blog
6 Common Failure Scenarios for MySQL & MariaDB, and How to Fix Them

It this blog post, we will analyze 6 different failure scenarios in production database systems, ranging from single-server issues to multi-datacenter failover plans. We will walk you through recovery and failover procedures for the respective scenario. Hopefully, this will give you a good understanding of the risks you might face and things to consider when designing your infrastructure.
Database Schema Corrupted
Let’s start with single node installation – a database setup in the simplest form. Easy to implement, at the lowest cost. In this scenario, you run multiple applications on the single server where each of the database schemas belongs to the different application. The approach for recovery of a single schema would depend on several factors.
- Do I have any backup?
- Do I have a backup and how fast can I restore it?
- What kind of storage engine is in use?
- Do I have a PITR-compatible (point in time recovery) backup?
Data corruption can be identified by mysqlcheck.
mysqlcheck -uroot -p Replace DATABASE with the name of the database, and replace TABLE with the name of the table that you want to check:
mysqlcheck -uroot -pMysqlcheck checks the specified database and tables. If a table passes the check, mysqlcheck displays OK for the table. In below example, we can see that the table salaries requires recovery.
employees.departments OK
employees.dept_emp OK
employees.dept_manager OK
employees.employees OK
Employees.salaries
Warning : Tablespace is missing for table 'employees/salaries'
Error : Table 'employees.salaries' doesn't exist in engine
status : Operation failed
employees.titles OKFor a single node installation with no additional DR servers, the primary approach would be to restore data from backup. But this is not the only thing you need to consider. Having multiple database schema under the same instance causes an issue when you have to bring your server down to restore data. Another question is if you can afford to rollback all of your databases to the last backup. In most cases, that would not be possible.
There are some exceptions here. It is possible to restore a single table or database from the last backup when point in time recovery is not needed. Such process is more complicated. If you have mysqldump, you can extract your database from it. If you run binary backups with xtradbackup or mariabackup and you have enabled table per file, then it is possible.
Here is how to check if you have a table per file option enabled.
mysql> SET GLOBAL innodb_file_per_table=1; With innodb_file_per_table enabled, you can store InnoDB tables in a tbl_name .ibd file. Unlike the MyISAM storage engine, with its separate tbl_name .MYD and tbl_name .MYI files for indexes and data, InnoDB stores the data and the indexes together in a single .ibd file. To check your storage engine you need to run:
mysql> select table_name,engine from information_schema.tables where table_name='table_name' and table_schema='database_name';or directly from the console:
[root@master ~]# mysql -u -p -D -e "show table statusG"
Enter password:
*************************** 1. row ***************************
Name: test1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 12
Avg_row_length: 1365
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2018-05-24 17:54:33
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment: To restore tables from xtradbackup, you need to go through an export process. Backup needs to be prepared before it can be restored. Exporting is done in the preparation stage. Once a full backup is created, run standard prepare procedure with the additional flag –export :
innobackupex --apply-log --export /u01/backupThis will create additional export files which you will use later on in the import phase. To import a table to another server, first create a new table with the same structure as the one that will be imported at that server:
mysql> CREATE TABLE corrupted_table (...) ENGINE=InnoDB;discard the tablespace:
mysql> ALTER TABLE mydatabase.mytable DISCARD TABLESPACE;Then copy mytable.ibd and mytable.exp files to database’s home, and import its tablespace:
mysql> ALTER TABLE mydatabase.mytable IMPORT TABLESPACE;However to do this in a more controlled way, the recommendation would be to restore a database backup in other instance/server and copy what is needed back to the main system. To do so, you need to run the installation of the mysql instance. This could be done either on the same machine – but requires more effort to configure in a way that both instances can run on the same machine – for example, that would require different communication settings.
You can combine both task restore and installation using ClusterControl.
ClusterControl will walk you through the available backups on-prem or in the cloud, let you choose exact time for a restore or the precise log position, and install a new database instance if needed.
