blog
An Overview of Amazon RDS & Aurora Offerings for PostgreSQL

AWS PostgreSQL services fall under the RDS umbrella, which is Amazon’s DaaS offering for all known database engines.
Managed database services offer certain advantages that are appealing to the customer seeking independence from infrastructure maintenance, and highly available configurations. As always, there isn’t a one size fits all solution. The currently available options are highlighted below:
Aurora PostgreSQL
The Amazon Aurora FAQ page provides important details that need to be considered before diving into the product. For example, we learn that the storage layer is virtualized and sits on a proprietary virtualized storage system backed up by SSD.
Pricing
In term of pricing, it must be noted that Aurora PostgreSQL is not available in the AWS Free Tier.
Compatibility
The same FAQ page makes it clear that Amazon doesn’t claim 100% PostgreSQL compatibility. Most (my emphasis) of the applications will be fine, e.g. the AWS PostgreSQL flavor is wire-compatible with PostgreSQL 9.6. As a result, the Wireshark PostgreSQL Dissector will work just fine.
Performance
Performance is also linked to the instance type, for example the maximum number of connections is by default configured based on the instance size.
Also important when it comes to compatibility is the page size that has been kept at 8KiB which is the PostgreSQL default page size. Speaking of pages it’s worth quoting the FAQ: “Unlike traditional database engines Amazon Aurora never pushes modified database pages to the storage layer, resulting in further IO consumption savings.” This is made possible because Amazon changed the way the page cache is managed, allowing it to remain in memory in case of database failure. This feature also benefits the database restart following a crash, allowing the recovery to happen much faster than in the traditional method of replaying the logs.
According to the FAQ referenced above, Aurora PostgreSQL delivers three times the performance of PostgreSQL on SELECT and UPDATE operations. As per Amazon’s PostgreSQL Benchmark White Paper the tools used to measure the performance were pgbench and sysbench. Notable is the performance dependency on the instance type, region selection, and network performance. Wondering why INSERT isn’t mentioned? It is because PostgreSQL ACID compliance (the “C”) requires that an updated record is created using a delete followed by an insert.
In order to take full advantage of the performance improvements, Amazon recommends that applications are designed to interact with the database using large numbers of concurrent queries and transactions. This important factor, is often overlooked leading to poor performance blamed on the implementation.
Limits
There are some limitations to be considered when planning the migration:
-
huge_pages cannot be modified, however it is on by default:
template1=> select aurora_version(); aurora_version ---------------- 1.0.11 (1 row) template1=> show huge_pages ; huge_pages ------------ on (1 row) - pg_hba cannot be used since it requires a server restart. As a side note, that must be a typo in Amazon’s documentation, since PostgreSQL only needs to be reloaded. Instead of relying on pg_hba, administrators will need to use the AWS Security Groups, and PostgreSQL GRANT.
- PITR granularity is 5 minutes.
- Cross-region replication is not currently available for PostgreSQL.
- Maximum size of tables is 64TiB
- Up to 15 read replicas
Scalability
Scaling up and down the database instance is currently a manual process, that can be done via the AWS Console or CLI, although automatic scaling is in works, however, according to Amazon Aurora FAQ it will only be available for MySQL.
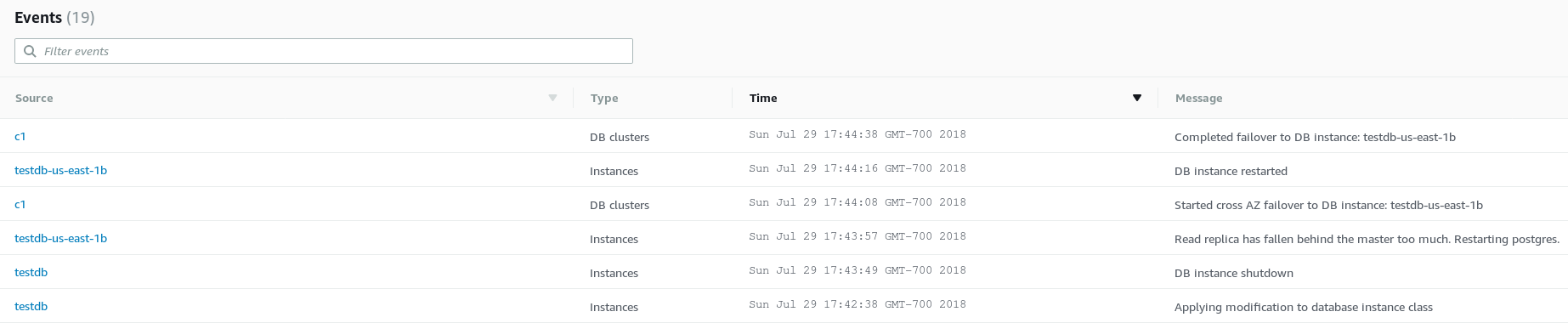
In order to scale horizontally applications must take advantage of AWS SDK APIs, for example in order to achieve fast failover.
