blog
MySQL in the Cloud – Pros and Cons of Amazon RDS

Moving your data into a public cloud service is a big decision. All the major cloud vendors offer cloud database services, with Amazon RDS for MySQL being probably the most popular.
In this blog, we’ll have a close look at what it is, how it works, and compare its pros and cons.
RDS (Relational Database Service) is an Amazon Web Services offering. In short, it is a Database as a Service, where Amazon deploys and operates your database. It takes care of tasks like backup and patching the database software, as well as high availability. A few databases are supported by RDS, we are here mainly interested in MySQL though – Amazon supports MySQL and MariaDB. There is also Aurora, which is Amazon’s clone of MySQL, improved, especially in area of replication and high availability.
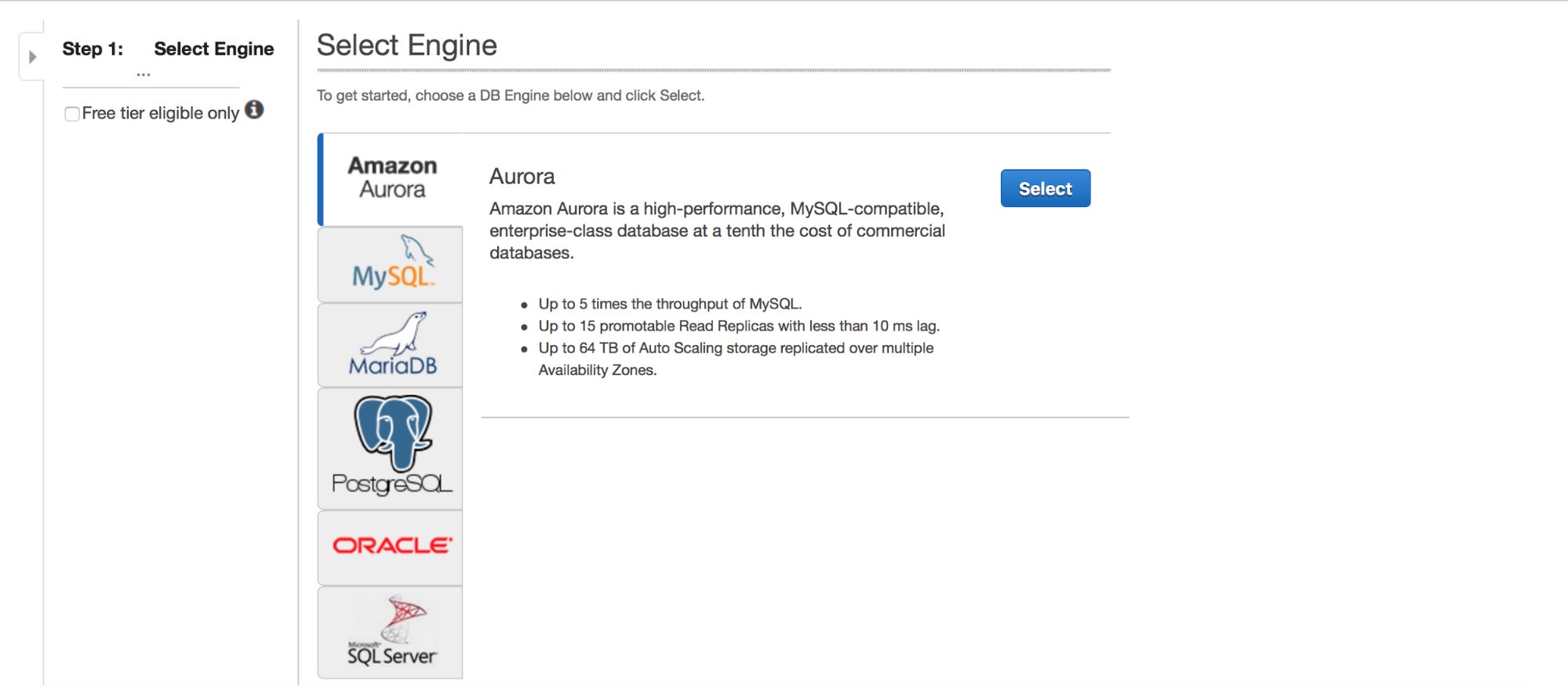
Deploying MySQL via RDS
Let’s take a look at the deployment of MySQL via RDS. We picked MySQL and then we are presented with couple of deployment patterns to pick from.
