blog
How to Reduce Replication Lag in Multi-Cloud Deployments

Replication lag is an inevitable occurrence for multi-cloud database deployments, as it causes delays of transactions to reflect into the target node or cluster. When implementing a multi-cloud database deployment, the most common scenario (and the reason why organizations tend to implement this) for multi-cloud is to have a disaster response mechanism for your architectural and underlying environment. An outage with downtime can cost your business money, often costing more money than if the Disaster and Recovery Plan (DRP) was not addressed and not planned beforehand.
Implementing a multi-cloud database should not be done without analyzing each of the components that comprises the entire stack. In this blog we’ll address some of those issues, but will primarily look at data consistency issues brought out by replication lag common to multi-cloud deployments.
Multi-Cloud Deployments
A common setup for multi-cloud deployments is where clusters are situated not only in different regions, but also on different providers. Providers, however, often have different hardware configurations (Azure, Google Cloud, AWS) and data centers that run these compute nodes that run your application and databases. We have discussed this previously on what can be the common cases and reasons why certain organizations and companies embrace multi-cloud database setup.
A common deployment can look like the structure below,
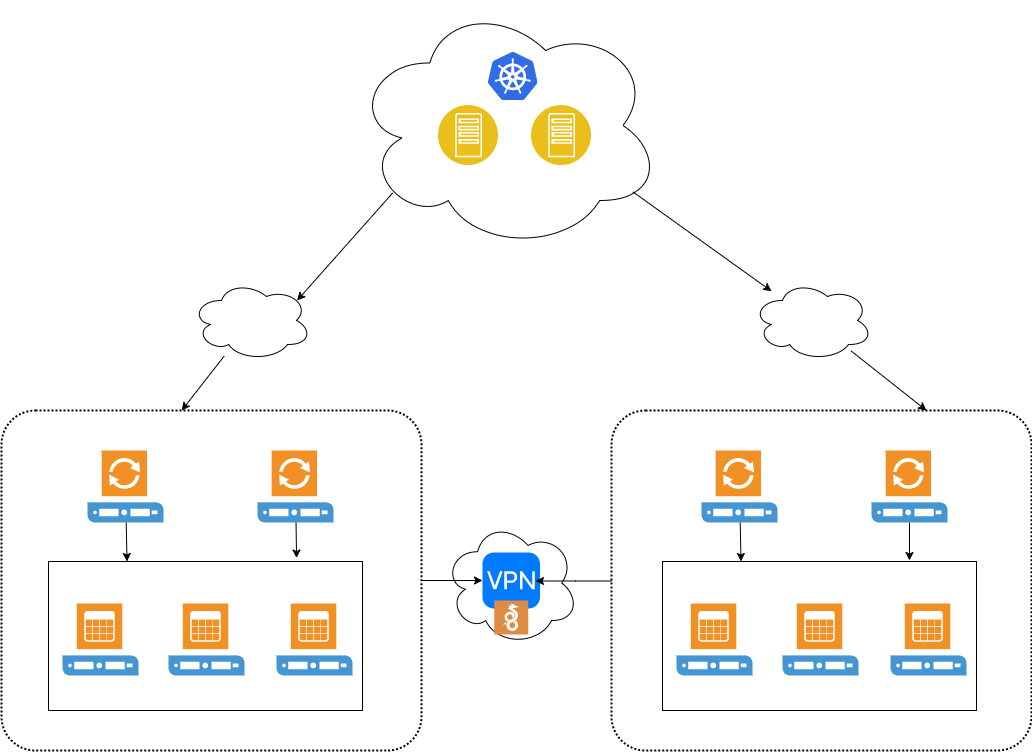
From applications (either running on containers), then connects to proxies, and proxies balance over through the database cluster or nodes depending on traffic demand. Interconnection between different cloud providers requires that it has to connect securely and the most common approach is over a VPN connection. Wireguard can be an option as well to establish a virtual connection between clouds. For production-based VPN’s, a cloud VPN gateway is a great option. Not only does it provide high availability, it offers you with secure downtime, high service availability (with SLA), and bandwidth speed; especially when a high transfer rate is needed. When dealing with replication lag, there’s no doubt you’ll find this type of service helpful.