High Availability
Moving on to high-availability, in case of primary node failure, Aurora PostgreSQL provides a cluster endpoint as a DNS A record, which is automatically updated internally to point to the replica selected to become master.
Backups
Worth mentioning that if the database is deleted, any manual backup snapshots will be kept, while automatic snapshots are removed.
Replication
Since replicas share the same underlying storage as the primary instance, replication lag is, in theory, in the range of milliseconds.
Amazon recommends read replicas in order to reduce the failover duration. With a read replica on standby the failover process takes about 30 seconds, while without a replica expect up to 15 minutes.
Other good news is that Logical replication is also supported, as shown on page 22.
Although the Amazon Aurora FAQ doesn’t provide details on replication as it does for MySQL, the Aurora PostgreSQL Best Practices provides a useful query for verifying the replication status:
select server_id, session_id, highest_lsn_rcvd,
cur_replay_latency_in_usec, now(), last_update_timestamp from
aurora_replica_status();The above query yields:
-[ RECORD 1 ]--------------+-------------------------------------
server_id | testdb
session_id | 9e268c62-9392-11e8-87fc-a926fa8340fe
highest_lsn_rcvd | 46640889
cur_replay_latency_in_usec | 8830
now | 2018-07-29 20:14:55.434701-07
last_update_timestamp | 2018-07-29 20:14:54-07
-[ RECORD 2 ]--------------+-------------------------------------
server_id | testdb-us-east-1b
session_id | MASTER_SESSION_ID
highest_lsn_rcvd |
cur_replay_latency_in_usec |
now | 2018-07-29 20:14:55.434701-07
last_update_timestamp | 2018-07-29 20:14:55-07Since replication is such an important topic it was worth setting up the pgbench test as outlined in the benchmark white paper referenced above:
[ec2-user@ip-172-31-45-67 ~]$ whoami
ec2-user
[ec2-user@ip-172-31-45-67 ~]$ tail -n 2 .bashrc
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib
export PATH=$PATH:/usr/local/pgsql/bin/
[ec2-user@ip-172-31-45-67 ~]$ which pgbench
/usr/local/pgsql/bin/pgbench
[ec2-user@ip-172-31-45-67 ~]$ pgbench --version
pgbench (PostgreSQL) 9.6.8Hint: Avoid unnecessary typing by creating a pgpass file and exporting the host, database, and user environment variables e.g.:
[root@ip-172-31-45-67 ~]# tail -n 3 ~/.bashrc export
PGUSER=dbadmin
export PGHOST=c1.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com
export PGDATABASE=template1
[root@ip-172-31-45-67 ~]# cat ~/.pgpass
*:*:*:dbadmin:passwordRun the data initialization command:
[ec2-user@ip-172-31-45-67 ~]$ pgbench -i --fillfactor=90 --scale=10000 postgresWhile data initialization is running, capture the replication lag using the above SQL called from within the following script:
while : ; do
psql -t -q
-c 'select server_id, session_id, highest_lsn_rcvd,
cur_replay_latency_in_usec, now(), last_update_timestamp
from aurora_replica_status();' postgres
sleep 1
doneFiltering the screenlog output through the following command:
[root@ip-172-31-45-67 ~]# awk -F '|' '{print $4,$5,$6}' screenlog.2 | sort -k1,1 -n | tail
513116 2018-07-30 04:30:44.394729+00 2018-07-30 04:30:43+00
529294 2018-07-30 04:20:54.261741+00 2018-07-30 04:20:53+00
544139 2018-07-30 04:41:57.538566+00 2018-07-30 04:41:57+00
1001902 2018-07-30 04:42:54.80136+00 2018-07-30 04:42:53+00
2376951 2018-07-30 04:38:06.621681+00 2018-07-30 04:38:06+00
2376951 2018-07-30 04:38:07.672919+00 2018-07-30 04:38:07+00
5365719 2018-07-30 04:36:51.608983+00 2018-07-30 04:36:50+00
5365719 2018-07-30 04:36:52.912731+00 2018-07-30 04:36:51+00
6308586 2018-07-30 04:45:22.951966+00 2018-07-30 04:45:21+00
8210986 2018-07-30 04:46:14.575385+00 2018-07-30 04:46:13+00It turns out the replication lagged as much as 8 seconds!
