blog
Introduction to Failover for MySQL Replication – the 101 Blog

Dealing with MySQL replication? Chances are that you chose that setup to achieve high availability. After all, it is the most popular HA solution for MySQL. But guess what absolutely does not qualify as ‘being highly available’ – that’s right, a failed or unavailable master node.
That’s one aspect of a MySQL replication setup that you need to make sure you account for: the health and status of your master.
So, what happens if something goes wrong with your master?
That’s when it becomes critical to have a fully tested failover plan in place.
In this article, you’ll learn exactly what failover means within the context of MySQL replication. You’ll also get a step-by-step walkthrough on how the failover process works from testing the health of a master node to ensuring the application topology recognizes the failover has taken place. Finally, we’ll show you how a tool like ClusterControl can help you automate the failover process.
Let’s dive in.
What is failover for MySQL replication?
Failover within a MySQL replication cluster is the process of promoting a replica to become a master after the old master has failed.
OK, so why does this need to happen?
Keep in mind that MySQL replication is a collective of nodes, with each of them serving one role at a time. Within the collective, a node is either a master or a replica.
There is only one master node at a given time. This node receives write traffic and it replicates writes to its replicas.
As you can imagine, being a single point of entry for data into the replication cluster, the master node is quite important. So, what would happen if it fails and becomes unavailable?
This is a serious condition for a replication cluster. A failed master means that the cluster cannot accept any writes at a given moment.
As you may expect, one of the replicas will have to take over the master’s tasks and start accepting writes. The rest of the replication topology may also have to change – the remaining replicas should change their master from the old failed node to the newly chosen one. This process of “promoting” a replica to become the new master is called “failover.”
Failover vs. switchover
The most important difference between “failover” and “switchover” is the state of the old master.
When a failover is performed, the old master is no longer reachable. It may have crashed, it may have suffered a network partitioning. For whatever reason, it cannot be used and its state is typically unknown.
On the other hand, “switchover” happens when the user manually triggers the promotion of a replica while the old master is still alive and working. In this case, the old master typically becomes a replica to the new master.
This can have serious consequences. For example, if a master is unreachable, it may mean that some of the data has not yet been sent to the slaves (unless semi-synchronous replication was used). Some of the data may have been corrupted or only partially sent.
There are mechanisms in place to avoid propagating such corruption on slaves but the point is that some of the data may be lost in the process. On the other hand, while performing a switchover, the old master is available and data consistency is maintained.
How does the failover process work in MySQL replication?
The most important thing to remember when you’re working with MySQL is that something needs to do the failover. This can be a tool, a set of scripts written by the administrator, or it can be done by hand.
Setting things up correctly with a tool or a script can save you a lot of time (and panic) when the inevitable happens. But regardless of how you decide to tackle failover, there are a few general steps that will always need to be covered.
Here’s how the failover process usually works:
1. Master crash is detected
For starters, a master has to crash before the failover will be performed. Once it is not available, it’s failover time.
The first thing to establish is how the health of your master is tested. Is it tested from one location or are tests distributed? Does the failover management software just attempt to connect to the master or does it implement more advanced verifications before master failure is declared?
