Whitepapers
Galera cluster for MySQL

This white paper provides a tutorial covering basic information about Galera Cluster for MySQL/MariaDB, with information about the latest features introduced.
There is also a more hands-on, practical section on how to quickly deploy and manage a replication setup using ClusterControl. You would need 4 hosts/VMs if you plan on doing this practical exercise.
Content of the white paper
- How does Galera Cluster work?
- How is Galera Cluster different from MySQL replication?
- What is the recommended setup for a Galera Cluster?
- What are the benefits and drawbacks of Galera Cluster?
- What are the benefits of combining Galera Cluster and MySQL Replication in the same setup?
- What are the differences, if any, between the three Galera vendors (Codership, MariaDB and Percona)?
- How do I manage my Galera Cluster?
- What backup strategies should I use with Galera?
What is Galera Cluster?
Galera Cluster is a synchronous multi-master replication plug-in for InnoDB. It is very different from the regular MySQL Replication, and addresses a number of issues including write conflicts when writing on multiple masters, replication lag and slaves being out of sync with the master. Users do not have to know which server they can write to (the master) and which servers they can read from (the slaves).
An application can write to any node in a Galera cluster, and transaction commits (row-based replication events) are then applied on all servers, via a certification-based replication. Certification-based replication is an alternative approach to synchronous database replication using Group Communication and transaction ordering techniques.
A minimal Galera cluster consists of 3 nodes and it is recommended to run with odd number of nodes. The reason is that, should there be a problem applying a transaction on one node (e.g., network problem or the machine becomes unresponsive), the two other nodes will have a quorum (i.e. a majority) and will be able to proceed with the transaction commit.
This plug-in is open-source and developed by Codership as a patch for standard MySQL. There are 3 Galera variants – MySQL Galera Cluster by Codership, Percona XtraDB Cluster by Percona and MariaDB Galera Cluster (5.5 and 10.0) by MariaDB. Starting from MariaDB Server 10.1, the Galera is already included in the regular server (and not anymore in a separate cluster version). Enabling Galera cluster is just a matter of activating the correct configuration parameters in any MariaDB Server installation.
MySQL Replication and Galera Cluster differences
The following diagram illustrates some high-level differences between MySQL Replication and Galera Cluster:
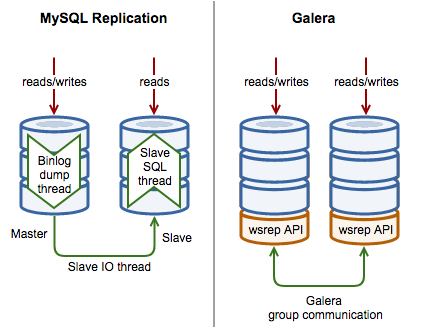
MySQL Replication Implementation
MySQL uses 3 threads to implement replication, one on the master and two on the slaves per master-slave connection:
- Binlog dump thread – The master creates a thread to send the binary log contents to a slave when the slave connects. This thread can be identified in the output of SHOW PROCESSLIST on the master as the Binlog Dump thread.
- Slave IO thread – The slave creates an IO thread, which connects to the master and asks it to send the updates recorded in its binary logs. The slave I/O thread reads the updates that the master’s Binlog Dump thread sends and copies them to local files that comprise the slave’s relay log.
- Slave SQL thread – The slave creates an SQL thread to read the relay log that is written by the slave I/O thread and execute the events contained therein.
MySQL Replication is part of the standard MySQL database, and is mainly asynchronous in nature. Updates should always be done on one master, these are then propagated to slaves. It is possible to create a ring topology with multiple masters, however this is not recommended as it is very easy for the servers to get out of sync in case of a master failing. With introduction of GTID in MySQL 5.6 and later, it simplifies the management of the replication data flow and failover activities in particular, however, there is no automatic failover or resynchronization.
Galera Cluster Implementation
Galera Cluster implements replication using 4 components:
- Database Management System – The database server that runs on the individual node. The supported DBMS are MySQL Server, Percona Server for MySQL and MariaDB Server.
- wsrep API – The interface and the responsibilities for the database server and replication provider. It provides integration with the database server engine for write-set replication.
- Galera Plugin – The plugin that enables the write-set replication service functionality.
- Group Communication plugins – The various group communication systems available to Galera Cluster.
A database vendor that would like to leverage Galera Cluster technology would need to incorporate the WriteSet Replication (wsrep) API patch into its database server codebase. This will allow the Galera plugin which works as a wsrep provider to communicate and replicate transactions (writesets in Galera terms) via group communication protocol. This enables a synchronous master-master setup for InnoDB. Transactions are synchronously committed on all nodes.
In case of a node failing, the other nodes will continue to operate and kept up to date. When the failed node comes up again, it automatically synchronizes with the other nodes through State Snapshot Transfer (SST) or Incremental State Transfer (IST) depending on the last known state, before it is allowed back into the cluster. No data is lost when a node fails.
Galera Cluster makes use of certification based replication, that is a form of synchronous replication with reduced overhead.
What is Certification based Replication?
Certification based replication uses group communication and transaction ordering techniques to achieve synchronous replication. Transactions execute optimistically in a single node (or replica) and, at commit time, run a coordinated certification process to enforce global consistency. Global coordination is achieved with the help of a broadcast service, that establishes a global total order among concurrent transactions.
Pre-requisites for certification based replication:
- database is transactional (i.e. it can rollback uncommitted changes)
- each replication event changes the database atomically
- replicated events are globally ordered (i.e. applied on all instances in the same order)
The main idea is that a transaction is executed conventionally until the commit point, under the assumption that there will be no conflict. This is called optimistic execution. When the client issues a COMMIT command (but before the actual commit has happened), all changes made to the database by the transaction and the primary keys of changed rows are collected into a writeset. This writeset is then replicated to the rest of the nodes. After that, the writeset undergoes a deterministic certification test (using the collected primary keys) on each node (including the writeset originator node) which determines if the writeset can be applied or not.
