blog
Best Practices for Archiving Your Database in the Cloud

With the technology available today there is no excuse for failing to recover your data due to lack of backup policies or understanding of how vital it is to take backups as part of your daily, weekly, or monthly routine. Database backups must be taken on a regular basis as part of your overall disaster recovery strategy.
The technology for handling backups has never been more efficient and many best practices have been adopted (or bundled) as part of a certain database technology or service that offers it.
To some extent, people still don’t understand how to store data backups efficiently, nor do they understand the difference between data backups versus archived data.
Archiving your data provides many benefits, especially in terms of efficiency such as storage costs, optimizing data retrieval, data facility expenses, or payroll for skilled people to maintain your backup storage and its underlying hardware. In this blog, we’ll look at the best practices for archiving your data in the cloud.
Data Backups vs Data Archives
For some folks in the data tech industry, these topics are often confusing, especially for newcomers.
Data backups are backups that are taken from your physical and raw data to be stored locally or offsite which can be accessed in case of emergency or data recovery. It is used to restore data in case it is lost, corrupted or destroyed.
Data archived, on the other hand, are data (or can still be a backup data) but are no longer used or less critical to your business needs such as stagnant data, yet it’s still not obsolete and has value on it. This means that data that is to be stored is still important but that doesn’t need to be accessed or modified frequently (if at all). Its purpose can be among these:
- reduce its primary consumption so it can be stored on a low-performant machines since data stored on it doesn’t mean it has to be retrieved everyday or immediately.
- Retain cost-efficiency on maintaining your data infrastructure
- Worry-less for an overgrowing data especially those data that are old or data that are infrequently changed from time-to-time.
- Avoid large expenses when maintaining backup appliances or software that are integrated into the backup system.
- As a requirement to meet regulatory standards like HIPAA, PCI-DSS or GDPR to store legacy data or data that they are required to keep
While for databases, it has a very promising benefits which are,
- it helps reduce data complexity especially when data grows drastically but archiving your data helps maintain the size of your data set.
- It helps your daily, weekly, or monthly data backups perform optimally because it has less data since it doesn’t need to include processing the old or un-useful data. It’s un-useful since it’s not a useless data but it’s just un-useful for daily or frequent needs.
- It helps your queries perform efficiently and optimization results can be consistent at times since it doesn’t require to scan large and old data.
- data storage space can be managed and controlled accordingly based on its data retention and policy.
Data archived facility is not necessarily has to be the same power and resources as the data backups storage have. Tape drives, magnetic disk, or optical drives can be used for data archiving opposes. While it’s purpose of storing the data means its infrequently accessed or shall be accessed not very soon but still can be accessible when it’s needed.
Additionally, people involved in data archival requires to identify what archived data means. Data archives are those data that are not reproducible or data that can be re-generated or self-generated. If the data stored in the database are records that can be a result of a mathematical determinants or calculation that are predictably reproducible, then these can be re-generated if needed. This can be excluded for your data archival purposes.
Data Retention Standards
It’s true that pruning your data records stored in your database and moving it to your archives has some great benefits. It doesn’t mean, however, that you are free to do this as it depends on your business requirements. In fact, different countries have laws that require you to follow (or at least implement) based on the regulation. You will need to determine what archived data mean to your business application or what data are infrequently accessed.
For example, Healthcare providers are commonly required (depending on its country of origin) to retain patient’s information for long periods of time. While in Finance, the rules depend on the specific country. What data you need to retain should be verified so you can safely prune it for archival purposes and then store it in a safe, secure place.
The Data Life-Cycle
Data backups and data archives are usually taken alongside through a backup life-cycle process. This life-cycle process has to be defined within your backup policy. Most backup policies have to undergo the process as listed below…
- it has the process defined on which it has to be taken (daily, weekly, monthly),
- if it has to be a full backup or an incremental backup,
- the format of the backup if it has to be compressed or stored in an archived file format,
- if the data has to be encrypted or not,
- its designated location to store the backup (locally stored on the same machine or over the local network),
- its secondary location to store the backup (cloud storage, or in a collo),
- and it’s data retention on how old your data can be present until its end-of-life or destroyed.
What Applications Need Data Archiving?
While everyone can enjoy the benefits of data archiving, there are certain fields that regularly practice this process for managing and maintaining their data.
