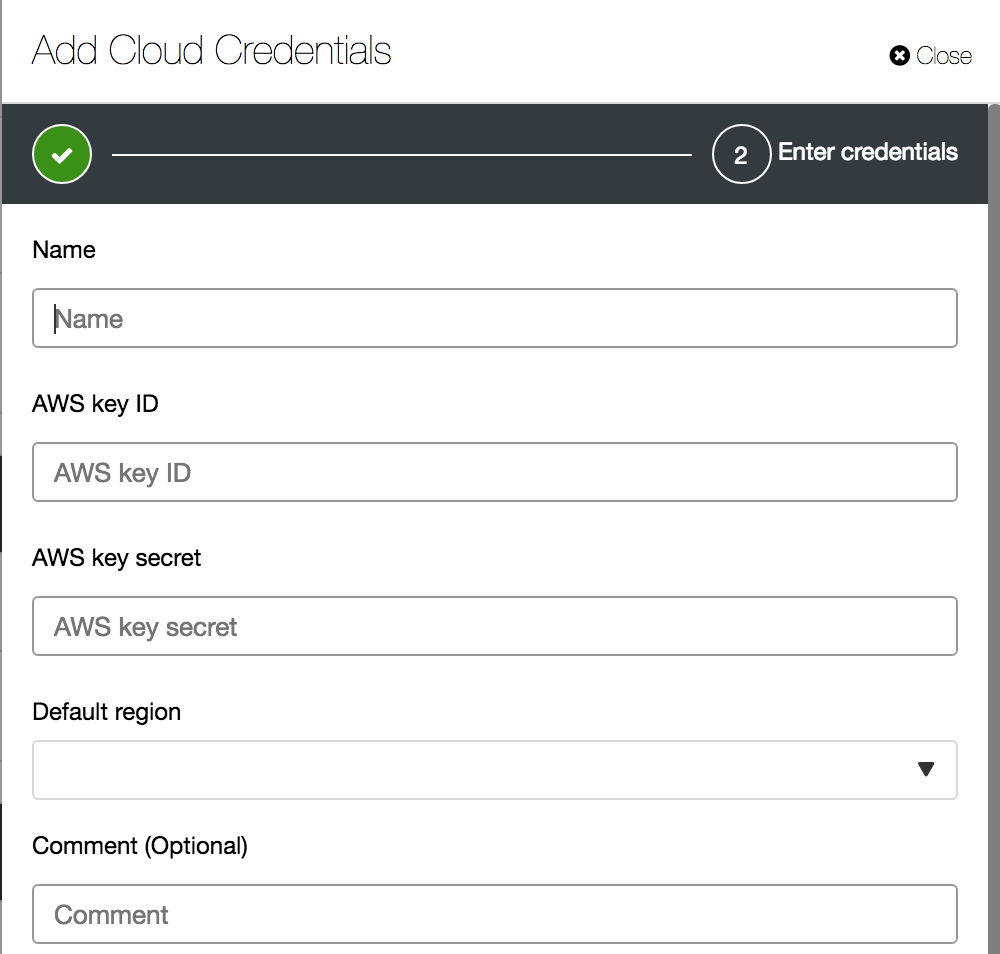
All you need is the AWS Key ID and the secret for the region where you want to store your backup. You can get that from AWS console. You can follow a few steps to get it.
- Use your AWS account email address and password to sign in to the AWS Management Console as the AWS account root user.
- On the IAM Dashboard page, choose your account name in the navigation bar, and then select My Security Credentials.
- If you see a warning about accessing the security credentials for your AWS account, choose to Continue to Security Credentials.
- Expand the Access keys (access key ID and secret access key) section.
- Choose to Create New Access Key. Then choose Download Key File to save the access key ID and secret access key to a file on your computer. After you close the dialog box, you will not be able to retrieve this secret access key again.
