blog
An Overview of Cluster-to-Cluster Replication

Nowadays, it’s pretty common to have a database replicated in another server/datacenter, and it’s also a must in some cases. There are different reasons to replicate your databases to a totally separate environment.
- Migrate to another datacenter.
- Upgrade (hardware/software) requirements.
- Maintain a fully synced operational system in a Disaster Recovery (DR) site that can take over at any time
- Keep a slave database as part of a lower cost DR Plan.
- For geo-location requirements (data needs to be locally in a specific country).
- Have a testing environment.
- Troubleshooting purpose.
- Reporting database.
And, there are different ways to perform this replication task:
- Backup/Restore: Backing up a production database and restoring it in a new server/environment is the classic way to do this, but it is also an old-fashioned way as you won’t keep your data up-to-date and you need to wait for each restoring process if you need some recent data. If you have a cluster (master-slave, multi-master), and if you want to recreate it, you should restore the initial backup and then recreate the rest of the nodes, which could be a time-consuming task.
- Clone Cluster: It is similar to the previous one but the backup and restore process is for the whole cluster, not only one specific database server. In this way, you can clone the entire cluster in the same task and you don’t need to recreate the rest of the nodes manually. This method still has the problem of keeping data up-to-date between clones.
- Replication: This way includes the backup/restore option, but after the initial restore, the replication process will keep your data synchronized with the master node. In this way, if you have a database cluster, you need to restore the backup to one node, and recreate all the nodes manually.
In this blog, we will see a new ClusterControl 1.7.4 feature that allows you to use a mix of the method that we mentioned earlier to improve this task.
What is Cluster-to-Cluster Replication?
Replication between two clusters is not the same thing as extending a cluster to run across two datacenters. When setting up replication between two clusters, we actually have 2 separate systems that can operate autonomously. Replication is used to keep them in sync, so that the slave system has an updated state and can take over.
From ClusterControl 1.7.4, it is possible to create a new cluster by directly cloning a running source cluster, or by using a recent backup of the source cluster.
After cloning the cluster, you will have a Slave Cluster (SC) receiving data, and a Master Cluster (MC) sending changes to the slave one.
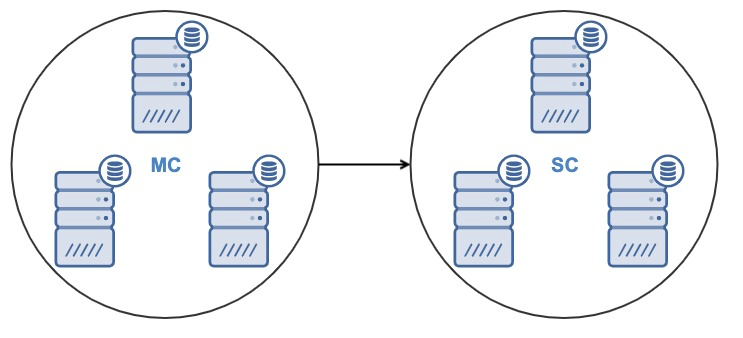
ClusterControl supports Cluster-to-Cluster Replication for the following cluster types:
- Percona XtraDB Cluster version 5.6.x and later.
- MariaDB Galera Cluster version 10.x and later.
- PostgreSQL 9.6 and later.
Cluster-to-Cluster Replication for Percona XtraDB / MariaDB Galera Cluster
For MySQL based engines, GTID is required to use this feature, and asynchronous replication between the Master and Slave cluster will be used.
There are a couple of actions to perform in order to prepare the current cluster for this job. First, at least one node on the current cluster must have the binary logs enabled. Then, you need to add the backup user configured in the database node in the ClusterControl configuration file, which will be used for management tasks. All these actions can be performed by using the ClusterControl UI or ClusterControl CLI.
