blog
How to Minimize RPO for Your PostgreSQL Databases Using Point in Time Recovery

In a disaster recovery plan, your Recovery Point Objective (RPO) is a key recovery parameter that dictates how much data you can afford to lose. RPO is listed in time, from seconds to days. Effectively, RPO is directly dependent on your backup system. It marks the age of your backup data that you must recover in order to resume normal operations.
If you do a nightly backup at 10 p.m. and your database system crashes beyond repair at 3 p.m. the following day, you lose everything that was changed since your last backup. Your RPO in this particular context is the previous day’s backup, which means you can afford to lose one day’s worth of changes.
The below diagram from our Whitepaper on Disaster Recovery illustrates the concept.
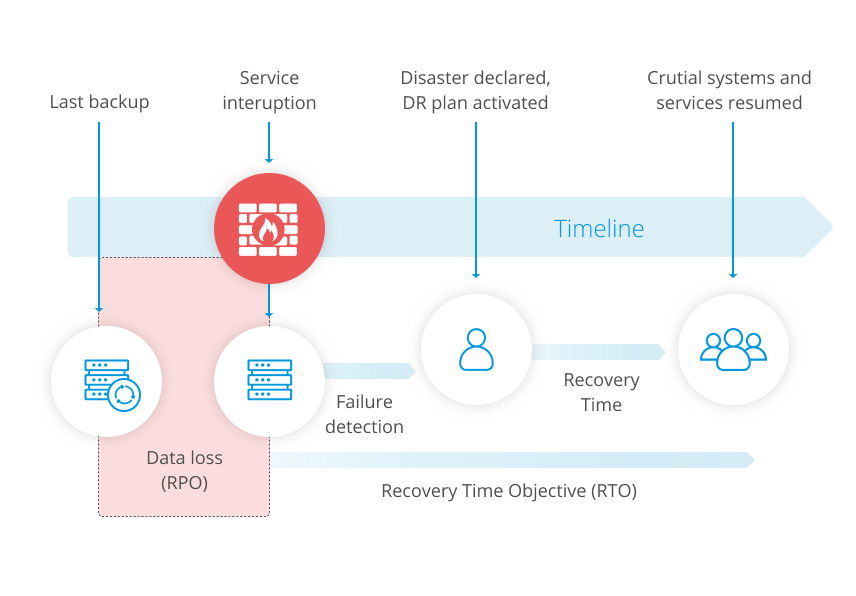
For tighter RPO, a backup might not be enough though. When backing up your database, you are actually taking a snapshot of the data at a given moment. So when you are restoring a backup, you will miss the changes that happened between the last backup and the failure.
This is where the concept of Point In Time Recovery (PITR) comes in.
What is PITR?
Point In Time Recovery (PITR), as the name states, involves restoring the database at any given moment in the past. For being able to do this, we will need to restore a backup, and then apply all the changes that happened after the backup until rightbefore the failure.
For PostgreSQL, the changes are stored in the WAL logs (for more details about WALs and the data they store, you can check out this blog).
So there are two things we need to ensure for being able to perform a PITR: The backups and the WALs (we need to setup continuous archiving for them).
For performing the PITR, we will need to recover the backup and then apply the WALs.
When Could it be Useful?
You can use this strategy whenever you are restoring from an issue that caused the data to be corrupted. You need to keep in mind that you are trying to minimize the data loss, but there are some issues that may cause the data to be not useful anymore after it.
Some examples of this can be unplanned data modifications (DMLs or DDLs), media failure or database maintenances (like upgrades) that lead to data corruption. You will not be able to recover the data changes that happened after the issue.
Let’s suppose a user has wrongly performed a DML, making the data of a whole table to be wrongly altered or deleted. You can perform a PITR of the database in a separate location and then export the contents of the table. You can then restore that table into the existing database, effectively rolling back to a copy of how the table was before the issue happened.
Of course, it is not always possible to restore only a portion of the database in this fashion, so in that case you will need to restore all the database to a given point, and will have a minimal but unavoidable data loss (you will miss any changes that happened after the issue happened).
How to use it with ClusterControl?
In a previous blog, we could see how to implement PITR manually, now let’s see how to use ClusterControl to perform this task.
Enabling Point In Time Recovery
To enable the PITR feature we must have the WAL Archiving enabled. For this we can go to ClusterControl -> Select PostgreSQL Cluster -> Node actions -> Enable WAL Archiving, or just go to ClusterControl -> Select PostgreSQL Cluster -> Backup -> Settings and enable the option “Enable Point-In-Time Recovery (WAL Archiving)” as we will see in the following image.