Other Ways to Reduce Lag in your Multi-Cloud Deployments
Reducing lag is a complex process. There are a ton of things to consider as to what could cause your replication between clouds to lag. Certain occasions, when replication lag tends to accumulate high, can then fix itself over a period of time. These are acceptable for some cases when a certain occurrence of execution or expected amount of traffic is bound to happen.
Although certain formulas that work (and that you think are enough) may be ok in a traditional environment, but in a multi-cloud environment, there’s a lot of things to consider and look at between cloud providers. However, in every problem, there can always be a solution but we’ll go through the basics and vital areas to look upon.
Cloud Infrastructure
A difference between cloud infrastructure can impact lag. For example, the difference between the type of compute node specifications matters. The number of vCPus, CPUs, memory, storage, network bandwidth and hardware are things you need to know. Memory and CPU contention, disk throughput, network latency, issues with concurrency, impacts your instance in the cloud. It also depends on what type of queries or transactions you are serving coming from your client, down to your database cluster. Then your database cluster replicates to the other cluster which resides in another cloud provider. If you’re using general purpose instances, it might produce poor performance if you’re serving tons of query requests or handling bulk updates to your tables and databases. Not only the queries are required to be handled, if you run onto specific or custom configurations of your databases, for example, using encryption such as TLS/SSL, it can be CPU bound and that might produce outstanding impact for general purpose type instances.
Running or hosting your database VM’s on a multi-tenant hardware provides impact as well. You’ll have to take note that there are compute nodes running as guest OS will run on that particular hosting hardware. If such a high-computing node runs on the same tenant, it can impact as well where your compute node is running. For example, disks may also run out of memory, I/O and CPU, keeping data from being written down to the storage can cause your replica to fall further behind the primary node in the other region or cloud. An alternative option which can be dealt with the cloud provider is to use dedicated instances or hosts. These are physically isolated at the hardware level, although there can be instances that it shares hardware with other instances from the same account that are not dedicated instances.
While those mentioned above help determine the source and impact of lag, reducing the lag is very important to know your underlying hardware and its sole purpose which is to replicate the data from one cluster within another cloud provider, to another cluster of a different provider. Instead of running database transactions to the receiving replica (the node which will intercept replicated data from the other cluster of a different cloud provider), you can dedicate the tasks and responsibility of node only for syncing and replicating your data and nothing else. Avoiding unwanted tasks aside from replication helps your replica node to catch up with the master as quick as possible. Distance matters also wherever your database clusters belong to. For example, if both clusters run on different regions, yet these regions are based on eastern-us vs asia-east, this can be a problem. It would make sense to use the same region or use the nearest region if the latter is not possible. If your mission is to expand your system using multi-cloud deployments for your mission critical systems and avoid downtime and outage, then lag and data drift is very important to be avoided.
For MySQL Lag within Intra-Cloud Deployments
A very common approach for replication with MySQL is using the single-threaded replication. This works all the time especially for a simple setup with low to moderately high demand replication. However, there are certain cases that replication lag on a master-slave setup can cause consistent and frequent issues. Hence, you do need your slave node to catch up with your master wherein both nodes reside on different cloud providers. A great deal to handle this is to use parallelism with replication. Using –slave-parallel-type=[DATABASE, LOGIAL_CLOCK] with a combination of binlog_group_commit_sync_delay helps drastically reduce the slave lag.
Of course hardware can be your sweet spot here to address performance issues especially on a high-traffic systems, it might help boost as well if you relax some variables such as sync_binlog, innodb_flush_log_at_trx_commit, and innodb_flush_log_at_timeout.
