blog
Top PG Clustering High Availability Solutions for PostgreSQL

If your system relies on PostgreSQL and you are looking for clustering solutions for High Availability, we want to let you know in advance that it is a complex task but not impossible to achieve.
Considering your requirements for fault tolerance, here are some high availability clustering solutions to choose from that can help.
PostgreSQL does not natively support any multi-master clustering solution like MySQL or Oracle. Nevertheless, many commercial and community products offer this implementation, including replication and load balancing for PostgreSQL.
To start, let’s review some basic concepts:
What is High Availability?
High availability refers to the amount of time a service is available and is usually defined by a business’ agreed level of performance.
Redundancy is the basis for high availability; in the event of an incident, you can continue to operate and access systems without issue.
Continuous Recovery
When an incident occurs, if you have to restore a backup and then apply the WAL (Write-Ahead Logging) logs, the recovery time would be very high, and it would not be highly available.
However, if you have the backups and logs archived in a contingency server, you can apply the logs as they arrive. If the logs are sent and applied every minute, the contingency base would be in a continuous recovery and would have an outdated state to the production of at most one minute.
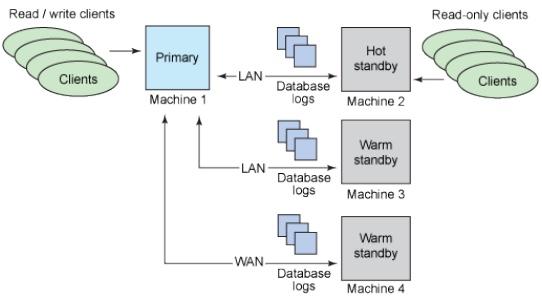
Standby Databases
The idea of a standby database is to keep a copy of a production database that always has the same data and is ready to be used in case of an incident.
There are several ways to classify a standby database.
By the nature of the replication:
-
Physical standbys: Disk blocks are copied.
-
Logical standbys: Streaming of the data changes.
By the synchronicity of the transactions:
-
Asynchronous: There is a possibility of data loss.
-
Synchronous: There is no possibility of data loss; The commits in the master wait for the response of the standby.
By the usage:
-
Warm standbys: They do not support connections.
-
Hot standbys: Support read-only connections.
Clusters
A cluster is a group of hosts working together and seen as one. This provides a way to achieve horizontal scalability and the ability to process more work by adding servers.
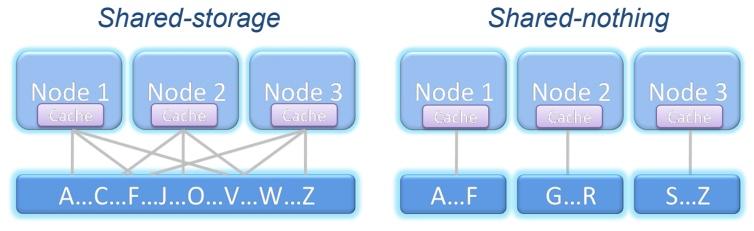
It can resist the failure of a node and continue to work transparently. Depending on what is shared, there are two cluster models:
-
Shared storage: All nodes access the same storage with the same information.
-
Shared nothing: Each node has its own storage, which may or may not have the same information as the other nodes, depending on the structure of our system.
Let’s now review some of the clustering options we have in PostgreSQL.
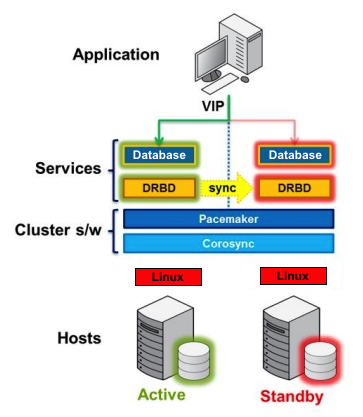
Distributed Replicated Block Device
DRBD is a Linux kernel module that implements synchronous block replication using the network. It actually does not implement a cluster and does not handle failover or monitoring. You need complementary software for that, for example, Corosync + Pacemaker + DRBD.