We must keep in mind that to enable the WAL Archiving, we must restart our database. ClusterControl can do this for us too.
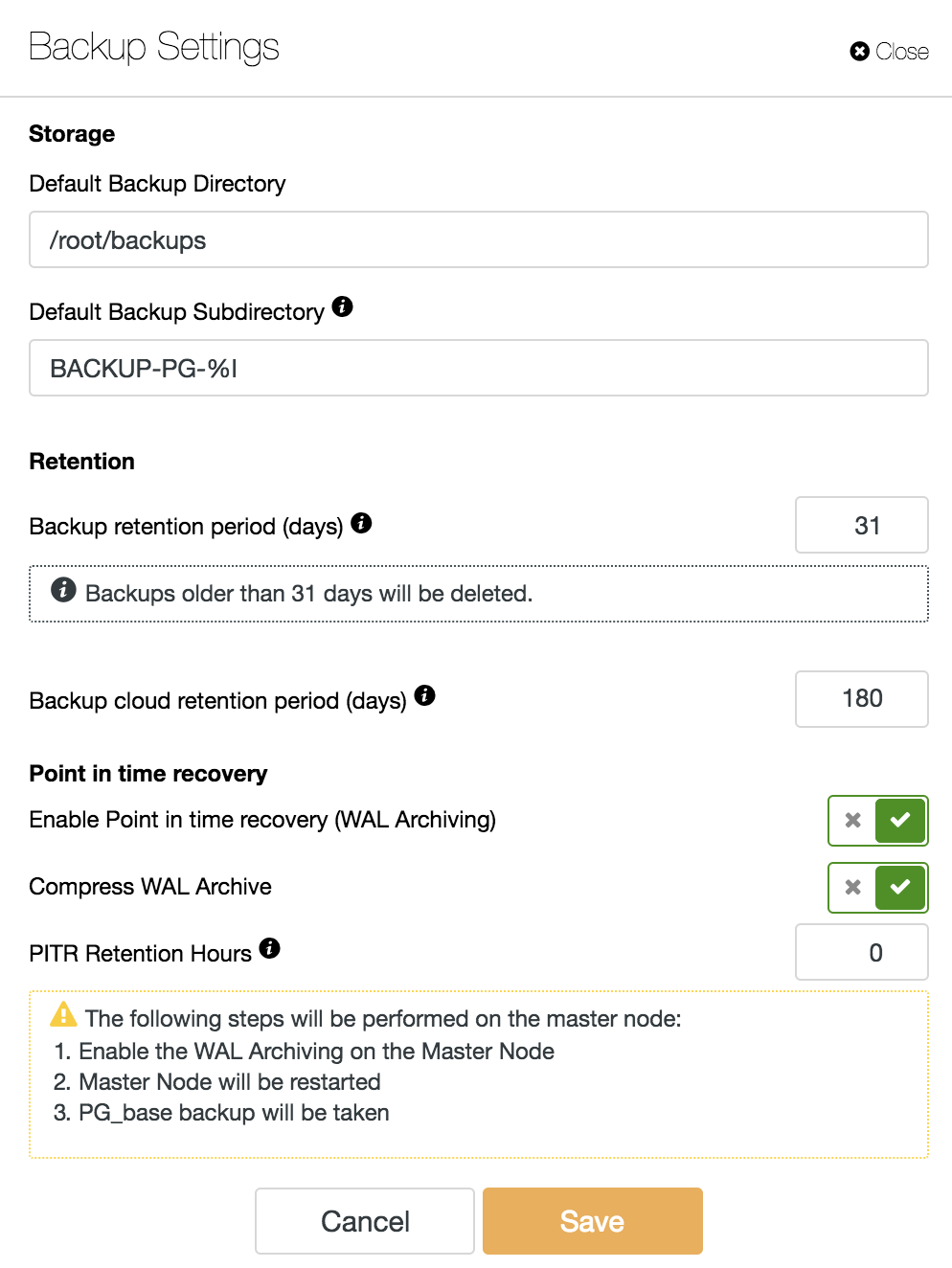
In addition to the options common to all backups like the “Backup Directory” and the “Backup Retention Period”, here we can also specify the WAL Retention Period. By default is 0, which means forever.