For Galera-based clusters, keeping up with clusters of different clouds can be a challenge as well. However, it’s advisable to set your Galera clusters using different segments. You can do this by setting your gmcast.segment value for every cluster separated to a different region or cloud.
For PostgreSQL within Intra-Cloud Deployments
A common approach for replication with PostgreSQL is to use physical streaming replication. It might depend on your desired setup but reducing a replication lag with streaming replication is a good deal here. Of course logical replication or using continuous archiving is an option but it may not be an ideal setup and exposes limited capability when dealing with monitoring and management especially with different cloud providers and also the major concern for reducing your replica lag when tuning and monitoring it. Unless you’re using third-party extensions such as pglogical or BDR from 2ndQuadrant for your logical replication, but that’s not covered here in the blog and it’s out of scope for the main topic.
A good approach to deal with this is to dedicate your replication streams only for that purpose. For example, two replication streams (primary and standby) do not receive any read queries but only do replication streams alone. These two nodes which reside in different cloud providers must have secondary nodes in case one fails, so preserve a highly available environment especially for mission critical systems.
With physical streaming replication, you may take advantage of tuning the variables hot_standby_feedback = off and max_standby_streaming_delay longer than 0 in your postgresql.conf. Twitch uses 6h value on their setup but they might add changes since this post of their blog. Tuning these variables help avoid the replication source from not being burdened and replication will not cancel queries because of multi-version concurrency control (MVCC).
Also when dealing with replication lag, you may consider checking your transaction isolation. For some cases, a specific transaction isolation might cause impact (e.g. using SERIALIZABLE) in your replicating node.
For MongoDB within Intra-Cloud Deployments
MongoDB addresses this in their manual on how to troubleshoot especially for replica sets. Common reasons are network latency, disk throughput, concurrency, and bulk changes or large data sent to your MongoDB replica. If your major business requires dealing with large data and you have a mission critical system, then investing for a dedicated instance or host can be your great deal of choice here. A common concern can be impacted if your compute instances are running on multi-tenant systems.