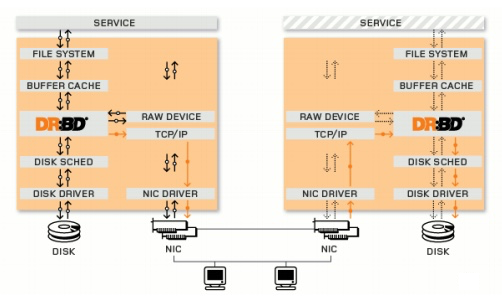
Example:
-
Corosync: Handles messages between hosts.
-
Pacemaker: Starts and stops services, making sure they run only on one host.
-
DRBD: Synchronizes the data at the level of block devices.
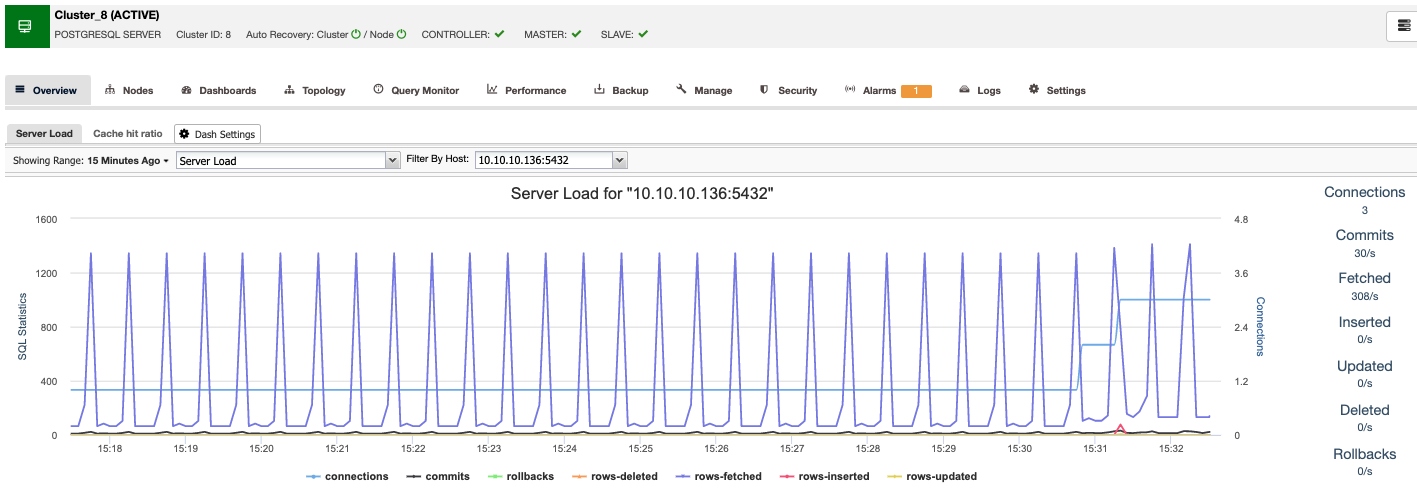
ClusterControl
ClusterControl is an agentless management and automation software for database clusters. It helps deploy, monitor, manage and scale your database server/cluster directly from its user interface. It can handle most administration tasks required to maintain database servers or clusters.
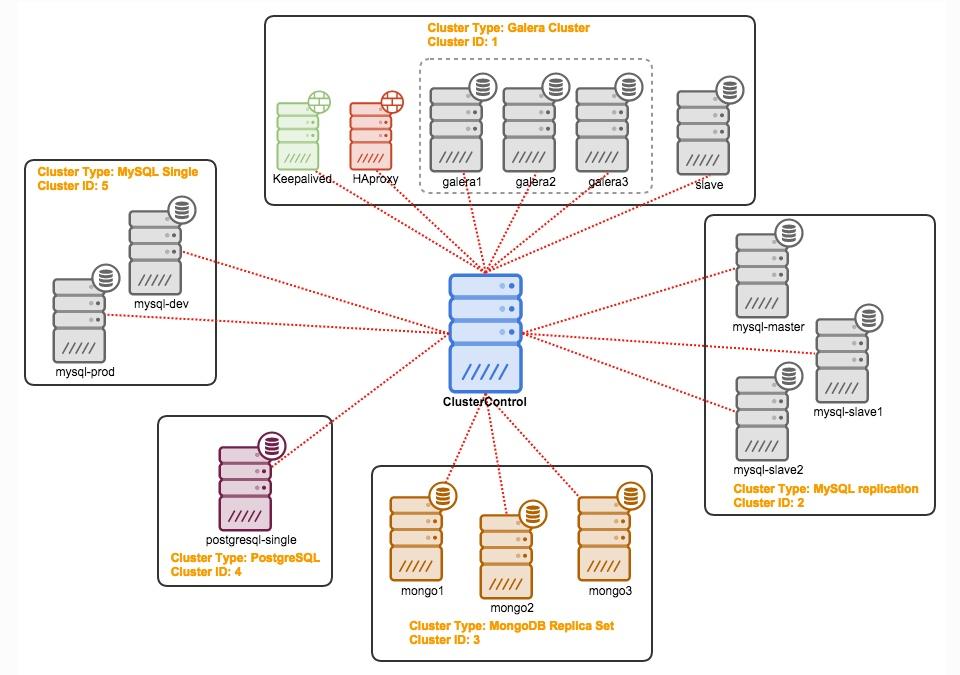
With ClusterControl, you can:
-
Deploy standalone, replicated, or clustered databases on the technology stack of your choice.