If the certification test fails, the writeset is dropped and the original transaction is rolled back. If the test succeeds, the transaction is committed and the writeset is applied on the rest of the nodes.
The certification test implemented in Galera depends on the global ordering of transactions. Each transaction is assigned a global ordinal sequence number during replication. Thus, when a transaction reaches the commit point, it is known what was the sequence number of the last transaction it did not conflict with. The interval between those two numbers is an uncertainty land: transactions in this interval have not seen the effects of each other. Therefore, all transactions in this interval are checked for primary key conflicts with the transaction in question. The certification test fails if a conflict is detected.
Since the procedure is deterministic and all replicas receive transactions in the same order, all nodes reach the same decision about the outcome of the transaction. The node that started the transaction can then notify the client application if the transaction has been committed or not.
Certification based replication (or more precisely, certification-based conflict resolution) is based on academic research, in particular on Fernando Pedone’s Ph.D. thesis.
Galera Cluster Strengths and Weaknesses
Galera Cluster has a number of benefits:
- A high availability solution with synchronous replication, failover and resynchronization
- No loss of data
- All servers have up-to-date data (no slave lag)
- Read scalability
- ‘Pretty good’ write scalability
- High availability across data centers
Like any solution, there are some limitations:
- It supports only InnoDB or XtraDB storage engine
- With increasing number of writeable masters, the transaction rollback rate may increase, especially if there is write contention on the same dataset (a.k.a hotspot). This increases transaction latency.
- It is possible for a slow/overloaded master node to affect performance of the Galera Cluster, therefore it is recommended to have uniform servers across the cluster.
We would suggest you to also look at these resources which explains the subject in great details:
- Is Synchronous Replication Right for your App
- MariaDB Galera Cluster – Known Limitations
- Webinar: Migrating to Galera Cluster
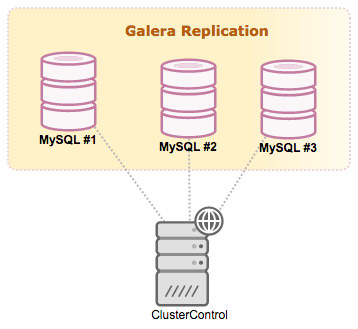
Deploying a Galera Cluster with ClusterControl
A Galera Cluster can be deployed using ClusterControl. Our architecture is illustrated as below:
Install ClusterControl by following the instructions on the Getting Started page. Do not forget to setup passwordless SSH from ClusterControl to all nodes (including the ClusterControl node itself). We are going to use root user for deployment. On ClusterControl node as root user, run:
$ ssh-keygen -t rsa
$ ssh-copy-id 192.168.10.100 # clustercontrol
$ ssh-copy-id 192.168.10.101 # galera1
$ ssh-copy-id 192.168.10.102 # galera2
$ ssh-copy-id 192.168.10.103 # galera3Open the ClusterControl UI, go to the “Deploy Database Cluster” and open the “MySQL Galera” tab. In the dialog, there are two steps as shown in the following screenshots.
Cluster Deployment
General and SSH Settings
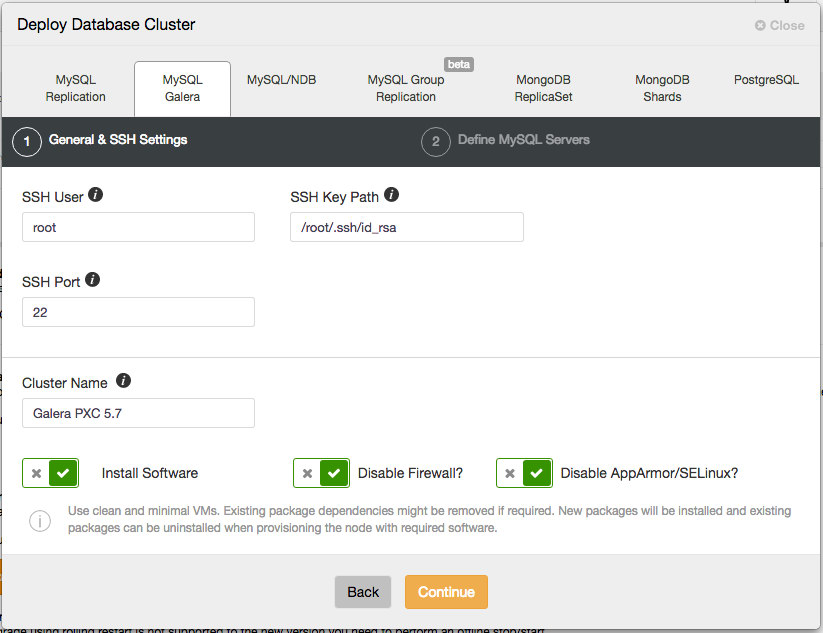
Under “General & SSH Settings”, specify the required information:
- SSH User – Specify the SSH user that ClusterControl will use to connect to the target host.
- SSH Key Path – Passwordless SSH requires an SSH key. Specify the physical path to the key file here.
- Sudo Password – Sudo password if the sudo user uses password to escalate privileges. Otherwise, leave it blank.
- SSH Port Number – Self-explanatory. Default is 22.
- Cluster Name – Name of the cluster that will be deployed.
Keep the checkboxes as default so ClusterControl installs the software and configures the security options accordingly. If you would like to to keep the firewall settings, uncheck the “Disable Firewall” however make sure MySQL related ports are opened before the deployment begins, as shown in this documentation page.