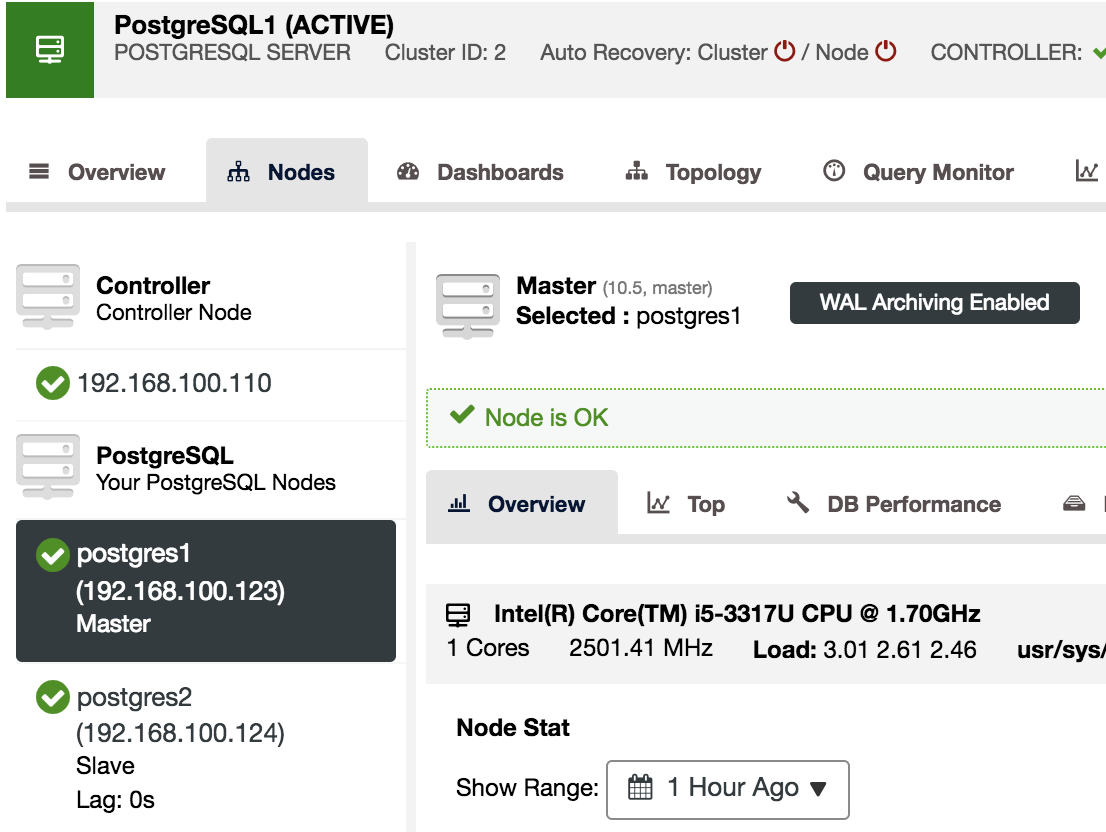
To confirm that we have WAL Archiving enabled, we can select our Master node in ClusterControl -> Select PostgreSQL Cluster -> Nodes, and we should see the WAL Archiving Enabled message, as we can see in the following image.
Creating a Backup Compatible with Point In Time Recovery
Having WAL Archiving enabled, as we saw in the previous step, we can create our backup compatible with PITR. For this, go to ClusterControl -> Select PostgreSQL Cluster -> Backup -> Create Backup.
