blog
The Most Common PostgreSQL Failure Scenarios

There is not a perfect system, hardware, or topology to avoid all the possible issues that could happen in a production environment. Overcoming these challenges requires an effective DRP (Disaster Recovery Plan), configured according to your application, infrastructure, and business requirements. The key to success in these types of situations is always how fast we can fix or recover from the issue.
In this blog we’ll take a look at the most common PostgreSQL failure scenarios and show you how you can solve or cope with the issues. We’ll also look at how ClusterControl can help us get back online
The Common PostgreSQL Topology
To understand common failure scenarios, you must first start with a common PostgreSQL topology. This can be any application connected to a PostgreSQL Primary Node which has a replica connected to it.
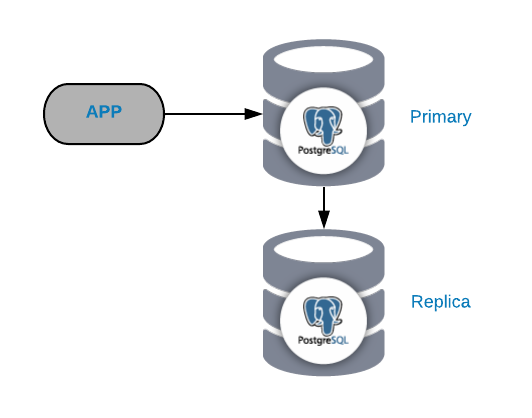
You can always improve or expand this topology by adding more nodes or load balancers, but this is the basic topology we’ll start working with.
Primary PostgreSQL Node Failure
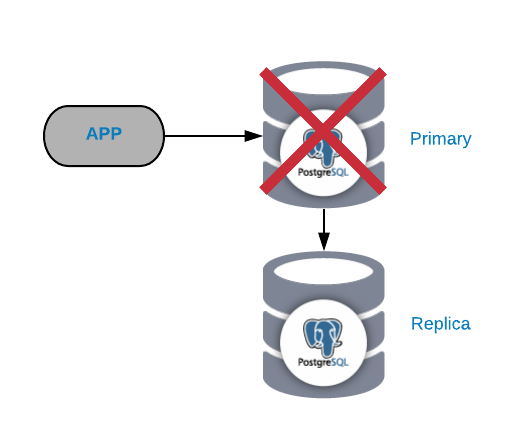
This is one of the most critical failures as we should fix it ASAP if we want to keep our systems online. For this type of failure it’s important to have some kind of automatic failover mechanism in place. After the failure, then you can look into the reason for the issues. After the failover process we ensure that the failed primary node doesn’t still think that it’s the primary node. This is to avoid data inconsistency when writing to it.
The most common causes of this kind of issue are an operating system failure, hardware failure, or a disk failure. In any case, we should check the database and the operating system logs to find the reason.
The fastest solution for this issue is by performing a failover task to reduce downtime To promote a replica we can use the pg_ctl promote command on the slave database node, and then, we must send the traffic from the application to the new primary node. For this last task, we can implement a load balancer between our application and the database nodes, to avoid any change from the application side in case of failure. We can also configure the load balancer to detect the node failure and instead of sending traffic to him, send the traffic to the new primary node.
After the failover process and make sure the system is working again, we can look into the issue, and we recommend to keep always at least one slave node working, so in case of a new primary failure, we can perform the failover task again.
PostgreSQL Replica Node Failure
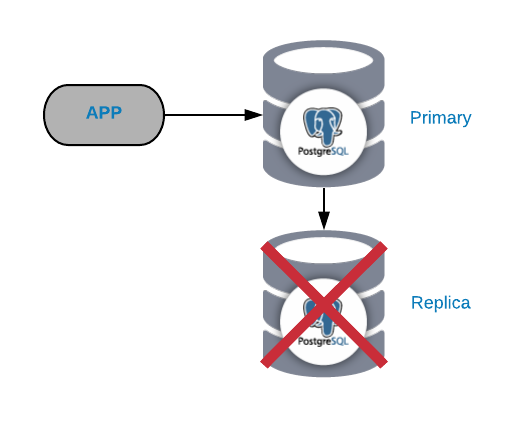
This is not normally a critical issue (as long as you have more than one replica and are not using it to send the read production traffic). If you are experiencing issues on the primary node, and don’t have your replica up-to-date, you’ll have a real critical issue. If you’re using our replica for reporting or big data purposes, you will probably want to fix it quickly anyway.
The most common causes of this kind of issue are the same that we saw for the primary node, an operating system failure, hardware failure, or disk failure .You should check the database and the operating system logs to find the reason.
It’s not recommended to keep the system working without any replica as, in case of failure, you don’t have a fast way to get back online. If you have only one slave, you should solve the issue ASAP; the fastest way being by creating a new replica from scratch. For this you’ll need to take a consistent backup and restore it to the slave node, then configure the replication between this slave node and the primary node.
If you wish to know the failure reason, you should use another server to create the new replica, and then look into the old one to discover it. When you finish this task, you can also reconfigure the old replica and keep both working as a future failover option.
If you’re using the replica for reporting or for big data purposes, you must change the IP address to connect to the new one. As in the previous case, one way to avoid this change is by using a load balancer that will know the status of each server, allowing you to add/remove replicas as you wish.