Define MySQL Servers
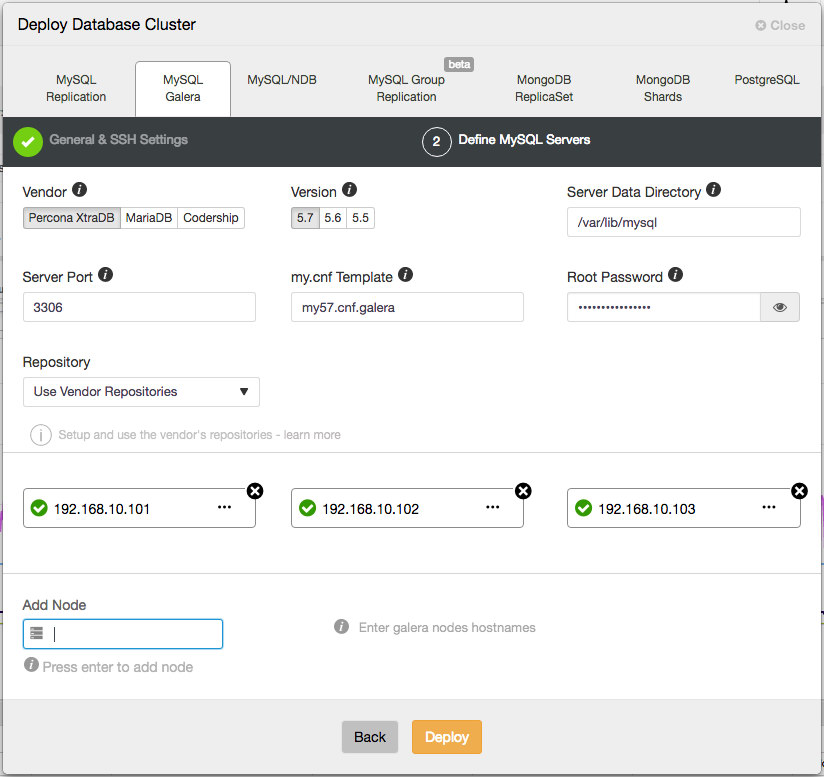
Move to the next tab, define the MySQL Servers installation and configuration options:
- Vendor – Currently supported vendor is Percona Server, MariaDB and Codership.
- Version – MySQL major version. Version 5.7 (Codership/Percona) or 10.1 (MariaDB) is recommended.
- Server Data Directory – The physical location of MySQL data directory. Default is /var/lib/mysql.
- Server Port – MySQL server port. Default is 3306.
- my.cnf Template – MySQL configuration template. Leave it to use the default template located under
/usr/share/cmon/templates. - Root Password – MySQL root password. ClusterControl will set this up for you.
- Repository – Choose the default value is recommended, unless if you want to use existing repositories on the database nodes. You can also choose “Create New Repository” to create and mirror the current database vendor’s repository and then deploy using the local mirrored repository.
- Add Node – Specify the IP address or hostname of the target hosts. ClusterControl must able to reach the specified server through passwordless SSH.
ClusterControl then performs the necessary actions to provision, install, configure and monitor the Galera nodes. Once the deployment completes, you will see the database cluster in the ClusterControl dashboard.
Scaling Out
Introducing a new Galera node is automatic. It follows the same process as recovering a failed node. When the node is introduced, the state is expected to be empty, thus Galera will do a full state snapshot transfer (SST) from the selected donor.
Using ClusterControl, adding a new Galera node is very straightforward. You just need to setup passwordless SSH to the target node and then go to ClusterControl > Cluster Actions > Add Node > Create and add a new DB Node:
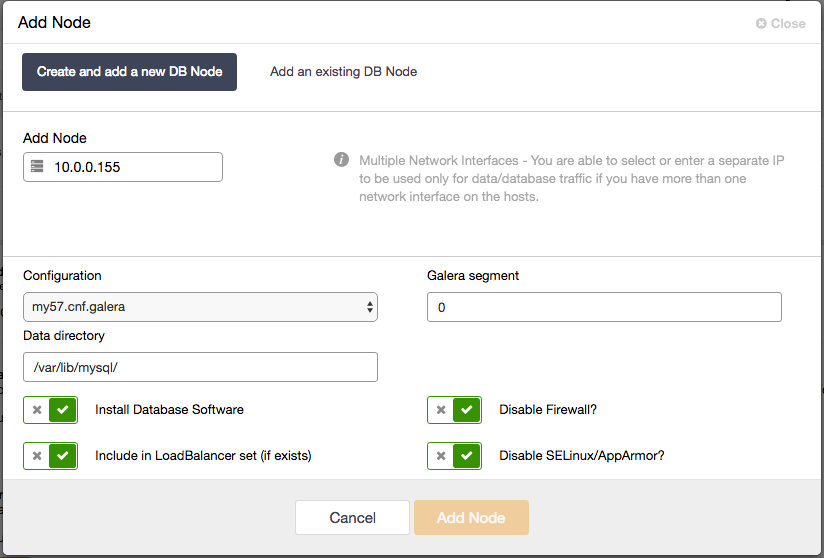
If you already have a load balancer deployed, you can set “Include in LoadBalancer set” to true so ClusterControl will automatically add it into the chosen load balancer.
Scaling Down
Scaling down is trivial. You just need to remove the corresponding database node from Galera through the ClusterControl UI by clicking on the “X” icon under Nodes page. If a Galera node stops with a proper shutdown, the node is marked as leaving the cluster gracefully and can be considered as a scale down. ClusterControl will then remove the node from the load balancer (if exists) and update the wsrep_cluster_address variable on the available nodes accordingly.
Attaching Replication Slave
Another common setup in Galera Cluster is to have an asynchronous replication slave attach to it. There are a few good reasons to attach an asynchronous slave to a Galera Cluster. For one, long-running reporting/OLAP type queries on a Galera node might slow down an entire cluster, if the reporting load is so intensive that the node has to spend considerable effort coping with it. So reporting queries can be sent to a standalone server, effectively isolating Galera from the reporting load. An asynchronous slave can also serve as a remote live backup.