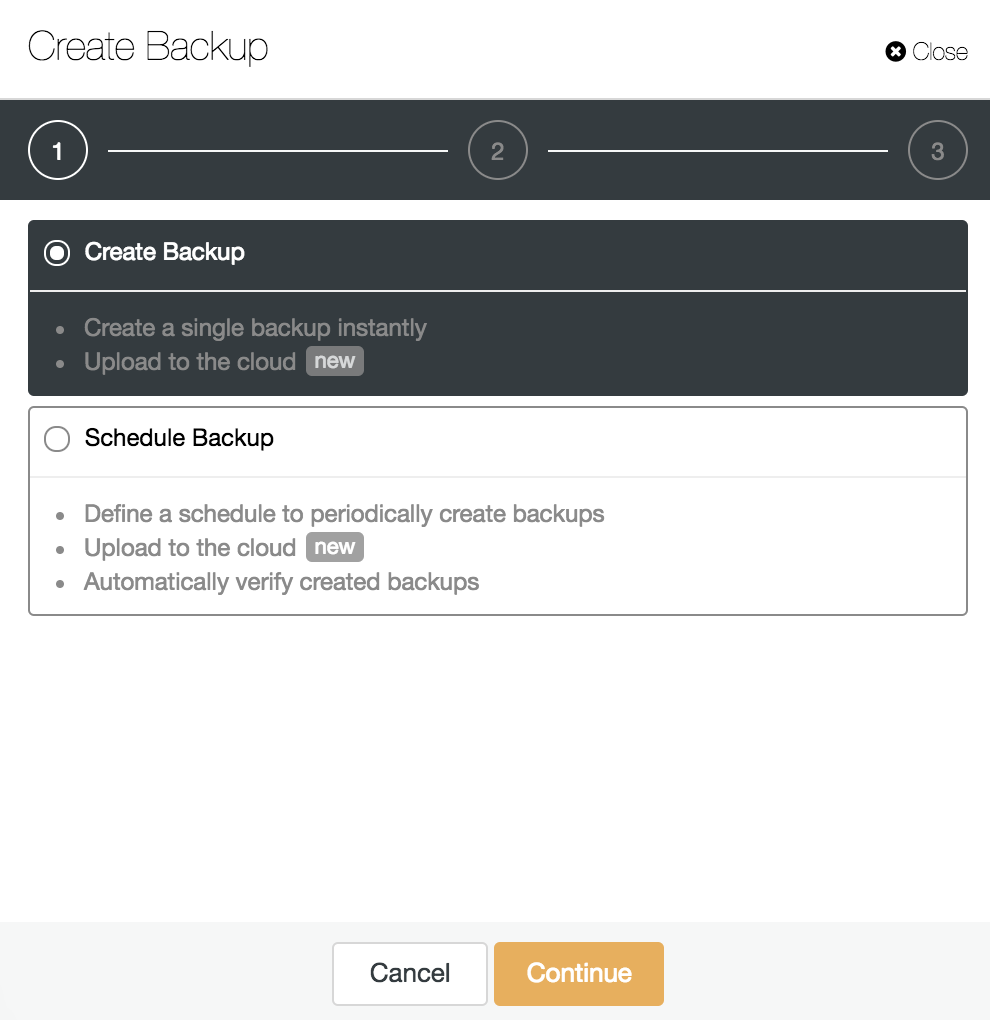
We can create a new backup or configure a scheduled one. For our example, we will create a single backup instantly.
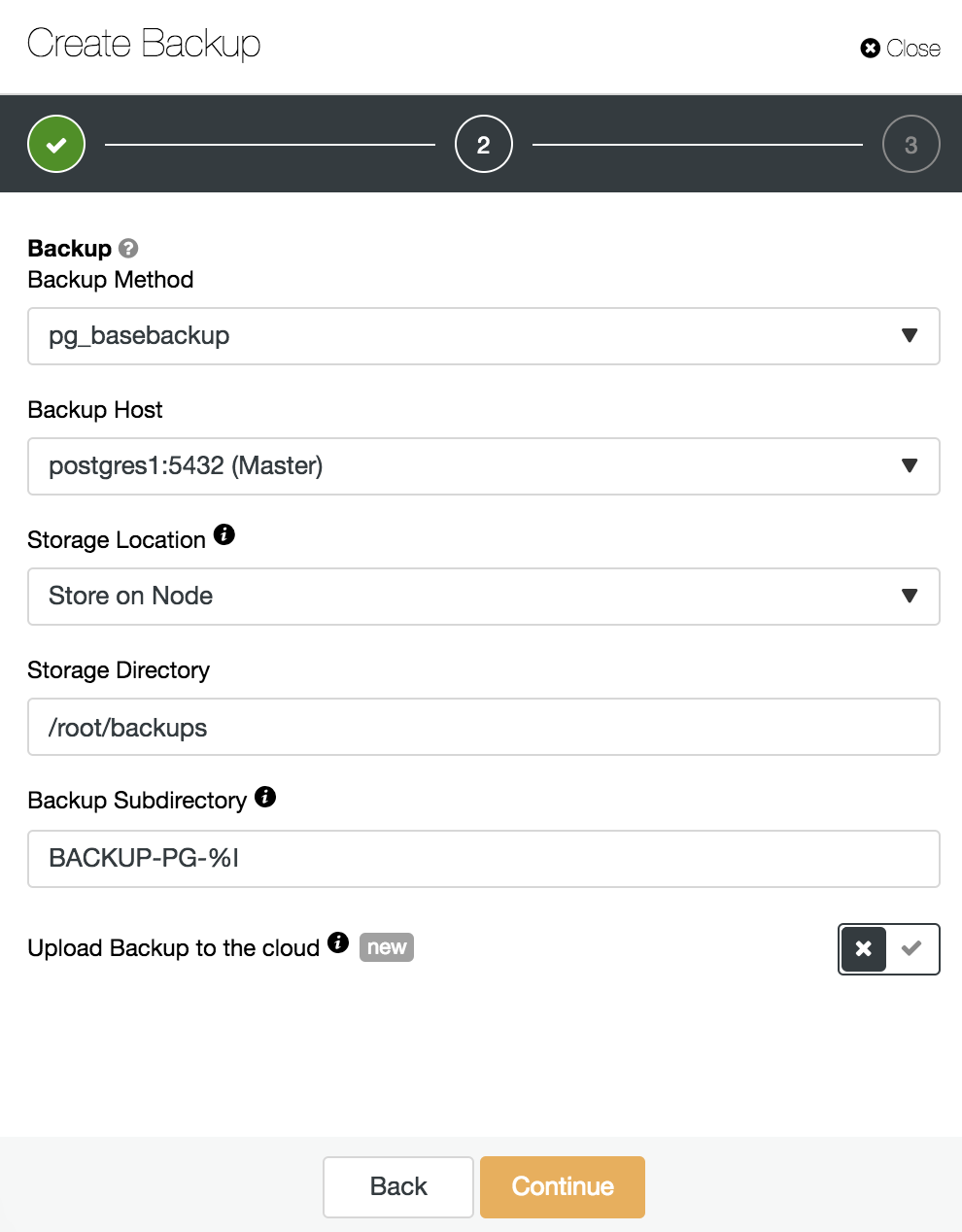
Here we must choose the method “pg_basebackup”, compatible with