blog
My MySQL Database is Corrupted… What Do I Do Now?

How do MySQL tables get corrupted? There are many ways to spoil data files. Often, corruption is due to defects in the underlying platform, which MySQL relies on to store and retrieve data – disk subsystem, controllers, communication channels, drivers, firmware or other hardware faults. Data corruption can also occur if the MySQL server daemon restarts suddenly, or your server reboots due to a crash of other OS components. If the database instance was in the middle of writing data to disk, it could write the data partially which may end up with a page checksum that is different than expected. There have also been bugs in MySQL so even if the server hardware is ok, MySQL itself can cause corruption.
Usually when MySQL data gets corrupted the recommendation is to restore it from the last backup, switch to DR server or take down the affected node if you have Galera cluster to serve data immediately from other nodes. In some cases you can’t – if the backup is not there, the cluster was never set up, your replication is down for a very long time, or the DR procedure was never tested. Even if you have a backup, you may still want to take some actions to attempt recovery as it may take less time get back online.
MyISAM, the bad and ugly
InnoDB is more fault-tolerant than MyISAM. InnoDB has auto_recovery features and is much safer as compared to the older MyISAM engine.
MyISAM tables can easily get corrupted when lots of writes happen and a lot of locks happen on that table. The storage engine “writes” data to the filesystem cache, which may take some time before it is flushed to disk. Therefore if your server restarts suddenly, some unknown amount of data in the cache is lost. That’s a usual way for MyISAM data to be corrupted. The recommendation is to migrate from MyISAM to InnoDB, but there may be cases where this is not possible.
Primum non nocere, the backup
Before you attempt to repair corrupted tables, you should back your database files first. Yes, it’s already broken but this is to minimize the risk of possible further damage which may be caused by a recovery operation. There is no guarantee that any action you take will not harm untouched data blocks. Forcing InnoDB recovery with values greater than 4 can corrupt data files, so make sure you will do it with prior backup and ideally on a separate physical copy of the database.
To back up all of the files from all of your databases, follow these steps:
Stop the MySQL server
service mysqld stopType the following command for your datadir.
cp -r /var/lib/mysql /var/lib/mysql_bkpAfter we have a backup copy of the data directory, we are ready to start troubleshooting.
Data Corruption Identification
The error log is your best friend. Usually, when data corruption happens, you will find relevant information (including links to documentation) in the error log. If you don’t know where it’s located, check my.cnf and variable log_error, for more details check this article https://dev.mysql.com/doc/refman/8.0/en/error-log-destination-configuration.html. What you should also know is your storage engine type. You can find this information in the error log or in information_schema.
mysql> select table_name,engine from information_schema.tables where table_name = '' and table_schema = '
The main tools/commands to diagnose issues with data corruption are CHECK TABLE, REPAIR TABLE, and myisamchk. The mysqlcheck client performs table maintenance: It checks, repairs (MyISAM), optimizes or analyzes tables while MySQL is running.
mysqlcheck -uroot -p
Replace DATABASE with the name of the database, and replace TABLE with the name of the table that you want to check:
mysqlcheck -uroot -p
Mysqlcheck checks the specified database and tables. If a table passes the check, mysqlcheck displays OK for the table.
employees.departments OK
employees.dept_emp OK
employees.dept_manager OK
employees.employees OK
Employees.salaries
Warning : Tablespace is missing for table 'employees/salaries'
Error : Table 'employees.salaries' doesn't exist in engine
status : Operation failed
employees.titles OK
Data corruption issues may be also related to permission issues. In some cases, OS can switch mount point to read-only mode due to R/W issues or this can be caused by a user who accidentally changed ownership of the data files. In such cases, you will find relevant information in the error log.
[root@node1 employees]# ls -rtla
...
-rw-rw----. 1 mysql mysql 28311552 05-10 06:24 titles.ibd
-rw-r-----. 1 root root 109051904 05-10 07:09 salaries.ibd
drwxr-xr-x. 7 mysql mysql 4096 05-10 07:12 ..
drwx------. 2 mysql mysql 4096 05-10 07:17 .