On a related note, AWS CloudWatch metric AuroraReplicaLagMaximum doesn’t agree with the results from the above SQL command. I’d like to know why, so feedback is highly appreciated.

Security
-
Encryption is available and it must be enabled when the database is created, as it cannot be changed afterwards.
Troubleshooting
This short section is an important bit Ensure that the PostgreSQL work_mem is tuned appropriately so sorting operations do not write data to disk.
Setup
Just follow the setup wizard in the AWS Console:
-
Open up the Amazon RDS management console.
 RDS management console
RDS management console -
Select Amazon Aurora and PostgreSQL edition.
 Aurora PostgreSQL wizard
Aurora PostgreSQL wizard -
Specify the DB details and note the Aurora PostgreSQL password limitations:
Master Password must be at least eight characters long, as in "mypassword". Can be any printable ASCII character except "/", """, or "@".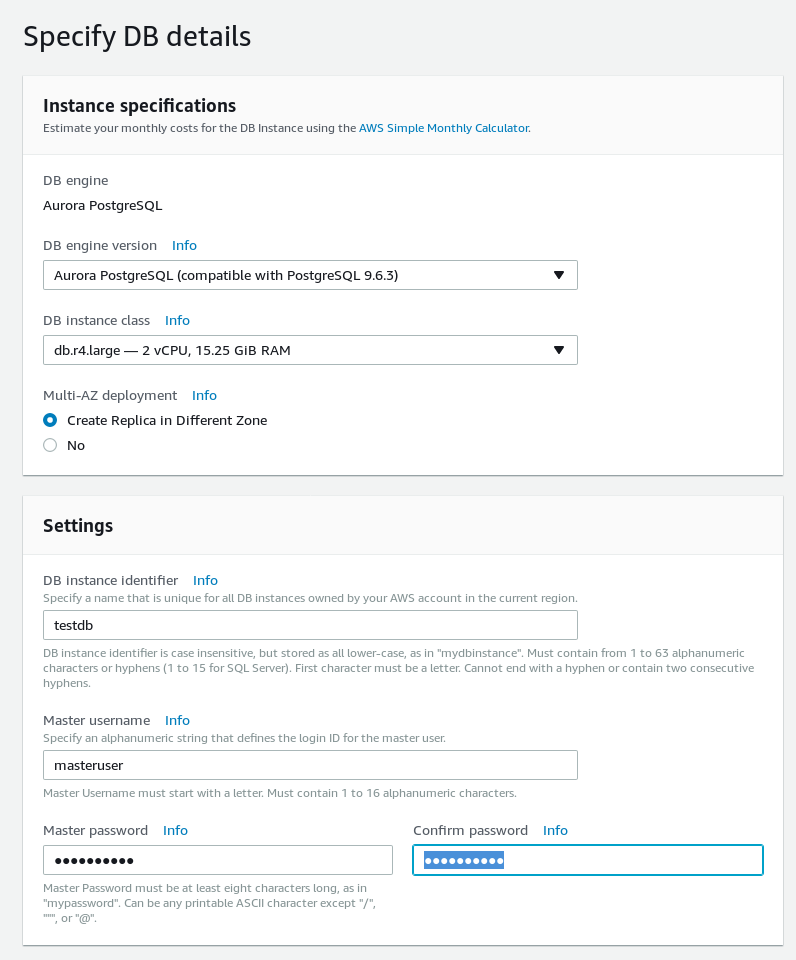 Aurora PostgreSQL wizard database details