PITR, the server from which the backup will be taken (to be compatible with PITR, it must be the master), and where we want to store the backup. We can also upload our backup to the cloud (AWS, Google or Azure) by enabling the corresponding button.
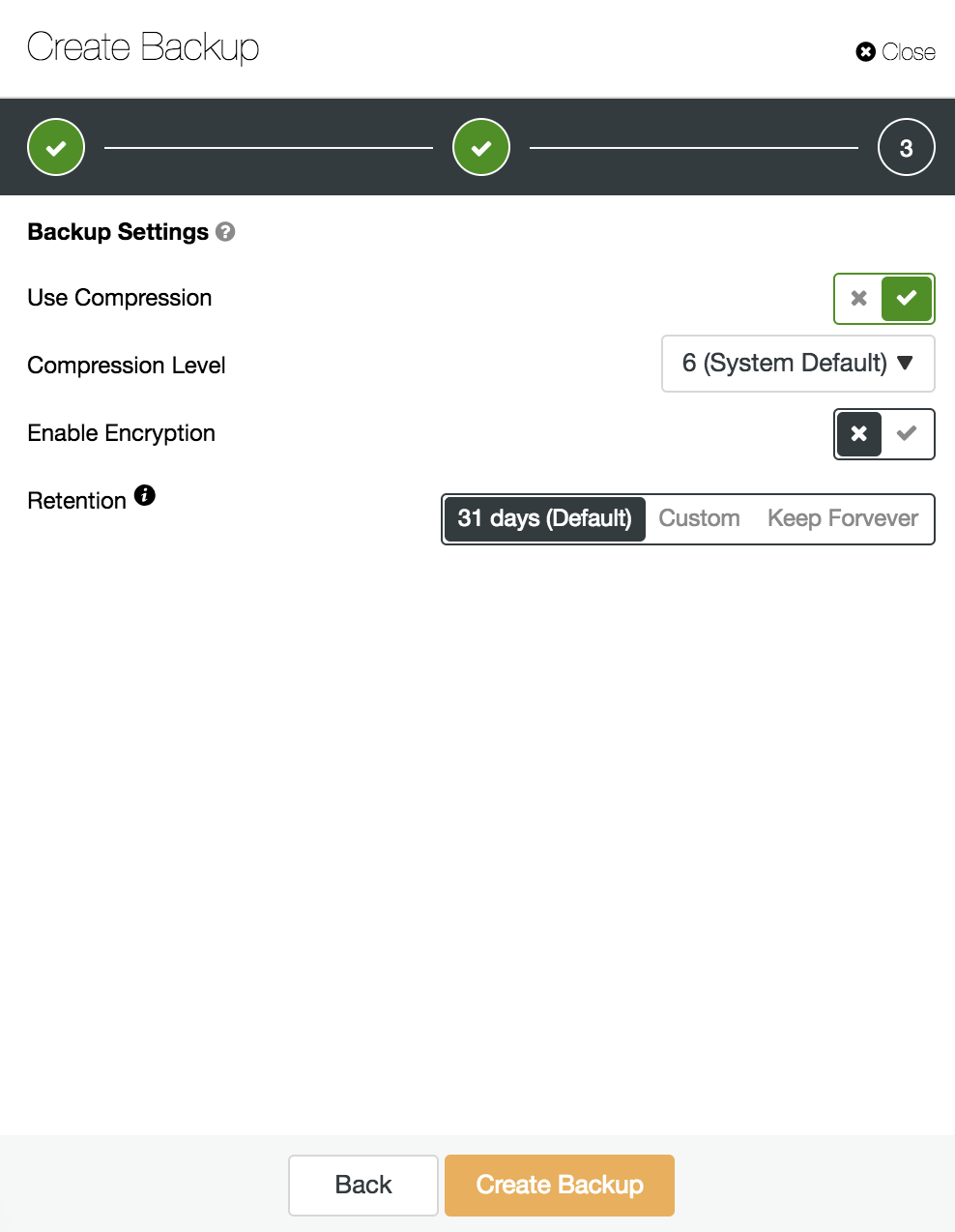
