blog
Implementing the golden backup rule for your databases

Data security is crucial in today’s world. Personally Identifiable Information (PII) is everywhere – emails, names, addresses, personal ID numbers and so on. There are regulations in place that organizations managing PII have to comply with and fines for those who fail to comply are significant. This is a known threat and organizations are taking steps to ensure the access to the critical data is limited and monitored.
What about other threats, though? What if it is not a cyber security threat? What if it is a good old hardware failure? Say, on a big scale, just to mix things up? Can your organization survive losing most or all of its data? Your customer data is gone. Not just stolen, which would still be a huge problem, but literally gone. Puff! It does not exist anymore on your database servers. Maybe even those servers do not exist anymore as well? What now? Are you prepared for such a catastrophic event?
The 3-2-1-1-0 Golden Rule for backups
You may have heard about a backup Golden Rule: 3-2-1-1-0. If not, let’s quickly explain what it means.
3 – Keep at least three copies of your data
This one is quite simple — you want to create three copies of your data. In case there are problems with any one of them, you still have two more copies to work with.
2 – Store the backups on at least two different storage mediums
You don’t want to use the same storage medium to keep all of the backups. If you store the data on the disk array, disks may fail. If you upload the data to some sort of cloud storage, you rely on internet access to download that data. What if, during the incident, your internet access is unreliable?
1 – Store at least one copy in an offsite location
This is quite self-explanatory — you don’t want to put all eggs in one basket. We have seen whole data centers affected by failures. You want to keep at least one copy of your data in some other place, in case you would need to rebuild your infrastructure from scratch, using a different ISP.
1 – Store at least one copy offline