-
Automate failovers, recovery, and day-to-day tasks uniformly across polyglot databases and dynamic infrastructures.
-
Create full or incremental backups manually or schedule them.
-
Do unified and comprehensive real-time monitoring of your entire database and server infrastructure.
-
Easily add or remove a node with a single action.
-
Clone your cluster to another data center/cloud provider
If you have an incident on PostgreSQL, your Standby node can be promoted to Primary automatically.
It’s a complete tool that offers full-ops lifecycle management and automation through a single pane of glass. ClusterControl also provides a free 30-day trial so you can evaluate it, no strings attached.
Rubyrep
Rubyrep is a solution providing asynchronous, multi-master, multi-platform replication (implemented in Ruby or JRuby) and multi-DBMS (MySQL or PostgreSQL).
It is based on triggers, and it does not support DDL, users, or grants. The simplicity of use and administration is its primary objective.
Some features include:
-
Simple configuration
-
Simple installation
-
Platform independent, table design independent.
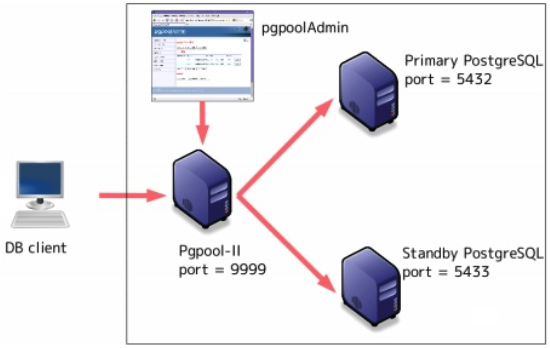
Pgpool-II
Pgpool-II is a middleware that works between PostgreSQL servers and a PostgreSQL database client.
Some features include:
-
Connection pool
-
Replication
-
Load balancing
-
Automatic failover
-
Parallel queries
It can be configured on top of streaming replication:
Bucardo
Bucardo offers asynchronous cascading master-slave replication, row-based, using triggers and queueing in the database, and asynchronous master-master replication, row-based, using triggers and customized conflict resolution.
Bucardo requires a dedicated database and runs as a Perl daemon that communicates with this database and all other databases involved in the replication. It can run as multi-master or multi-slave.
Master-slave replication involves one or more sources going to one or more targets. The source must be PostgreSQL, but the targets can be PostgreSQL, MySQL, Redis, Oracle, MariaDB, SQLite, or MongoDB.
Some features include:
-
Load balancing
-
Slaves are not constrained and can be written
-
Partial replication
-
Replication on demand (changes can be pushed automatically or when desired)
-
Slaves can be “pre-warmed” for quick setup
Drawbacks:
-
Cannot handle DDL
-
Cannot handle large objects
-
Cannot incrementally replicate tables without a unique key
-
Will not work on versions older than Postgres 8
Postgres-XC
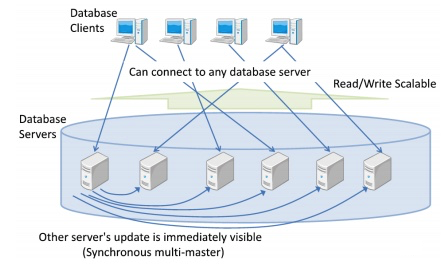
Postgres-XC is an open-source project to provide a write-scalable, synchronous, symmetric, and transparent PostgreSQL cluster solution. It is a collection of tightly coupled database components that can be installed in more than one hardware or virtual machine.
