blog
Transparent Database Failover for Your Applications

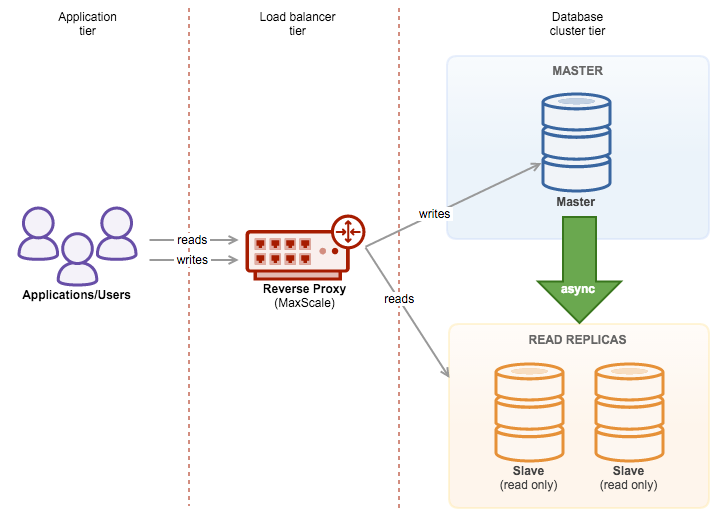
ClusterControl is a great tool to deploy and manage databases clusters – if you are into MySQL, you can easily deploy clusters based on both traditional MySQL master-slave replication, Galera Cluster or MySQL NDB Cluster. To achieve high availability, deploying a cluster is not enough though. Nodes may (and will most probably) go down, and your system has to be able to adapt to those changes.
This adaptation can happen at different levels. You can implement some kind of logic within the application – it would check the state of cluster nodes and direct traffic to the ones which are reachable at the given moment. You can also build a proxy layer which will implement high availability in your system. In this blog post, we’d like to share some tips on how you can achieve that using ClusterControl.
Deploying HAProxy Using the ClusterControl
HAProxy is the standard – one of the most popular proxies used in connection with MySQL (but not only, of course). ClusterControl supports deployment and monitoring of HAProxy nodes. It also helps to implement high availability of the proxy itself using keepalived.
Deployment is pretty simple – you need to pick or fill in the IP address of a host where HAProxy will be installed, pick port, load balancing policy, decide if ClusterControl should use existing repository or the most recent source code to deploy HAProxy. You can also pick which backend nodes you’d like to have included in the proxy configuration, and whether they should be active or backup.
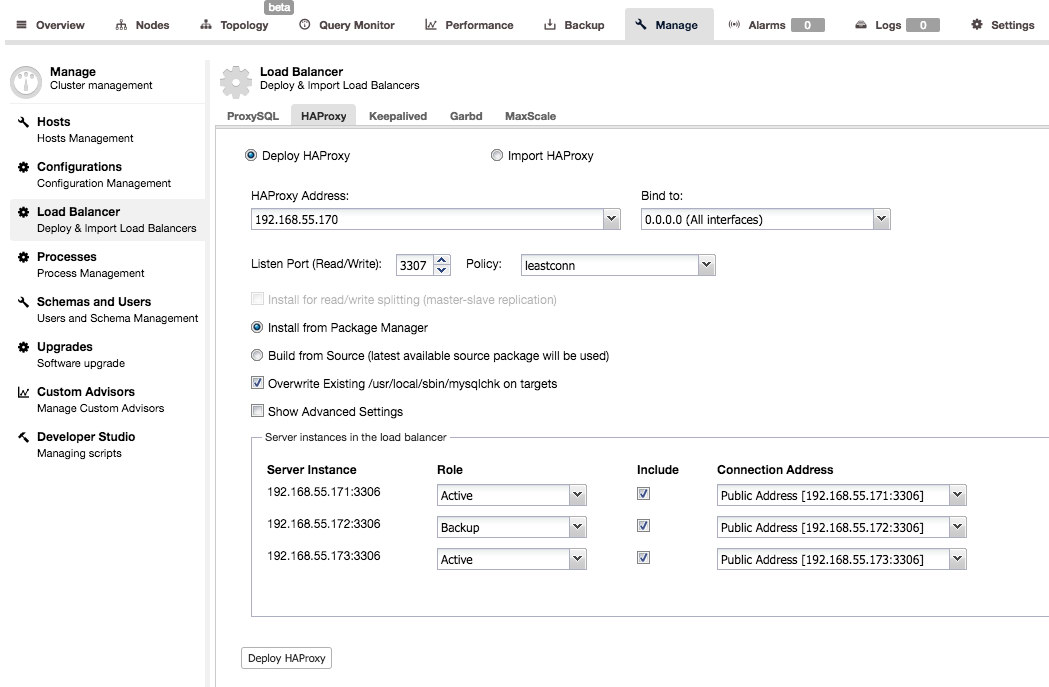
By default, the HAProxy instance deployed by ClusterControl will work on MySQL Cluster (NDB), Galera Cluster, PostgreSQL streaming replication and MySQL Replication. For master-slave replication, ClusterControl can configure two listeners, one for read-only and another one for read-write. Applications will then have to send reads and writes to the respective ports. For multi-master replication, ClusterControl will setup the standard TCP load-balancing based on least connection balancing algorithm (e.g., for Galera Cluster where all nodes are writeable).