Storing data offsite is not good enough to cover all of the bases. If your infrastructure has been compromised, anything that is online may, potentially, be accessed and affected. To put it bluntly, someone who gained full access to the system can just destroy a VM where you store the backup, even if the VM is stopped. You want to use storage that can be “unplugged” from the infrastructure. External disk drives, tapes etc. Sure, it feels like the 90’s here but this is really secure. Think of it, if tape is out from the drive, no one, no matter which server or laptop he gained access to, can access it in any way other than physically.
0 – Test your backups to verify there’s zero errors during restore
This is again, self-explanatory. You may have heard about Schrodinger’s backup – each backup is in an unknown state, it may work or may not and you won’t know until you attempt to restore it. Therefore, testing each backup is critical – only then you can verify that a backup can be restored correctly and it can be reliably used if there’s a need for it.
How ClusterControl can help to implement 3-2-1-1-0 rule
ClusterControl is a database ops orchestration platform that, among others, allows you to automate backup handling and; as such, it can be used, with a little bit of additional work, to implement the 3-2-1-1-0 rule. Let’s see how we can do that.
First of all, let’s create a backup. You can either create an ad hoc backup or schedule one.
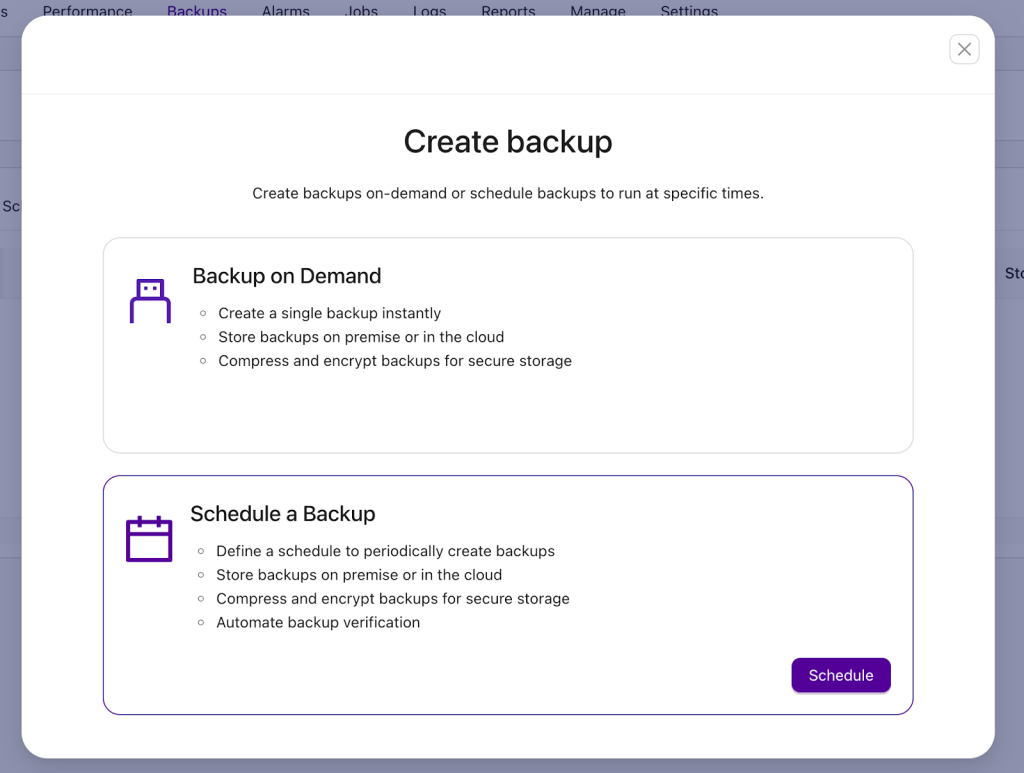
Here, we want to schedule a backup.
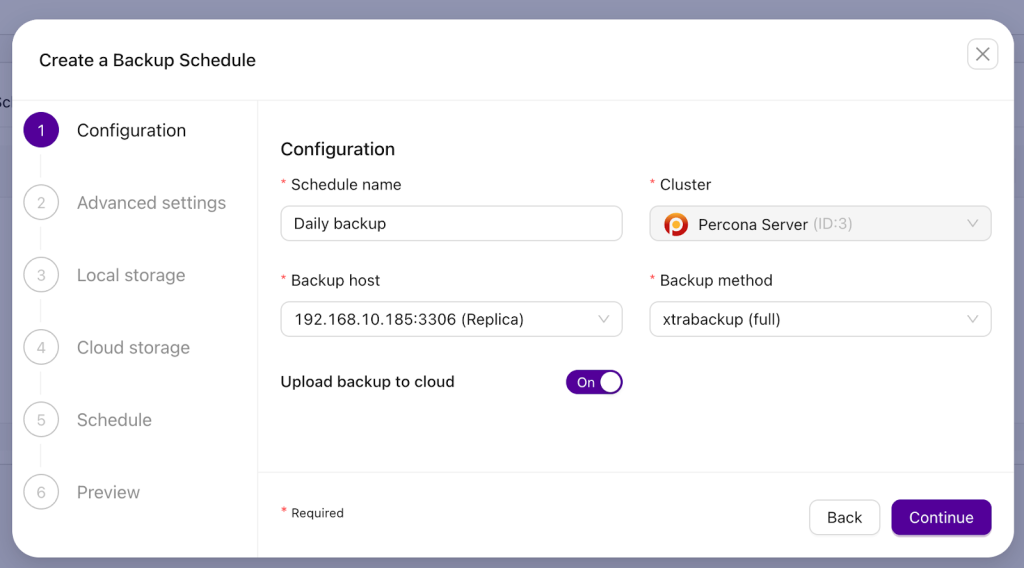
Now, this is going to be a full backup so we are picking am xtrabackup (full) as a backup method. The list of backup methods depends on the cluster type. In this case we have a Percona Server cluster of a primary node and a couple of replicas. We can pick a replica to take the backup from, to minimize the impact on the primary. Let’s not forget about enabling a cloud upload – ClusterControl will upload the backup to the cloud (to a S3 compatible storage) after the backup completes.