Government institutions fall into this criteria. Security and public safety (such as video surveillance, threats to personal, residential, social, and business safety) require that this information be retained. This type of data must be stored securely for years to come for forensic and investigative purposes.
Digital Media companies often have to store large amounts of content of their data and these files are often very large in size. Digital Libraries also has to store tons of data for research or information for public use.
Healthcare providers, including insurance, are required to retain large amounts of information on their patients’ for many years. Certainly, data can grow quickly and it can affect the efficiency of the database when it’s not maintained properly.
Cloud Storage Options For Your Archived Data
The oop cloud companies are actively competing to get you great features to store your archived data in the cloud. It starts with a low cost price and offers flexibility to access your data off-site. Cloud storage is a useful and reliable off-site data storage for data backups and data archiving purposes, especially because it’s very cost efficient. You don’t need to maintain large amounts of data. No need to maintain your hardware and storage services in your local site or primary site. It’s less expensive, as well, in handling electricity billings.
These points are important as you might not need to access your archived date in real-time. On certain occasions, especially when a recovery or investigation has to be done, you might require access to your data abruptly. For some businesses, they offer their customers the ability to access their old data, but you have to wait for hours or days before they can provide the access to download the archived data.
For example, in AWS, they have AWS S3 Glacier which offers a great flexibility. In fact, you can store your data via S3, setup a life-cycle policy and define the end of your data when it will be destroyed. Check out the documentation on How Do I Create a Lifecycle Policy for an S3 Bucket?. The great thing with AWS S3 Glacier is that, it is highly flexible. See their waterfall model below,
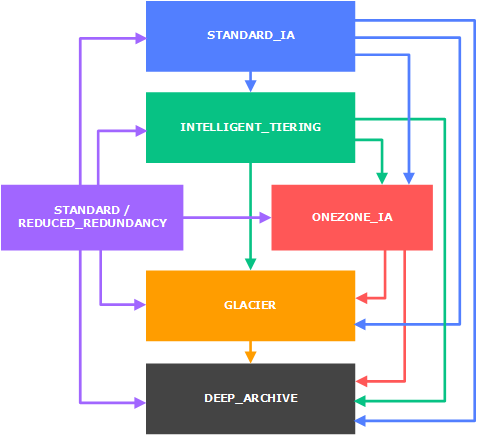
At this level, you can store your backups to S3 and let the life-cycle process defined in that bucket handle the data archival purposes.
If you’re using GCP (Google Cloud Platform), they also offer similar approach. Check out their documentation about Object Lifecycle Management. GCP uses the TTL (or Time-to-Live) approach for retaining objects stored in their Cloud Storage. The great thing with the GCP offering is that they have Archival Cloud Storage which offers Nearline and Coldline storage types.
Coldline is ideal for data that are infrequently modified or access in a year. Where as with the Nearline storage type, it’s more frequent (a monthly rate or at least modified once a month) but possibly multiple times throughout the year. Your data stored in a life-cycle basis can be accessed in a sub-second and that could be fast.
With Microsoft Azure, its offerings are plain and simple. They offer the same thing as GCP and AWS does and it offers you to move your archived data into hot or cool tiers. You maybe able to prioritize your requested archived data when needed to the hot or cool tiers but comes with a price compared to a standard request. Checkout their documentation on Rehydrate blob data from the archive tier.
Overall, this provides hassle free when storing your archived data to the cloud. You may need to define your requirements and of course cost involved when determining which cloud would you need to avail.
Best Practices for Your Archived Data in the Cloud
Since we have tackled the differences of data backups and archived data (or data archives), and some of the top cloud vendor offerings, let’s take a list of what’s the best practices you must have when storing to the cloud.
- Identify the type of data to be archived. As stated earlier, data backups is not data archived but your data backups can be a data archived. However, data archives are those data that are stagnant, old data, and has infrequently accessed. You need to identify first what are these, mark a tag or add a label to these archived data so you would be able to identify it when stored off-site.
- Determine Data Access Frequency. Before everything else has to be archived, you need to identify how frequently will you be going to access the archived data when needed. Certain price can differ on the time you have to access data. For example, Amazon S3 will charge higher if you avail for Expedite Retrieval using Provisioned instead of On-Demand, same thing with Microsoft Azure when you rehydrate archived data with a higher priority.
