blog
Challenges of Scaling the Moodle MySQL Database

Moodle, an open source Learning Management System, became more and more popular in last year as the pandemic forced hard lockdowns and majority of the education activities have moved from schools, colleges and universities to online platforms. With it, a pressure was put on the IT teams to ensure that those online platforms will be able to accommodate much higher load than they used to experience. Questions have been raised – how can a Moodle platform be scaled to handle the increased load? On one hand, scaling the application itself is not a hard feat to accomplish, but database, on the other hand, is a different animal. Databases, like all stateful services, are notoriously hard to scale out. In this blog post we would like to discuss some challenges you’ll be facing when scaling a Moodle database.
Scaling Moodle database – The Challenge
The main source of problems is the heritage – Moodle, just like many databases, comes from a single database background and, as such, it comes with some expectations that are related to such an environment. The typical one is that you can execute one transaction after another and the second transaction will always see the outcome of the first one. This is not necessarily the case in most of the distributed database environments. Asynchronous replication makes no promises. Any transaction may get lost in the process. It is enough that the master will crash before the transaction data will be transferred to slaves. Semisynchronous replication brings the promise of data safety but it doesn’t promise anything else. Slaves can still be lagging behind and even though the data is stored on persistent storage as a relay log and, eventually, it will be applied to the dataset, it still doesn’t mean it has been applied already. You can query your slaves and do not see the data you have just written to the master.
Even clusters like Galera by default do not come with the truly synchronous replication – the gap is significantly reduced compared to the replication systems but it is still there and immediate SELECT executed after a previous write may not see the data you just stored in the database because your SELECT was routed to a different Galera node than your previous write.
There are several workarounds you can use to scale Moodle MySQL database. For starters, if you use replication setup, you can use the “safe reads” feature from Moodle. We covered that in one of our previous blogs. This will lead to the situation in which Moodle will decide which writes will be distributed across the slaves and which ones will be hitting the master.
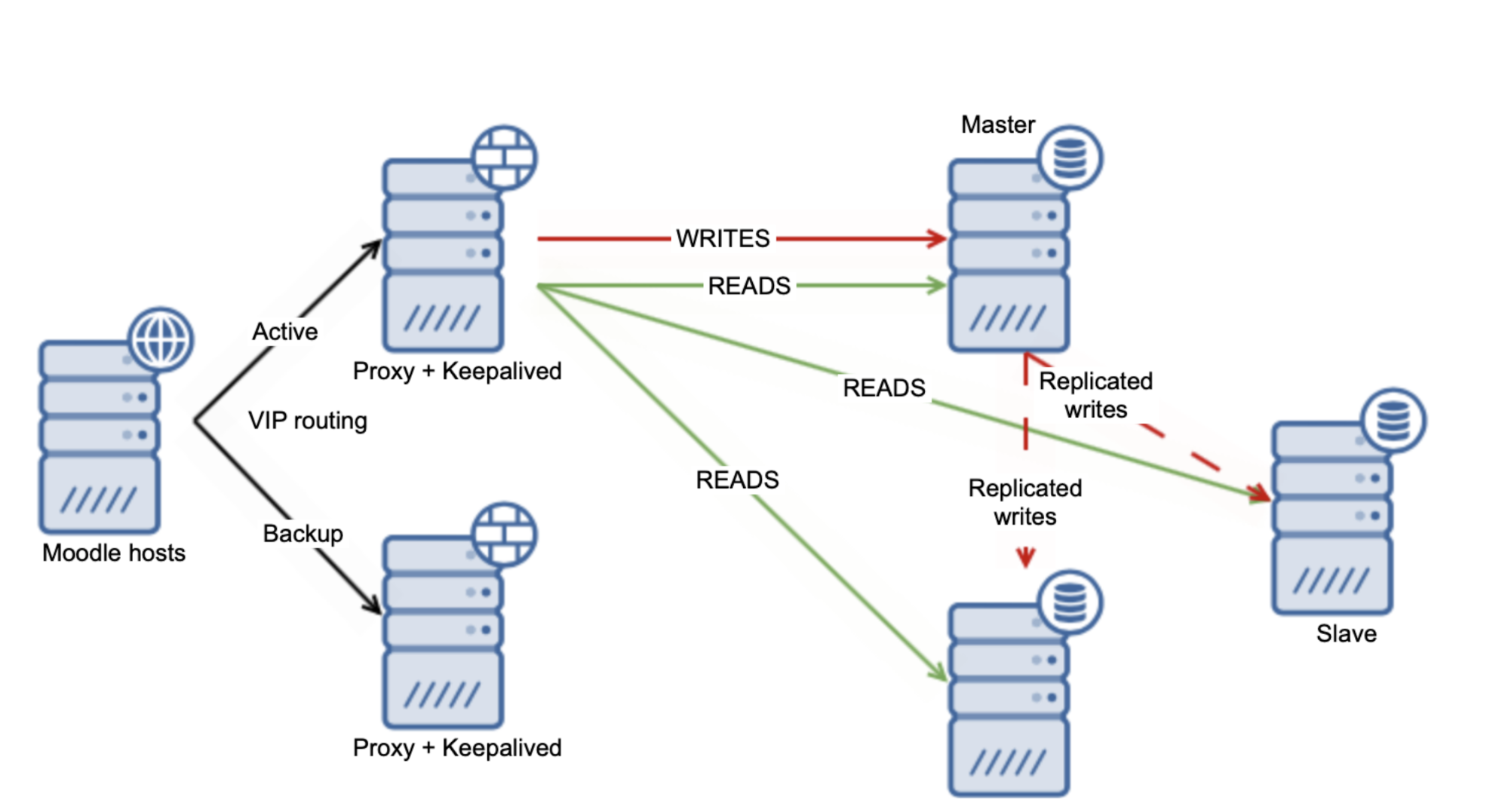
On one hand it is good – you are safe to use several slaves attached to the master, allowing you to offload the master to some extent at least. On the other hand, it is far from ideal, because it is just a subset of SELECTs that you will be able to send to the slaves. Of course, it all depends on the exact case but you can expect that the master will remain to be a bottleneck regarding the load.