MySQL Client
MariaDB [employees]> select count(*) from salaries;
ERROR 1932 (42S02): Table 'employees.salaries' doesn't exist in engine
Error log entry
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: Failed to find tablespace for table `employees`.`salaries` in the cache. Attempting to load the tablespace with space id 9
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: Operating system error number 13 in a file operation.
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: The error means mysqld does not have the access rights to the directory.
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: Cannot open datafile for read-only: './employees/salaries.ibd' OS error: 81
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: Operating system error number 13 in a file operation.
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: The error means mysqld does not have the access rights to the directory.
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: Could not find a valid tablespace file for `employees/salaries`. Please refer to http://dev.mysql.com/doc/refman/5.7/en/innodb-troubleshooting-datadict.html for how to resolve the issue.
Recovering InnoDB table
If you are using the InnoDB storage engine for a database table, you can run the InnoDB recovery process.
To enable auto recovery MySQL needs innodb_force_recovery option to be enabled. Innodb_force_recovery forces InnoDB to start up while preventing background operations from running, so that you can dump your tables.
To do this open my.cnf and add the following line to the [mysqld] section:
[mysqld]
innodb_force_recovery=1
service mysql restart
You should start from innodb_force_recovery=1 save the changes to my.cnf file, and then restart the MySQL server using the appropriate command for your operating system. If you are able to dump your tables with an innodb_force_recovery value of 3 or less, then you are relatively safe. In many cases you will have to go up to 4 and as you already know that can corrupt data.
[mysqld]
innodb_force_recovery=1
service mysql restart
If needed change to the higher value, six is the maximum and most dangerous.
Once you are able to start your database, type the following command to export all of the databases to the databases.sql file:
mysqldump --all-databases --add-drop-database --add-drop-table > dump.sql
Start mysql, and then try to drop the affected database or databases using the DROP DATABASE command. If MySQL is unable to drop a database, you can delete it manually using the steps below after you stop the MySQL server.
service mysqld stop
If you were unable to drop a database, type the following commands to delete it manually.
cd /var/lib/mysql
rm -rf
Make sure you do not delete the internal database directories.
After you are done, comment out the following line in the [mysqld] to disable InnoDB recovery mode.
#innodb_force_recovery=...
Save the changes to the my.cnf file, and then start the MySQL server
service mysqld start
Type the following command to restore the databases from the backup file you created in step 5:
mysql> tee import_database.log
mysql> source dump.sql
Repairing MyISAM
If mysqlcheck reports an error for a table, type the mysqlcheck command with -repair flag to fix it. The mysqlcheck repair option works while the server is up and running.
mysqlcheck -uroot -p -r
If the server is down and for any reason mysqlcheck cannot repair your table, you still have an option to perform recovery directly on files using myisamchk. With myisamchk, you need to make sure that the server doesn't have the tables open.
Stop the MySQL
service mysqld stop
cd /var/lib/mysql
Change to the directory where the database is located.
cd /var/lib/mysql/employees
myisamchk
To check all of the tables in a database, type the following command:
myisamchk *.MYI
If the previous command does not work, you can try deleting temporary files that may be preventing myisamchk from running correctly. To do this, change back to the data dir directory, and then run the following command:
ls */*.TMD
If there are any .TMD files listed, delete them:
rm */*.TMD
Then re-run myisamchk.
To attempt repair a table, execute the following command, replacing TABLE with the name of the table that you want to repair:
myisamchk --recover
Restart the MySQL server
service mysqld start
How to avoid data loss
There are several things you can do to minimize the risk of unrecoverable data. First of all backups. The problem with backups is that sometimes they can be overlooked. For cron scheduled backups, usually we write wrapper scripts that detect problems in the backup log, but that does not include cases when the backup didn’t start at all. Cron can sometimes hang and often there is no monitoring set on it. Another potential issue could be the case when the backup was never set up. The good practice is to run reports from a separate tool that will analyze the backup status and inform you about missing backups schedules. You can use ClusterControl for that or write your own programs.