Aurora PostgreSQL wizard database details -
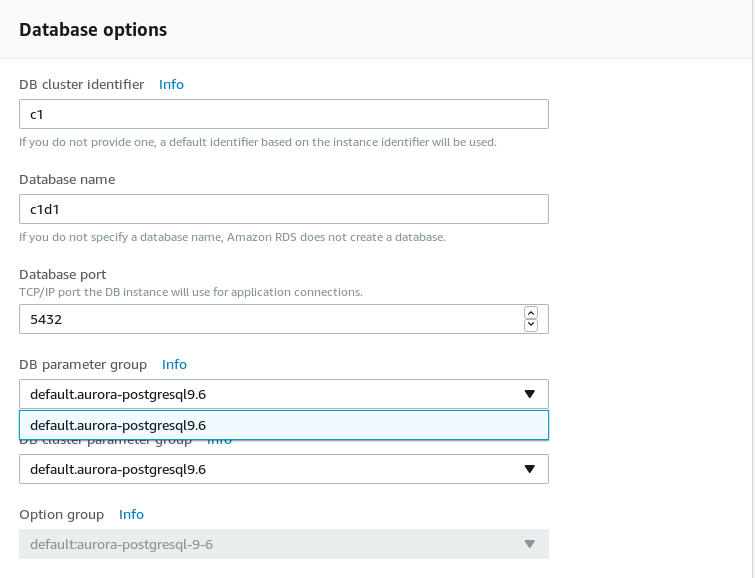
Configure the database options:
- As of this writing only PostgreSQL 9.6 available. Use PostgreSQL on Amazon RDS if you need support for more recent versions, including beta previews.
-
Configure the failover priority, and select the number of replicas.
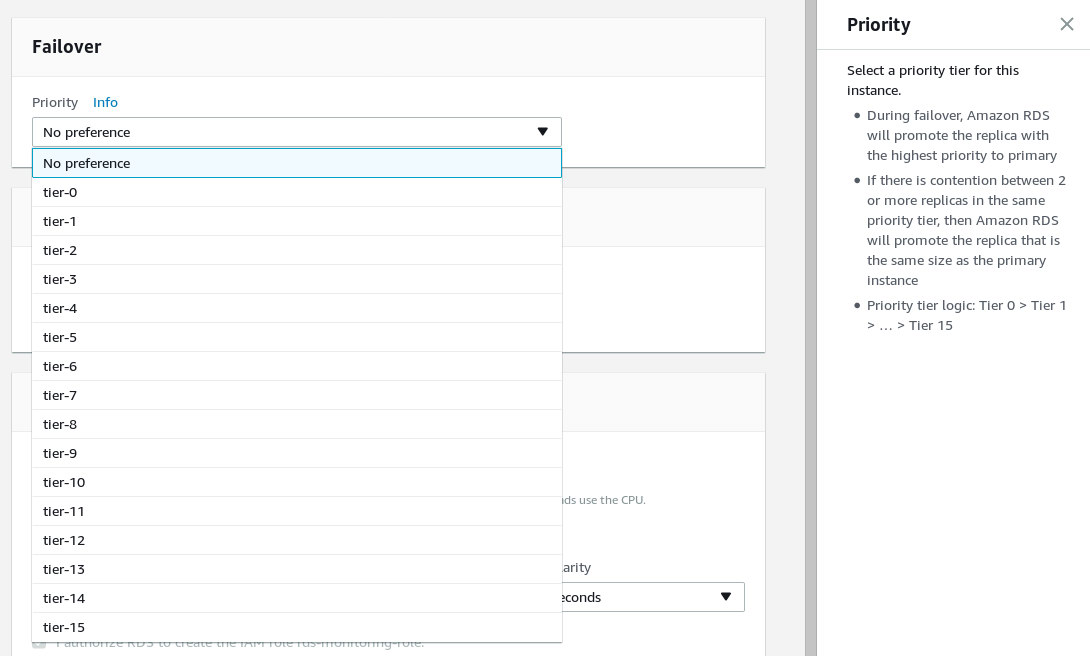 Photo description
Photo description -
Set the backup retention (maximum is 35 days).
 Aurora PostgreSQL wizard backup retention
Aurora PostgreSQL wizard backup retention -
Select the maintenance schedule. Automatic minor version upgrades are available, however it’s important to verify with AWS support whether or not their patch schedule can be expedited in case the PostgreSQL project releases any urgent updates. As an example, it took more than two months for AWS to push the 2018-05-10 updates.
