blog
My DBA is Sick – Database Failover Tips for SysAdmins

In case of a database failure, the best case scenario is that you have a good Disaster Recovery Plan (DRP) and a highly available environment with an automatic failover process in place. But what happens if your best efforts fail for some unexpected reason? What if you need to perform a manual failover?
In this blog, we’ll share some recommendations to follow if you find yourself without a DBA and need to manually failover your database.
Verification Checks
Before performing any change, you must first verify some basic things to avoid new issues after the failover process.
Replication Status
It could be possible that at the time of failure, the replica is not up-to-date due to a network failure, high load, or another issue, so you need to make sure your replica has all (or almost all) the information. If you have more than one replication node, you should also check which one is the most advanced and choose it to failover.
Let’s check the replication status in a MariaDB Server.
MariaDB [(none)]> SHOW SLAVE STATUSG
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.100.110
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000014
Read_Master_Log_Pos: 339
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 635
Relay_Master_Log_File: binlog.000014
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_Errno: 0
Skip_Counter: 0
Exec_Master_Log_Pos: 339
Relay_Log_Space: 938
Until_Condition: None
Until_Log_Pos: 0
Master_SSL_Allowed: No
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_SQL_Errno: 0
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3001
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3001-20
Parallel_Mode: conservative
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0
1 row in set (0.000 sec)In case of PostgreSQL, it’s a bit different as you need to check the WALs status and compare the applied to the fetched ones.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Credentials
Before running the failover process, you must check if your applications/users will be able to access your new primary node with the current credentials. If you are not replicating your database users, perhaps the credentials changed, so you will need to update them in the replication nodes before any changes.
You can query the user table in the MySQL database to check the user credentials in a MariaDB/MySQL Server:
MariaDB [(none)]> SELECT Host,User,Password FROM mysql.user;
+-----------------+--------------+-------------------------------------------+
| Host | User | Password |
+-----------------+--------------+-------------------------------------------+
| localhost | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | mysql | invalid |
| 127.0.0.1 | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.100 | cmon | *F80B5EE41D1FB1FA67D83E96FCB1638ABCFB86E2 |
| 127.0.0.1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| ::1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.112 | user1 | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 127.0.0.1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| ::1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 192.168.100.110 | rpl_user | *EEA7B018B16E0201270B3CDC0AF8FC335048DC63 |
+-----------------+--------------+-------------------------------------------+
12 rows in set (0.001 sec)In PostgreSQL, you can use the ‘\du’ command to know the roles, and you must also check the pg_hba.conf configuration file to manage the user access (not credentials), as seen below:
postgres=# du
List of roles
Role name | Attributes | Member of
------------------+------------------------------------------------------------+-----------
admindb | Superuser, Create role, Create DB | {}
cmon_replication | Replication | {}
cmonexporter | | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
s9smysqlchk | Superuser, Create role, Create DB | {}And pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD
host replication cmon_replication localhost md5
host replication cmon_replication 127.0.0.1/32 md5
host all s9smysqlchk localhost md5
host all s9smysqlchk 127.0.0.1/32 md5
local all all trust
host all all 127.0.0.1/32 trustNetwork/Firewall Access
The credentials are not the only possible issue with accessing your new primary server. If the node is in another data center, or you have a local firewall to filter traffic, you must check if you are allowed to access it or even if you have the network route to reach the new primary node.
Let’s use iptables to allow traffic from the network 167.124.57.0/24 and check the current rules after adding it:
$ iptables -A INPUT -s 167.124.57.0/24 -m state --state NEW -j ACCEPT
$ iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT all -- 167.124.57.0/24 0.0.0.0/0 state NEW
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destinationNext, let’s suppose your new primary node is in the network 10.0.0.0/24, your application server is in 192.168.100.0/24, and you can reach the remote network using 192.168.100.100. So in your application server, add the corresponding route:
$ route add -net 10.0.0.0/24 gw 192.168.100.100
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.100.1 0.0.0.0 UG 0 0 0 eth0
10.0.0.0 192.168.100.100 255.255.255.0 UG 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1027 0 0 eth0
192.168.100.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0Action Points
After checking all the mentioned points, you should be ready to take the steps to failover your database.
New IP Address
As you promote a replica, the primary IP address will change, so you need to change it in your application or client access.
Using a Load Balancer is an excellent way to avoid this issue/change. After the failover process, the Load Balancer will detect the old primary node as offline and, depending on the configuration, send the traffic to the new one to write on it, so you don’t need to change anything in your application.