- Ensure Multiple Copies Are Spread. Yes, you read it correctly. Even it’s archived data or stagnant data, you still need to ensure that your copies are highly available and highly durable when needed. The cloud vendors we have mentioned earlier offers SLA’s that will give you an overview of how they store the data for efficiency and faster accessibility. In fact, when configuring your life-cycle policy/backup policy, ensure that you are able to store it in multiple regions or replicate your archived data into a different region. Most of these tech-giant cloud vendors stores their archival cloud storage offerings with multiple zones to offer highly scalable and durable in times of data retrieval is requested.
- Data Compliance. Ensure that data compliance and regulations are followed accordingly and make it happen during initial phase and not later. Unless the data doesn’t affect customer’s profile and are just business logic data and history, it might be harmless when it’s destroyed but it’s better to make things in accord.
- Provider standards. Choose the right cloud backup and data-retention provider. Walking the path of online data archiving and backup with an experienced service provider could save you from unrecoverable data loss. The top 3 tech-giants of the cloud can be your top choice. But you’re free to choose as well promising cloud vendors out there such as Alibaba, IBM or Oracle Archive Storage. It can be best to try it out before making your final decision.
Data Archiving Tools and Software
Database using MariaDB, MySQL, or Percona Server can benefit with using pt-archiver. pt-archiver has been widely used for almost a decade and allows you to prune your data while doing archiving as well. For example, the command below to remove orphan records can be done as,
pt-archiver --source h=host,D=db,t=child --purge
--where 'NOT EXISTS(SELECT * FROM parent WHERE col=child.col)'or send the rows to a different host such as OLAP server,
pt-archiver --source h=oltp_server,D=test,t=tbl --dest h=olap_server
--file '/var/log/archive/%Y-%m-%d-%D.%t'
--where "1=1" --limit 1000 --commit-eachFor PostgreSQL or TimescaleDB, you can try and use the CTE (Common Table Expressions) to achieve this. For example,
CREATE TABLE public.user_info_new (LIKE public.user_info INCLUDING ALL);
ALTER TABLE public.user_info_new OWNER TO sysadmin;
GRANT select ON public.user_info_new TO read_only
GRANT select, insert, update, delete ON public.user_info TO user1;
GRANT all ON public.user_info TO admin;
ALTER TABLE public.user_info INHERIT public.user_info_new;
BEGIN;
LOCK TABLE public.user_info IN ACCESS EXCLUSIVE MODE;
LOCK TABLE public.user_info_new IN ACCESS EXCLUSIVE MODE;
ALTER TABLE public.user_info RENAME TO user_info_old;
ALTER TABLE public.user_info_new RENAME TO user_info;
COMMIT; (or ROLLBACK; if there's a problem)Then do a,
WITH row_batch AS (
SELECT id FROM public.user_info_old WHERE updated_at >= '2016-10-18 00:00:00'::timestamp LIMIT 20000 ),
delete_rows AS (
DELETE FROM public.user_info_old u USING row_batch b WHERE b.id = o.id RETURNING o.id, account_id, created_at, updated_at, resource_id, notifier_id, notifier_type)
INSERT INTO public.user_info SELECT * FROM delete_rows;Using CTE with Postgres might incur performance issues. You might have to run this during non-peak hours. See this external blog to be careful on using CTE with PostgreSQL.
For MongoDB, you can try and use mongodump with the –archive parameters just like below,
mongodump --archive=test.$(date +"%Y_%m_%d").archive --db=testthis will dump an archive file namely test.
Using ClusterControl for Data Archival
ClusterControl allows you to set a backup policy and upload data off-site to your desired cloud storage location. ClusterControl supports the Top three clouds (AWS, GCP, and Microsoft Azure). Please checkout our previous blog on Best Practices for Database Backups to learn more.
