blog
Considerations for Building a Hybrid Cloud Database

On-prem setups are not uncommon nowadays – we still see businesses owning and managing their datacenters. Cloud is appealing, though – it comes with a promise of velocity and flexibility. You may wonder if it is possible to combine both cloud and on-prem environments. Sure, it definitely is. Let’s discuss how you can accomplish this and what are pros and cons of building a hybrid cloud database.
Connectivity
First of all, connectivity. You have to figure out how to connect your local database to the cloud infrastructure. This is, usually, quite easy to accomplish – most of the cloud providers have some sort of a connectivity option available. For Amazon Web Services this could be Amazon AWS Direct Connect. For Google Cloud there are options discussed on the following web site: https://cloud.google.com/hybrid-connectivity. There are also numerous other ways of implementing such connectivity as long as you manage the cloud instance (so, it is not some sort of a Database as a Service offering). In that case, you can setup a VPN on your own and use it to encrypt the data sent between your datacenter and the cloud environment. Open VPN is a great example of a tool that can be used to accomplish this.
If your cloud instances can be accessed via public IP (we do not really recommend that as databases always should be hidden behind the firewall), you can use SSL as a means of encrypting the data in transit. Pretty much all databases have an option to use SSL to encrypt the replication traffic, making it possible to use an open WAN connection without a need for a VPN.
Cost
You have to remember that the traffic that comes to your cloud instances does not come for free. All cloud providers charge for the incoming and outgoing traffic. Depending on the type of connectivity, you may also be charged for the VPN peering or the dedicated network capacity. You will have to account for this cost – it will depend on the amount of data that is replicating between your on-prem environment and the cloud part. We are talking about the replication but also backups, state transfers for Galera Cluster or InnoDB Cluster. Every bit of data will add to the total cost of owning the database spanning across your local and cloud environments. Of course, you also have to pay for the node itself, but we hope this is obvious enough and we won’t go into details here.
Latency
Latency in networking comes from two main sources. First, geographical distance. Sure, the packets are transferred with a speed of light but the speed of light is finite after all. For example, the distance between London and Singapore, as the crow flies, is a bit shy of 11 thousands kilometers. That alone translates to 36 milliseconds of latency. Of course, packets won’t take the shortest route as they have to use the infrastructure, undersea cables and so on. We can probably say (and we won’t be very wrong) that the latency that comes directly from the distance on such a route will be at least 50 milliseconds. Then we have to account for the second source of latency – hardware, which, to some extent, is also a function of distance. Every hop in the network, every router our packet has to pass through, adds latency. It is obvious when you think of it. Packets have to be processed, routing has to be done, some CPU cycles are required to handle all of the process of passing the packet to its destination using a proper route. Couple of milliseconds here and there and it adds up. Longer the route, more the hops and higher the latency routers generate. In our case it adds up to around 160 milliseconds: https://wondernetwork.com/pings/London/Singapore.
Sure, most likely you won’t be connecting from your on-prem network to some cloud infrastructure on the other side of the world but you still have to consider such a setup as something that will increase the latency of your intra-cluster connections even if we are talking about as small increase as by couple of milliseconds. This may or may not be an issue. Some clusters do not really care about latency, an example being clusters based on MySQL replication. As long as the latency isn’t going through the roof and starts to cause timeouts, you don’t really notice it much. On the other side of the spectrum we have clusters like MySQL NDB Cluster or Galera Cluster, where intra-cluster communication is critical to keep the cluster operational. On top of that, Galera Cluster, for example, is very sensitive to hotspots – rows that are being updated over and over again. The number of updates to a single row in Galera Cluster is a function of the latency. If network round trip time is 10 milliseconds, a given row can be updated 100 times per second. If the latency increases to 25 milliseconds, the number of changes per second is reduced to 40. Again, this may or may not be a problem but it is a fact you have to consider before adding a new node to your Galera Cluster. A node, that is located in a cloud environment.
Flexibility
Yes, cloud is flexible. It also (typically) comes with a vast set of features. Having a database node in the cloud might help you to utilize those features better. Do you want to export your data and load it into some analytical datastore that was made available by a given cloud provider? You may find the ETL process a way easier to implement while done in the cloud rather than when you want to export data from your on-prem environment. You can store your backups in object storage faster when you have the data already in the cloud compared to when you have to upload everything from your datacenter.
Velocity
As long as your workload allows you to do that, having a part of your database located in a cloud makes perfect sense when your load fluctuates. Provisioning new hardware in local environments tends to be a slow process. Of course, not all the time but that’s the average. You have to order new hardware, set it up, configure and so on. On the other hand, cloud can (again, not all the time but that’s the most common outcome) deliver you new instances in a matter of minutes. Those instances can be used to set up the databases and increase the total ability of your cluster to process queries. Sure, there are additional bits you have to account for – load balancers, provisioning databases and so on (that’s why ClusterControl is great platform that can help you to speed up your scaling processes) but the gist is, you don’t have to wait for your vendor to deliver hardware that you can then put in your racks, plug into your switch and install Linux distribution of your choosing.