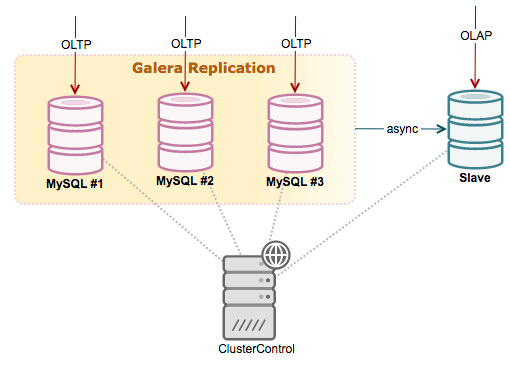
To add a new replication slave, you have to perform the following steps:
- Enable binary logging on the selected Galera node (master). Go to ClusterControl > Nodes > choose the Galera node > Node Actions > Enable Binary Logging. This requires a MySQL restart on the corresponding node. You can repeat this step for the rest of the Galera nodes if you would like to have multiple masters.
- Setup a passwordless SSH to the target node.
- Go to ClusterControl > Cluster Actions > Add a Replication Slave > New Replication Slave and specify the required information like the slave node IP address/hostname, pick the right master and streaming port.
There is also an option to setup a delayed slave by specifying the amount of time in seconds. We have covered this in details in this blog post, How to Set Up Asynchronous Replication from Galera Cluster to Standalone MySQL server with GTID.
Accessing the Galera Cluster
By now, we should have a Galera Cluster setup ready. The next thing is to import an existing database or to create a brand new database for a new application. Galera Cluster maintains the native MySQL look and feel. Therefore, most of the existing MySQL libraries and connectors out there are compatible with it. However, there are some considerations when connecting to the cluster, as explained in the next section.
Direct Access
A running MySQL server in Galera Cluster does not really mean it is operational. Take an example when Galera nodes are partitioned. During this time, the wsrep_cluster_state value would report as Non-Primary. Note that only Primary Component is a healthy cluster. You could still connect to the MySQL server and perform a number of statements like SHOW and SET though. Keep in mind that DML statements like SELECT, INSERT and UPDATE would not work at this point.
There are three states that must be true which exposed through MySQL’s SHOW statement when determining Galera healthiness:
- wsrep_cluster_state: Primary
- wsrep_local_state_comment: Synced
- wsrep_ready: On
Check for those states before sending any transaction to the Galera nodes. If the probing logic adds complexity to your applications, you can use a reverse proxy approach as described in the next section.
Reverse Proxy
All database nodes in a Galera Cluster can be treated equally, since they are all holding the same dataset and are able to process reads and writes simultaneously. Therefore, it can be load balanced with reverse proxies.
A reverse proxy or load balancer typically sits in front of the Galera nodes and directs client requests to the appropriate backend server. This setup will reduce the complexity when dealing with multiple MySQL masters, distribute the MySQL connections efficiently and make the MySQL service more resilient to failure. Applications just have to send queries to the load balancer servers, and the queries are then re-routed to the correct backends. The application side does not need to perform health checks for cluster state and database availability as these tasks have been taken care of by the reverse proxy.
By adding a reverse-proxy into the picture, our architecture should look like this
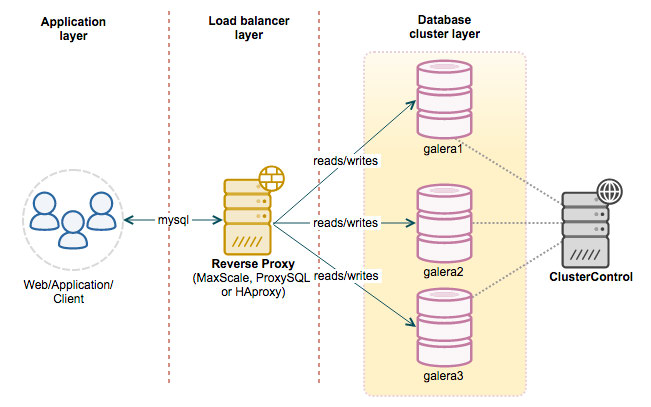
ClusterControl supports the deployment of HAProxy, ProxySQL and MariaDB MaxScale.
HAProxy
HAProxy as MySQL load balancer works similarly to a TCP forwarder, which operates in the transport layer of the TCP/IP model. It does not understand the MySQL queries (which operates in the higher layer) that it distributes to the backend MySQL servers. Setting up HAProxy for Galera nodes requires an external script planted into the database node called mysqlchk. This health check script will report the database state via an HTTP status code on port 9200. ClusterControl will install this script automatically on the selected Galera node.
To create an HAProxy instance in front of the Galera nodes, go to Manage > Load Balancer > HAProxy > Deploy HAProxy. The following screenshot shows the HAProxy instance stats:
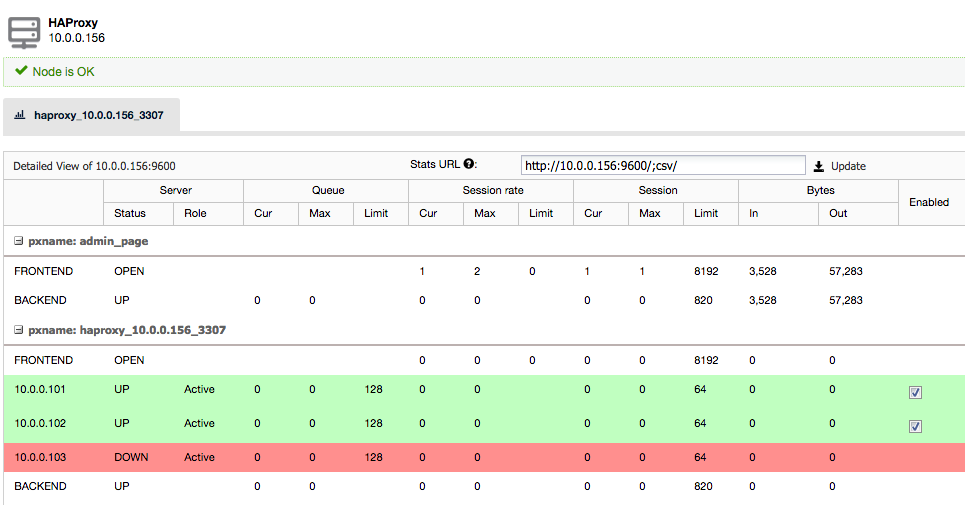
The application can then send the MySQL queries through port 3307 of the load balancer node.