 Aurora PostgreSQL wizard maintenance schedule
Aurora PostgreSQL wizard maintenance schedule -
If the database has been created successfully a link to instructions on how to connect to it will be displayed:
 Aurora PostgreSQL wizard setup complete
Aurora PostgreSQL wizard setup complete
Connecting to database
Review detailed instructions for available connections options, based on the infrastructure setup. In the simplest scenario the connection is done via a public EC2 instance.
Note: The client must be compatible with PostgreSQL 9.6.3 or above.
[root@ip-172-31-45-67 ~]# psql -U dbadmin -h c1.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com template1
Password for user dbadmin:
psql (9.6.8, server 9.6.3)
SSL connection (protocol: TLSv1.2, cipher: DHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.Monitoring
Amazon provides various metrics for monitoring the database, an example below showing instance metrics:
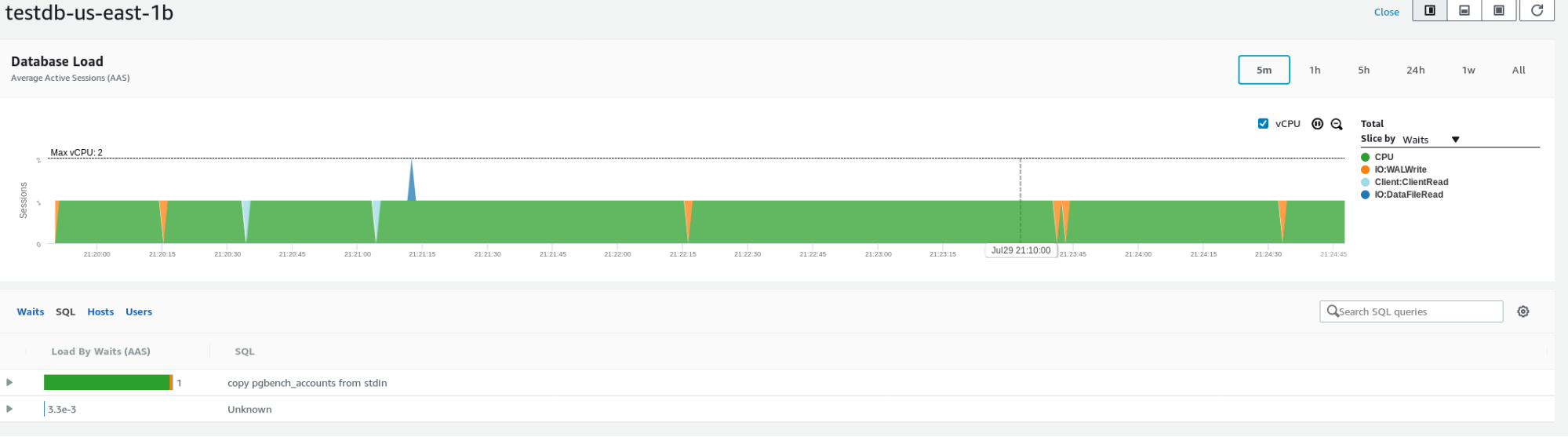
RDS for PostgreSQL
This is an offering allowing more granularity in terms of configuration choices. For example, in contrast to Aurora that uses a proprietary storage system, RDS offers configurable storage using EBS volumes that can be either General Purpose SSD (GP2), or Provisioned IOPS, or magnetic (not recommended).
In order to assist large installations, requiring customization not available in the Aurora offering, Amazon has recently released the Best practices recommendations, only available for RDS.
High availability must be configured manually (or automated using any of the known AWS tools) and it is recommended to setup a Multi-AZ deployment.
Replication is implemented using the PostgreSQL native replication.
There are some limits for PostgreSQL DB instances that need to be considered.
With the above notes in mind here’s a walkthrough for setting up an RDS PostgreSQL Multi-AZ environment:
-
From the RDS Management Console start the wizard
 RDS PostgreSQL wizard
RDS PostgreSQL wizard -
Choose between a production and a development setup.