With ClusterControl you can take a backup by first defining the backup policy, choose the database, and archive the table just like below…
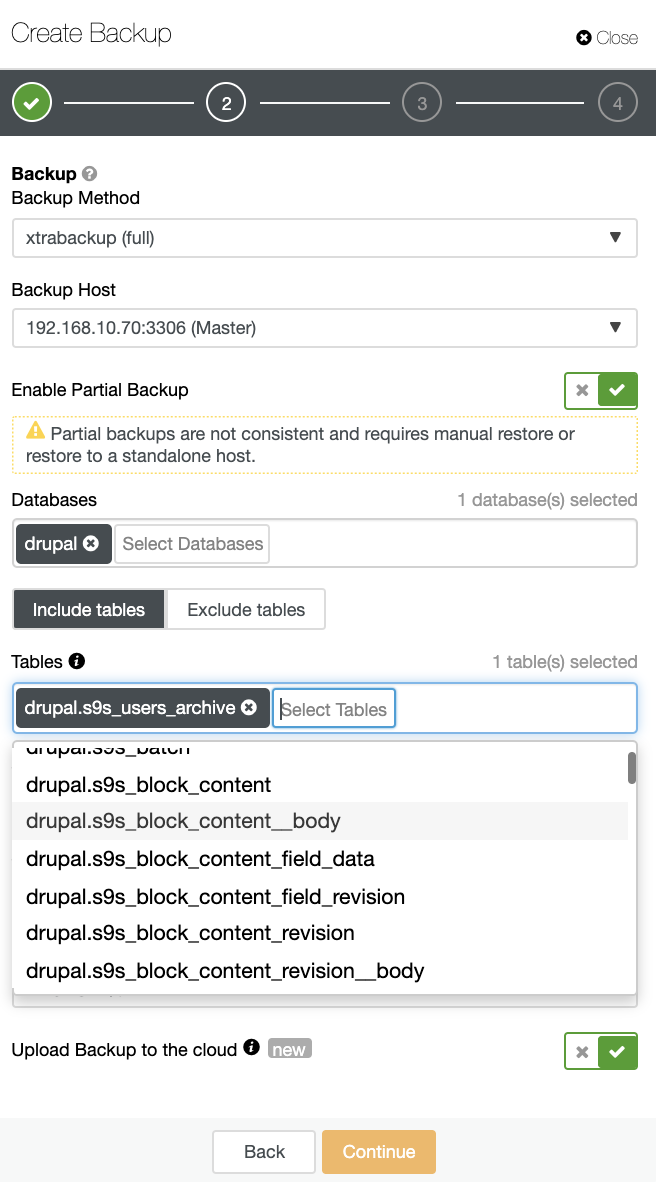
Make sure that the “Upload Backup to the cloud” is enabled or checked just like above. Define the backup settings and set retention,
Then define the cloud settings just like below.
For the selected bucket, ensure that you have setup lifecycle management, and in this scenario, we’re using AWS S3. In