Disaster Rrecovery
Disaster recovery is one of the most important aspects of database management. High availability and the ability to recover from disasters that would cause your datacenter to stop operating areis critical for mostthe majority of the production setups. Having database nodes located offsite can be a game changer for your disaster recovery procedures. First of all, you can have your backups taken and stored on both sides of your environment – you can create and store backups in your datacenter, but at the same time you can create and store backups in cloud. If your datacenter becomes unavailable, you may not be able to recover your backups. Unless you have backups stored offsite, this is a serious danger for your organization. Luckily, if you have a set of nodes in a public cloud that you are taking backups off, you are pretty well protected. Having the nodes themselves is great to cover the majority of the disaster cases – you can quickly spin up more nodes and scale your cluster to its original size. Worst case scenario, if your on-prem datacenter would become unavailable while you are dealing with a data loss scenario, having backups taken in the cloud part of your infrastructure ensures that you can recover even from such dire scenario.
All in all, a hybrid on-prem/cloud database may be a great way to enhance your database infrastructure, enable you to improve your ability to handle traffic spikes, increase the security of your data and many more.
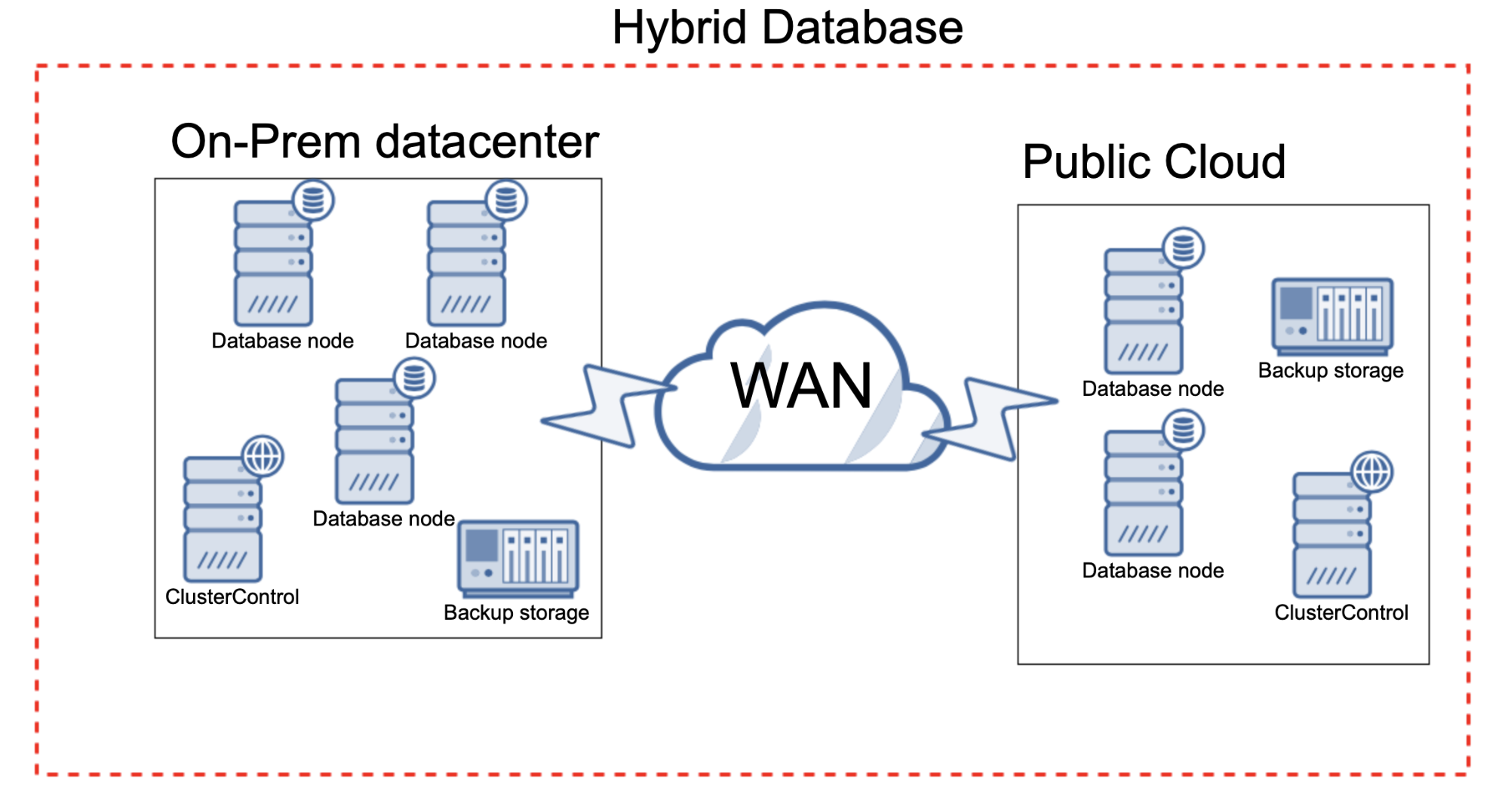
One of the great advantages of ClusterControl is that it does not care where your database nodes are located. If you have ClusterControl installed on-prem, as long as the connectivity is in place, you can use it to deploy and manage databases created both on-prem and in the cloud.
If you have experience with setups like this, we would love to hear about it in the comments below.