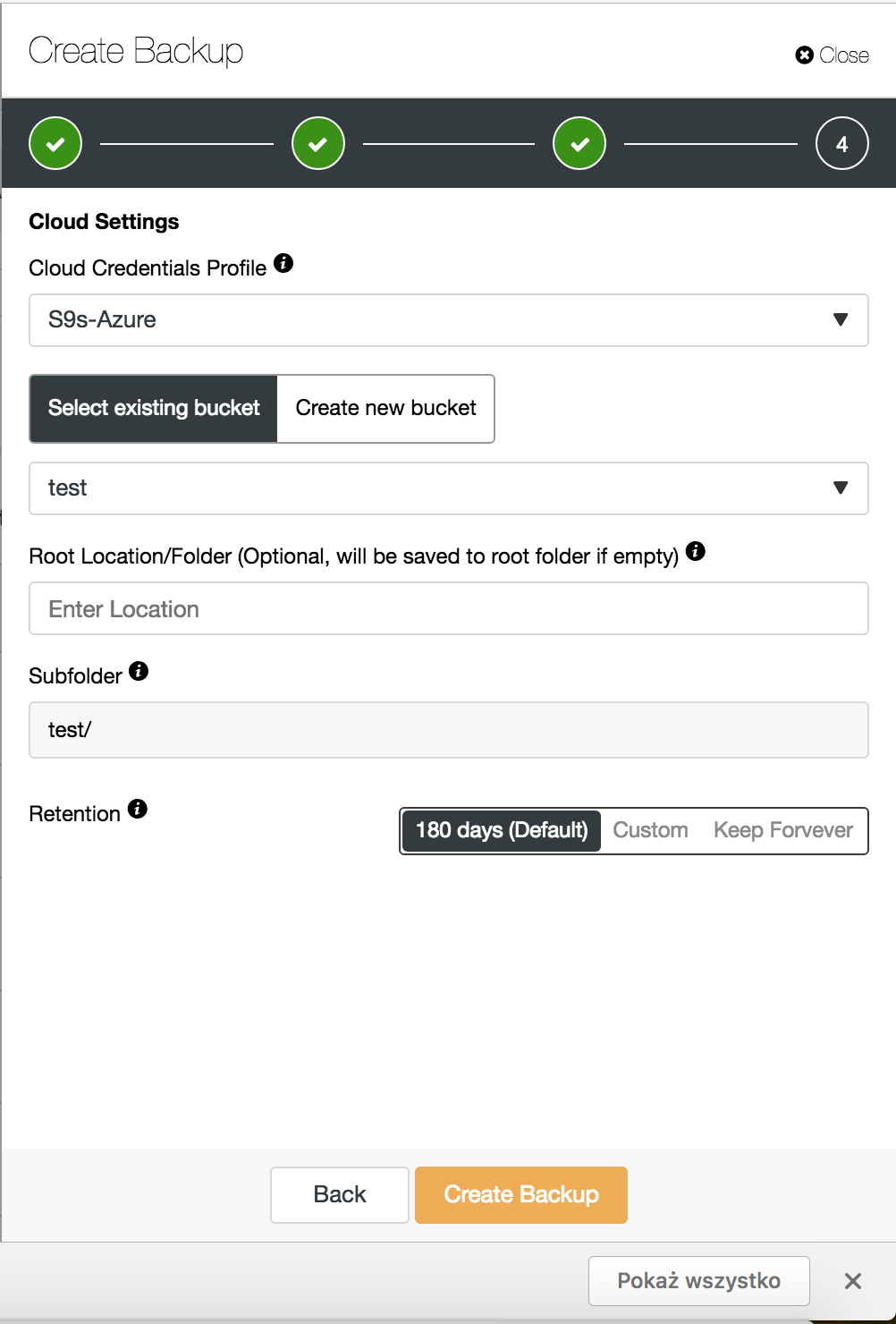
When all is set, you can adjust your backup schedule and enable backup to cloud option. To reduce network traffic make sure to enable data compression. It makes backups smaller and minimizes the time needed for upload. Another good practice is to encrypt the backup. ClusterControl creates a key automatically and uses it if you decide to restore it. Advanced backup policies should have different keep times for backups stored on servers in the same datacenter, and the backups stored in another physical location. You should set a more extended retention period for cloud-based backups, and shorter period for backups stored near the production environment, as the probability of restore drops with the backup lifetime.