Read more about this in our tutorial on MySQL load balancing with HAProxy.
ProxySQL
ProxySQL is a new high-performance MySQL proxy with an open-source GPL license. It was released as generally available (GA) for production usage towards the end of 2015. It accepts incoming traffic from MySQL clients and forwards it to backend MySQL servers. It supports various MySQL Replication topologies as well as multi-master setup with Galera Cluster, with capabilities like query routing (e.g, read/write split), sharding, queries rewrite, query mirroring, connection pooling and lots more.
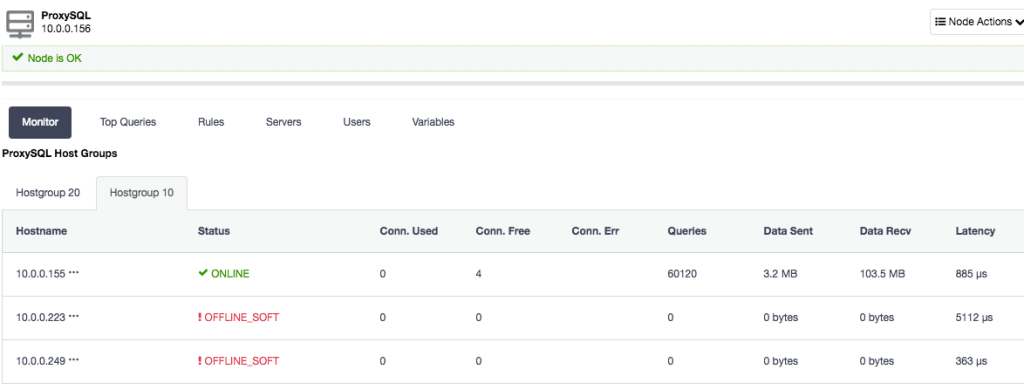
To deploy a ProxySQL instance, simply go to Manage > Load Balancer > ProxySQL > Deploy ProxySQL and specify the necessary information. Choose the server instance to be included into the load balancing set and specify the max replication lag for each of them. ClusterControl will configure two hostgroups for the Galera Cluster, one for multi-master and another one is single-master. By default, all queries will be routed to hostgroup 10 (single-master pool). You can customize the query routing under “Query Rules” at later stage to suit your needs.
Once deployed, you can simply send the MySQL connection to the load balancer host on port 6033. The following screenshot shows the single-master hostgroup (Hostgroup 10) with some stats captured by ProxySQL:
MariaDB MaxScale
MariaDB MaxScale is a database proxy that allows the forwarding of database statements to one or more MySQL/MariaDB database servers. The recent MaxScale 2.0 is licensed under MariaDB BSL which is free to use on up to two database servers. ClusterControl installs MaxScale 1.4 which is free to use on an unlimited number of database servers.
Other Load Balancers
We have built a healthcheck script called clustercheck-iptables that can be used with other load balancers like nginx, IPVS, Keepalived and Pen. This background script checks the availability of a Galera node, and adds a redirection port using iptables if the Galera node is healthy (instead of returning HTTP response). This allows other TCP-load balancers with limited health check capabilities to understand and monitor the backend Galera nodes correctly.
Keepalived
Keepalived is commonly used to provide a single endpoint through virtual IP address, which allows an IP address to float around between load balancer nodes. In case of the primary load balancer goes down, the IP address will be failed over to the backup load balancer node. Once the primary load balancer comes back up, the IP address will be failed back to this node.
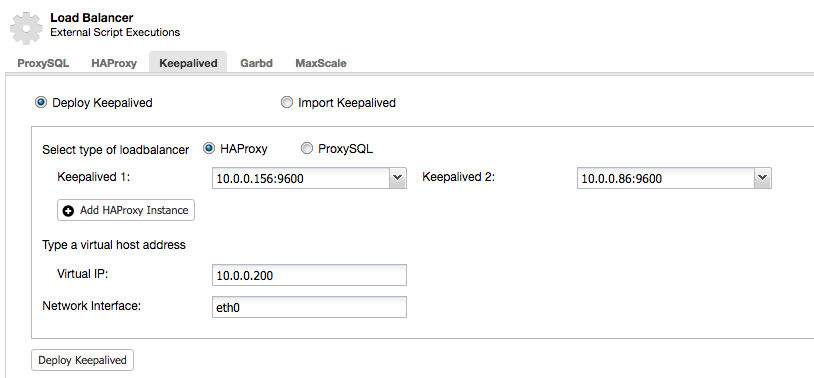
You can deploy a Keepalived instance using ClusterControl > Manage > Load Balancer > Keepalived > Deploy Keepalived. It requires at least two load balancers deployed by or imported to ClusterControl.
Failure handling with ClusterControl and Galera
In order to keep the database cluster stable and running, it is important for the system to be resilient to failures. Failures are caused by either software bugs or hardware problems, and can happen at any time. In case a server goes down, failure handling, failover and reconfiguration of the Galera cluster needs to be automatic, so as to minimize downtime.
In case of a node failing, applications connected to that node can connect to another node and continue to do database requests. Keepalive messages are sent between nodes in order to detect failures, in which case the failed node is excluded from the cluster.
ClusterControl will restart the failed database process, and point it to one of the existing nodes (a ‘donor’) to resynchronize. The resynchronization process is handled by Galera. It can be either through state snapshot transfer (SST) or incremental snapshot transfer (IST).
While the failed node is resynchronizing, any new transactions (writesets) coming from the existing nodes will be cached in a slave queue. Once the node has caught up, it will be considered as synced and is ready to accept client connections.
View this webinar for more information on how to recover MySQL and MariaDB clusters.