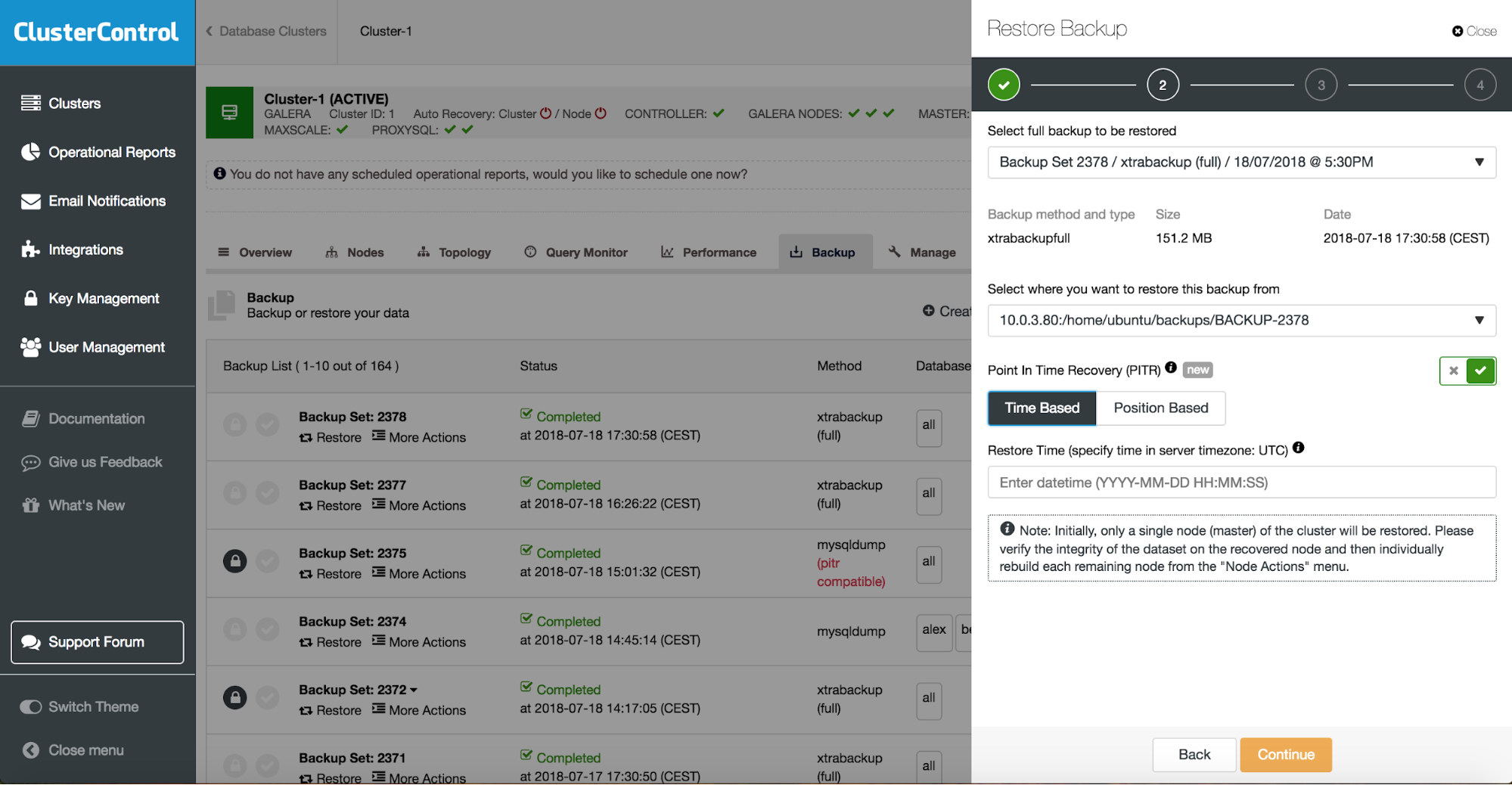
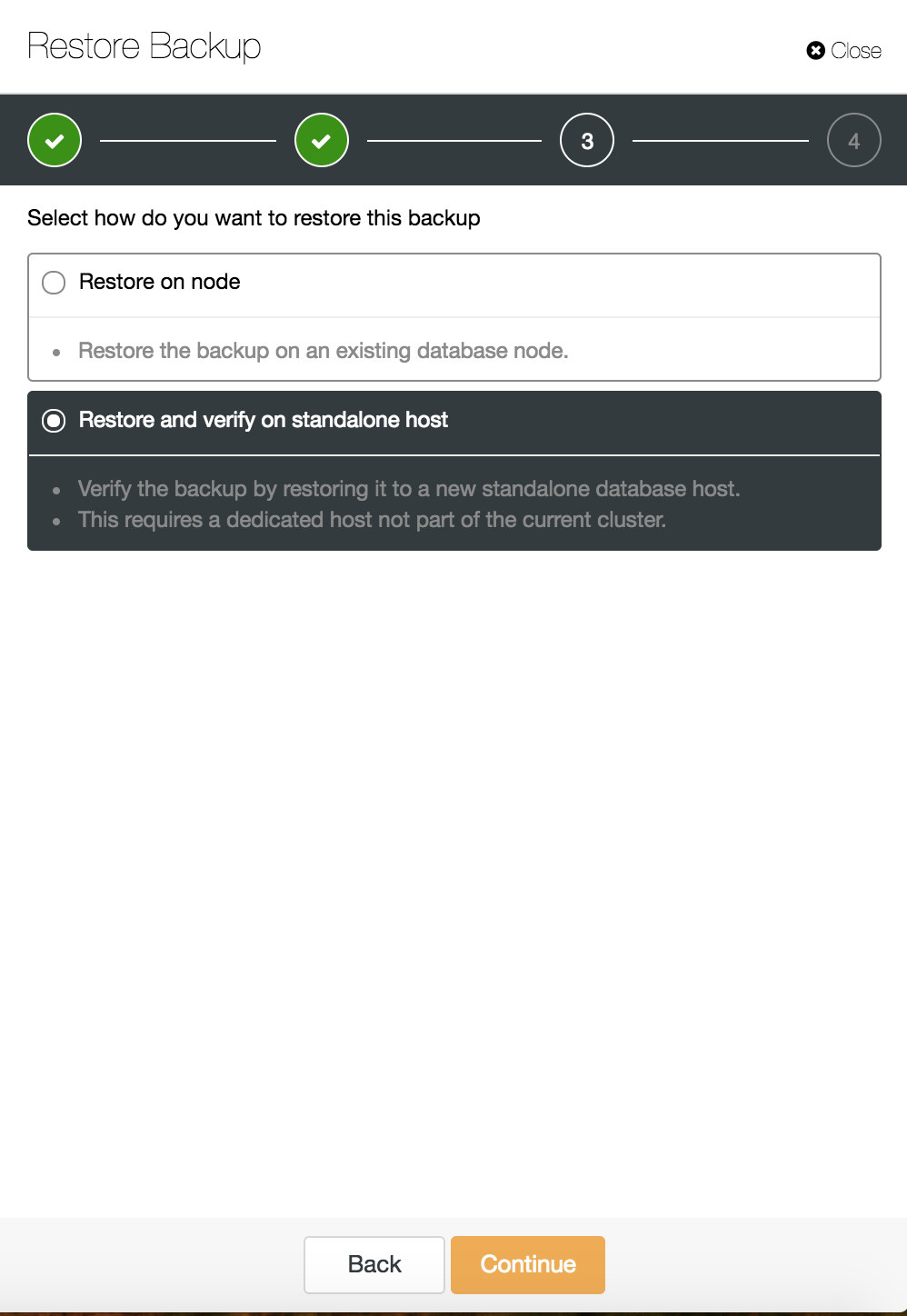
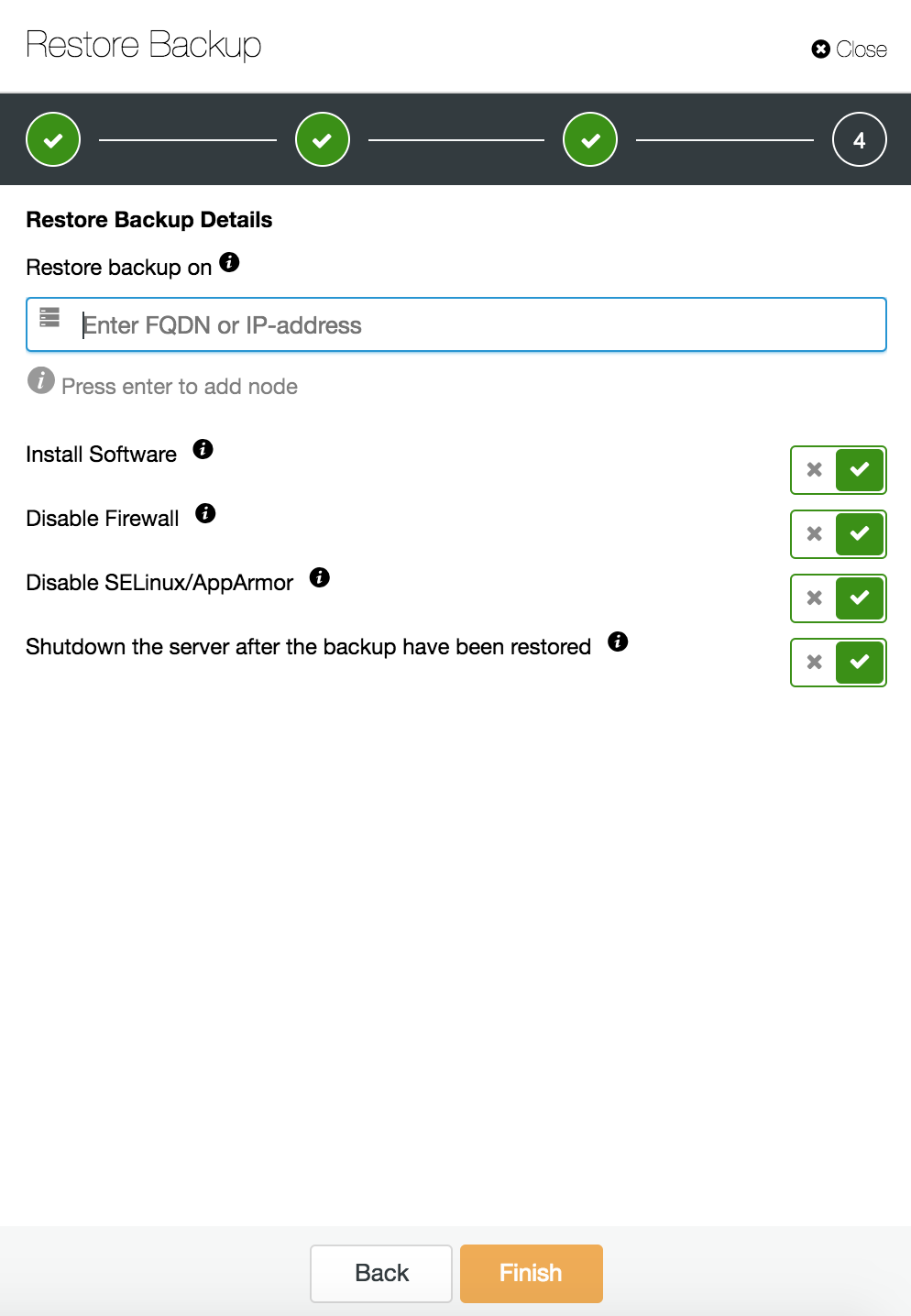
You can find more information about data recovery in blog My MySQL Database is Corrupted… What Do I Do Now?
Database Instance Corrupted on the Dedicated Server
Defects in the underlying platform are often the cause for database corruption. Your MySQL instance relies on a number of things to store and retrieve data – disk subsystem, controllers, communication channels, drivers and firmware. A crash can affect parts of your data, mysql binaries or even backup files that you store on the system. To separate different applications, you can place them on dedicated servers.