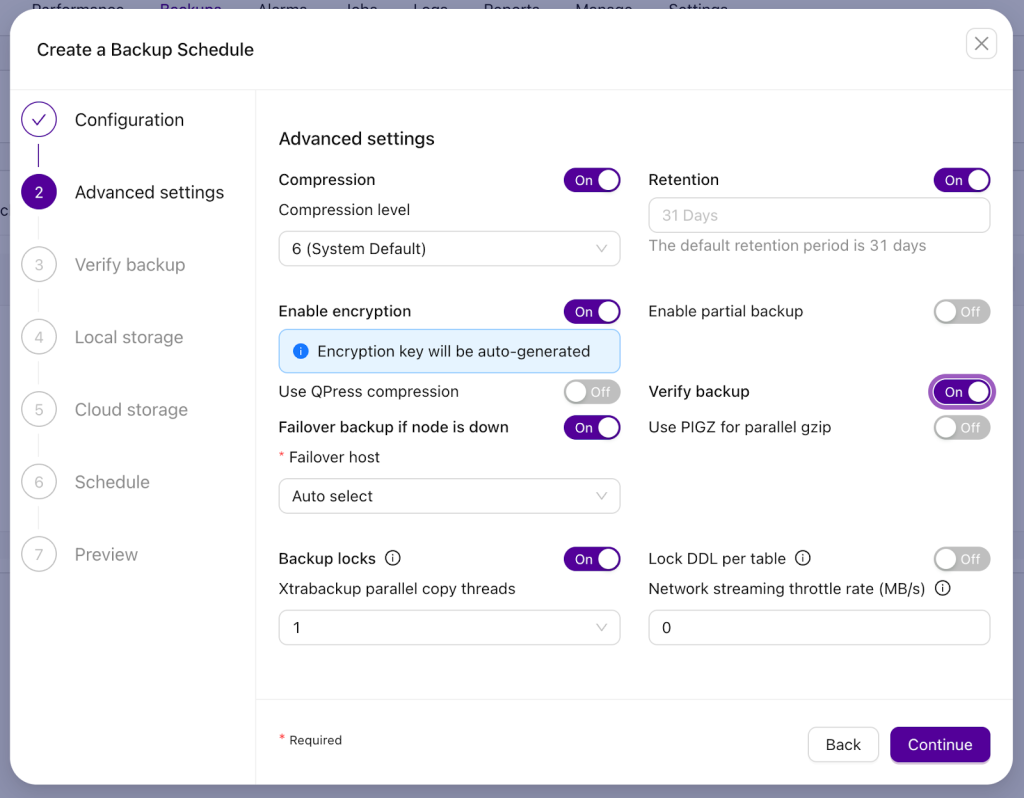
Here, there are 3 settings we want to pick:
- Enable encryption – as we are uploading data to S3, we want it to be encrypted.
- Enable the option to failover if the node is down. What does it mean? At the previous step we picked a backup host – one of the replicas, 192.168.10.185. That will be the node where the backup will be executed. Still, if that node, for whatever reason, would be unavailable at the time the backup is scheduled, this option makes ClusterControl use another node from the cluster. In this case we decided to let CC pick any node that is available (Auto select) but you can also pick a particular one, let’s say, another replica.
- Enable backup verification.