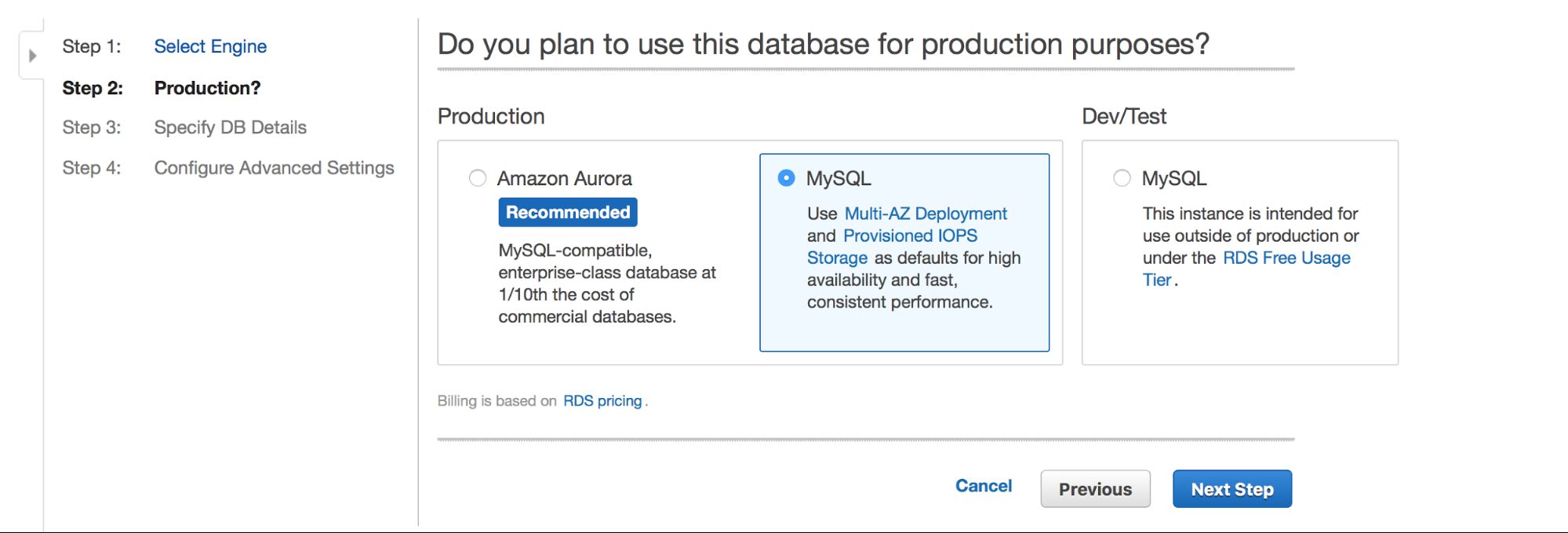
Main choice is – do we want to have high availability or not? Aurora is also promoted.
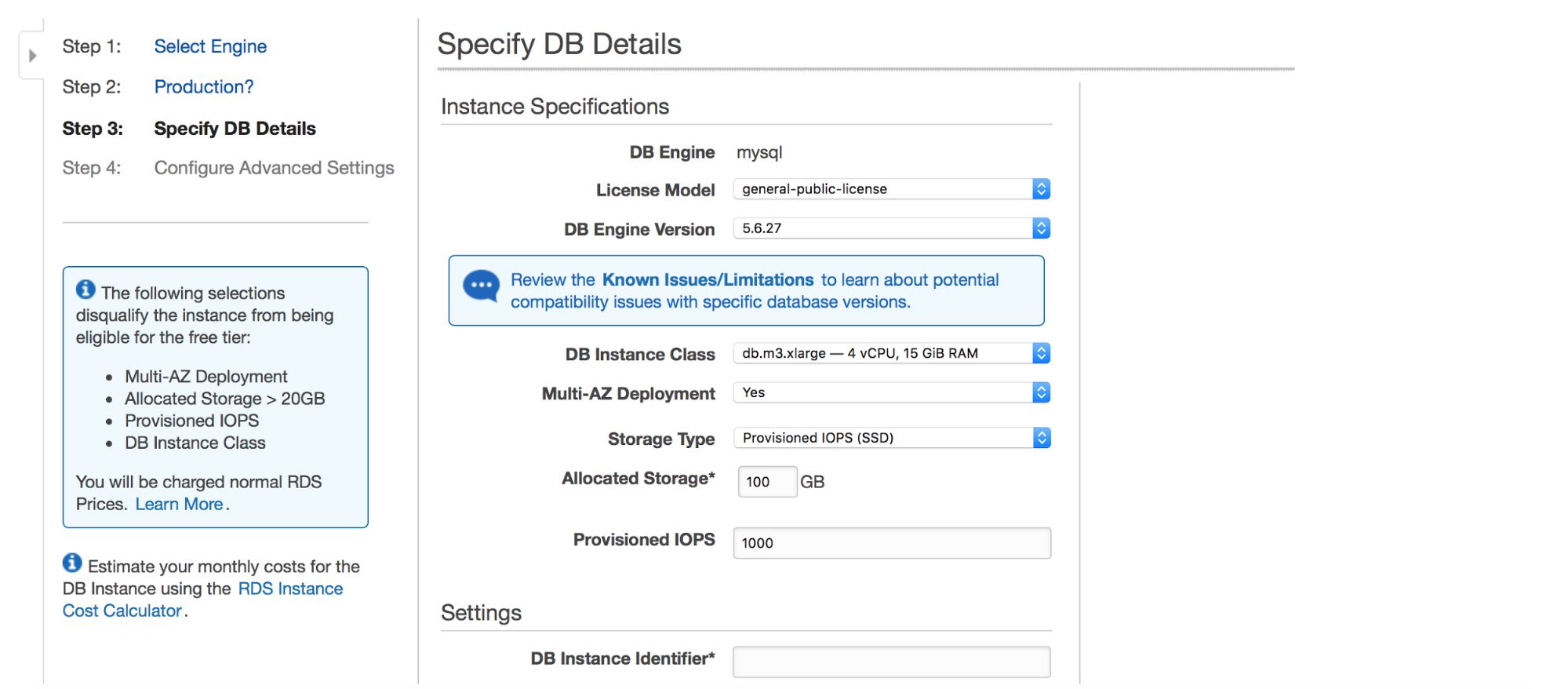
Next dialog box gives us some options to customize. You can pick one of many MySQL versions – several 5.5, 5.6 and 5.7 versions are available. Database instance – you can choose from typical instance sizes available in a given region.
Next option is a pretty important choice – do you want to use multi-AZ deployment or not? This is all about high availability. If you don’t want to use multi-AZ deployment, a single instance will be installed. In case of failure, a new one will be spun up and its data volume will be remounted to it. This process takes some time, during