Here’s an example for an HAProxy configuration:
listen haproxy_5433
bind *:5433
mode tcp
timeout client 10800s
timeout server 10800s
balance leastconn
option tcp-check
server 192.168.100.119 192.168.100.119:5432 check
server 192.168.100.120 192.168.100.120:5432 checkIn this case, if one node is down, HAProxy won’t send traffic there and will instead only send traffic to the available node.
Reconfigure the Slave Nodes
If you have more than one replica, you must reconfigure the rest of the replication nodes to connect to the new primary after promoting one of the replicas. This could be a time-consuming task, depending on the number of nodes.
Verify & Configure the Backups
After you have everything in place (new primary promoted, replica reconfigured, and application is writing in the new primary node), it’s important to take the necessary actions to prevent a new issue. To do that, you must verify and configure your backups.
You most likely had a backup policy running before the incident (if not, you need to have it for sure), so you will need to check if the backups are still running or will run correctly in the new topology. It could be possible that you had the backups running on the old primary node or using the replication node that is now the primary node, so you need to check to ensure your backup policy will still work after the changes.
Database Monitoring
When performing a failover process, monitoring is a must before, during, and after. Database monitoring can prevent an issue before it gets worse, detect an unexpected problem during the failover, or alert if something goes wrong after. For example, you must monitor if your application can access your new primary node by checking the number of active connections.