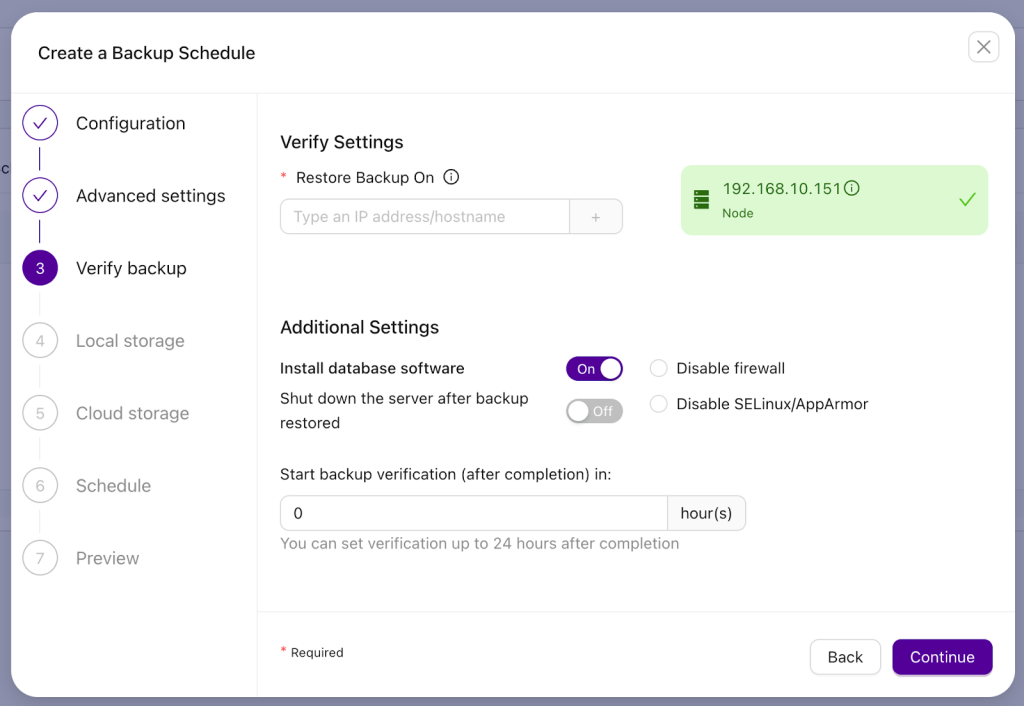
To verify the backup we have to have a node up and running with SSH access configured in a way that ClusterControl can connect to it. After the backup is completed, a given node (in our case 192.168.10.151) will have database software provisioned and then the backup will be copied to it and restored.
N.B. You can configure the delay after which the restore process will start and can decide whether the server will remain up and running or stop after the test restore is completed. If the restore process finishes successfully, the backup is assumed to be working.
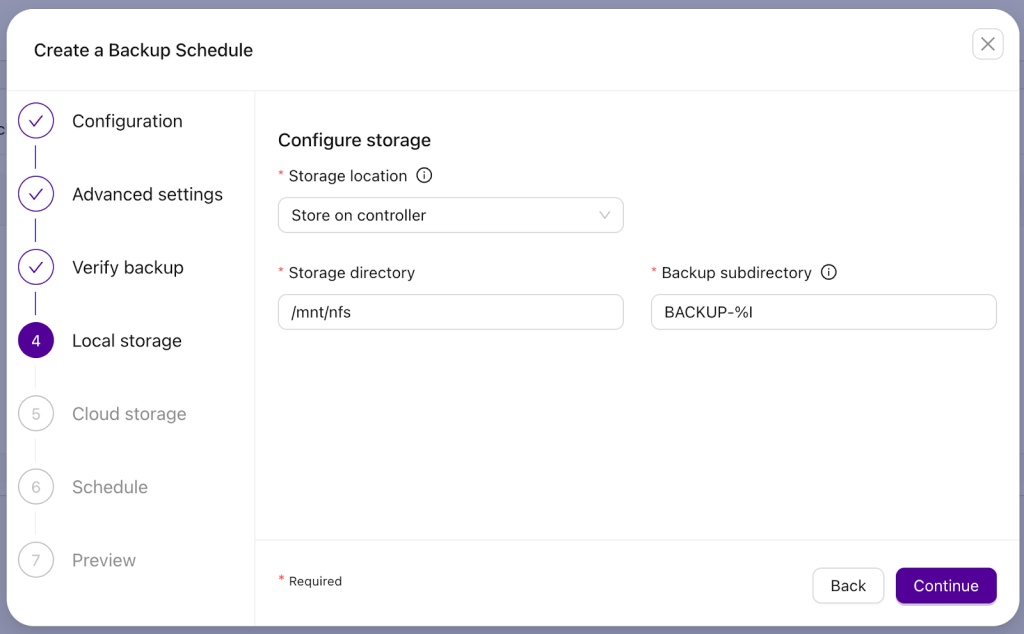
Now we want to configure the local storage part. Backups can be kept on the backup node, which may have its pros and cons, or transferred over to the controller host. Here you can pick a location where the backup should be kept and; quite often, it is an NFS or some other mount from a “backup” server that has been configured with a large amount of storage.