Then we specify the use of compression, encryption and the retention of our backup.
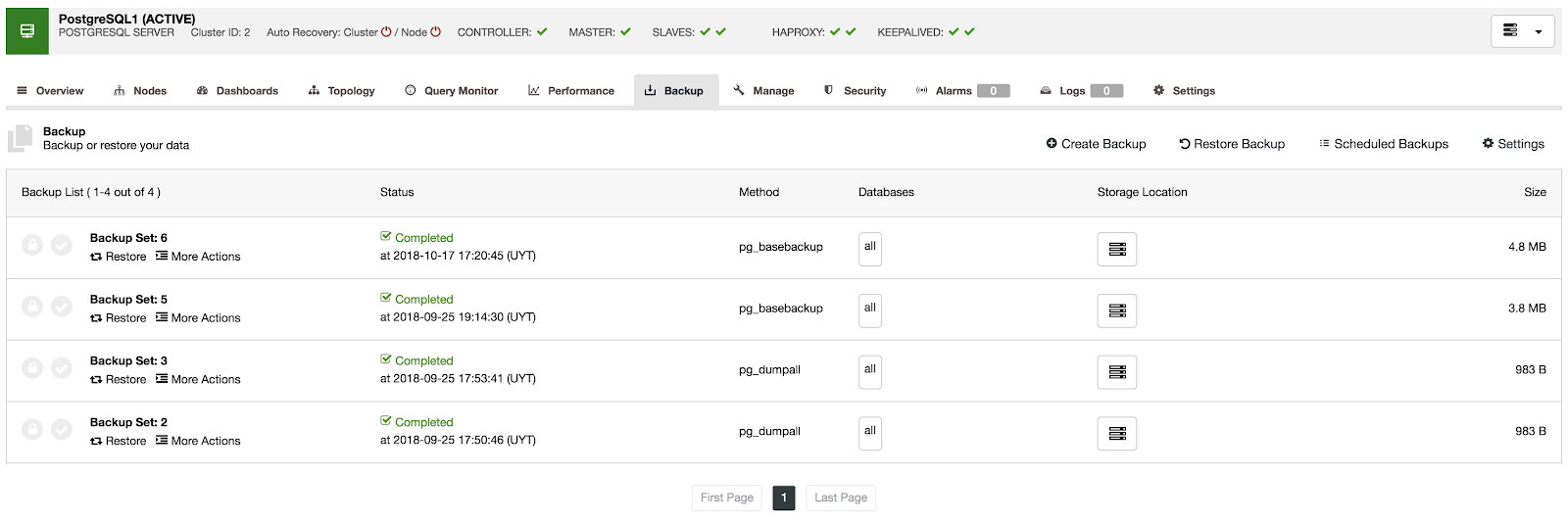
On the backup section, we can see the progress of the backup, and information like the method, size, location, and more.