which your database will not be available. Of course, you can minimize this impact by using slaves and promoting one of them, but it’s not an automated process. If you want to have automated high availability, you should use multi-AZ deployment. What will happen is that two database instances will be created. One is visible to you. A second instance, in a separate availability zone, is not visible to the user. It will act as a shadow copy, ready to take over the traffic once the active node fails. It is still not a perfect solution as traffic has to be switched from the failed instance to the shadow one. In our tests, it took ~45s to perform a failover but, obviously, it may depend on instance size, I/O performance etc. But it’s much better than non-automated failover where only slaves are involved.
Finally, we have storage settings – type, size, PIOPS (where applicable) and database settings – identifier, user and password.
In the next step, a few more options are waiting for user input.
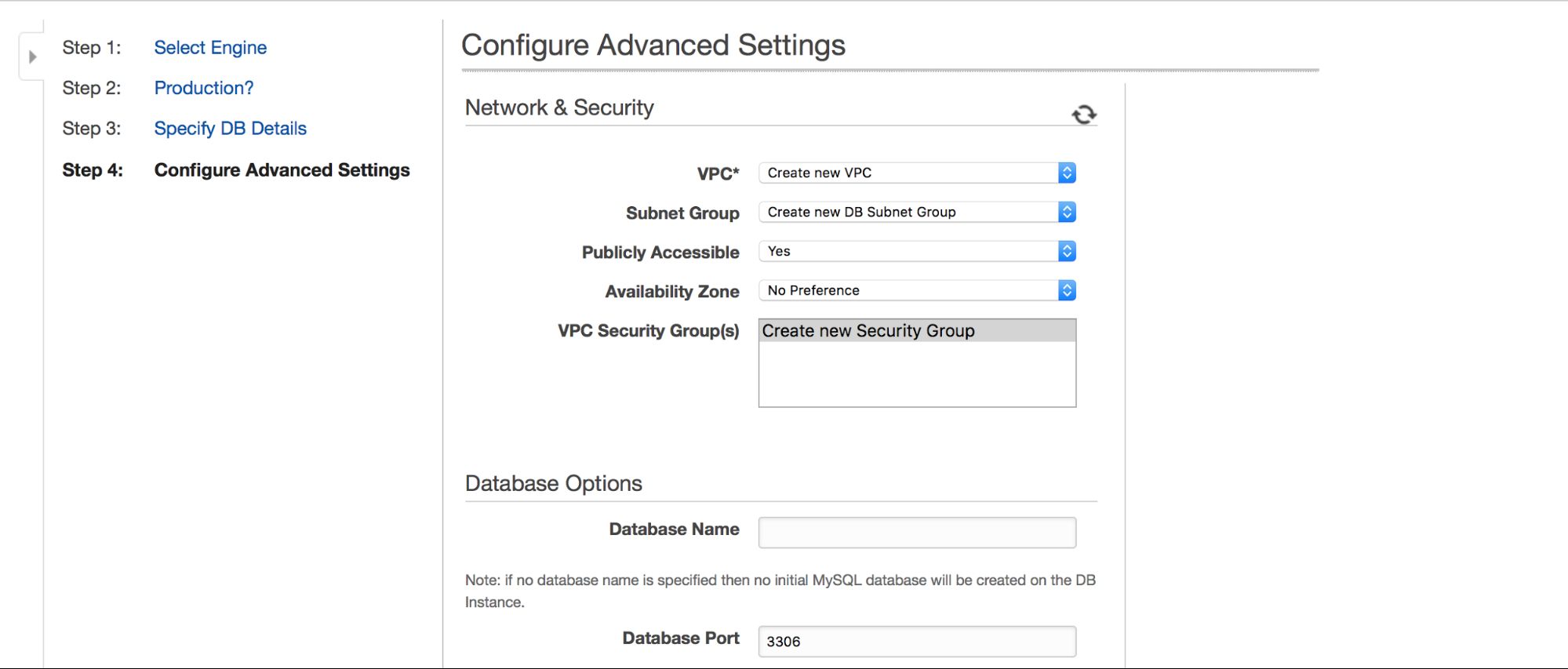
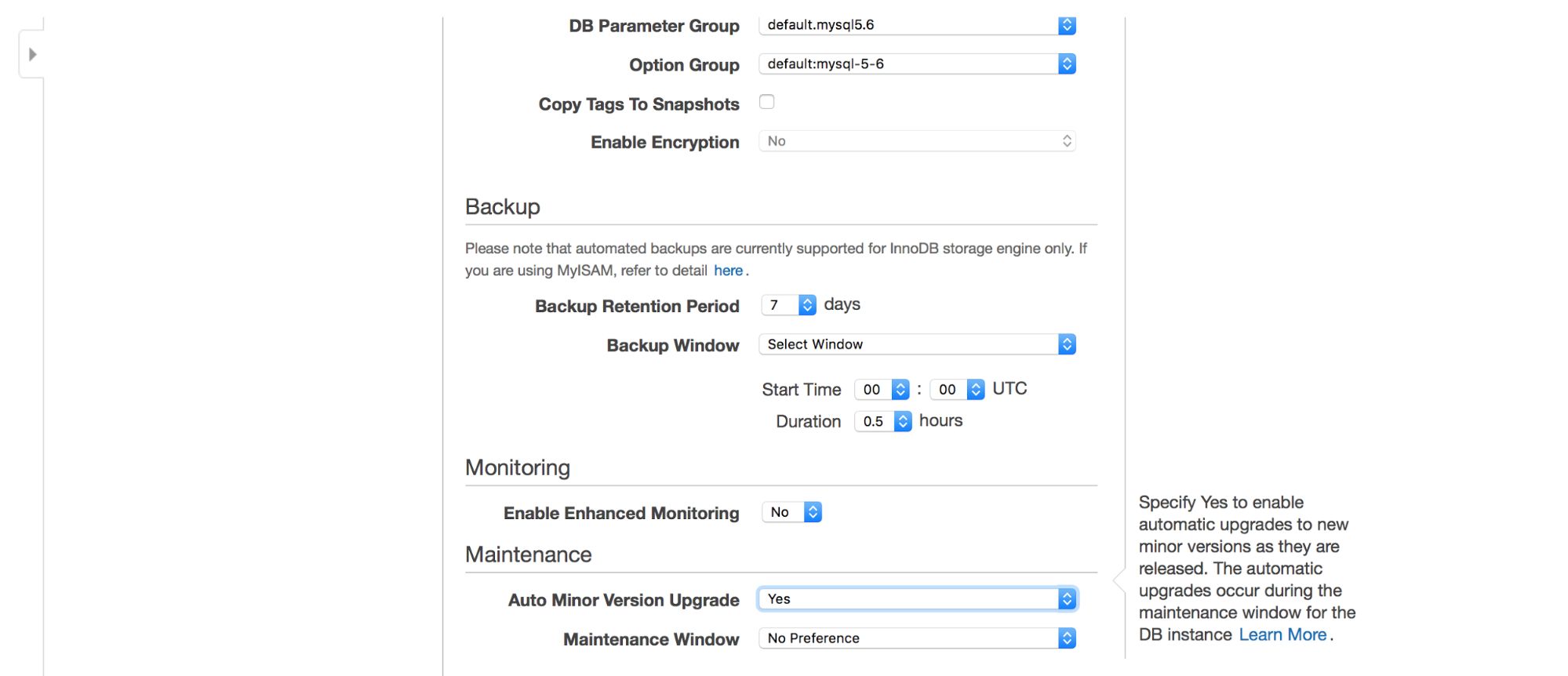
We can choose where the instance should be created: VPC, subnet, should it be publicly available or not (as in – should a public IP be assigned to the RDS instance), availability zone and VPC Security Group. Then, we have database options: first schema to be created, port, parameter and option groups, whether metadata tags should be included in snapshots or not, encryption settings.