Alternative approach could be to use the Galera Cluster and distribute the load evenly across all of the nodes.
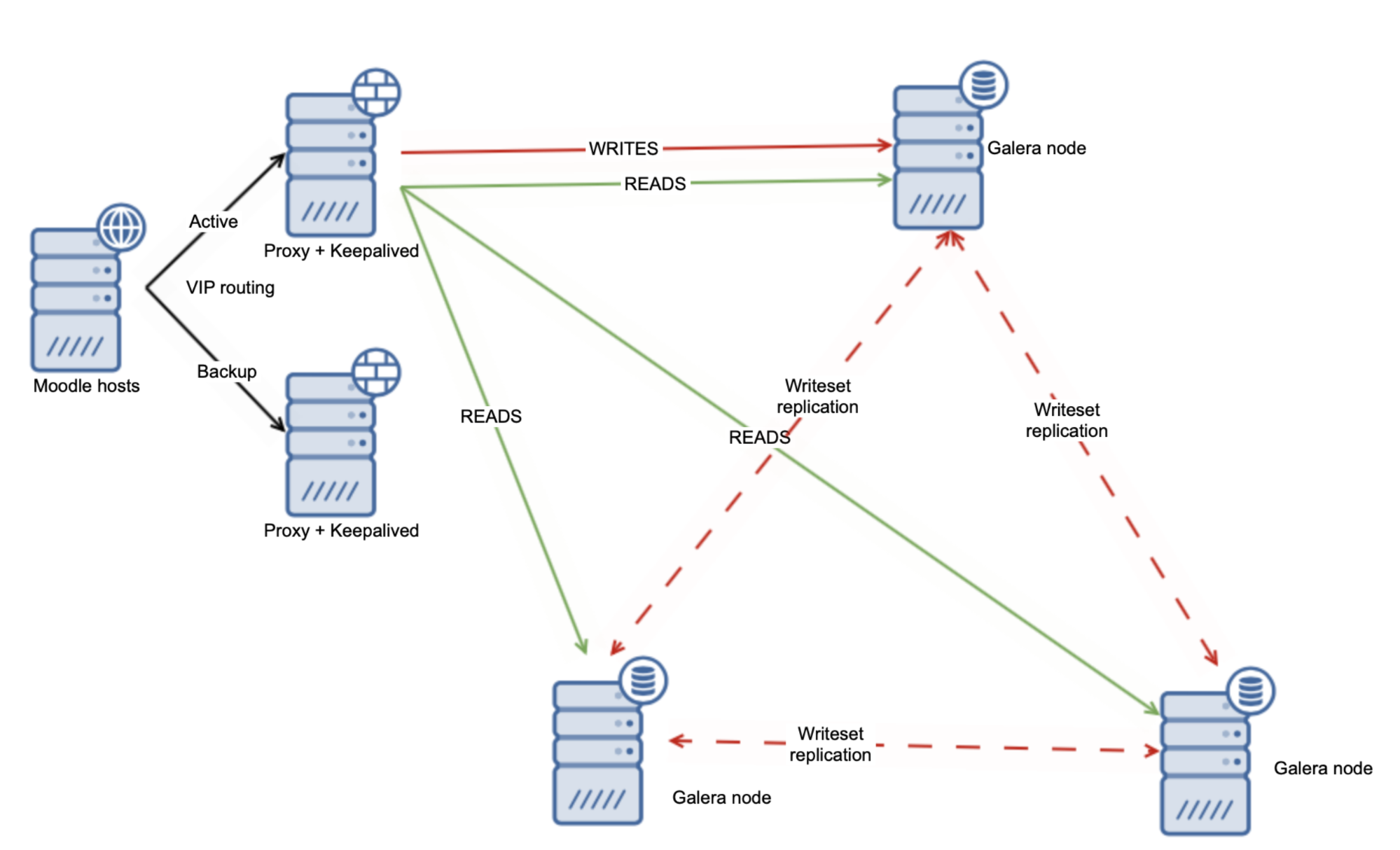
On its own this is not enough to handle all of the read-after-write issues but luckily you can use the wsrep-sync-wait variable which can be used to ensure that the causality checks are in place and the cluster behaves like a real synchronous cluster. Using this setting will allow you to read safely from all of your Galera nodes.
Of course, enforcing causality checks will impact the Galera performance but it still makes sense as you can benefit from reading from multiple Galera nodes at the same time. From that point, scaling reads with the Galera Cluster is quite easy – you just add more Galera nodes to the cluster. Load Balancer should be reconfigured to pick them up and use as an additional target for the reads letting you scale out to even 10+ reader nodes.
You have to keep in mind that adding additional nodes, replication or Galera, it doesn’t really matter, adds some complexity to the operations on the cluster. You have to ensure that your nodes are monitored properly, that you have backups working, the replication is performing properly and that the cluster itself is in a correct state. For replication environments failover has to be handled one way or the other and for both Galera and replication you may want to be able to rebuild the nodes in the cluster if you detect any kind of data inconsistency across the cluster. Luckily, ClusterControl can significantly help you to handle those challenges.