Operations – Managing your Galera Cluster
Backup
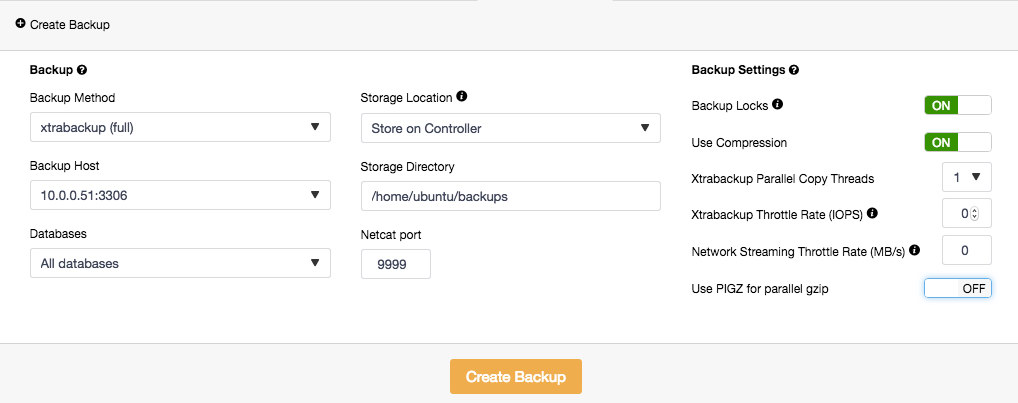
We have covered previously about backup strategies for MySQL. ClusterControl supports mysqldump and xtrabackup (full and incremental) to perform backups. Backups can be performed or scheduled on any database node and stored locally or stored centrally on the ClusterControl node. When storing backups on the ClusterControl node, the backup is first created on the target database node and then streamed over using netcat to the controller node. You can also choose to backup individual databases or all databases. Backup progress is available underneath it and you will get notification on the backup status each time it is created.
To create a backup, simply go to Backup > Create Backup and specify the necessary details:
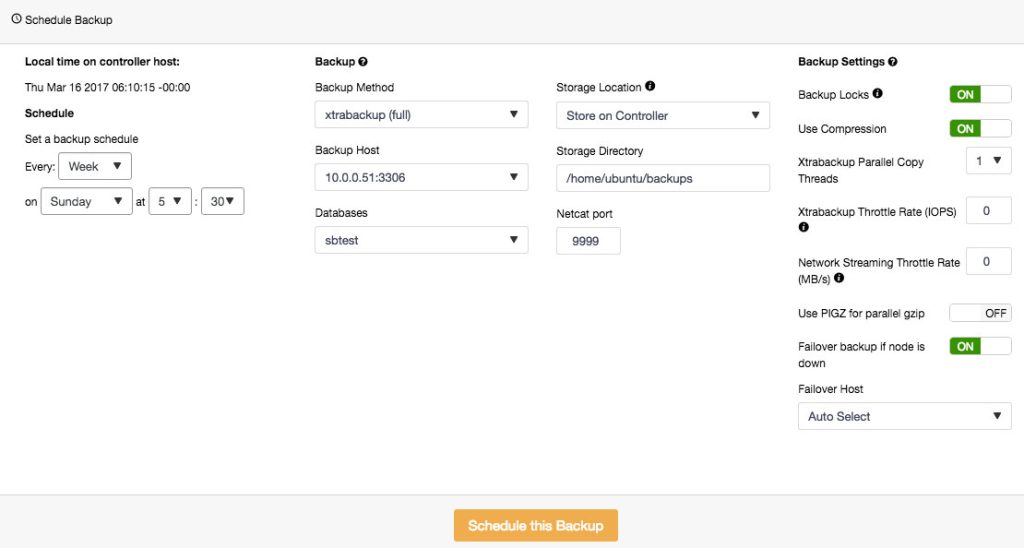
To schedule backups, click on “Schedule Backup” and configure the scheduling accordingly:
Backups created by ClusterControl can be restored on one of the database node.
Restore
ClusterControl has ability to restore backups (mysqldump and xtrabackup) created by ClusterControl or externally via some other tool. For external backup, the backup files must exist on the ClusterControl node and only xbstream, xbstream.gz and tar.gz extensions are supported.
All incremental backups are automatically grouped together under the last full backup and expandable with a drop down. Each created backup will have “Restore” and “Log” buttons:
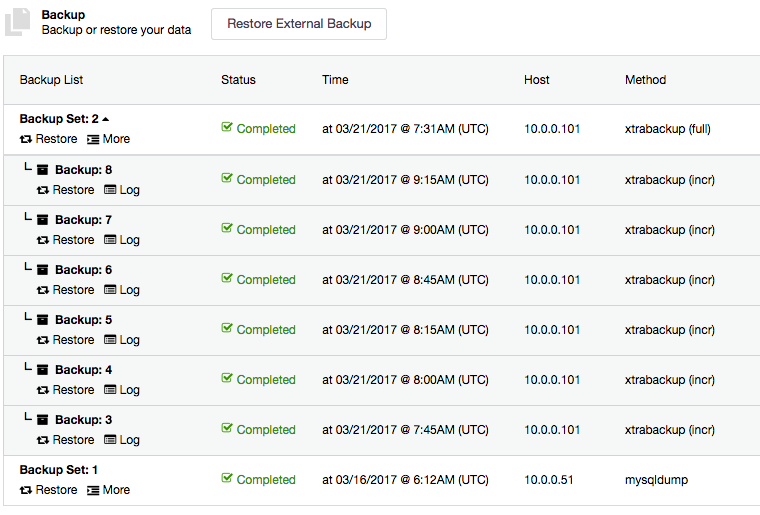
To restore a backup, simply click on the “Restore” button for the respective backup. You should then see the following Restore wizard and a couple of post-restoration options:
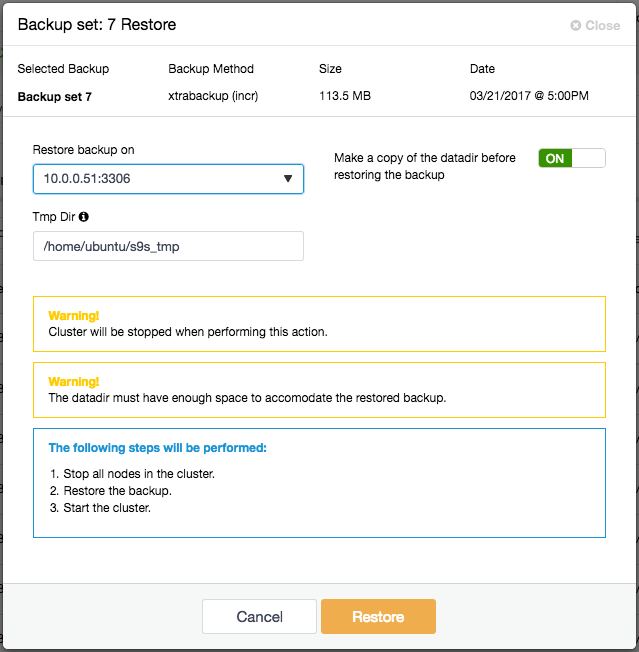
If the backup was taken using Percona Xtrabackup, the replication has to be stopped. The following steps will be performed:
- Stop all nodes in the Galera setup.