order to setup the lifecycle rule, you just have to select the bucket, then go to the Management tab just like below,
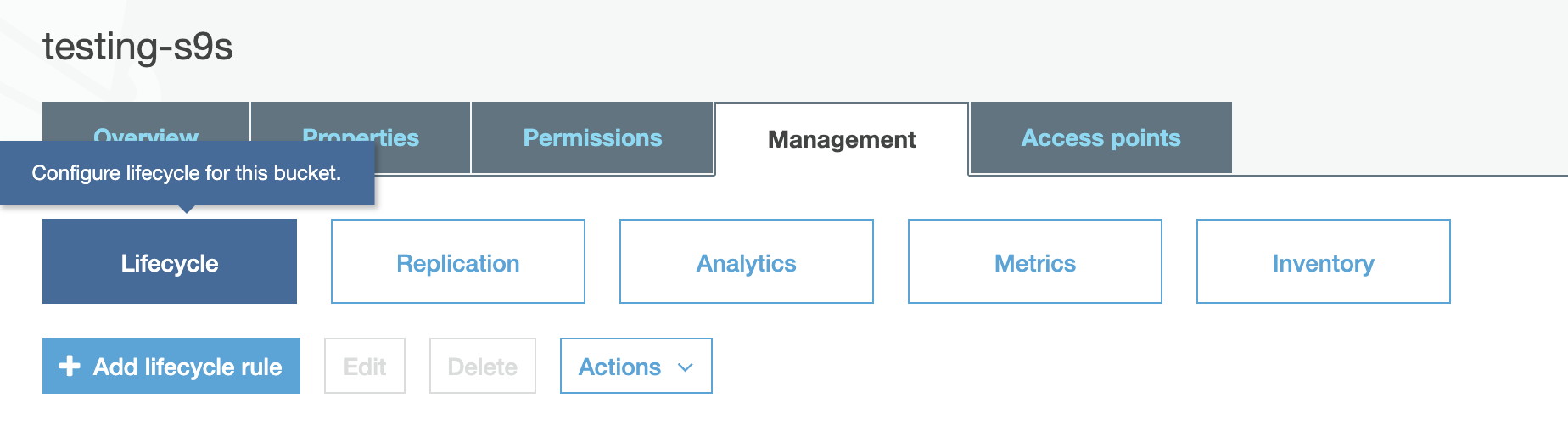
then setup the lifecycle rules as follows,
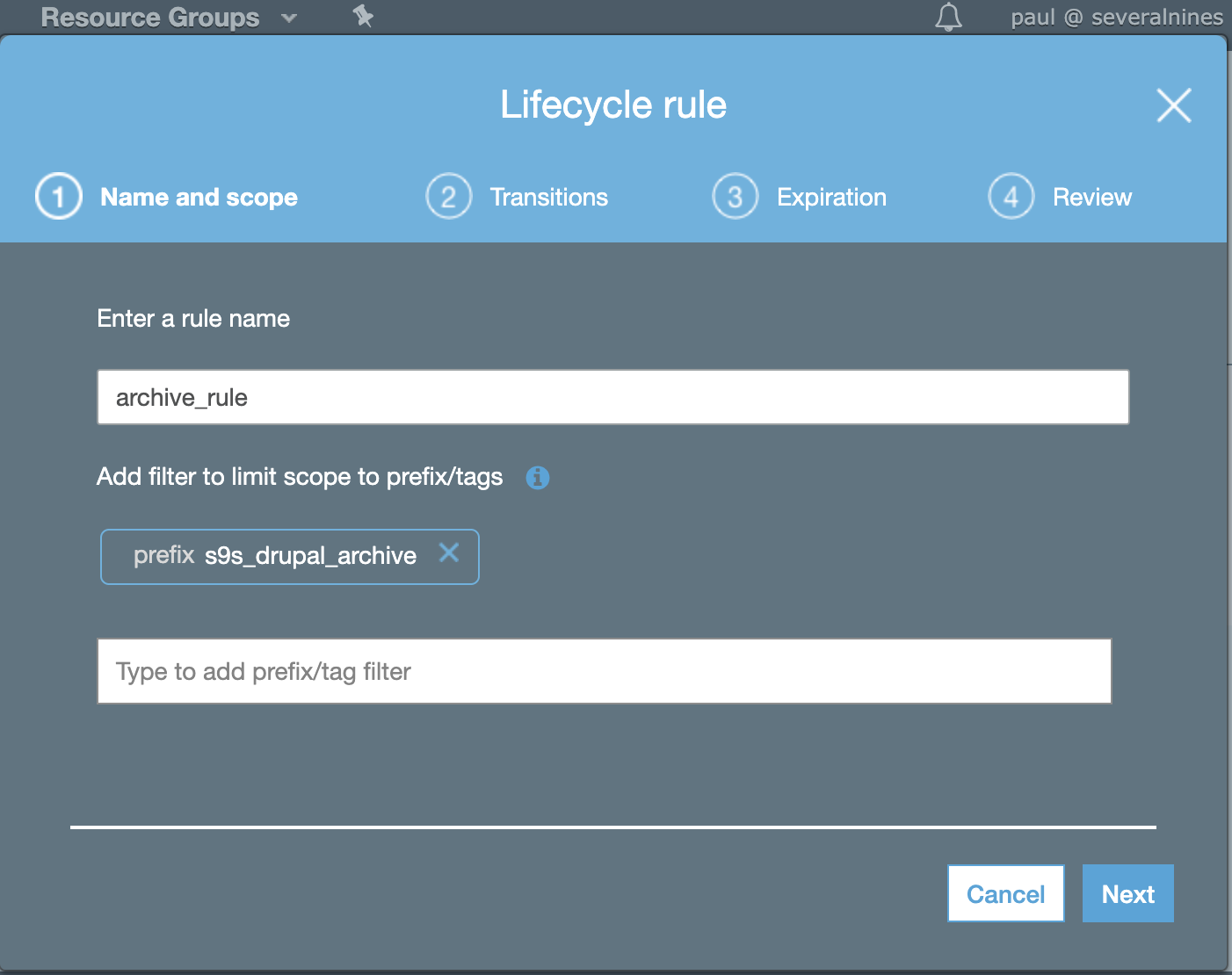
then ensure its transitions,
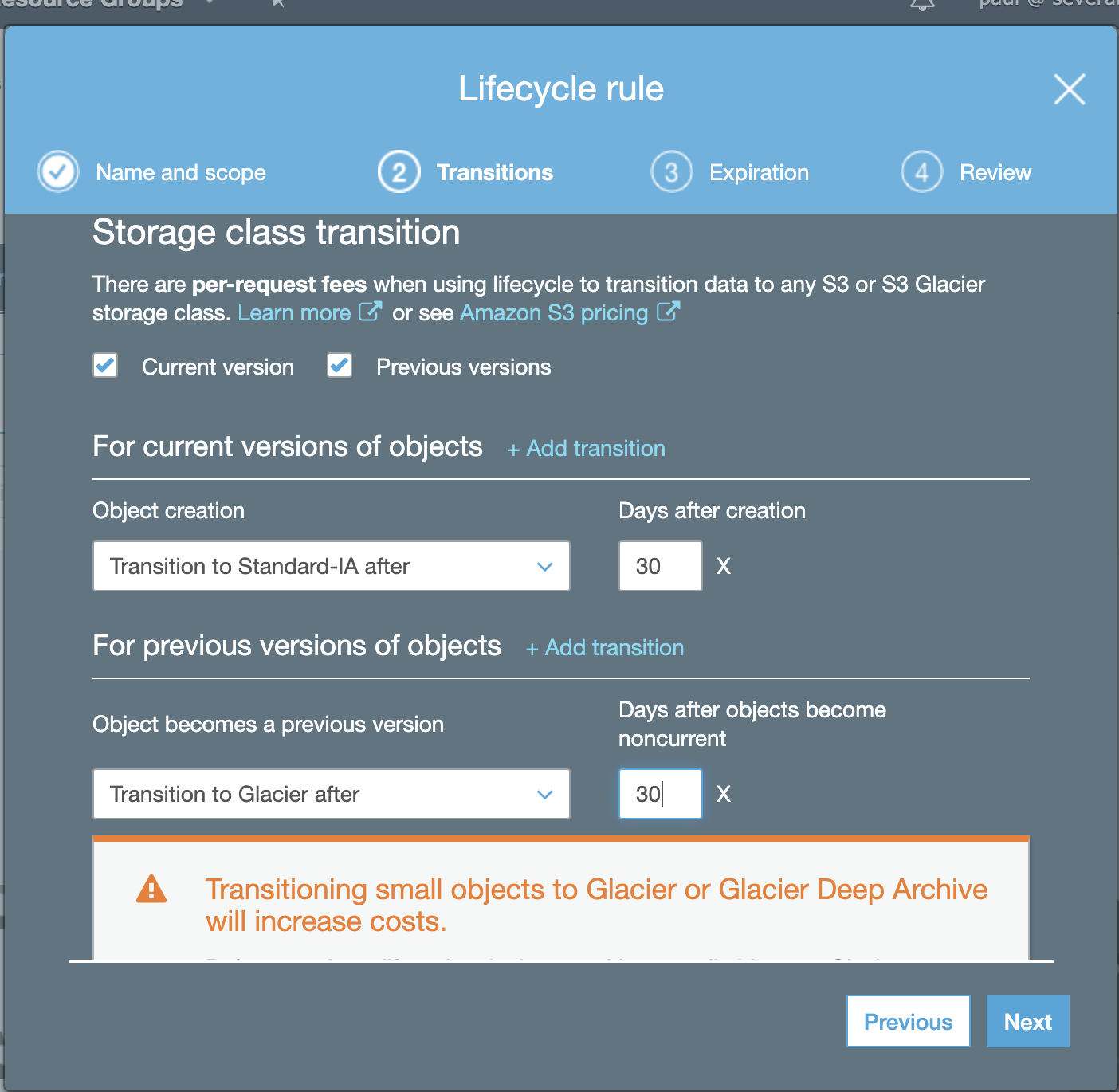
In the example above, we’re ensuring the transition will go to Amazon S3 Glacier, which is our best choice to retain archived data.
Once you are done setting up, you’re good-to-go to take the backup. Your archived data will follow the lifecycle you have setup within AWS for this example. If you use GCP or Microsoft Azure, it’s just the same process where you have to set the backup along with its lifecycle.
Conclusion
Adopting the best practices for archiving your data into the cloud can be cumbersome at the beginning, however, if you have the right set of tools or bundled software, it will make your life easier to implement the process.