Let’s imagine the following topology:
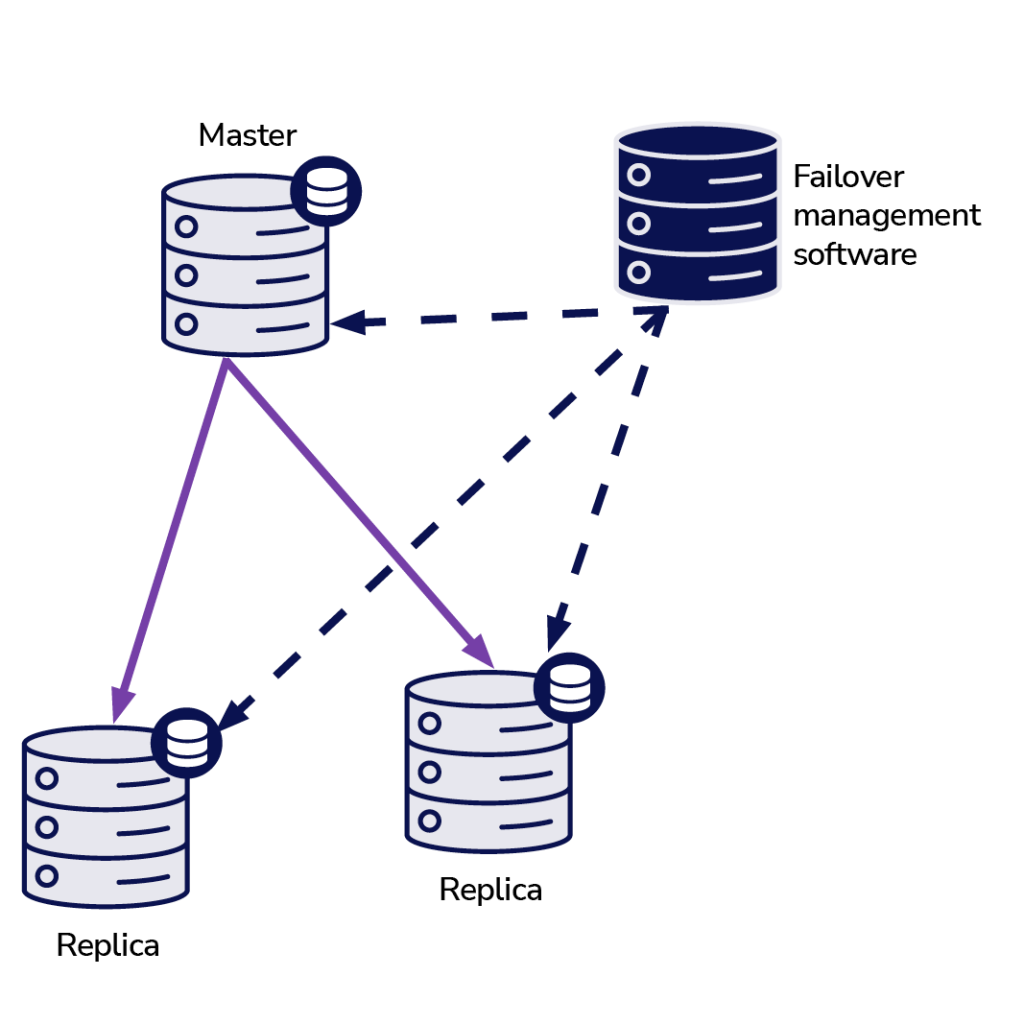
We have a master and two replicas. We also have a failover management software located on some external host. What would happen if a network connection between the host with failover software and the master failed?
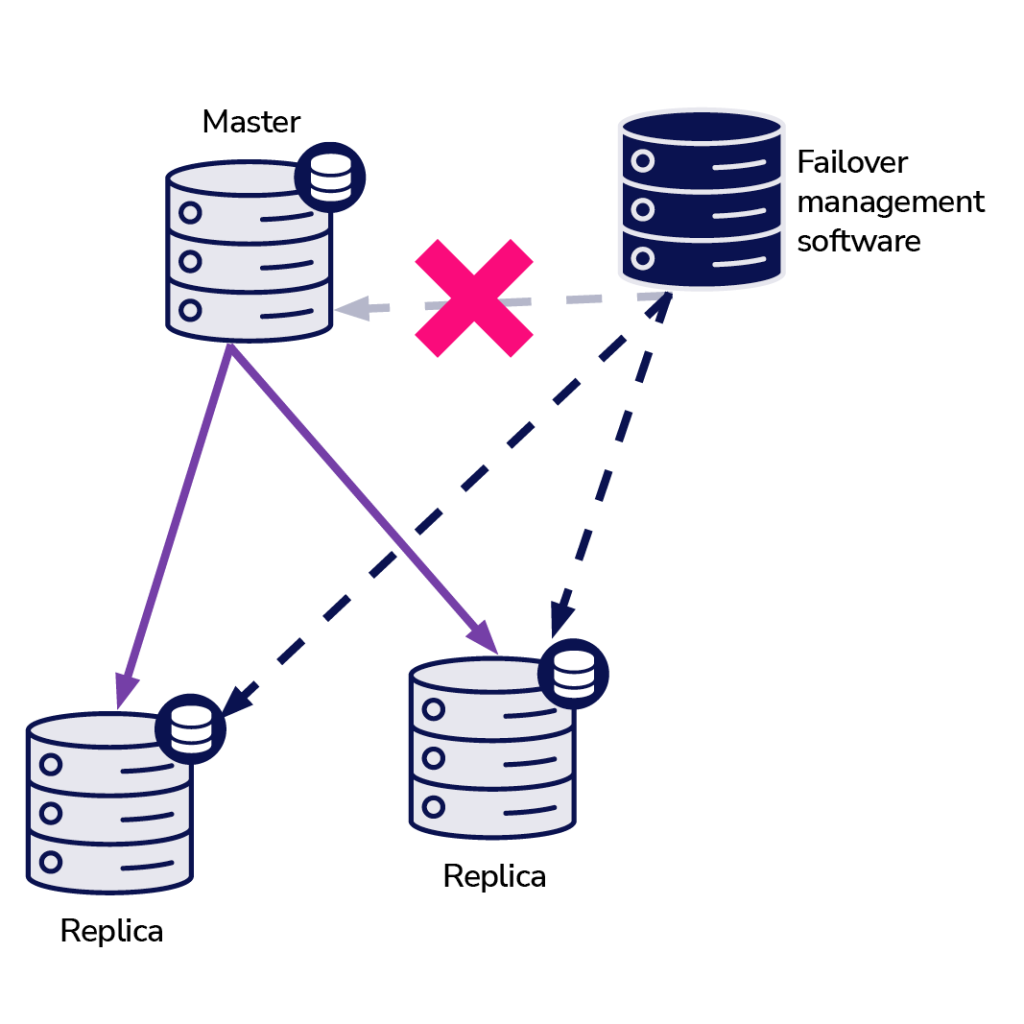
According to the failover management software, the master has crashed – there’s no connectivity to it. Still, the replication itself is working just fine. What should happen here is that the failover management software would try to connect to replicas and see what their point of view is.
Do they complain about a broken replication or are they happily replicating?
Things may become even more complex. What if we’d add a proxy (or a set of proxies)? It will be used to route traffic – writes to master and reads to replicas. What if a proxy cannot access the master? What if none of the proxies can access the master?
This means that the application cannot function under those conditions. Should the failover (actually, it would be more of a switchover as the master is technically alive) be triggered?
Technically, the master is alive but it cannot be used by the application. Here, the business logic has to come in and a decision has to be made.
2. Prevent the old master from running
No matter how and why, if there is a decision to promote one of the replicas to become a new master, the old master has to be stopped and should not be able to start again.
How this can be achieved depends on the details of the particular environment. Therefore, this part of the failover process is commonly reinforced by external scripts integrated into the failover process through different hooks.
Those scripts can be designed to use tools available in the particular environment to stop the old master. The most common scripts that serve this function include:
- A CLI or API call that will stop a VM
- Shell code that runs commands through some sort of “lights out management” device
- A script which sends SNMP traps to the Power Distribution Unit that disable the power outlets the old master is using (without electric power we can be sure it will not start again)
If your failover management software is a part of a more complex product that also handles recovery of nodes (like ClusterControl), you may have the option to exclude the old master from recovery routines.
It’s very important to prevent the old master from becoming available again. That’s because only one node can be used for writes in replication setups.
Typically you ensure that by enabling a read_only (and super_read_only, if applicable) variable on all replicas and keeping it disabled only on the master.
Once a new master is promoted, it will have read_only disabled. The problem is that, if the old master is unavailable, we cannot switch it back to read_only=1.
In a case where MySQL or a host crashed, this should not be too much of an issue since best practices are to have my.cnf configured with that setting so, once MySQL starts, it always starts in read only mode.
The real problem arises when it’s not a crash but a network issue. Here, the old master is still active and running with read_only disabled, it’s just not available. When networks converge, you will end up with two writeable nodes.
This may or may not be a problem.
Some of the proxies use the read_only setting as an indicator whether a node is a master or a replica. Two masters showing up at the given moment may result in a huge issue as data is written to both hosts, but replicas get only half of the write traffic (the part that hit the new master).