Next, backup options – how long do you want to keep your backups? When would you like them taken? Similar setup is related to maintenances – sometimes Amazon administrators have to perform maintenance on your RDS instance – it will happen within a predefined window which you can set here. Please note, there is no option not to pick at least 30 minutes for the maintenance window, that’s why having multi-AZ instance on production is really important. Maintenance may result in node restart or lack of availability for some time. Without multi-AZ, you need to accept that downtime. With multi-AZ deployment, failover happens.
Finally, we have settings related to additional monitoring – do we want to have it enabled or not?
Managing RDS
In this chapter we will take a closer look at how to manage MySQL RDS. We will not go through every option available out there, but we’d like to highlight some of the features Amazon made available.
Snapshots
MySQL RDS uses EBS volumes as storage, so it can use EBS snapshots for different purposes. Backups, slaves – all based on snapshots. You can create snapshots manually or they can be taken automatically, when such need arises. It is important to keep in mind that EBS snapshots, in general (not only on RDS instances), adds some overhead to I/O operations. If you want to take a snapshot, expect your I/O performance to drop. Unless you use multi-AZ deployment, that is. In such case, the “shadow” instance will be used as a source of snapshots and no impact will be visible on the production instance.
Backups
Backups are based on snapshots. As mentioned above, you can define your backup schedule and retention when you create a new instance. Of course, you can edit those settings afterwards, through the “modify instance” option.
At any time you can restore a snapshot – you need to go to the snapshot section, pick the snapshot you want to restore, and you will be presented with a dialog similar to the one you’ve seen when you created a new instance. This is not a surprise as you can only restore a snapshot into a new instance – there is no way to restore it on one of the existing RDS instances. It may come as a surprise, but even in cloud environment, it may make sense to reuse hardware (and instances you already have). In a shared environment, performance of a single virtual instance may differ – you may prefer to stick to the performance profile that you are already familiar with. Unfortunately, it’s not possible in RDS.
Another option in RDS is point-in-time recovery – very important feature, a requirement for anyone who need to take good care of her data. Here things are more complex and less bright. For starters, it’s important to keep in mind that MySQL RDS hides binary logs from the user. You can change a couple of settings and list created binlogs, but you don’t have direct access to them – to make any operation, including using them for recovery, you can only use the UI or CLI. This limits your options to what Amazon allows you to do, and it allows you to restore your backup up to the latest “restorable time” which happens to be calculated in 5 minutes interval. So, if your data has been removed at 9:33a, you can restore it only up to the state at 9:30a. Point-in-time recovery works the same way as restoring snapshots – a new instance is created.
Scale-out, replication
MySQL RDS allows scale-out through adding new slaves. When a slave is created, a snapshot of the master is taken and it is used to create a new host. This part works pretty well. Unfortunately, you cannot create any more complex replication topology like one involving intermediate masters. You are not able to create a master – master setup, which leaves any HA in the hands of Amazon (and multi-AZ deployments). From what we can tell, there is no way to enable GTID (not that you could benefit from it as you don’t have any control over the replication, no CHANGE MASTER in RDS), only regular, old-fashioned binlog positions.
Lack of GTID makes it not feasible to use multithreaded replication – while it is possible to set a number of workers using RDS parameter groups, without GTID this is unusable. Main issue is that there is no way to locate a single binary log position in case of a crash – some workers could have been behind, some could be more advanced. If you use the latest applied event, you’ll lose data that is not yet applied by those “lagging” workers. If you will use the oldest event, you’ll most likely end up with “duplicate key” errors caused by events applied by those workers which are more advanced. Of course, there is a way to solve this problem but it is not trivial and it is time-consuming – definitely not something you could easily automate.