Key Metrics to Monitor
Here are the most important metrics to take into account while monitoring:
- Replication Lag
- Replication Status
- Number of connections
- Network usage/errors
- Server load (CPU, Memory, Disk)
- Database and system logs
Rollback
Of course, if something goes wrong, you must be able to roll back. Blocking traffic to the old node and keeping it as isolated as possible can be a good strategy for this. In case you need to roll back, you will have the old node available.
Suppose the rollback is after several minutes, depending on the traffic. In that case, you will probably need to insert data of these minutes in the old primary, so make sure you also have your temporary primary node available and isolated to take this information and apply it back.
Automate Failover Process with ClusterControl
Seeing all these tasks necessary to perform a failover, you might be interested in finding a way to automate it and avoid all this manual work. For this, you can take advantage of some of the features that ClusterControl can offer for different database technologies, like auto-recovery, backups, user management, and monitoring, among other features, all from a single UI.
With ClusterControl, you can verify the replication status and lag, create or modify credentials, know the network and host status, and even more.
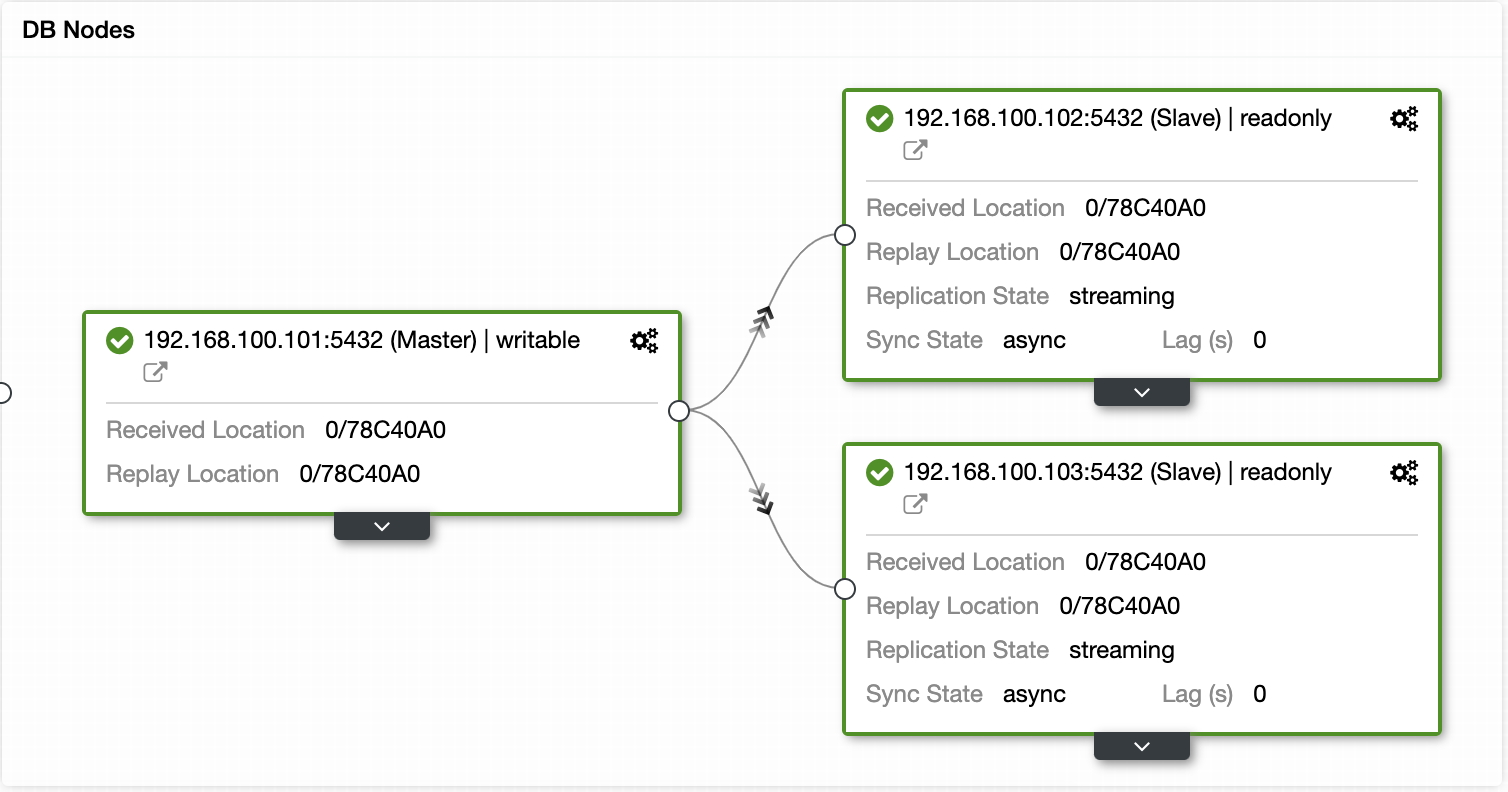
You can also perform different cluster and node actions, like promote slave, restart database and server, add or remove database nodes, add or remove load balancer nodes, rebuild a replication slave, and more.
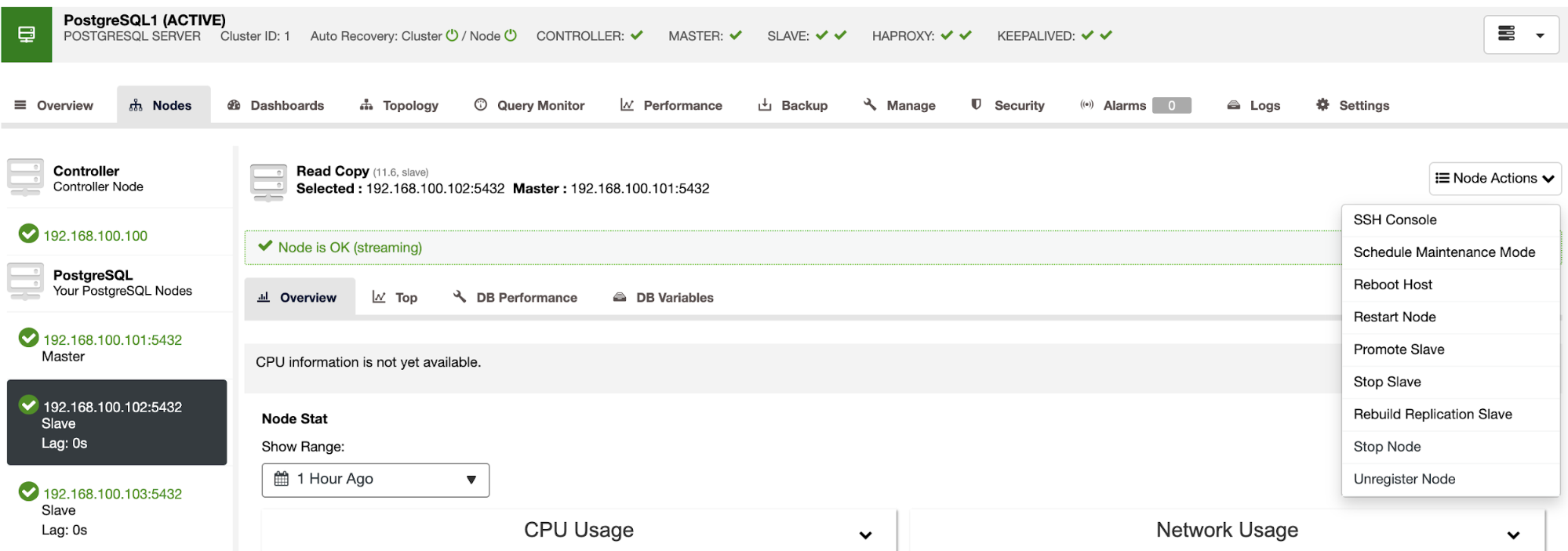
Using these actions, you can also roll back your failover if needed by rebuilding and promoting the previous master.