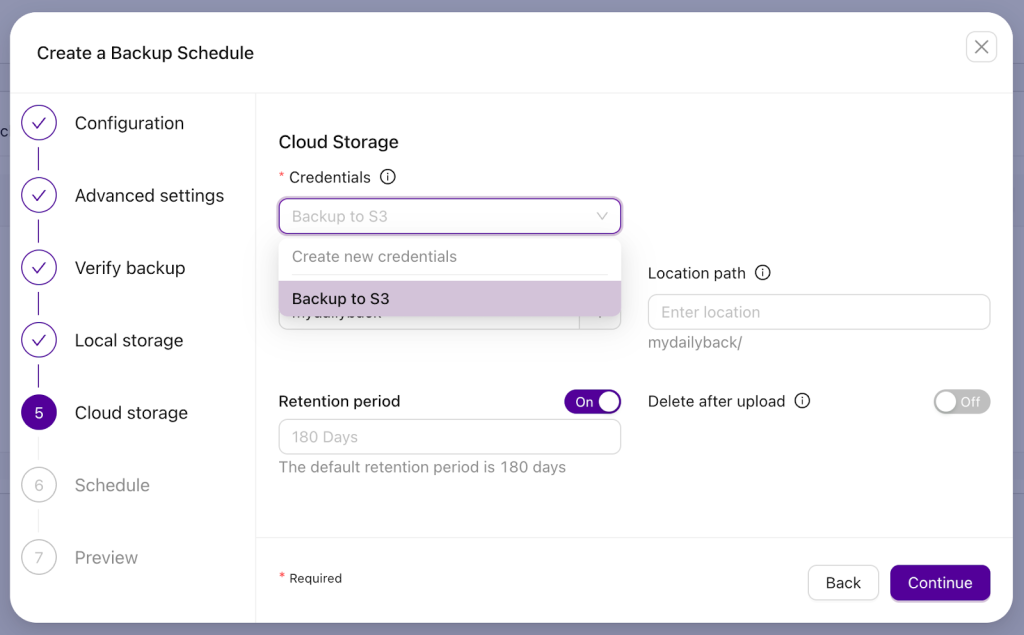
The next step is to configure cloud access. If you have already set up the integration, you can pick it by its name. If you haven’t done that yet, you can create new credentials.
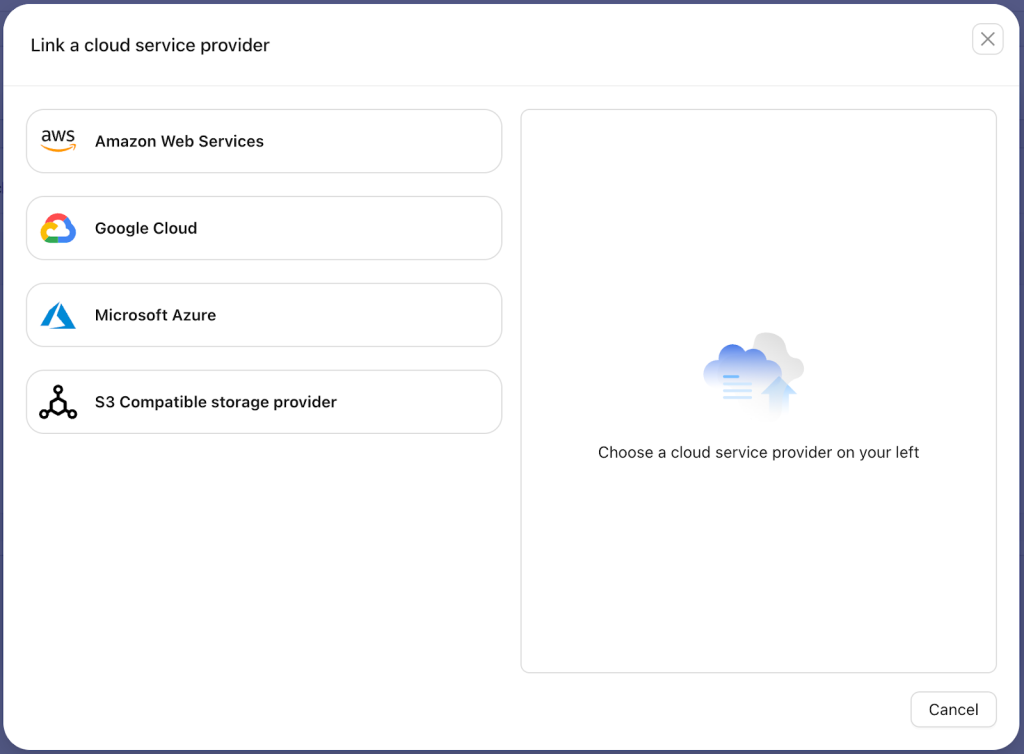
ClusterControl supports AWS, GCP, Azure and any S3 compatible storage, for example from OpenStack.