Users created on MySQL RDS don’t have SUPER privilege so operations, which are simple in stand-alone MySQL, are not trivial in RDS. Amazon decided to use stored procedures to empower the user to do some of those operations. From what we can tell, a number of potential issues are covered although it hasn’t always been the case – we remember when you couldn’t rotate to the next binary log on the master. A master crash + binlog corruption could render all slaves broken – now there is a procedure for that: rds_next_master_log.
A slave can be manually promoted to a master. This would allow you to create some sort of HA on top of multi-AZ mechanism (or bypassing it) but it has been made pointless by the fact that you cannot reslave any of existing slaves to the new master. Remember, you don’t have any control over the replication. This makes the whole exercise futile – unless your master can accommodate all of your traffic. After promoting a new master, you are not able to failover to it because it does not have any slaves to handle your load. Spinning up new slaves will take time as EBS snapshots have to be created first and this may take hours. Then, you need to warm up the infrastructure before you can put load on it.
Lack of SUPER Privilege
As we stated earlier, RDS does not grant users SUPER privilege and this becomes annoying for someone who is used to having it on MySQL. Take it for granted that, in the first weeks, you will learn how often it is required to do things that you do rather frequently – such as killing queries or operating the performance schema. In RDS, you will have to stick to predefined list of stored procedures and use them instead of doing things directly. You can list all of them using the following query:
SELECT specific_name FROM information_schema.routines;As with replication, a number of tasks are covered but if you ended up in a situation which is not yet covered, then you’re out of luck.
Interoperability and Hybrid Cloud Setups
This is another area where RDS is lacking flexibility. Let’s say you want to build a mixed cloud/on-premises setup – you have a RDS infrastructure and you’d like to create a couple of slaves on premises. The main problem you’ll be facing is that there is no way to move data out of RDS except to take a logical dump. You can take snapshots of RDS data but you don’t have access to them and you cannot move them away from AWS. You also don’t have physical access to the instance to use xtrabackup, rsync or even cp. The only option for you is to use mysqldump, mydumper or similar tools. This adds complexity (character set and collation settings have a potential to cause problems) and is time-consuming (it takes long time to dump and load data using logical backup tools).
It is possible to setup replication between RDS and an external instance (in both ways, so migrating data into RDS is also possible), but it can be a very time-consuming process.
On the other hand, if you want to stay within an RDS environment and span your infrastructure across the atlantic or from east to west coast US, RDS allows you to do that – you can easily pick a region when you create a new slave.
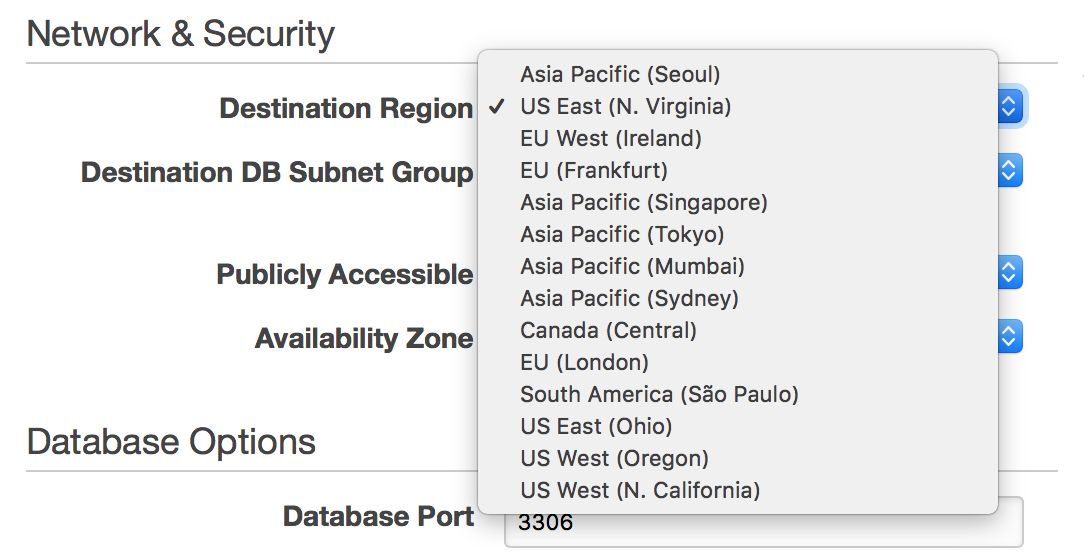
Unfortunately, if you’d like to move your master from one region to the other, this is virtually not possible without downtime – unless your single node can handle all of your traffic.