Concurrency can be a major concern with MongoDB especially large and long running write operations. This can cause your system to stop because the system is locked and incoming operations are blocked affecting replication to your replica situated on a different cloud provider, and this will increase replication lag. In the replica or secondary level, also, a common issue similar to concurrency, is when running frequent and large write operations. The disk of the replica will be unable to read the oplog resulting in a poor performance and can have hard time catching up with the primary and causing the replication to fall behind. Killing or terminating running operations is not an option here especially if you data has been written already from the primary cluster or primary node.
Lastly, as those concerns will not be mitigated until known. Avoiding writes to your replica or secondary nodes situated on the other cloud will help avoid concurrency and poor performance that can impact during replication.
Monitoring Your Replication Lag
Using external tools available at your own disposal can be the key here. However, choosing the right tool for monitoring is the key here to understand and analyze how your data performs. ClusterControl which offers monitoring and management is a great deal to start from when deploying multi-cloud databases. For example, the screenshot below provides you a great deal to determine network performance, CPU utilization, flow control of your Galera-based cluster:
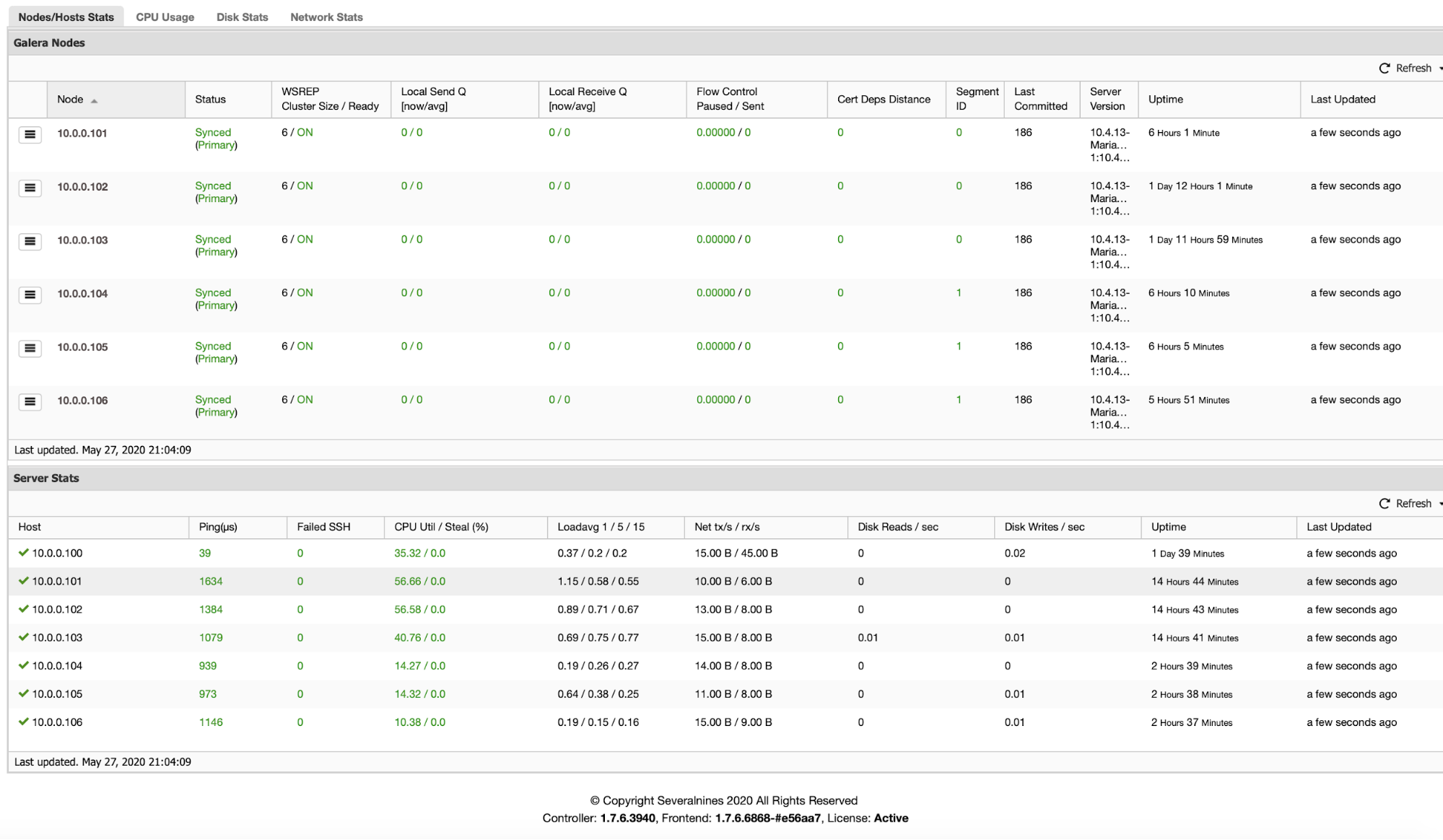
ClusterControl supports PostgreSQL/TimescaleDB, MongoDB, MySQL/MariaDB including Galera Cluster deployments, management, and monitoring. It also offers query analysis on what queries are impacting your cluster and provides advisors to deal with the issues that are detected and provide you solutions to solve the problem. Expanding your cluster onto a different cloud provider is not that difficult with ClusterControl.
Conclusion
Different cloud providers have different infrastructure yet might offer solutions to help you mitigate lags to your database deployments. However, this might be difficult and goes complicated without proper monitoring tools regardless of your expertise and skills to know what can cause your database replication lag in your multi-cloud environment. A manual check is not a great idea when critical systems that require rapid response. It requires higher observability of your cluster. A rapid solution has to be in place before replication lag escalates to a higher degree of impact. So choose the right tool at your own expense and avoid drastic measures when a crisis hits.