Different application schemas on separate systems is a good idea if you can afford them. One may say that this is a waste of resources, but there is a chance that the business impact will be less if only one of them goes down. But even then, you need to protect your database from data loss. Storing backup on the same server is not a bad idea as long you have a copy somewhere else. These days, cloud storage is an excellent alternative to tape backup.
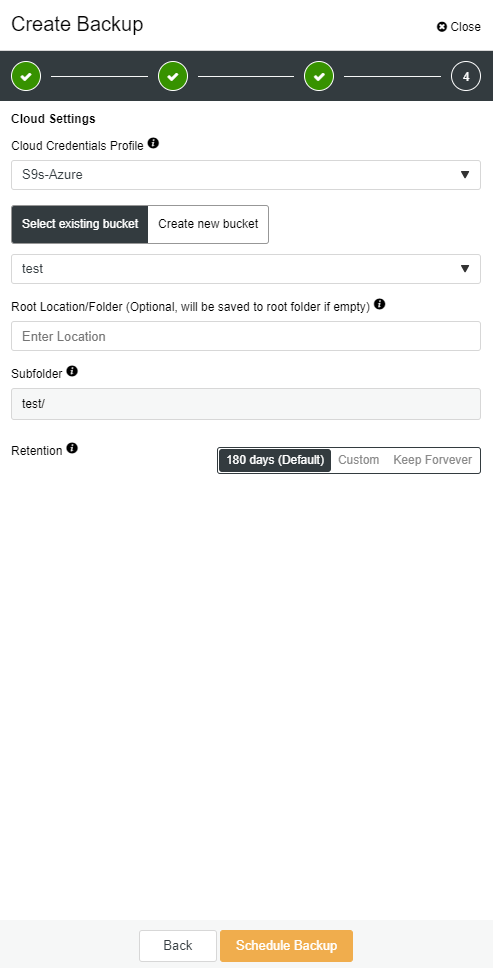
ClusterControl enables you to keep a copy of your backup in the cloud. It supports uploading to the top 3 cloud providers – Amazon AWS, Google Cloud, and Microsoft Azure.
When you have your full backup restored, you may want to restore it to certain point in time. Point-in-time recovery will bring server up to date to a more recent time than when the full backup was taken. To do so, you need to have your binary logs enabled. You can check available binary logs with:
mysql> SHOW BINARY LOGS;And current log file with:
SHOW MASTER STATUS;Then you can capture incremental data by passing binary logs into sql file. Missing operations can be then re-executed.
mysqlbinlog --start-position='14231131' --verbose /var/lib/mysql/binlog.000010 /var/lib/mysql/binlog.000011 /var/lib/mysql/binlog.000012 /var/lib/mysql/binlog.000013 /var/lib/mysql/binlog.000015 > binlog.outThe same can be done in ClusterControl.
Database Slave Goes Down
Ok, so you have your database running on a dedicated server. You created a sophisticated backup schedule with a combination of full and incremental backups, upload them to the cloud and store the latest backup on local disks for fast recovery. You have different backup retention policies – shorter for backups stored on local disk drivers and extended for your cloud backups.
It sounds like you are well prepared for a disaster scenario. But when it comes to the restore time, it may not satisfy your business needs.
You need a quick failover function. A server that will be up and running applying binary logs from the master where writes happen. Master/Slave replication starts a new chapter in the failover scenario. It’s a fast method to bring your application back to life if you master goes down.
But there are few things to consider in the failover scenario. One is to setup a delayed replication slave, so you can react to fat finger commands that were triggered on the master server. A slave server can lag behind the master by at least a specified amount of time. The default delay is 0 seconds. Use the MASTER_DELAY option for CHANGE MASTER TO to set the delay to N seconds:
CHANGE MASTER TO MASTER_DELAY = N;Second is to enable automated failover. There are many automated failover solutions on the market. You can set up automatic failover with command line tools like MHA, MRM, mysqlfailover or GUI Orchestrator and ClusterControl. When it’s set up correctly, it can significantly reduce your outage.
ClusterControl supports automated failover for MySQL, PostgreSQL and MongoDB replications as well as multi-master cluster solutions Galera and NDB.