- Copy the backup files to the selected server.
- Restore the backup.
- Once the restore job is completed, ClusterControl will bootstrap the restored node.
- ClusterControl will start the remaining nodes by using the bootstrapped node as the donor.
Software Upgrade
You can perform a database software upgrade via ClusterControl > Manage > Upgrades > Upgrade. Upgrades are online and are performed on one node at a time. One node will be stopped, then the software is updated through package manager and finally the node is started again. If a node fails to upgrade, the upgrade process is aborted. Upgrades should only be performed when there is as little traffic as possible on the database hosts.
You can monitor the MySQL upgrade progress from ClusterControl > Activity > Jobs, as shown in the following screenshot:
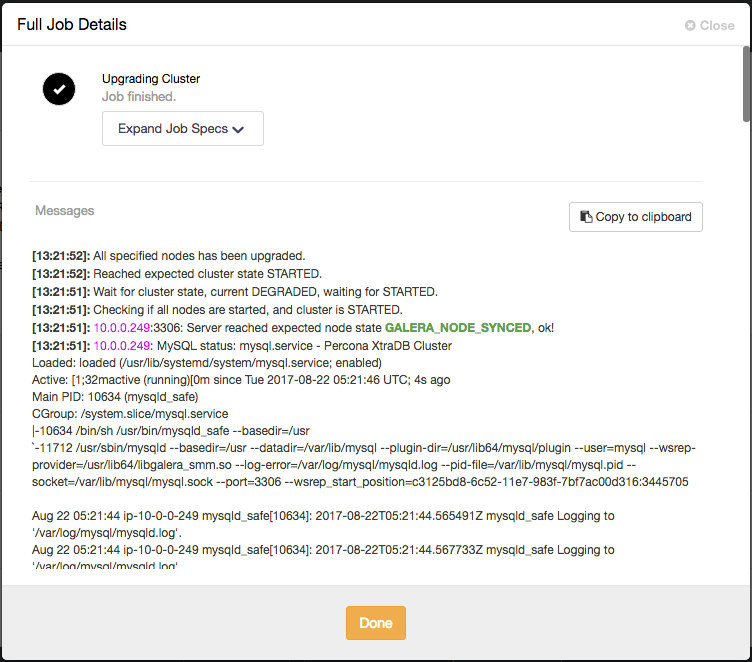
ClusterControl performs upgrade of Galera Cluster by upgrading them one at a time. Once the job is completed, verify the new version is correct from the “Cluster Overview” page.
Configuration Management
System variables are found in my.cnf. Some of the variables are dynamic and can be set at runtime, others not. ClusterControl provides an interface to update MySQL configuration parameters on all DB instances at once. Select DB instance(s), configuration group and parameter and ClusterControl will perform the necessary changes via SET GLOBAL (if possible) and also make it persistent in my.cnf.
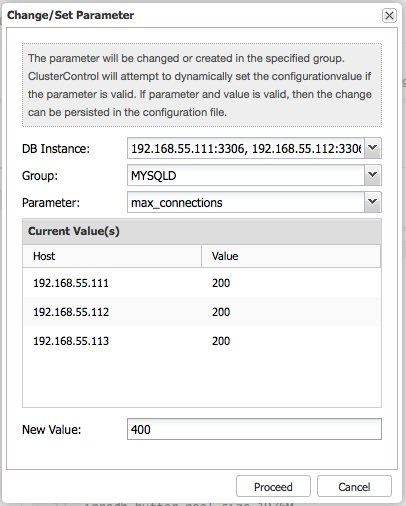
If restart is required, ClusterControl will acknowledge that in the Config Change Log dialog:
More information in this blog post, Updating your MySQL Configuration.
Online Schema Upgrade
Any DDL statement that runs on the database, such as CREATE TABLE, ALTER TABLE or GRANT, upgrades the schema. Traditionally, a schema change in MySQL was a blocking operation – a table had to be locked for the duration of the changes. In Galera Cluster, there are two ways you can perform the online schema changes (OSU):
- Total Order Isolation (TOI)
- Rolling Schema Upgrade (RSU)
These two options, TOI and RSU are part of the wsrep_osu_method variable.
Total Order Isolation (TOI)
This is the default value of wsrep_osu_method. Where the schema upgrades run on all cluster nodes in the same total order sequence, preventing other transactions from committing for the duration of the operation. In Total Order Isolation, queries that update the schema replicate as statements to all nodes in the cluster. The nodes wait for all preceding transactions to commit then, simultaneously, they execute the schema upgrade in isolation. For the duration of the DDL processing, no other transactions can commit.
More details in this blog on schema changes using TOI.