Extend Your Cluster With Asynchronous Replication
Galera with asynchronous replication can be an excellent solution to build an active DR node in a remote data center. There are a few good reasons to attach an asynchronous slave to a Galera Cluster. Long-running OLAP type queries on a Galera node might slow down a whole cluster. With delay apply option, delayed replication can save you from human errors so all those golden enters will be not immediately applied to your backup node.
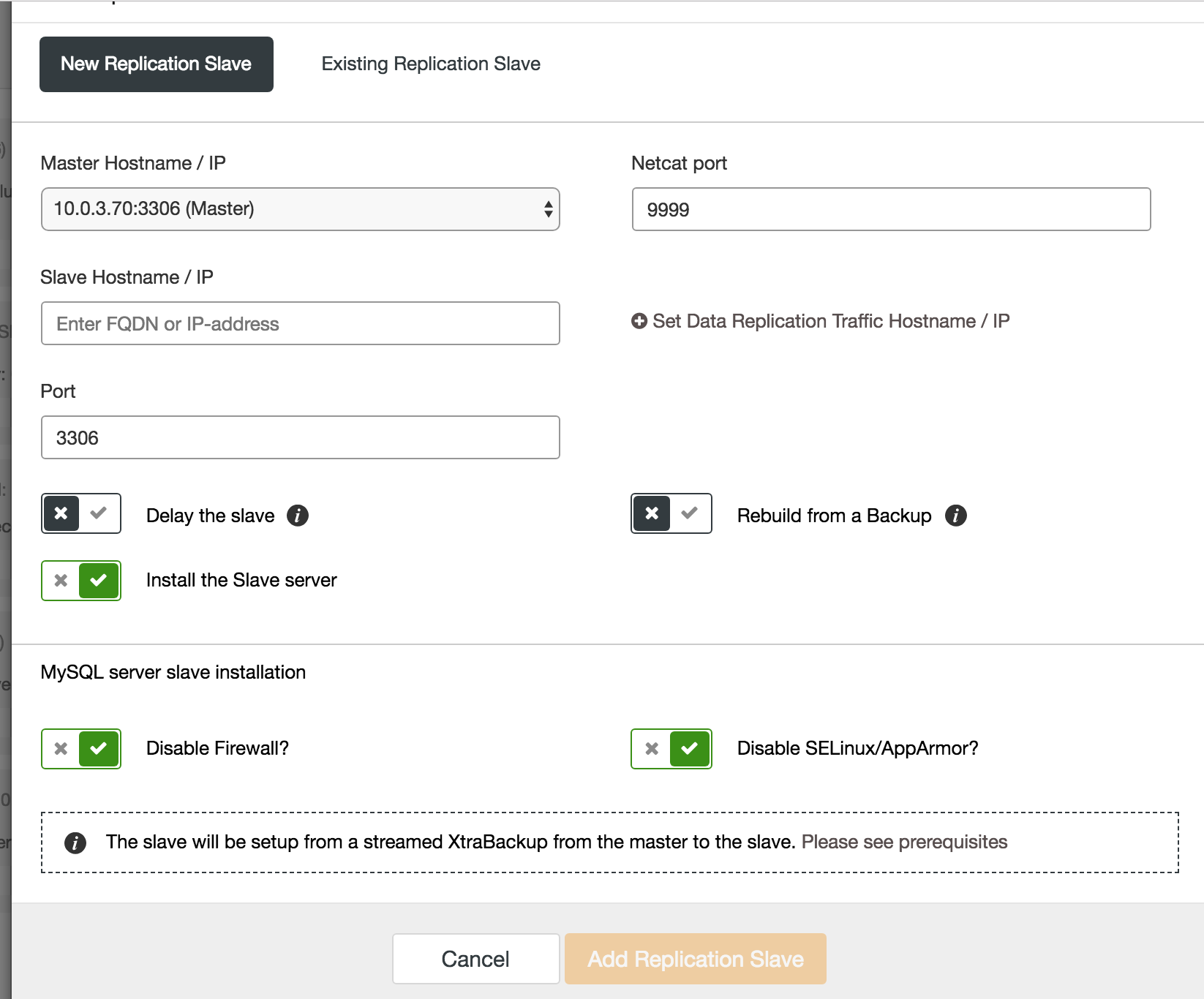
In ClusterControl, extending a Galera node group with asynchronous replication is done in a single page wizard. You need to provide the necessary information about your future or existing slave server. The slave will be set up from an existing backup, or a freshly streamed XtraBackup from the master to the slave.