Keepalived is used to add high availability to the proxy layer. When you have at least two HAProxy nodes in your system, you can install Keepalived from the ClusterControl UI.
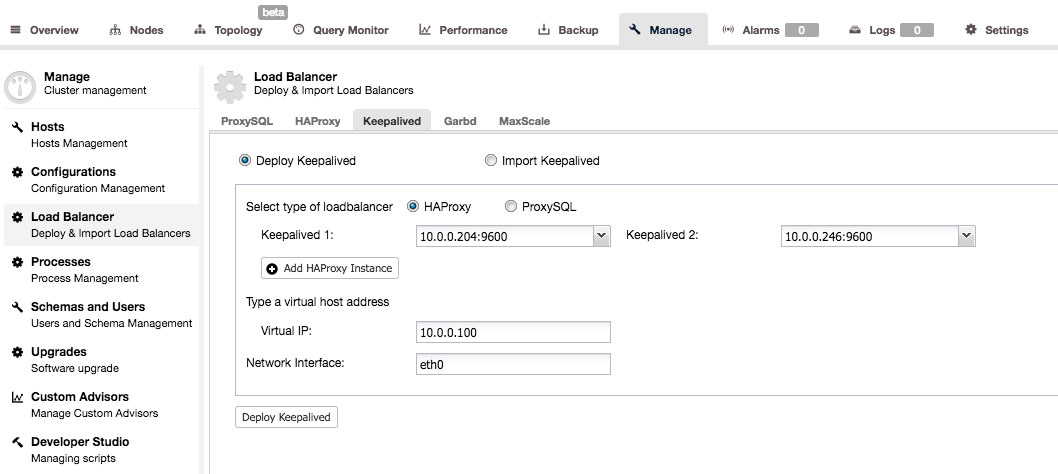
You’ll have to pick two HAProxy nodes and they will be configured as an active – standby pair. A Virtual IP would be assigned to the active server and, should it fail, it will be reassigned to the standby proxy. This way you can just connect to the VIP and all your queries will be routed to the currently active and working HAProxy node.
You can find more details in how the internals are configured by reading through our HAProxy tutorial.
Deploying ProxySQL Using ClusterControl
While HAProxy is a rock-solid proxy and very popular choice, it lacks database awareness, e.g., read-write split. The only way to do it in HAProxy is to create two backends and listen on two ports – one for reads and one for writes. This is, usually, fine but it requires you to implement changes in your application – the application has to understand what is a read and what is a write, and then direct those queries to the correct port. It’d be much easier to just connect to a single port and let the proxy decide what to do next – this is something HAProxy cannot do as what it does is just routing packets – no packet inspection is done and, especially, it has no understanding of the MySQL protocol.
ProxySQL solves this problem – it talks MySQL protocol and it can (among other things) perform a read-write split through its powerful query rules and route the incoming MySQL traffic according to various criterias. Installation of ProxySQL from ClusterControl is simple – you want to go to Manage -> Load Balancer section and fill the “Deploy ProxySQL” tab with the required data.
