blog
Database Backups in the Cloud for Disaster Recovery

Multi-cloud deployments of open source databases require considerations such as high availability, scalability, resiliency, backups, and disaster recovery. In this blog, we will emphasize the importance of database backups in the cloud which provide you data redundancy, durability, data security, and higher data retention.
Backups for Disaster Recovery
Creating a backup copy doesn’t mean your business has attained a “high security rating” when it comes to data loss. We always recommend our customers to always store redundant copies of your backups over disparate locations to satisfy your RTO and RPO needs. Having reliable backups in a sole destination (such as your on-site copy) without dispersing off-site increases risk for your organization. Not only is your data at risk, but also your underlying mission critical systems and its architecture. Every component is vital to make your business run smoothly and function healthy at normal times.
Storing your backup at least twice or more provides your organization durability and higher resiliency with the capacity to recover from data loss at 99.99999% assurance. However, it doesn’t mean that simple. Storing your data to make it more highly available at times requires also to determine your backup policies which involves higher retention, types of backup, the backup cycle, and data security from in-transit and at-rest.
Database Backups in the Cloud
Cloud computing has risen in popularity and is constantly improving, especially in the last decade. Organizations from the SMB (Small and Medium Businesses) to large enterprises have all adopted the nature of cloud computing; running their technology stack within the cloud provider’s domain. Cloud providers also offer various solutions to take backups of the on-cloud running applications, compute nodes, and database backups. For higher availability, backups are stored not only on one location, but also into different locations by storing it on different availability zones.
Creating your backup and storing it to your desired location is not an easy task. Determining the right and reliable solutions make you more secure and gives your company a peace of mind. That’s why a lot of organizations and companies are relying on the solutions that cloud providers offer.
Most cloud providers, however, do not extend these backups solutions the flexibility on what to do with your backups (especially when at-rest). How quick and flexible are your backup to recover from data loss or when data corruption is damaging and impacting your whole database clusters. How your backup data is stored, is it stored securely and is it stored on a dedicated host or on a multi-tenant host? For example, Amazon RDS Backup does offer a backup solution right to their customers, but it doesn’t allow you to create the naitive type of backups to create logical backups or physical backups; the most trusted and custom type of backups designed for the type of database you are using.
Types of Database Backups
The most common type of backups are the following:
- Logical backup – backup of data is stored in a human-readable format like SQL
- Physical backup – backup contains binary data
These two types are commonly utilized in conjunction. You take your logical backup first, followed by a physical backup. It’s highly recommended you do not want to run them both at the same time on the same database host. Running a full backup is resource intensive and you might not want to interfere with normal operations. For example, backup is taken on a replica but due to high-intensive operations, the replica starts to lag and this can impact your backup operations and the data to be backed up as well.