PostgreSQL Replication Failure
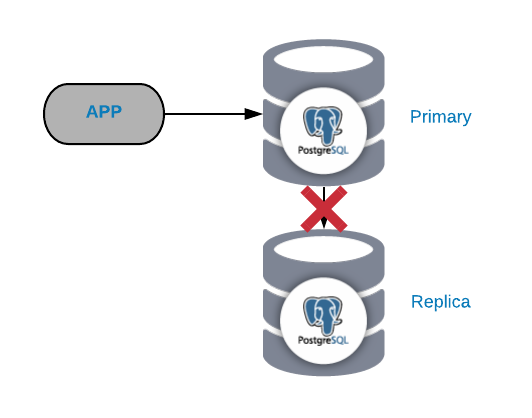
In general, this kind of issue is generated due to a network or configuration issue. It’s related to a WAL (Write-Ahead Logging) loss in the primary node and the way PostgreSQL manages the replication.
If you have important traffic, you’re doing checkpoints too frequently, or you’re storing WALS for only a few minutes; if you have a network issue you’ll have little time to solve it. Your WALs would be deleted before you can send and apply it to the replica.
If the WAL that the replica needs to continue working was deleted you need to rebuild it, so to avoid this task, we should check our database configuration to increase the wal_keep_segments (amounts of WALS to keep in the pg_xlog directory) or the max_wal_senders (maximum number of simultaneously running WAL sender processes) parameters.
Another recommended option is to configure archive_mode on and send the WAL files to another path with the parameter archive_command. This way, if PostgreSQL reaches the limit and deletes the WAL file, we’ll have it in another path anyway.
PostgreSQL Data Corruption / Data Inconsistency / Accidental Deletion

This is a nightmare for any DBA and probably the most complex issue to be fixed, depending on how widespread the issue is.
When your data is affected by some of these issues, the most common way to fix it (and probably the only one) is by restoring a backup. That is why backups are the basic form of any disaster recovery plan and it is recommended that you have at least three backups stored in different physical places. Best practice dictates backup files should have one stored locally on the database server (for a faster recovery), another one in a centralized backup server, and the last one on the cloud.
We can also create a mix of full/incremental/differential PITR compatible backups to reduce our Recovery Point Objective.
Managing PostgreSQL Failure with ClusterControl
Now that we have looked at these common PostgreSQL failures scenarios let’s look at what would happen if we were managing your PostgreSQL databases from a centralized database management system. One that is great in terms of reaching a fast and easy way to fix the issue, ASAP, in the case of failure.
ClusterControl provides automation for most of the PostgreSQL tasks described above; all in a centralized and user-friendly way. With this system you will be able to easily configure things that, manually, would take time and effort. We will now review some of its main features related to PostgreSQL failure scenarios.
Deploy / Import a PostgreSQL Cluster
Once we enter the ClusterControl interface, the first thing to do is to deploy a new cluster or import an existing one. To perform a deployment, simply select the option Deploy Database Cluster and follow the instructions that appear.
Scaling Your PostgreSQL Cluster
If you go to Cluster Actions and select Add Replication Slave, you can either create a new replica from scratch or add an existing PostgreSQL database as a replica. In this way, you can have your new replica running in a few minutes and we can add as many replicas as we want; spreading read traffic between them using a load balancer (which we can also implement with ClusterControl).
PostgreSQL Automatic Failover
ClusterControl manages failover on your replication setup. It detects master failures and promotes a slave with the most current data as the new master. It also automatically fails-over the rest of the slaves to replicate from the new master. As for client connections, it leverages two tools for the task: HAProxy and Keepalived.
HAProxy is a load balancer that distributes traffic from one origin to one or more destinations and can define specific rules and/or protocols for the task. If any of the destinations stop responding, it is marked as offline, and the traffic is sent to one of the available destinations. This prevents traffic from being sent to an inaccessible destination and the loss of this information by directing it to a valid destination.
Keepalived allows you to configure a virtual IP within an active/passive group of servers. This virtual IP is assigned to an active “Main” server. If this server fails, the IP is automatically migrated to the “Secondary” server that was found to be passive, allowing it to continue working with the same IP in a transparent way for our systems.
Adding a PostgreSQL Load Balancer
If you go to Cluster Actions and select Add Load Balancer (or from the cluster view – go to Manage -> Load Balancer) you can add load balancers to our database topology.
The configuration needed to create your new load balancer is quite simple. You only need to add IP/Hostname, port, policy, and the nodes we are going to use. You can add two load balancers with Keepalived between them, which allows us to have an automatic failover of our load balancer in case of failure. Keepalived uses a virtual IP address, and migrates it from one load balancer to another in case of failure, so our setup can continue to function normally.
PostgreSQL Backups
We have already discussed the importance of having backups. ClusterControl provides the functionality either to generate an immediate backup or schedule one.
You can choose between three different backup methods, pgdump, pg_basebackup, or pgBackRest. You can also specify where to store the backups (on the database server, on the ClusterControl server, or in the cloud), the compression level, encryption required, and the retention period.
PostgreSQL Monitoring & Alerting
Before being able to take action you need to know what is happening, so you’ll need to monitor your database cluster. ClusterControl allows you to monitor our servers in real-time. There are graphs with basic data such as CPU, Network, Disk, RAM, IOPS, as well as database-specific metrics collected from the PostgreSQL instances. Database queries can also be viewed from the Query Monitor.
In the same way that you enable monitoring from ClusterControl, you can also setup alerts which inform you of events in your cluster. These alerts are configurable, and can be personalized as needed.
Conclusion
Everyone will eventually need to cope with PostgreSQL issues and failures. And since you can’t avoid the issue, you need to be able to fix it ASAP and keep the system running. We also saw also how using ClusterControl can help with these issues; all from a single and user-friendly platform.
These are what we thought were some of the most common failure scenarios for PostgreSQL. We would love to hear about your own experiences and how you fixed it.