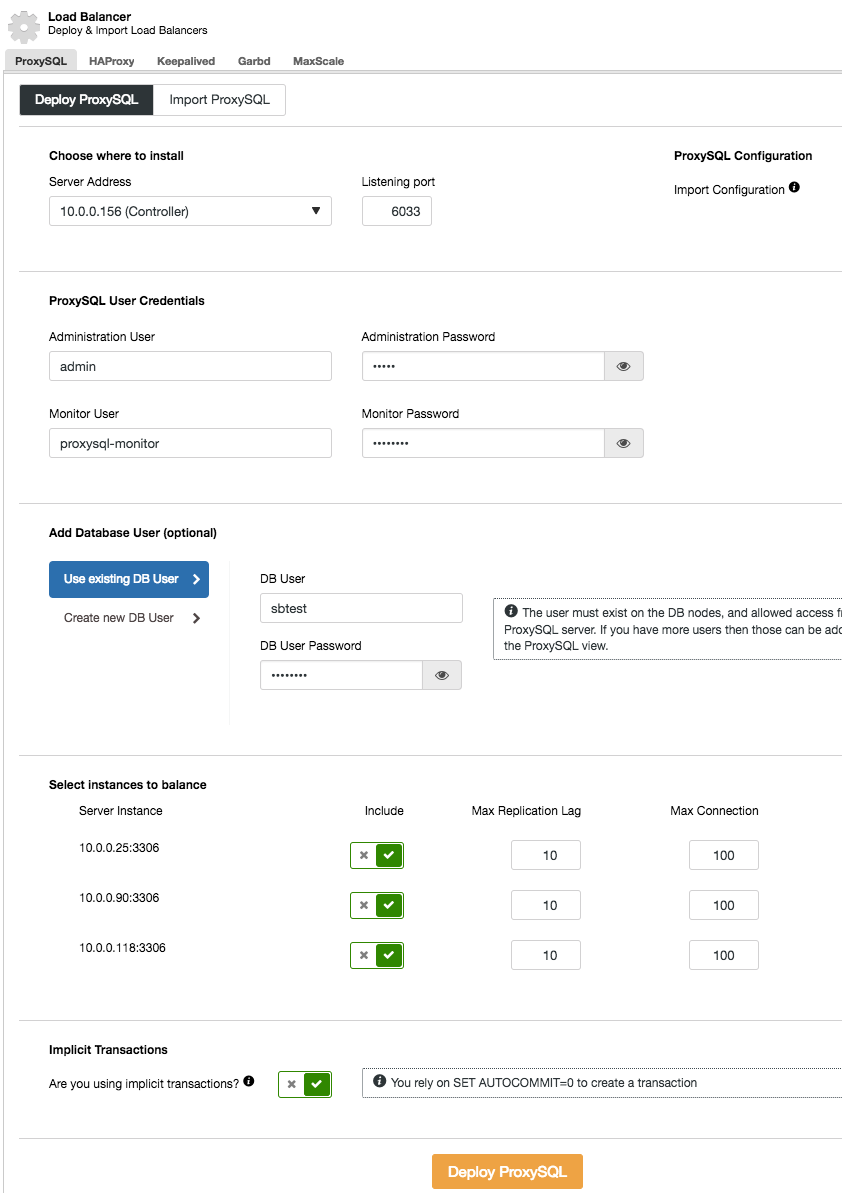
In short, we need to pick where ProxySQL will be installed, what administration user and password it should have, which monitoring user it should use to connect to the MySQL backends and verify their status and monitor state. From ClusterControl, you can either create a new user to be used by the application – you can decide on its name, password, access to which databases are granted and what MySQL privileges that user will have. Such user will be created on both MySQL and ProxySQL side. Second option, more suitable for existing infrastructures, is to use the existing database users. You need to pass username and password, and such user will be created only on ProxySQL.
Finally, you need to answer a question: are you using implicit transactions? By that we understand transactions started by running SET autocommit=0; If you do use it, ClusterControl will configure ProxySQL to send all of the traffic to the master. This is required to ensure ProxySQL will handle transactions correctly in ProxySQL 1.3.x and earlier. If you don’t use SET autocommit=0 to create new transaction, ClusterControl will configure read/write split.
ProxySQL, as every proxy, can become a single point of failure and it has to be made redundant to achieve high availability. There are a couple of methods to do that. One of them is to collocate ProxySQL on the web nodes. The idea here is that, most of the time, the ProxySQL process will work just fine and the reason for its unavailability is that the whole node went down. In such case, if ProxySQL is collocated with the web node, not much harm has been done because that particular web node will not be available either.
Another method, is to use Keepalived in a similar way like we did in the case of HAProxy.
You can find more details in how the internals are configured by reading through our ProxySQL tutorial.