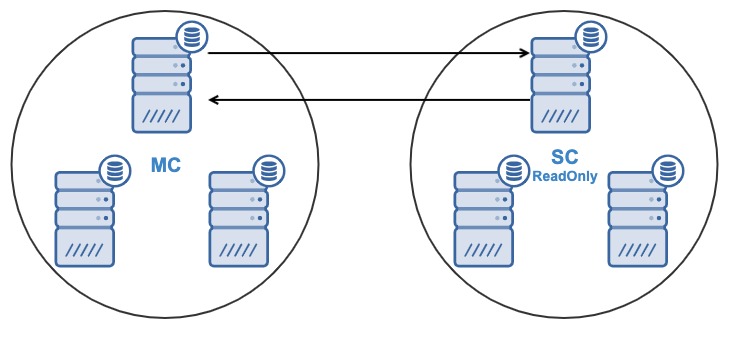
Now you are ready to create the Percona XtraDB/MariaDB Galera Cluster-to-Cluster replication. When the job is finished, you will have:
- One node in the Slave Cluster will replicate from one node in the Master Cluster.
- The replication will be bi-directional between the clusters.
- All nodes in the Slave Cluster will be read-only by default. It is possible to disable the read-only flag on the nodes one by one.
- Active-Active clustering is only recommended if applications are only touching disjoint data sets on either Cluster since the engine doesn’t offer any Conflict Detection or Resolution.
From both ClusterControl UI or ClusterControl CLI, you will be able to:
- Create this Replication Cluster.
- Enable the Active-Active configuration.
- Change the Cluster Topology.
- Rebuild a Replication Cluster.
- Stop/Start a Replication Slave.
- Reset Replication Slave (only implemented using ClusterControl CLI atm).
Considerations
- The backup user must be added manually in the ClusterControl configuration file.
- The backup user credentials must be the same in both the current and new cluster.
- The MySQL root password specified when creating the Slave Cluster must be the same as the root password used on the Master Cluster.
Known Limitations
- Automatic Failover is not supported yet. If the master fails, then it is the responsibility of the administrator to failover to another master.
- It is only possible to “RESET” a replication slave from the ClusterControl CLI as it’s not implemented in the ClusterControl UI yet.
- It is only possible to Rebuild a Cluster that is in read-only mode. All nodes in a Cluster must be read-only to count as read-only Cluster.
Cluster-to-Cluster Replication for PostgreSQL
ClusterControl Cluster-to-Cluster Replication is supported on PostgreSQL using streaming replication.
As a requirement, there must be a PostgreSQL server with the ClusterControl role ‘master’, and when you set up the Slave Cluster, the Admin credentials must be identical to the Master Cluster.
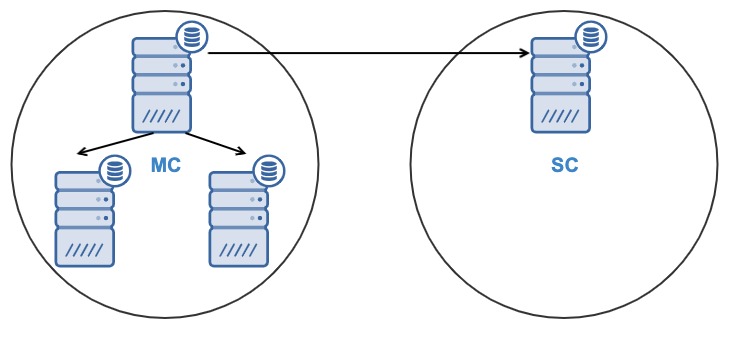
Now you are ready to create the PostgreSQL Cluster-to-Cluster replication. When the job is finished, you will have:
- One node in the Slave Cluster will replicate from one node in the Master Cluster.
- The replication will be unidirectional between the clusters.
- The node in the Slave Cluster will be read-only.
From both ClusterControl UI or ClusterControl CLI, you will be able to:
- Create this Replication Cluster.
- Rebuild a Replication Cluster.
- Stop/Start a Replication Slave.
Consideration
- The Admin Credentials must be identical in the Master and Slave Cluster.
Known Limitations
- The max size of the Slave Cluster is one node.
- The Slave Cluster cannot be staged from a backup.
- Topology changes are not supported.
- Only unidirectional replication is supported.
Conclusion
Using this new ClusterControl feature, you don’t need to do each step to create a Cluster Replication separately or manually, and as a result of using it, you will save time and effort. Give it a try!