Security
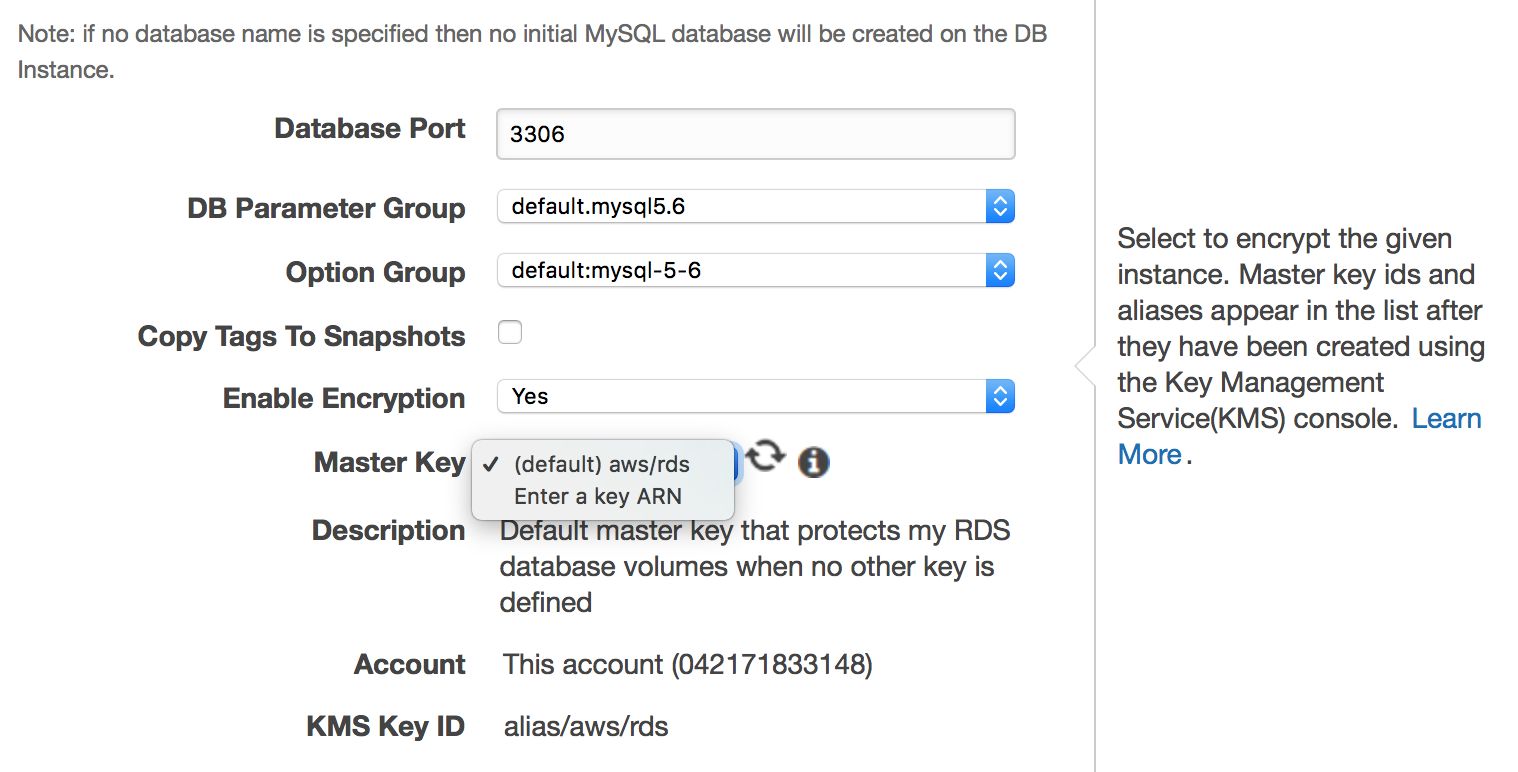
While MySQL RDS is a managed service, not every aspect related to security is taken care of by Amazon’s engineers. Amazon calls it “Shared Responsibility Model”. In short, Amazon takes care of the security of the network and storage layer (so that data is transferred in a secure way), operating system (patches, security fixes). On the other hand, user has to take care of the rest of the security model. Make sure traffic to and from RDS instance is limited within VPC, ensure that database level authentication is done right (no password-less MySQL user accounts), verify that API security is ensured (AMI’s are set correctly and with minimal required privileges). User should also take care of firewall settings (security groups) to minimize exposure of RDS and the VPC it’s in to external networks. It’s also the user’s responsibility to implement data at rest encryption – either on the application level or on the database level, by creating an encrypted RDS instance in the first place.
Database level encryption can be enabled only on the instance creation, you cannot encrypt an existing, already running database.
RDS limitations
If you plan to use RDS or if you are already using it, you need to be aware of limitations that come with MySQL RDS.