Sometimes it’s about hardcoded settings in some of the scripts which are configured to connect to a given host only. Normally they’d fail and someone would notice that the master has changed.With the old master being available, they will happily connect to it and data discrepancy will arise.
So, as you can see, making sure that the old master will not start is quite a high priority item.
3. Decide on a master candidate
The old master is down and will not return from its grave. Now it’s time to decide which host we should use as a new master. Usually there is more than one replica to pick from, so a decision has to be made. There are many reasons why one replica may be picked over another, therefore checks have to be performed.
Whitelists and blacklists
For starters, a team managing databases may have its reasons to pick one replica over another when deciding about a master candidate.
Maybe it’s using weaker hardware or has some particular job assigned to it (that replica runs backup, analytic queries, developers have access to it and run custom, hand-made queries).
Maybe it’s a test replica where a new version is undergoing acceptance tests before proceeding with the upgrade. Most failover management software supports white and blacklists, which can be utilized to precisely define which replicas should or cannot be used as master candidates.
Semi-synchronous replication
A replication setup may be a mix of asynchronous and semi-synchronous replicas. But even though they can work together in the same setup, there’s a huge difference between them. A semi-synchronous replica is guaranteed to contain all of the events from the master.
An asynchronous replica, however, may not have received all the data thus failing over to it may result in data loss.
For this reason, we would always prefer to see semi-synchronous replicas to be promoted.
Replication lag
Even though a semi-synchronous replica will contain all the events, those events may still reside in relay logs only. With heavy traffic, all replicas, no matter if semi-sync or async, may lag.
The problem with replication lag is that, when you promote a replica, you should reset the replication settings so it will not attempt to connect to the old master. This will also remove all relay logs, even if they are not yet applied – which leads to data loss.
Even if you will not reset the replication settings, you still cannot open a new master to connections if it hasn’t applied all events from its relay log. Otherwise you will risk that the new queries will affect transactions from the relay log, triggering all sorts of problems.
For example, an application may remove some rows which are accessed by transactions from relay log.
Taking all of this under consideration, the only safe option is to wait for the relay log to be applied. Still, it may take a while if the replica was lagging heavily.
Decisions have to be made as to which replica would make a better master – asynchronous, but with small lag or semi-synchronous, but with lag that would require a significant amount of time to apply.
Errant transactions
Even though replicas should not be written to, it still could happen that someone (or something) has written to it. It may have been just a single transaction in the past, but it can still have a serious effect on the ability to perform a successful failover.
The issue is strictly related to Global Transaction ID (GTID), a feature which assigns a distinct ID to every transaction executed on a given MySQL node.
Nowadays it’s quite a popular setup as it brings great levels of flexibility and it allows for better performance (with multi-threaded replicas).
The issue is that, while re-slaving to a new master, GTID replication requires all events from that master (which have not been executed on replica) to be replicated to the replica.
Let’s consider the following scenario: at some point in the past, a write happened on a replica. It was a long time ago and this event has been purged from the replica’s binary logs. Now, a master has failed and this replica was appointed as a new master.
All remaining replicas will be slaved off the new master. They will ask about transactions executed on the new master. It will respond with a list of GTIDs which came from the old master as well as the single GTID related to that old write.
GTIDs from the old master are not a problem as all remaining replicas contain at least the majority of them (if not all) and all missing events should be recent enough to be available in the new master’s binary logs. Worst case scenario, some missing events will be read from the binary logs and transferred to replicas.
The issue is with that old write – it happened on a new master only, while it was still a replica, thus it does not exist on remaining hosts. It is an old event therefore there is no way to retrieve it from binary logs.
As a result, none of the replicas will be able to slave off the new master. The only solution here is to take a manual action and inject an empty event with that problematic GTID on all replicas. It will also mean that, depending on what happened, the replicas may not be in sync with the new master.
As you can see, it is quite important to track errant transactions and determine if it is safe to promote a given replica to become a new master. If it contains errant transactions, it may not be the best option.
4. Failover handling for the application
It is crucial to keep in mind that master switch, forced or not, does have an effect on the whole topology. Writes have to be redirected to a new node. This can be done in multiple ways and it is critical to ensure that this change is as transparent to the application as possible.
Let’s take a look at some of the examples of how the failover can be made transparent to the application.