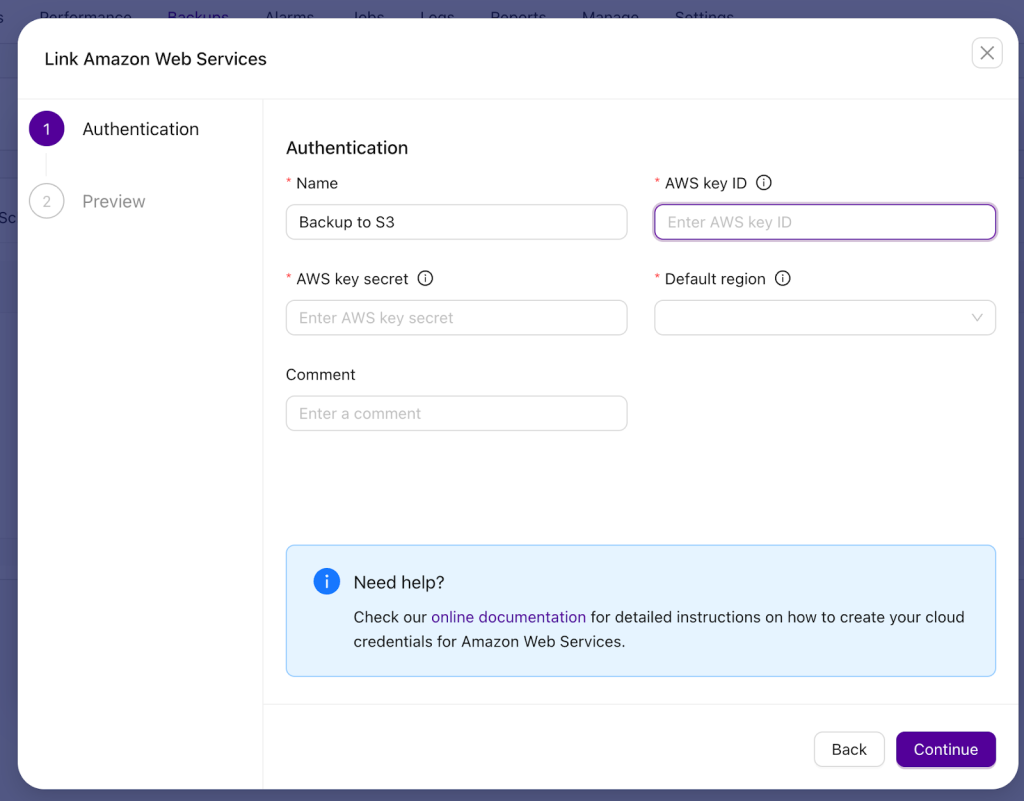
For this example, we’ll use AWS which requires you to define a name, pass credentials and pick the region.