Lack of SUPER privilege can be, as we mentioned, very annoying. While stored procedures take care of a number of operations, it is a learning curve as you need to learn to do things in a different way. Lack of SUPER privilege can also create problems in using external monitoring and trending tools – there are still some tools which may require this priviledge for some part of its functionality.
Lack of direct access to MySQL data directory and logs makes it harder to perform actions which involves them. It happens every now and then that a DBA needs to parse binary logs or tail error, slow query or general log. While it is possible to access those logs on RDS, it is more cumbersome than doing whatever you need by logging into shell on the MySQL host. Downloading them locally also takes some time and adds additional latency to whatever you do.
Lack of control over replication topology, high availability only in multi-AZ deployments. Given that you don’t have a control over the replication, you cannot implement any kind of high availability mechanism into your database layer. It doesn’t matter that you have several slaves, you cannot use some of them as master candidates because even if you promote a slave to a master, there is no way to reslave the remaining slaves off this new master. This forces users to use multi-AZ deployments and increase costs (the “shadow” instance doesn’t come free, user has to pay for it).
Reduced availability through planned downtime. When deploying an RDS instance, you are forced to pick a weekly time window of 30 minutes during which maintenance operations may be executed on your RDS instance. On the one hand, this is understandable as RDS is a Database as a Service so hardware and software upgrades of your RDS instances are managed by AWS engineers. On the other hand, this reduce your availability because you cannot prevent your master database from going down for the duration of the maintenance period. Again, in this case using multi-AZ setup increases availability as changes happen first on the shadow instance and then failover is executed. Failover itself, though, is not transparent so, one way or the other, you lose the uptime. This forces you to design your app with unexpected MySQL master failures in mind. Not that it’s a bad design pattern – databases can crash at any time and your application should be built in a way it can withstand even the most dire scenario. It’s just that with RDS, you have limited options for high availability.
Reduced options for high availability implementation. Given the lack of flexibility in the replication topology management, the only feasible high availability method is multi-AZ deployment. This method is good but there are tools for MySQL replication which would minimize the downtime even further. For example, MHA or ClusterControl when used in connection with ProxySQL can deliver (under some conditions like lack of long running transactions) transparent failover process for the application. While on RDS, you won’t be able to use this method.
Reduced insight into performance of your database. While you can get metrics from MySQL itself, sometimes it’s just not enough to get a full 10k feet view of the situation. At some point, the majority of users will have to deal with really weird issues caused by faulty hardware or faulty infrastructure – lost network packets, abruptly terminated connections or unexpectedly high CPU utilization. When you have an access to your MySQL host, you can leverage lots of tools that help you to diagnose state of a Linux server. When using RDS, you are limited to what metrics are available in Cloudwatch, Amazon’s monitoring and trending tool. Any more detailed diagnosis require contacting support and asking them to check and fix the problem. This may be quick but it also can be a very long process with a lot of back and forth email communication.
Vendor lock-in caused by complex and time-consuming process of getting data out of the MySQL RDS. RDS doesn’t grant access to MySQL data directory so there is no way to utilize industry standard tools like xtrabackup to move data in a binary way. On the other hand, the RDS under the hood is a MySQL maintained by Amazon, it is hard to tell if it is 100% compatible with upstream or not. RDS is only available on AWS, so you would not be able to do a hybrid setup.
Summary
MySQL RDS has both strengths and weaknesses. This is a very good tool for those who’d like to focus on the application without having to worry about operating the database. You deploy a database and start issuing queries. No need for building backup scripts or setting up monitoring solution because it’s already done by AWS engineers – all you need to do is to use it.
There is also a dark side of the MySQL RDS. Lack of options to build more complex setups and scaling outside of just adding more slaves. Lack of support for better high availability than what’s proposed under multi-AZ deployments. Cumbersome access to MySQL logs. Lack of direct access to MySQL data directory and lack of support for physical backups, which makes it hard to move the data out of the RDS instance.
To sum it up, RDS may work fine for you if you value ease of use over detailed control of the database. You need to keep in mind that, at some point in the future, you may outgrow MySQL RDS. We are not necessarily talking here about performance only. It’s more about your organization’s needs for more complex replication topology or a need to have better insight into database operations to deal quickly with different issues that arise from time to time. In that case, if your dataset already has grown in size, you may find it tricky to move out of the RDS. Before making any decision to move your data into RDS, information managers must consider their organization’s requirements and constraints in specific areas.
In next couple of blog posts we will show you how to take your data out of the RDS into a separate location. We will discuss both migration to EC2 and to on-premises infrastructure.