DNS
One of the ways in which an application can be pointed to a master is by utilizing DNS entries. With low TTL it is possible to change the IP address to which a DNS entry such as ‘master.dc1.example.com’ points. Such a change can be done through external scripts executed during the failover process.
Service discovery
Tools like Consul or etc.d can also be used for directing traffic to a correct location. Such tools may contain information that the current master’s IP is set to some value. Some of them also give the ability to use hostname lookups to point to a correct IP.
Again, entries in service discovery tools have to be maintained and one of the ways to do that is to make those changes during the failover process, using hooks executed on different stages of the failover.
Proxy
Proxies may also be used as a source of truth about topology. Generally speaking, no matter how they discover the topology (it can be either an automatic process or the proxy has to be reconfigured when the topology changes), they should contain the current state of the replication chain as otherwise they wouldn’t be able to route queries correctly.
The approach to use a proxy as a source of truth can be quite common in conjunction with the approach to collocate proxies on application hosts.
There are numerous advantages to collocating proxy and web servers: fast and secure communication using Unix socket, keeping a caching layer (as some of the proxies, like ProxySQL can also do the caching) close to the application. In such a case, it makes sense for the application to just connect to the proxy and assume it will route queries correctly.
Failover in ClusterControl
Use of a tool can help you automate failovers and save you the time and effort required to manually manage the process or write a script.
ClusterControl applies industry best practices to make sure that the failover process is performed correctly. It has been rigorously tested to ensure that the process is safe, with default settings intended to abort the failover if possible issues are detected. Those settings can be overridden by the user should they want to prioritize failover over data safety.
Here’s how the failover process works in ClusterControl.
Once a master failure has been detected, a failover process is initiated and a first failover hook is immediately executed:

Next, master availability is tested.

ClusterControl does extensive tests to make sure the master is indeed unavailable. This behavior is enabled by default and it is managed by the following variable:
replication_check_external_bf_failover
Before attempting a failover, perform extended checks by checking the slave status to detect if the master is truly down, and also check if ProxySQL (if installed) can still see the master. If the master is detected to be functioning, then no failover will be performed. Default is 1 meaning the checks are enabled.As a following step, ClusterControl ensures that the old master is down and if not, that ClusterControl will not attempt to recover it:

Next step is to determine which host can be used as a master candidate. ClusterControl does check if a whitelist or a blacklist is defined.
You can do that by using the following variables in the cmon configuration file:
replication_failover_blacklist
Comma separated list of hostname:port pairs. Blacklisted servers will not be considered as a candidate during failover. replication_failover_blacklist is ignored if replication_failover_whitelist is set.replication_failover_whitelist
Comma separated list of hostname:port pairs. Only whitelisted servers will be considered as a candidate during failover. If no server on the whitelist is available (up/connected) the failover will fail. replication_failover_blacklist is ignored if replication_failover_whitelist is set.It is also possible to configure ClusterControl to look for differences in binary log filters across all replicas. It can be done using replication_check_binlog_filtration_bf_failover variable. By default, those checks are disabled. ClusterControl also verifies there are no errant transactions in place, which could cause issues.

You can also ask ClusterControl to auto-rebuild replicas which cannot replicate from the new master using following setting in cmon configuration file:
* replication_auto_rebuild_slave:
If the SQL THREAD is stopped and error code is non-zero then the slave will be automatically rebuilt. 1 means enable, 0 means disable (default).
Afterwards a second script is executed: it is defined in replication_pre_failover_script setting. Next, a candidate undergoes preparation process.


ClusterControl waits for redo logs to be applied (ensuring that data loss is minimal). It also checks if there are other transactions available on remaining replicas, which have not been applied to master candidate. Both behaviors can be controlled by the user, using the following settings in cmon configuration file:
replication_skip_apply_missing_txs
Force failover/switchover by skipping applying transactions from other slaves. Default disabled. 1 means enabled.replication_failover_wait_to_apply_timeout
Candidate waits up to this many seconds to apply outstanding relay log (retrieved_gtids) before failing over. Default -1 seconds (wait forever). 0 means failover immediately.As you can see, you can force a failover even though not all of the redo log events have been applied – it allows the user to decide what has the higher priority – data consistency or failover velocity.