Aside from those conjunctions, a common approach is to always create a copy of your transaction logs. MySQL uses binary logs, PostgreSQL uses WAL files, and MongoDB uses oplog. The transactions logs are essential for performing a point-in-time recovery or PITR. These database transaction logs are vital to address your RPO at lower risk but you also need to determine the impact when extending the execution times of your backup so as to avoid unnecessary degradation of performance on the source host where the backup was taken. As stated earlier, you might not want to interfere with the normal operations of your database cluster when the backup process is on-going.
How do these types of backups differ from using the solutions offered by cloud vendors? As mentioned earlier, cloud giants offer backup solutions, but don’t have the sophistication to utilize your desired approaches when taking the backups. There are external solutions out there that provide companies and organizations more flexibility and autonomy when handling their backup. For example, ClusterControl and Backup Ninja offer you these types of backup.
Securing Your Database Backup
Security is one of the most challenges that organizations and companies are most concerned about. Ransomware attacks are costly and consequences of data loss reveals that 93% of companies that lost their data center for 10 days or more due to a disaster, filed for bankruptcy within one year of the disaster. 50% of businesses that found themselves without data management for this same time period filed for bankruptcy immediately. (National Archives & Records Administration in Washington). Interestingly, 94% of companies suffering from a catastrophic data loss do not survive – 43% never reopen and 51% close within two years according to the University of Texas. These are things that organizations have to deal with especially with security.
But how can you make your backups secure? Encrypt your backup always! Encrypting your backup requires two-ways. It shall be in-transit and at-rest.
Verifying Your Database Backup
A lot of times I heard especially when I run demos and handle tickets over our Support system are surprised about the offering we included within our ClusterControl product for backup verification. At Severalnines, we believed the philosophy of a Schrödinger’s Backup. Backup is not as reliable and still in an unknown state until it is restored. Always test your backup!
If you are familiar with Amazon RDS, automated backups are taken over a snapshot and with transaction logs that are stored from Amazon S3. When restoring a backup, it will bring out a new instance and which you can verify and not only that, you can also make that new node as a new database instance either for recovering your lost data or a failed node.
How to Create a Database Backup
In this section, we will create a backup using ClusterControl. ClusterControl does not only offer backup solutions, it provides you management and monitoring while providing you the whole observability of your database clusters. Not only that, the backup to be stored offers you to store in multiple locations that can be stored on-site and off-site such as to the cloud. Once backup is done, ClusterControl offers you the capability to schedule and verify your backup and notify you if it was able to restore it or not. Now, let’s dive into that.
Creating Your Backup
Creating your backup is fairly straightforward with ClusterControl. All you have to do is to click “Create Backup” button as shown below,
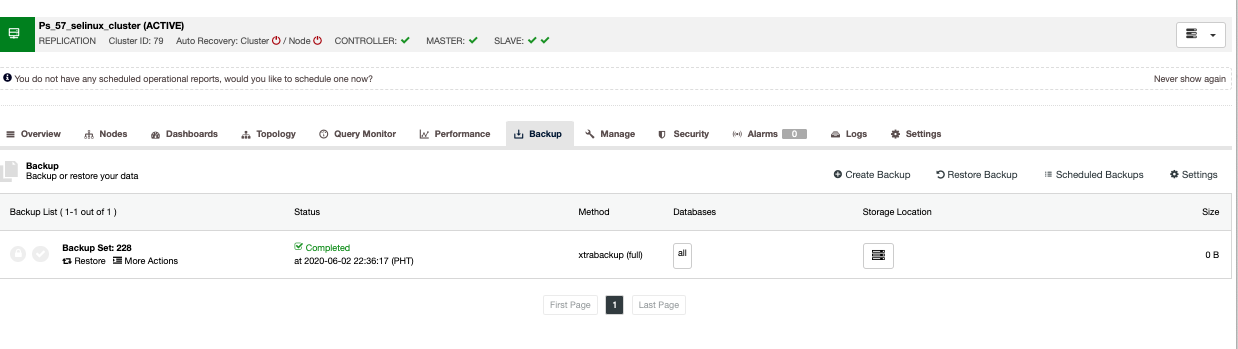
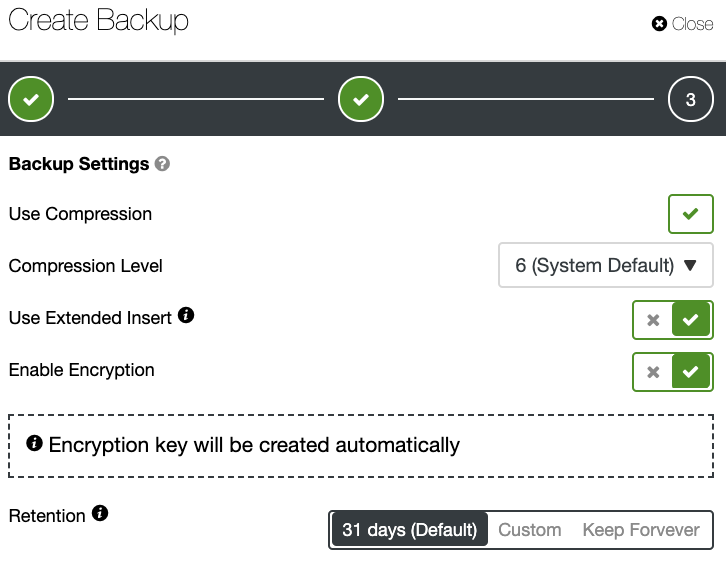
This is on a Percona Server which has an existing list of completed backup. ClusterControl allows your MySQL or MariaDB instances to create a backup in a more granular policy. It gives you more options to choose the type of backup method, the dump types, upload to the cloud once backup is done, and options when creating a backup. See below:
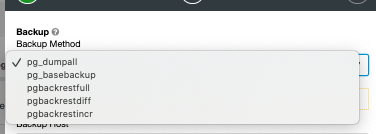
For PostgreSQL instances, the following options for the backup method are below:
While for MongoDB, it only offers a simple options to select,