ClusterControl also offers monitoring and alerting services that help you know what is happening or if something happened previously.
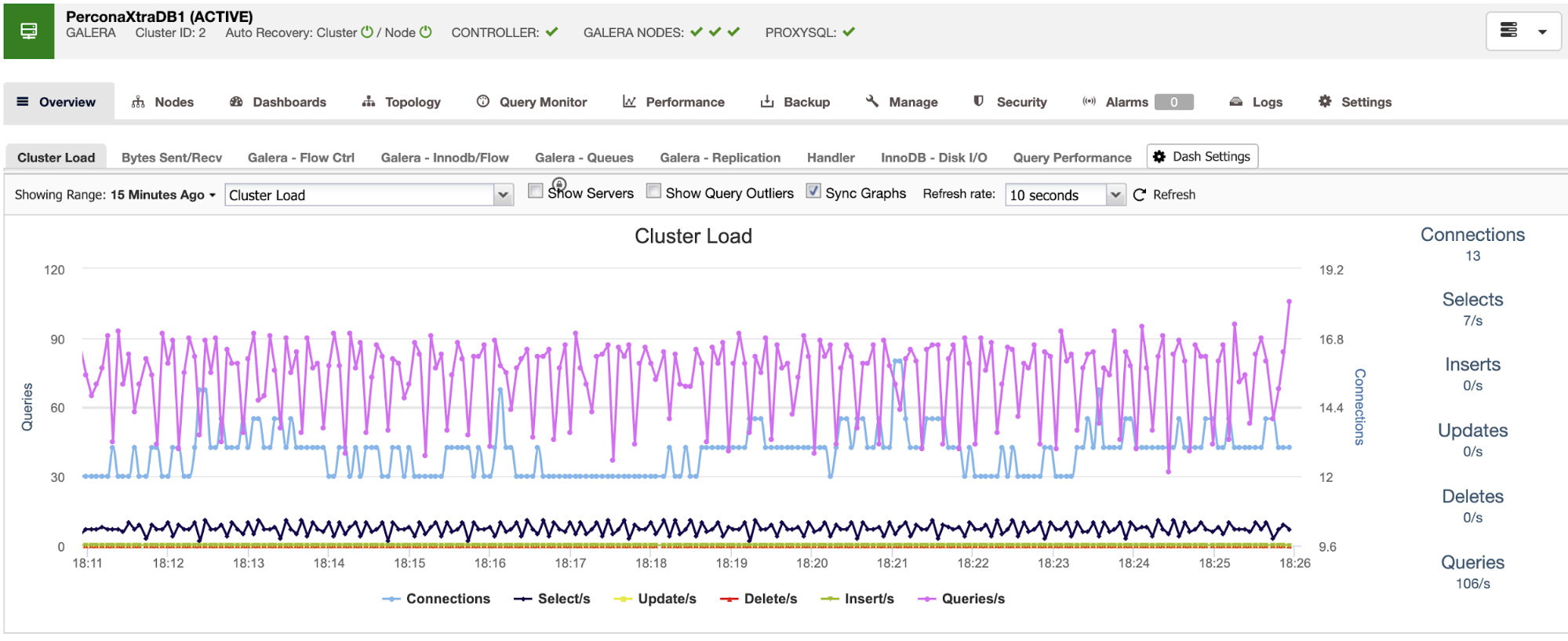
You can also use the dashboard section for a more user-friendly view of the status of your systems.
Wrapping Up
So if you find yourself with a primary database failure, you’ll need to have all necessary information in place in order to take appropriate action ASAP. Having a good Disaster Recovery Plan is key to keeping your system running at all (or almost all) times. Your Disaster Recovery Plan should be well-documented and include a failover process with an acceptable Recovery Time Objective (RTO) for your company.
If you plan to continue with the manual route, we have failover best practices and resources available for PostgreSQL, MySQL, and MariaDB.
If you’re looking for a way to automate the failover process, take a closer look at how ClusterControl performs automatic recovery and failover.
To keep up to date with all ClusterControl news, follow us on Twitter and LinkedIn and subscribe to our newsletter.