Write-scalable means Postgres-XC can be configured with as many database servers as you want and handle many more writes (updating SQL statements) compared to what a single database server can do.
You can have more than one database server that clients connect to, providing a single, consistent cluster-wide view of the database.
Any database update from any database server is immediately visible to any other transactions running on different masters.
Transparent means you do not have to worry about how your data is stored in more than one database server internally.
You can configure Postgres-XC to run on multiple servers. Your data is stored in a distributed way, partitioned or replicated, as chosen by you for each table. When you issue queries, Postgres-XC determines where the target data is stored and issues corresponding queries to servers containing the target data.
Citus
Citus is a drop-in replacement for PostgreSQL with built-in high availability features such as auto-sharding and replication. Citus shards your database and replicates multiple copies of each shard across the cluster of commodity nodes. If a node in the cluster becomes unavailable, Citus transparently redirects any writes or queries to one of the other nodes which house a copy of the impacted shard.
Some features include:
-
Automatic logical sharding
-
Built-in replication
-
Data-center aware replication for disaster recovery
-
Mid-query fault tolerance with advanced load balancing
You can increase the uptime of your real-time applications powered by PostgreSQL and minimize the impact of hardware failures on performance. You can achieve this with built-in high availability tools minimizing costly and error-prone manual intervention.
PostgresXL
PostgresXL is a shared-nothing, multi-master clustering solution that can transparently distribute a table on a set of nodes and execute queries in parallel with those nodes. It has an additional component called Global Transaction Manager (GTM) for providing a globally consistent view of the cluster.
PostgresXL is a horizontally scalable open-source SQL database cluster, flexible enough to handle varying database workloads:
-
OLTP write-intensive workloads
-
Business Intelligence requiring MPP parallelism
-
Operational datastore
-
Key-value store
-
GIS Geospatial
-
Mixed-workload environments
-
Multi-tenant provider-hosted environments
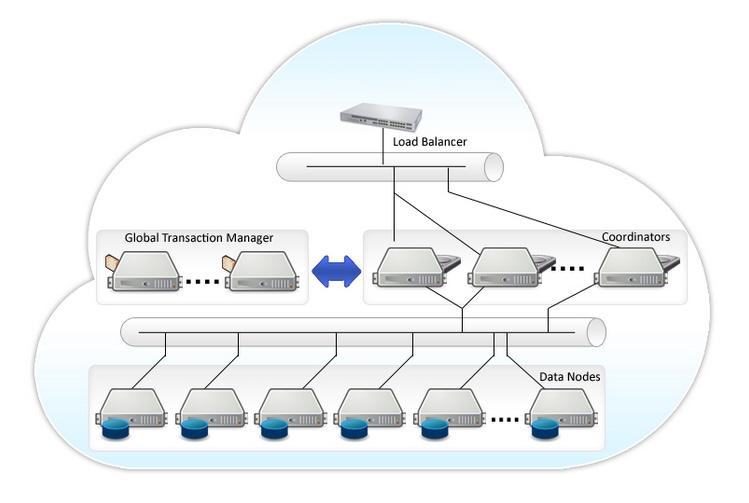
Components:
-
Global Transaction Monitor (GTM): The Global Transaction Monitor ensures cluster-wide transaction consistency.
-
Coordinator: The Coordinator manages the user sessions and interacts with GTM and the data nodes.
-
Data Node: The Data Node is where the actual data is stored.
Wrapping Up
There are many more products available to implement your high availability environment for PostgreSQL, but you have to be careful with:
-
New products, not sufficiently tested
-
Discontinued projects
-
Limitations
-
Licensing costs
-
Very complex implementations
-
Unsafe solutions
When selecting which solution you’ll use, also take into account your infrastructure. If you have only one application server, no matter how much you have configured the high availability of the databases, if the application server fails, you are inaccessible. You must analyze the single points of failure in the infrastructure well and try to solve them.
Taking these points into account, you can find a high availability cluster solution that adapts to your needs and requirements, headache-free. If you’re looking for additional HA resources for your PG database, check out this post on deploying PostgreSQL for high availability.
To stay updated on database management solutions and best practices, follow us on Twitter and LinkedIn and subscribe to our newsletter.