All these databases allows you to store on the current node or into the ClusterControl host and allows you to upload to the cloud when this option is selected as shown below:
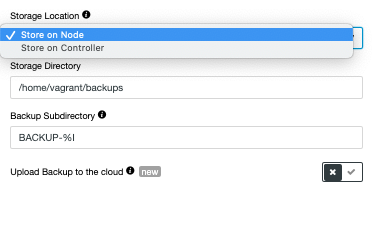
This enables your organisation to have more durability and redundancy of your backups allowing you to store not only on-site but also off-site.
Verifying Your Backup in ClusterControl
Verifying the backup exists or shown only when scheduling the backup in ClusterControl. This is an optional feature when creating a backup as shown below:

Once it’s checked, it will ask for the IP or FQDN of the host where ClusterControl can restore the database backup. See below:
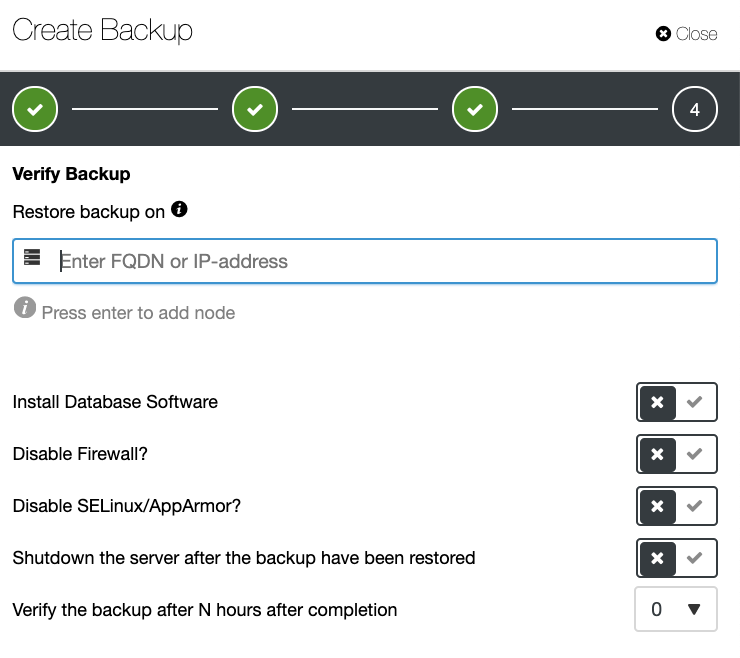
Once a backup verification is done, it will generate an alarm. Therefore notifying you how useful the backup is. See below,

Restoring a Backup in ClusterControl
Backup restoration in ClusterControl allows you to restore directly to your own cluster or over an external host. If your database cluster has experienced a total outage due to hardware failure, then restoring is fairly easy for ClusterControl. For example, this is on a PostgreSQL instance where attempting to restore will give you the following options:
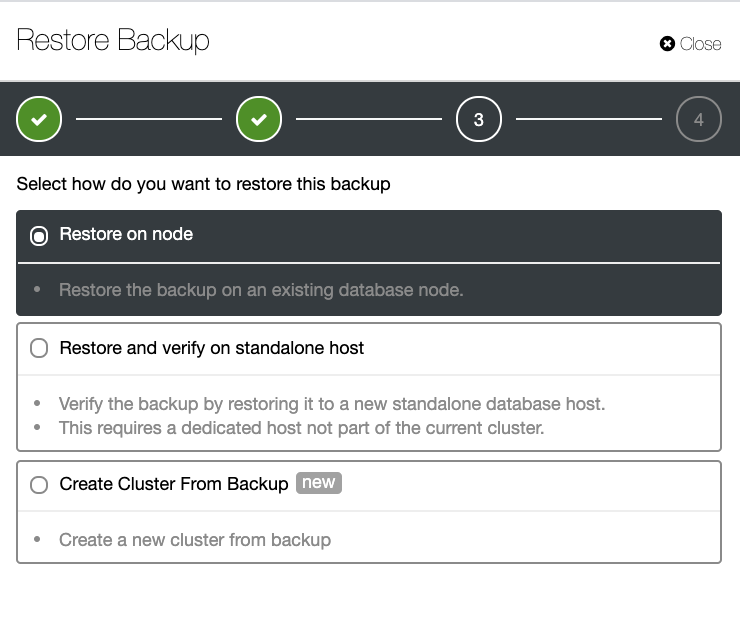
Because of this, you have more data autonomy when using ClusterControl regardless of whether your database is located on-prem, but you would also want your backups to store to the cloud for more durability, high availability, and redundancy.
Conclusion
It’s a matter of requirements on how you would use your backups based on your RTO and RPO. The most important thing here is to always make sure that your backup has been stored in multiple locations. Make sure it’s a disparate location so it has more availability, durability, and redundancy of your data when needed. Use the tools available in the market that suits your requirements and make sure data is transmitted securely and stored safely.




{kind=link}