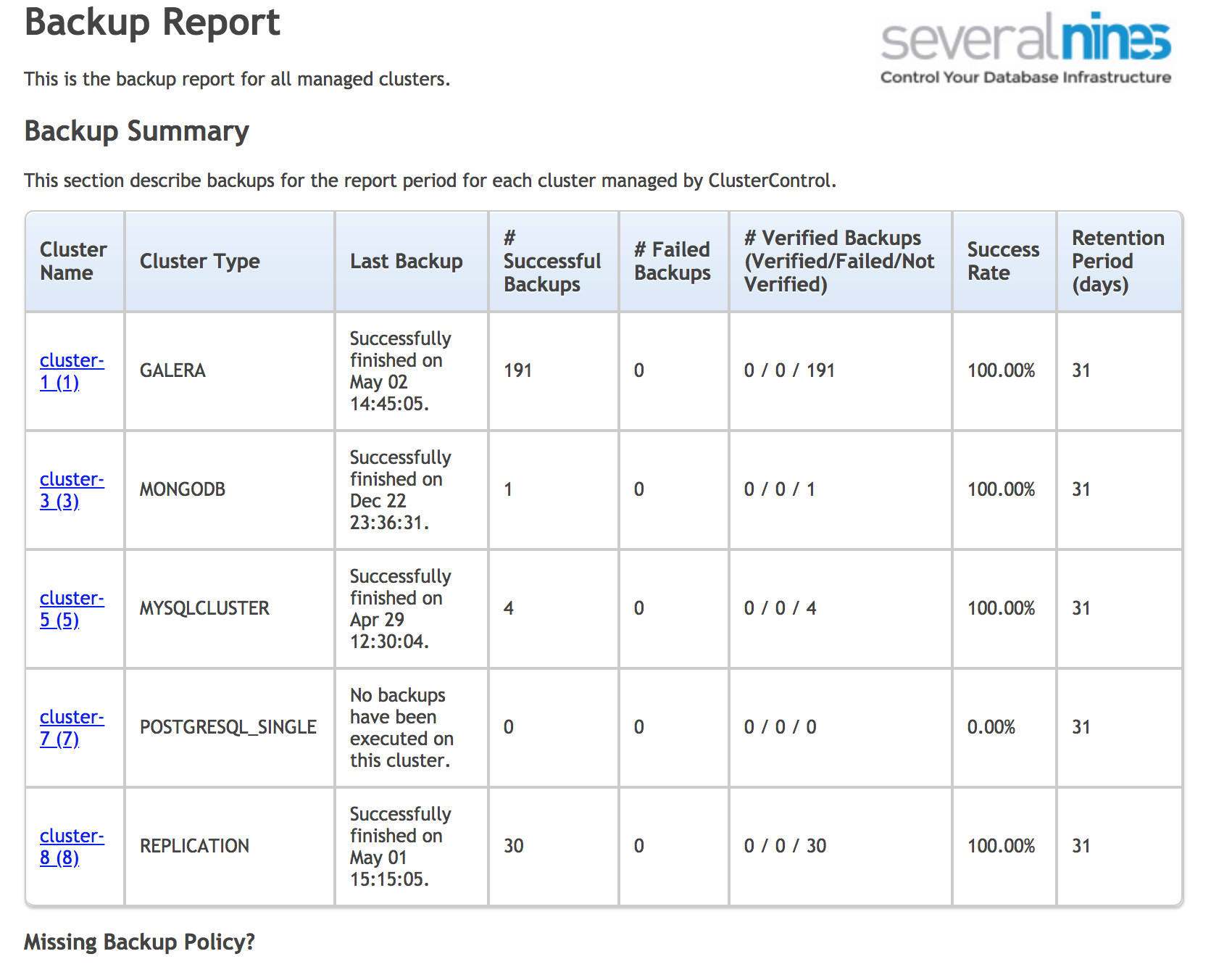 ClusterControl operational backup report
ClusterControl operational backup report
To reduce the impact of the possible data corruption you should always consider clustered systems. It’s just a matter of time when the database will crash or get corrupted, so it’s good to have a copy which you can switch to. It could be Master / Slave replication. The important aspect here is to have safe automatic recovery to minimize the complexity of the switchover and minimize the recovery time (RTO).
 ClusterControl auto recovery features
ClusterControl auto recovery features
Subscribe below to be notified of fresh posts
×
![]()