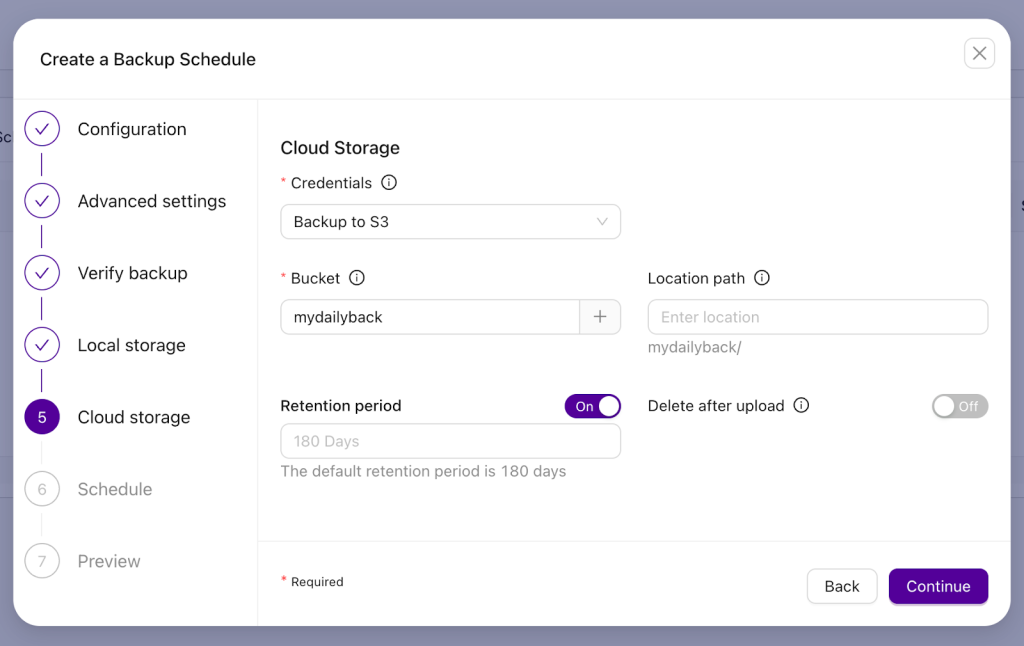
Once the credentials are created, you need to define the name of the S3 bucket. If needed, you can change the retention period. You can also keep the backup only in the cloud by enabling the “Delete after upload” option, but we don’t want to do that. We want to keep the data in multiple places, as per 3-2-1-1-0 rule.
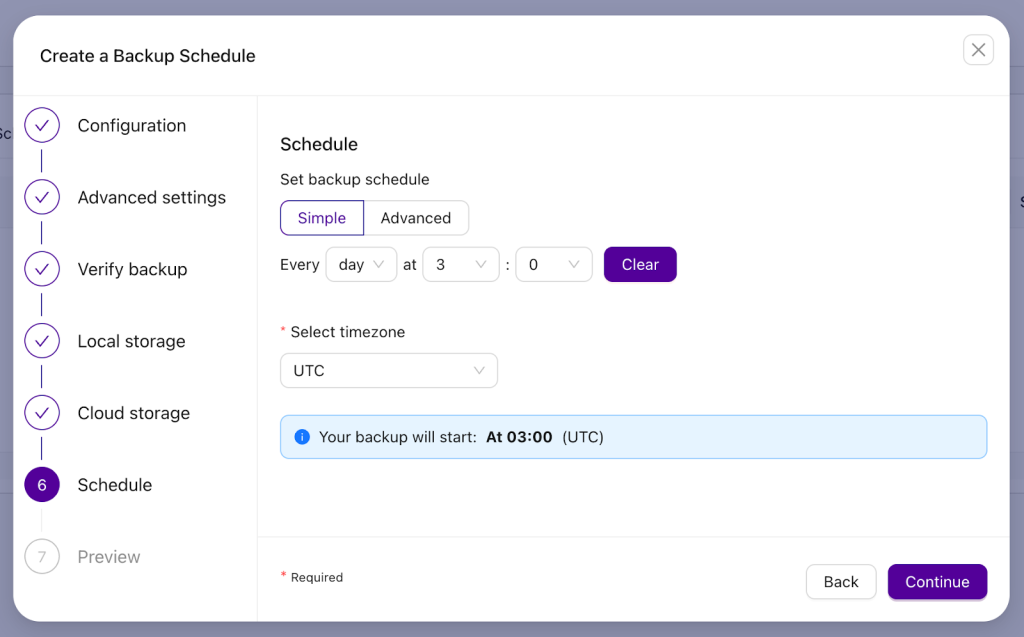
We can now define when the backup is supposed to be executed – in our case it’s 3:00am UTC every day.