Rolling Schema Upgrade (RSU)
The schema upgrades run locally, affecting only the node on which they are run. The changes do not replicate to the rest of the cluster. DDL statements that update the schema are only processed on the local node. While the node processes the schema upgrade, it desynchronizes with the cluster. When it finishes processing the schema upgrade it applies delayed replication events and synchronizes itself with the cluster.
More details can be found in this blog on schema changes using RSU.
Each method has its own pros and cons. More details in this blog post, Become a MySQL DBA blog series – Common operations – Schema Changes.
Common Questions about Galera Cluster
What can cause Galera to crash?
Stay clear of Galera’s known limitations to avoid problems.
There are several reasons which can cause Galera to crash:
- Too many deadlocks under heavy load when writing to the same set of rows,
- OS is swapping and/or high iowait,
- Out of disk space,
- InnoDB crashes,
- Use only binlog_format=ROW,
- Every table must have a PRIMARY KEY,
- Replication of MyISAM table is experimental and MyISAM tables should be avoided,
- Delete from table which does not have primary key can cause a cluster crash,
- No primary components available or cluster is out of quorum,
- MySQL misconfiguration,
- Galera software bug
What happens when disk is full?
Galera node provisioning is smart enough to kick out any problematic node from the cluster if it detects inconsistency among members. When the mysqld runs out of disk space (in the data directory), the node is not able to apply writesets. Galera detects this as failed transactions. Since this compromises node consistency, Galera will then signal it to close the group communication and force mysqld to terminate.
Restarting the node will give disk-full errors (such as “no space left on device”), and quota-exceeded errors (such as “write failed” or “user block limit reached”). You might want to add another data file on another disk or clear up some space before the node can rejoin the cluster.
What happens if OS is swapping?
If the OS starts swapping and/or if iowait is very high it can “freeze” the server for duration of time. During this time the Galera node may stop responding to the other nodes and will be deemed dead. In virtualized environments it can also be the Host OS that is swapping.
How to handle Galera crash?
First of all, make sure you are running the latest Galera stable release so you do not run into older bugs that have already been fixed. Start with inspecting the MySQL error log on the Galera nodes as Galera will be logging to this file. Try to shed some light to any relevant line which indicates error or failing. If the Galera nodes happen to be responsive, you may also try to collect following output:
mysql> SHOW FULL PROCESSLIST;
mysql> SHOW PROCESSLIST;
mysql> SHOW ENGINE INNODB STATUS;
mysql> SHOW STATUS LIKE 'wsrep%';Next, inspect the system resources by checking network, firewall, disk usage and memory utilization as well as inspecting the general system activity log (syslog, message, dmesg). If still no indication of the problem found, you may hit into a bug which you can report it directly at Galera bugs on Launchpad page or request for technical support assistance directly from the vendor (Codership, Percona or MariaDB). You may also join the Galera Google Group mailing list to seek for open assistance.
Note:
- If you are using rsync for state transfer, and a node crashes before the state transfer is over, rsync process might hang forever, occupying the port and not allowing to restart the node. The problem will show up as ‘port in use’ in the server error log. Find the orphan rsync process and kill it manually.
- Before re-initializing the cluster, you can determine which DB node is having the most updated data by comparing the wsrep_last_commited value among nodes. The one which holding the highest number is recommended to be the reference node when bootstrapping the cluster.
What happens if I don’t have primary keys in my table?
Each transaction is assigned a global ordinal sequence number during replication. Thus, when a transaction reaches the commit point, it is known what was the sequence number of the last transaction it did not conflict with. The interval between those two numbers is an uncertainty land: transactions in this interval have not seen the effects of each other. Therefore, all transactions in this interval are checked for primary key conflicts with the transaction in question. The certification test fails if a conflict is detected.
DELETE FROM statement requires PK or node(s) will die. Always define an explicit PRIMARY KEY in all tables. A simple AUTO_INCREMENT primary key will be just enough.
Is it true that MySQL Galera is as slow as the slowest node?
Yes it is. Galera relies on group communication between nodes. For any matters, it will wait for all nodes to return the status of certification test before proceed with committing or rollbacking. At this phase, an overloaded node will surely facing a hard time to reply within the time manner, delaying the rest of the cluster to wait for it. Therefore it is recommended to have uniform servers across the cluster. Also, transaction latency is no shorter than the RTT (round trip time) to the slowest node.
Can I Use Galera to Replicate between Data Centers?
Although Galera Cluster is synchronous, it is possible to deploy a Galera Cluster across data centers. Synchronous replication like MySQL Cluster (NDB) implements two-phase commit, where messages are sent to all nodes in a cluster in a ‘prepare’ phase, and another set of messages are sent in a ‘commit’ phase. This approach is usually not suitable for geographically disparate nodes, because of the latencies in sending messages between nodes.
Galera Cluster makes use of certification based replication, that is a form of synchronous replication with reduced overhead.
Usage of MyISAM tables? Why is it not recommended?
MySQL Galera treats MyISAM tables in quite different way:
- All DDL (create, drop, alter table…) on MyISAM will be replicated.
- DML (update, delete, insert) on MyISAM tables only, will not be replicated.
- Transactions containing both InnoDB and MyISAM access will be replicated.
So, MyISAM tables will appear in all nodes (since DDL is replicated). If you access the MyISAM tables outside of InnoDB transactions, then all data changes in MyISAM tables will remain locally in each node. If you access MyISAM tables inside InnoDB transactions, then MyISAM changes are replicated along InnoDB changes. However, if there happen cluster wide conflicts, MyISAM changes cannot be rolled back and your MyISAM tables will remain inconsistent.
Which version of Galera is the best (PXC, Maria, Codership)?
The Galera technology is developed by Codership Oy and is available as a patch for standard MySQL and InnoDB. Percona and MariaDB leverage the Galera library in Percona XtraDB Cluster (PXC) and MariaDB Galera Cluster respectively.
Since they all leverage the same Galera library, replication performance should be fairly similar. The Codership build usually has the latest version of Galera, although that could change in the future.