Load Balancers in Multi-Datacenter
Load balancers are a crucial component in MySQL and MariaDB database high availability. It’s not enough to have a cluster spanning across multiple data centers. You still need your services to access them. A failure of a load balancer that is available in one data center will make your entire environment unreachable.
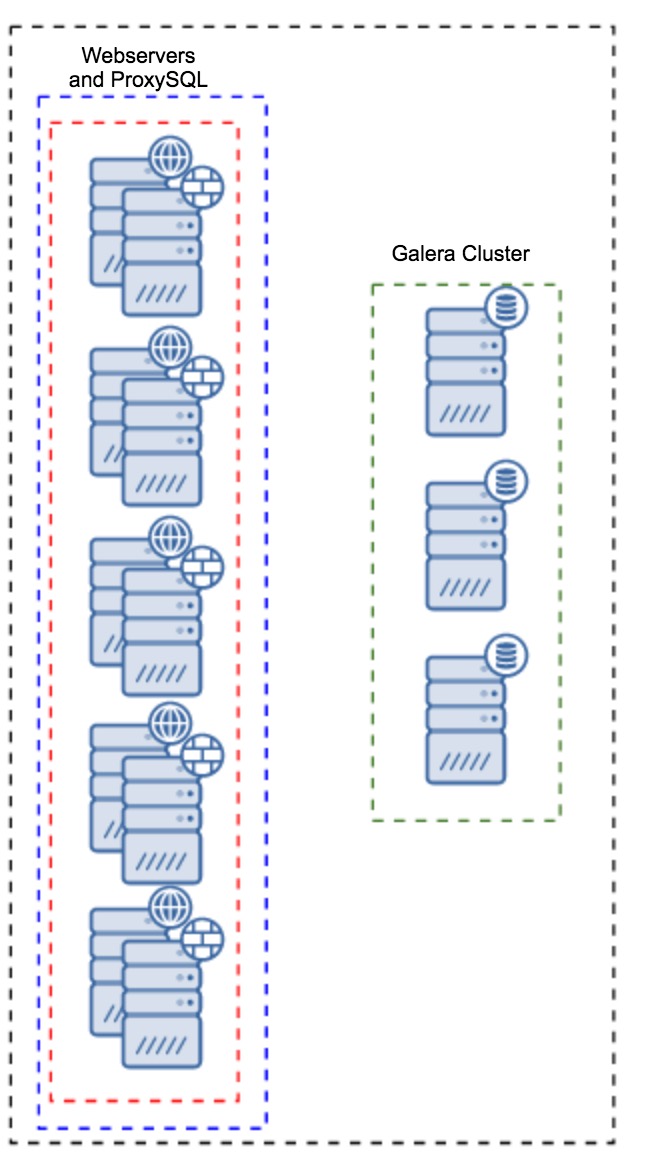
One of the popular methods to hide the complexity of the database layer from an application is to use a proxy. Proxies act as an entry point to the databases, they track the state of the database nodes and should always direct traffic to only the nodes that are available. ClusterControl makes it easy to deploy and configure several different load balancing technologies for MySQL and MariaDB, including ProxySQL, HAProxy, with a point-and-click graphical interface.
It also allows making this component redundant by adding keepalived on top of it. To prevent your load balancers from being a single point of failure, one would set up two identical (one active and one in different DC as standby) HAProxy, ProxySQL or MariaDB Maxscale instances and use Keepalived to run Virtual Router Redundancy Protocol (VRRP) between them. VRRP provides a Virtual IP address to the active load balancer and transfers the Virtual IP to the standby HAProxy in case of failure. It is seamless because the two proxy instances need no shared state.
Of course, there are many things to consider to make your databases immune to data center failures.
Proper planning and automation will make it work! Happy Clustering!