Finally, the master is elected and the last script is executed (a script which can be defined as replication_post_failover_script.
Master detection in ClusterControl
Master detection is always one of the key issues you need to deal with as part of the MySQL replication failover process.
When you use ClusterControl to deploy a full high availability stack, including database and proxy layers, master detection becomes automated.
Let’s quickly run through how it works.
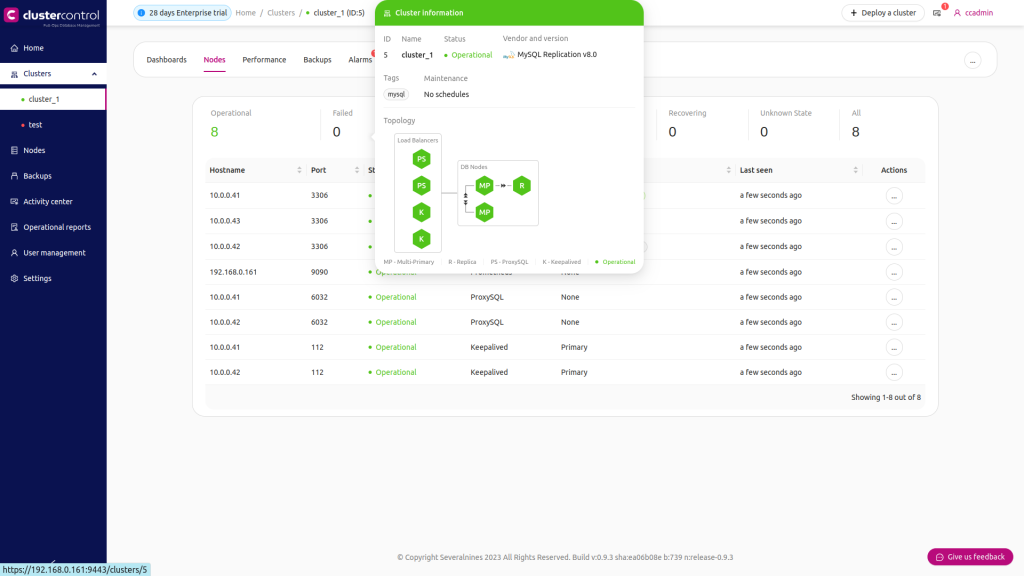
A high availability stack, deployed through ClusterControl, consists of three pieces:
- Database layer
- Proxy layer which can be HAProxy or ProxySQL
- Keepalived layer, which, with use of Virtual IP, ensures high availability of the proxy layer
The proxies rely on read_only variables on the nodes.
As you can see in the screenshot above, only one node in the topology is marked as “writable”. This is the master and this is the only node which will receive writes.
The proxy (in this example, ProxySQL) will monitor this variable and it will reconfigure itself automatically.
On the other side of that equation, ClusterControl takes care of any topology changes that take place during failovers and switchovers. It will make the necessary changes in read_only value to reflect the state of the topology after the change. If a new master is promoted, it will become the only writable node and it will have read_only disabled.
On top of the proxy layer, keepalived is deployed. It deploys a VIP and it monitors the state of underlying proxy nodes. VIP points to one proxy node at a given time. If this node goes down, virtual IP is redirected to another node, ensuring that the traffic directed to VIP will reach a healthy proxy node.
To sum it up:
- An application connects to the database using a virtual IP address
- This IP points to one of the proxies
- Proxies redirect traffic accordingly to the topology structure
- Information about topology is derived from read_only state
- This variable is managed by ClusterControl and it is set based on topology changes that the user requests or that ClusterControl performs automatically.
Wrapping up
MySQL replication is a great option for achieving high availability, but you need to ensure that you have a robust failover plan for any situation where your master node becomes unavailable.
Failover can be handled manually or by writing a script, but platforms like ClusterControl are designed to relieve you of the headache by automating the entire process – from master failure recognition to new master detection and topology changes.
You can try our sandbox demo environment to test exactly how failover works with ClusterControl, along with any other element of database operations.
Stay on top of all things MySQL by subscribing to our newsletter below.
Follow us on LinkedIn and Twitter for more great content in the coming weeks. Stay tuned!