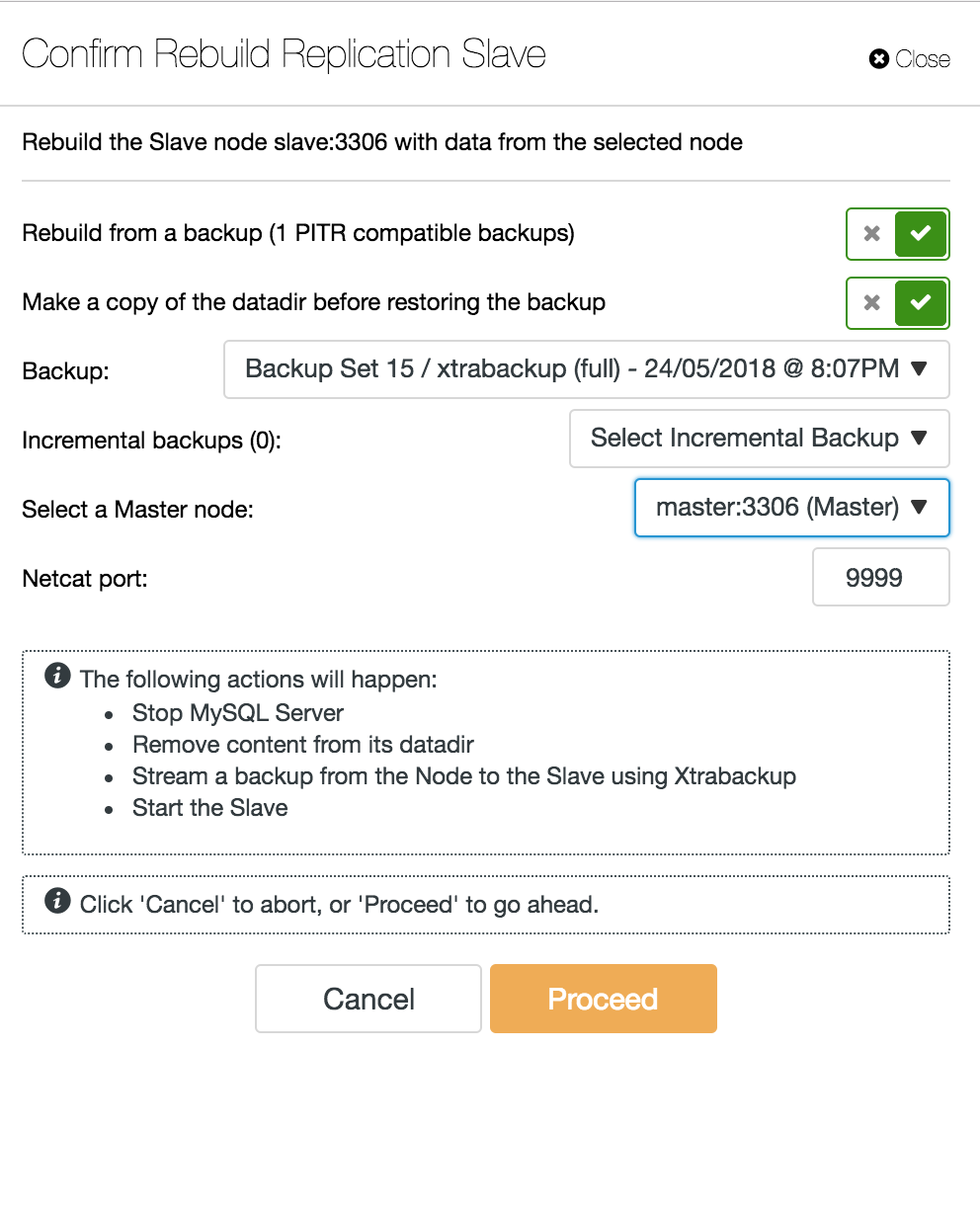
When a slave node crashes and the server is severely lagging behind, you may want to rebuild your slave server. The slave rebuild process is similar to restoring from backup.