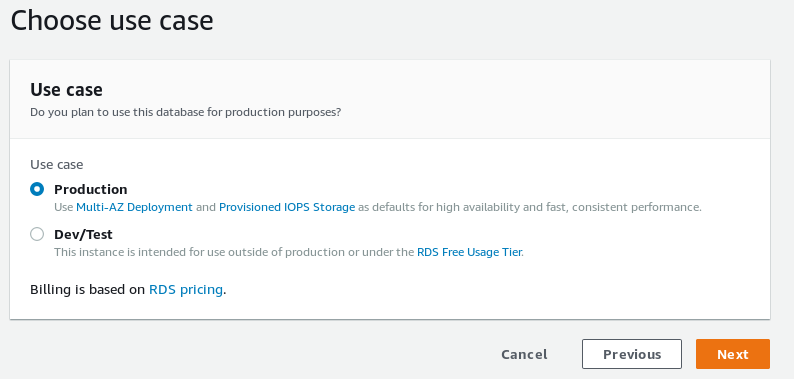 RDS PostgreSQL wizard database use case selection
RDS PostgreSQL wizard database use case selection -
Enter the details about your new database cluster.
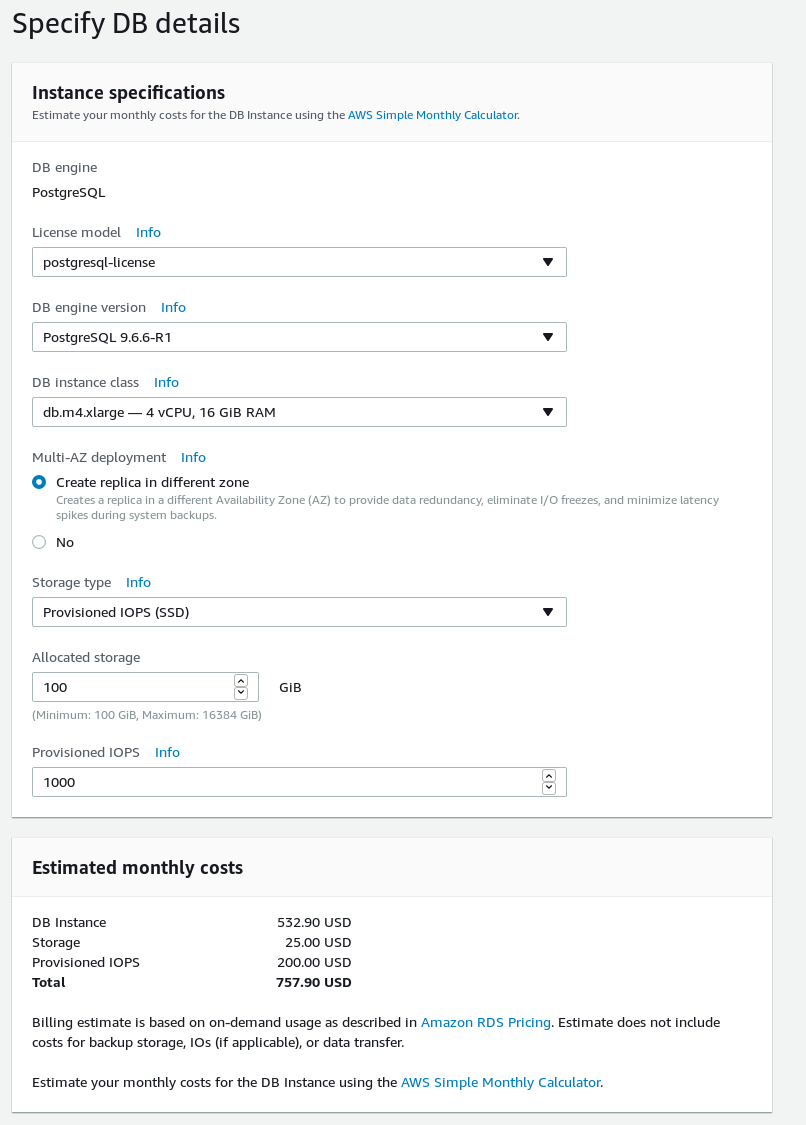 RDS PostgreSQL wizard DB details
RDS PostgreSQL wizard DB details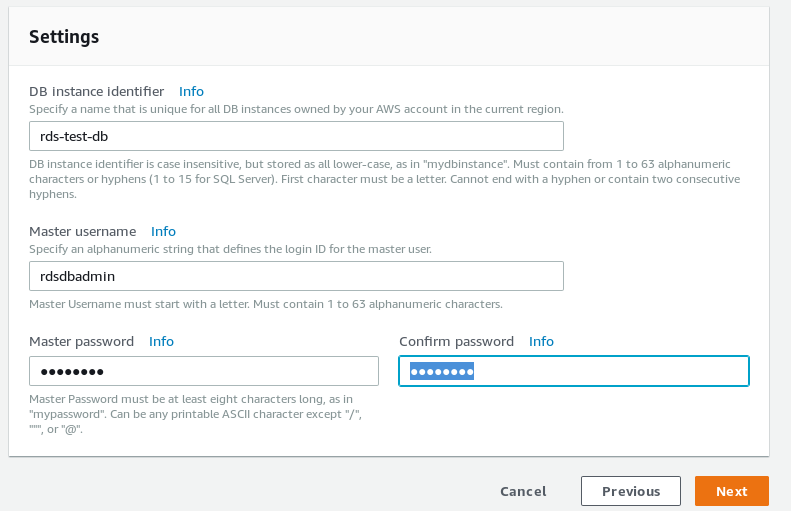 RDS PostgreSQL wizard database settings
RDS PostgreSQL wizard database settings -