Finally, review the configuration and proceed with creating the schedule.
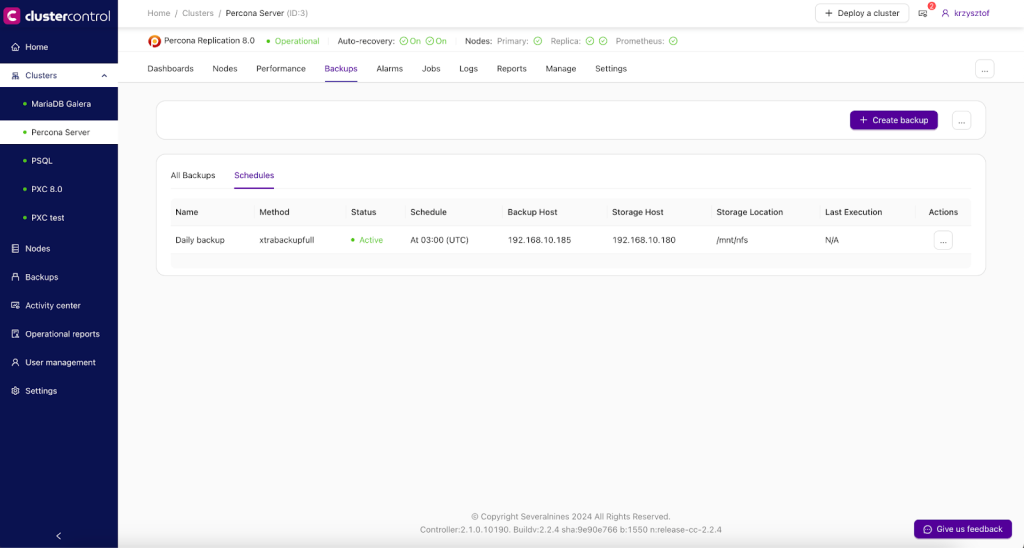
It will become visible in the “Schedules” tab.
Ok, that part is done but what exactly did we do and how does it compare with the 3-2-1-1-0 golden backup rule?
1. We have created a backup that is stored in multiple locations:
- a) Cloud — S3 bucket
- b) Via controller host — on a backup server
- c) Technically we can argue that the backup verification server also stores the backup, just in a restored form
2. We store the data in two different mediums:
- a) Disks for the backup server and backup verification server
- b) S3 bucket
3. We store one copy of the backup offsite
- a) Cloud provider via S3 bucket
4. We ensure that the backup has zero errors during restore via verifying each backup after it is created
Out of the 3-2-1-1-0 rule we are missing the only one — we do not store data offline. We have a very good reason for that though: you cannot really automate it from a host inside of your network (where ClusterControl instance is located) because that would kind of defeat the purpose of ensuring that data is totally offline. There are many ways in which you can easily implement this point. Let’s write down some options that would work quite well:
- You can have a computer that is started manually on a daily basis, downloads the backup from either S3 bucket or through rsyncing it from the controller host. Once this is done, you would stop the box and physically unplug it from the power source.
- A backup server may have a tape drive and a script that executes once the backup is completed. It would copy the latest backup to the tape and then, let’s say, umount it. You would then swap the tape and put in an empty one, ready for the next day’s backup.
As you can see, ClusterControl gets you across all of the aspects of the 3-2-1-1-0 rule that can be automated, making the implementation of that best practice a breeze. We always hope that we will never have to use our backups; but, should that time come, ClusterControl has you covered and ensures that you can recover even from the most dire scenarios.
To try it out for yourself by signing up to ClusterControl free for 30-days (no credit card required). In the meantime, stay abreast of the latest in open-source database operations best practices by following us on Twitter or LinkedIn or signing up to our monthly newsletter.