Database Multi-Master Server Goes Down
Now when you have slave server acting as a DR node, and your failover process is well automated and tested, your DBA life becomes more comfortable. That’s true, but there are a few more puzzles to solve. Computing power is not free, and your business team may ask you to better utilize your hardware, you may want to use your slave server not only as passive server, but also to serve write operations.
You may then want to investigate a multi-master replication solution. Galera Cluster has become a mainstream option for high availability MySQL and MariaDB. And though it is now known as a credible replacement for traditional MySQL master-slave architectures, it is not a drop-in replacement.
Galera cluster has a shared nothing architecture. Instead of shared disks, Galera uses certification based replication with group communication and transaction ordering to achieve synchronous replication. A database cluster should be able to survive a loss of a node, although it’s achieved in different ways. In case of Galera, the critical aspect is the number of nodes. Galera requires a quorum to stay operational. A three node cluster can survive the crash of one node. With more nodes in your cluster, you can survive more failures.
Recovery process is automated so you don’t need to perfom any failover operations. However the good practice would be to kill nodes and see how fast you can bring them back. In order to make this operation more efficient, you can modify the galera cache size. If the galera cache size is not properly planned, your next booting node will have to take a full backup instead of only missing write-sets in the cache.
The failover scenario is simple as starting the intance. Based on the data in the galera cache, the booting node will perfom SST (restore from full backup) or IST (apply missing write-sets). However, this is often linked to human intervention. If you want to automate the entire failover process, you can use ClusterControl’s autorecovery functionality (node and cluster level).

Estimate galera cache size:
MariaDB [(none)]> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;To make failover more consistent, you should enable gcache.recover=yes in mycnf. This option will revive the galera-cache on restart. This means the node can act as a DONOR and service missing write-sets (facilitating IST, instead of using SST).
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 2,
members = 2/3 (joined/total),
act_id = 12810,
last_appl. = 0,
protocols = 0/7/3 (gcs/repl/appl),
group UUID = 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Trying to continue unpaused monitor
2018-07-20 8:59:44 139657311033088 [Note] WSREP: New cluster view: global state: 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69:12810, view# 3: Primary, number of nodes: 3, my index: 1, protocol version 3Proxy SQL node goes down
If you have a virtual IP setup, all you have to do is to point your application to the virtual IP address and everything should be correct connection wise. It’s not enough to have your database instances spanning across multiple datacenters, you still need your applications to access them. Assume you have scaled out the number of read replicas, you might want to implement virtual IPs for each of those read replicas as well because of maintenance or availability reasons. It might become a cumbersome pool of virtual IPs that you have to manage. If one of those read replicas face a crash, you need to re-assign the virtual IP to the different host, or else your application will connect to either a host that is down or in the worst case, a lagging server with stale data.
Crashes are not frequent, but more probable than servers going down. If for whatever reason, a slave goes down, something like ProxySQL will redirect all of the traffic to the master, with the risk of overloading it. When the slave recovers, traffic will be redirected back to it. Usually, such downtime shouldn’t take more than a couple of minutes, so the overall severity is medium, even though the probability is also medium.
To have your load balancer components redundant, you can use keepalived.
Datacenter Goes Down
The main problem with replication is that there is no majority mechanism to detect a datacenter failure and serve a new master. One of the resolutions is to use Orchestrator/Raft. Orchestrator is a topology supervisor that can control failovers. When used along with Raft, Orchestrator will become quorum-aware. One of the Orchestrator instances is elected as a leader and executes recovery tasks. The connection between orchestrator node does not correlate to transactional database commits and is sparse.
Orchestrator/Raft can use extra instances which perfom monitoring of the topology. In the case of network partitioning, the partitioned Orchestrator instances won’t take any action. The part of the Orchestrator cluster which has the quorum will elect a new master and make the necessary topology changes.
ClusterControl is used for management, scaling and, what’s most important, node recovery – Orchestrator would handle failovers, but if a slave would crash, ClusterControl will make sure it will be recovered. Orchestrator and ClusterControl would be located in the same availability zone, separated from the MySQL nodes, to make sure their activity won’t be affected by network splits between availability zones in the data center.