How ClusterControl Helps to Manage the Moodle MySQL Database Cluster
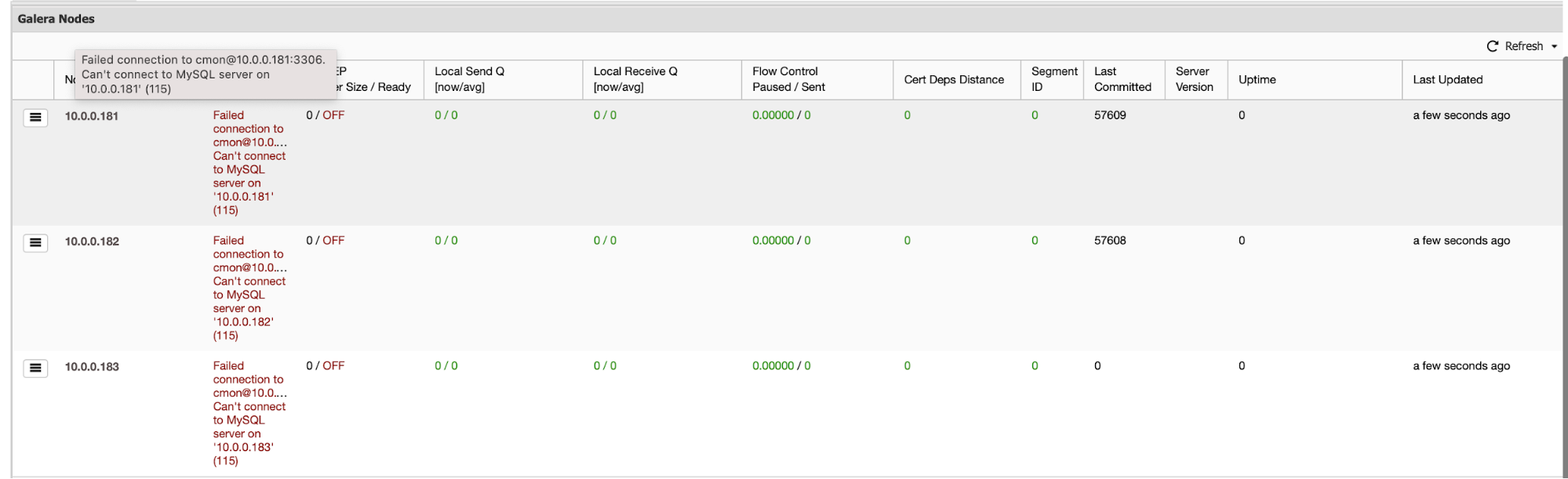
First of all, if the whole cluster collapses, ClusterControl will perform an automated cluster recovery – as long as all of the nodes will be available, ClusterControl will start the cluster recovery process:

After a bit of time, the whole cluster should be back online.
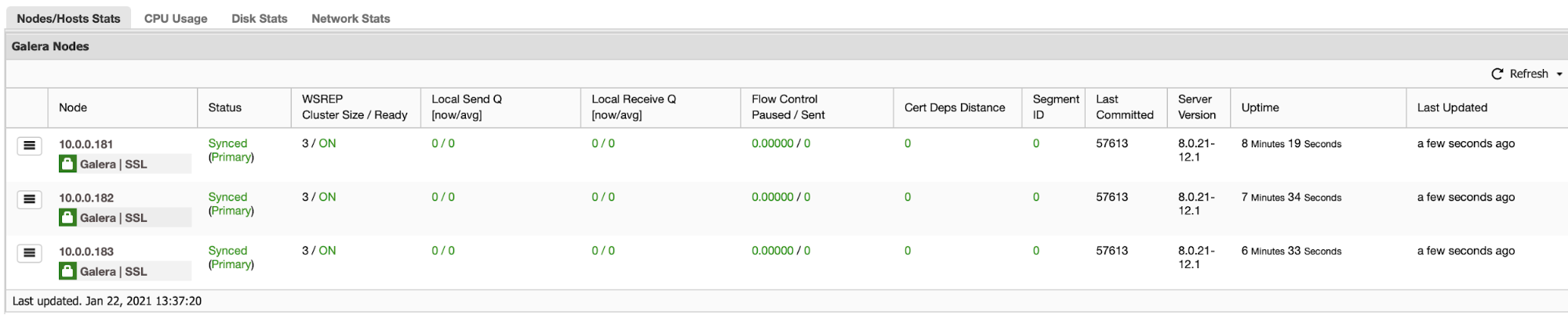
ClusterControl comes with a set of a management options:
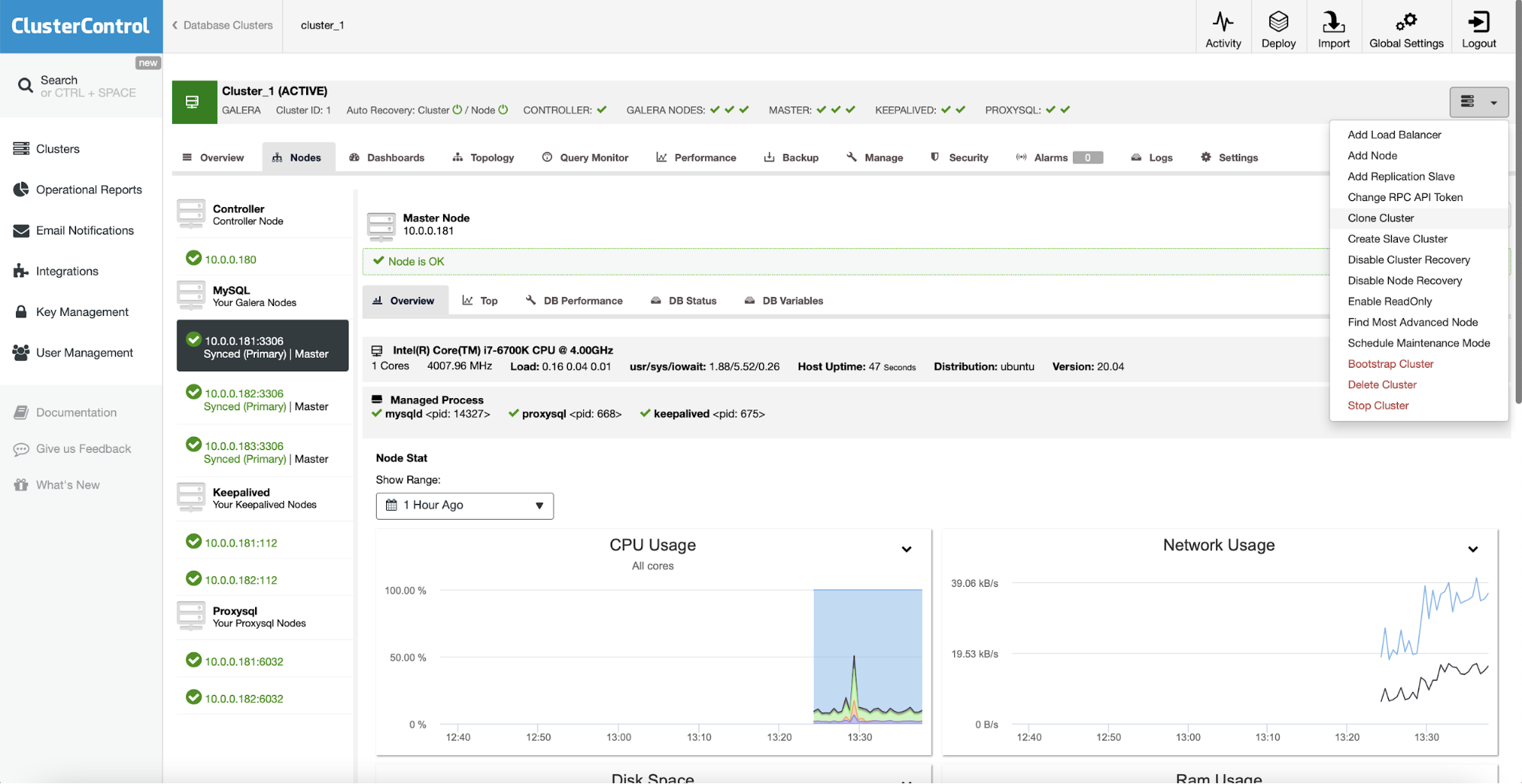
You can scale out the cluster by adding nodes or replication slaves. You can even create a whole slave cluster that will be replicating off the main cluster.