On the next page setup networking, security, and maintenance schedule:
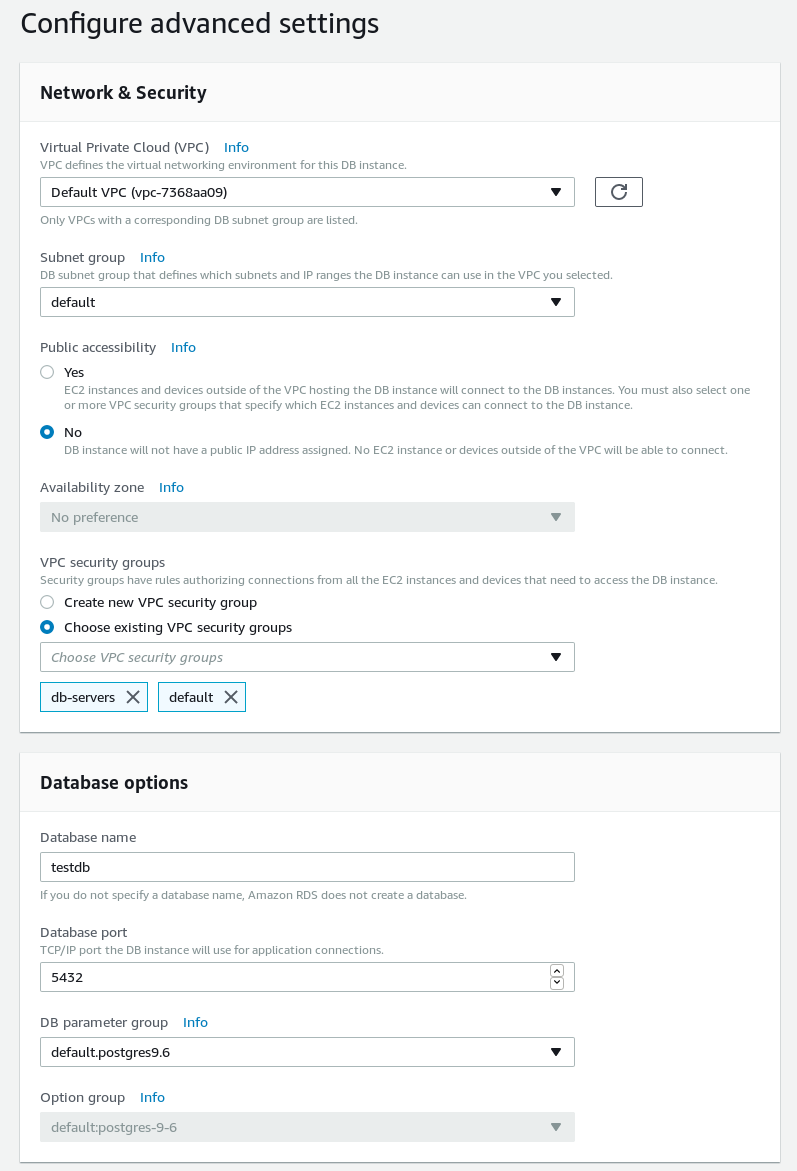 RDS PostgreSQL wizard advanced settings
RDS PostgreSQL wizard advanced settings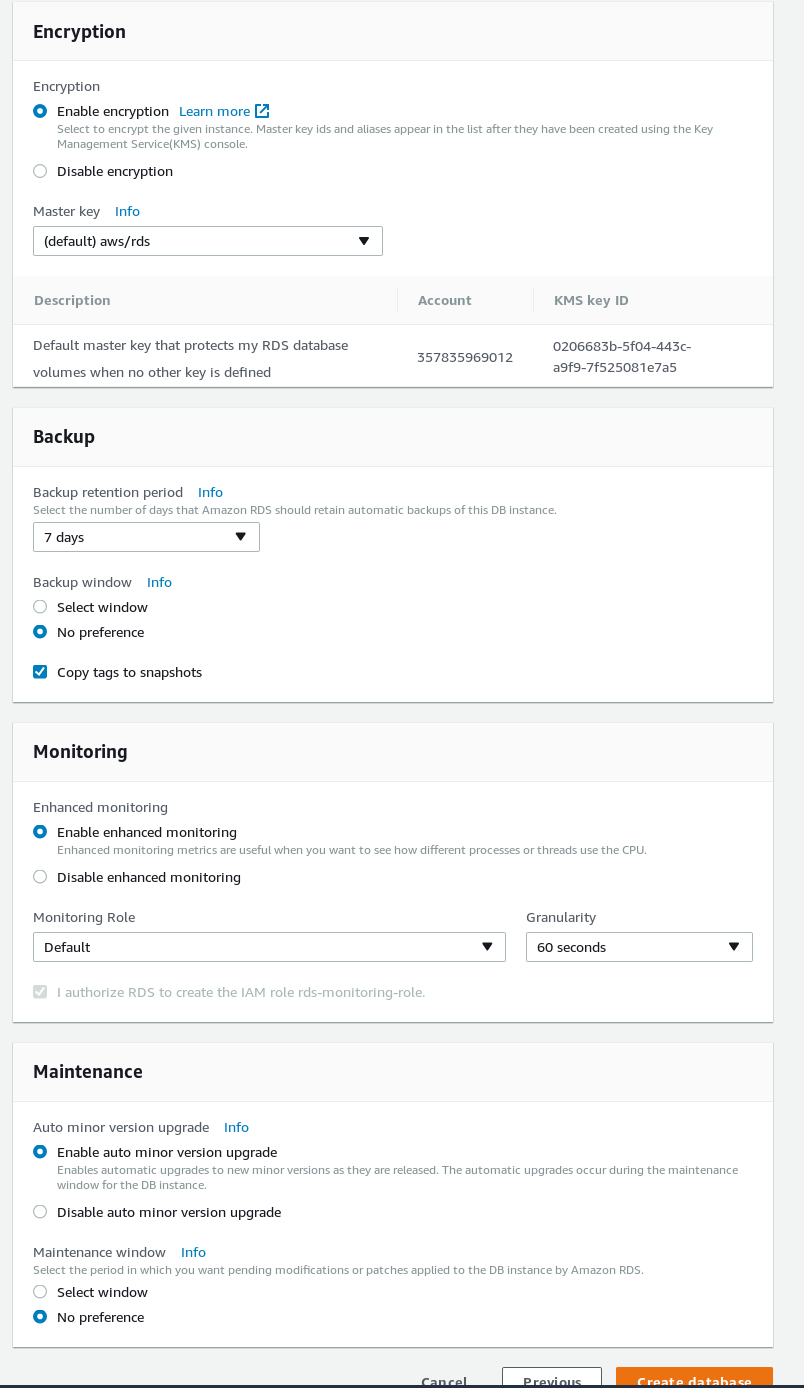 RDS PostgreSQL wizard security, and maintenance
RDS PostgreSQL wizard security, and maintenance
Conclusion
Amazon RDS Services for PostgreSQL include RDS PostgreSQL and Aurora PostgreSQL, both being managed DaaS offerings. Packed with plenty of features and solid backend storage they do have some limitations over the traditional setup, however, with careful planning these offerings can provide a well balanced cost-functionality ratio. Amazon RDS for PostgreSQL is targeted towards users requiring more options for configuring their environments, and is generally more expensive. Majority of users will benefit from starting up with Aurora PostgreSQL and work their way into more complex configurations.