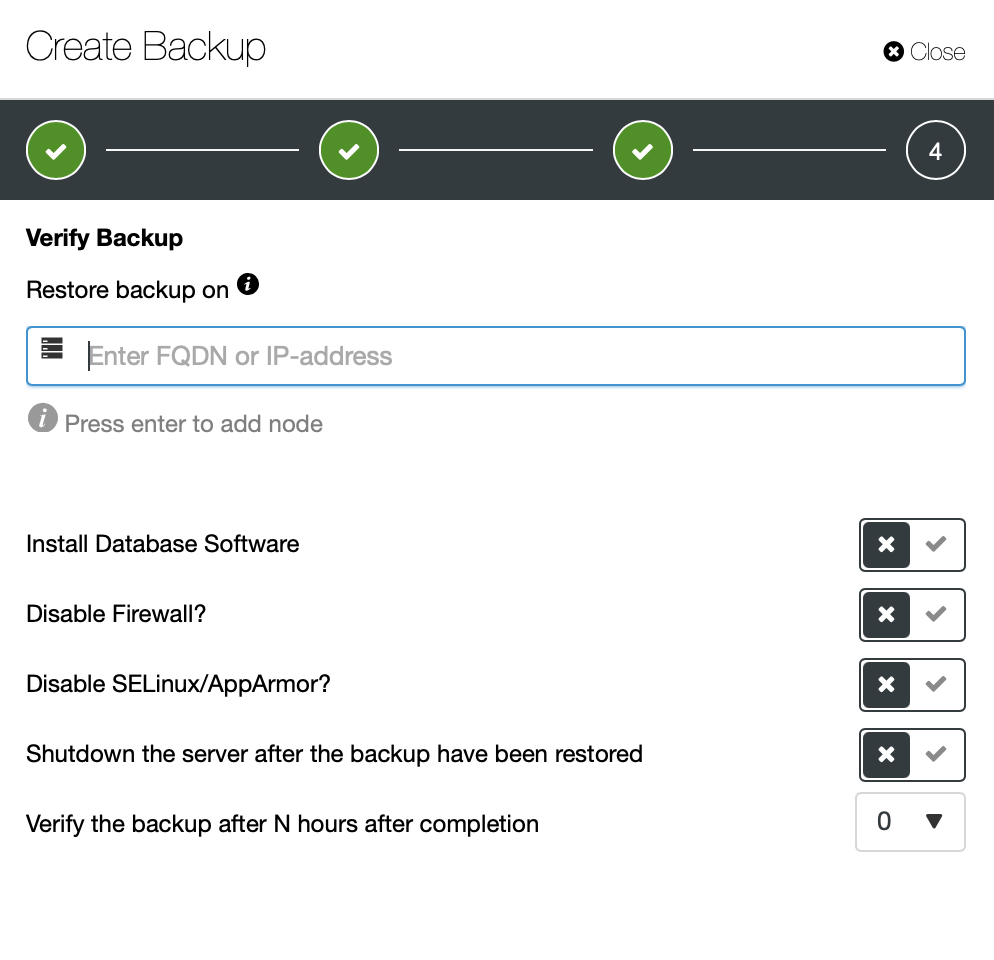
It is possible to easily set up a backup schedule which will be executed by ClusterControl. You can even set up automated backup verification.
You probably want to be able to monitor your database cluster. ClusterControl allows you to do just that:
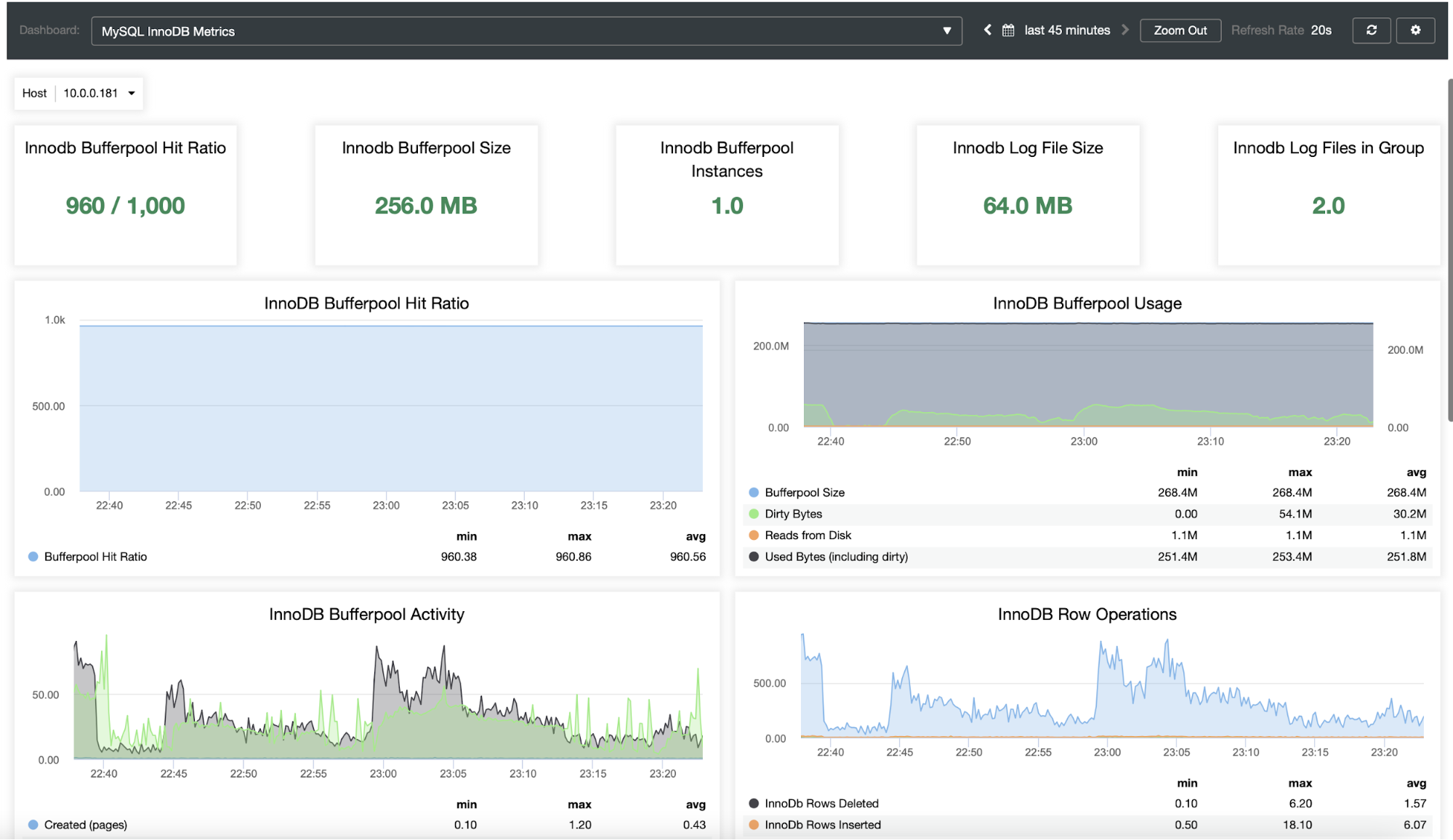
As you can see, ClusterControl is a great platform that can be used to reduce the complexity of scaling and managing the Moodle MySQL database. We would love to hear about your experience with scaling out the Moodle and its database in particular.