Point In Time Recovery from a backup
Once the backup is finished, we can restore it using the ClusterControl PITR feature. For this, in our backup section (ClusterControl -> Select PostgreSQL Cluster -> Backup), we can select “Restore Backup”, or directly “Restore” on the backup that we want to restore.
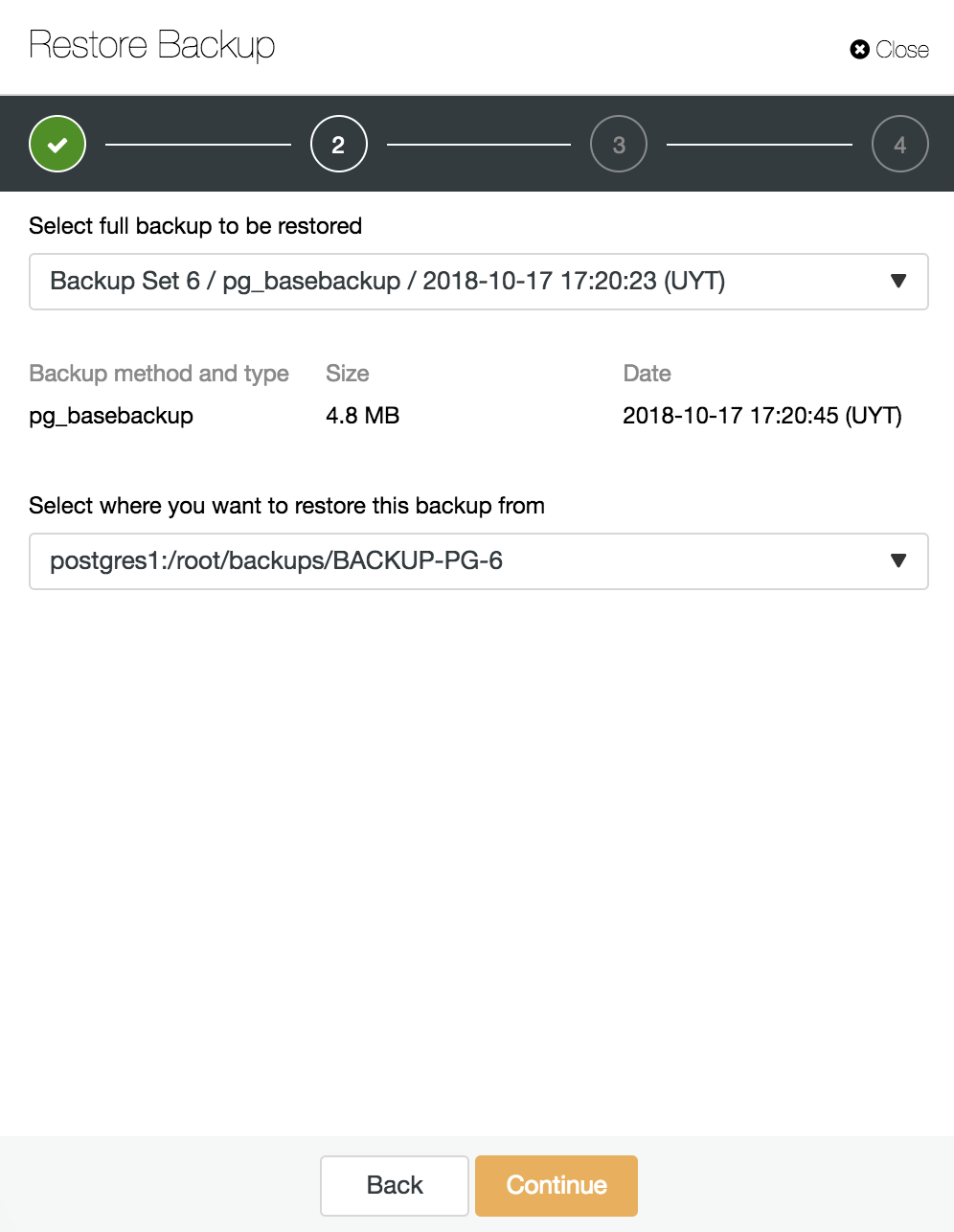
Here we choose which backup we want to restore and from which directory.
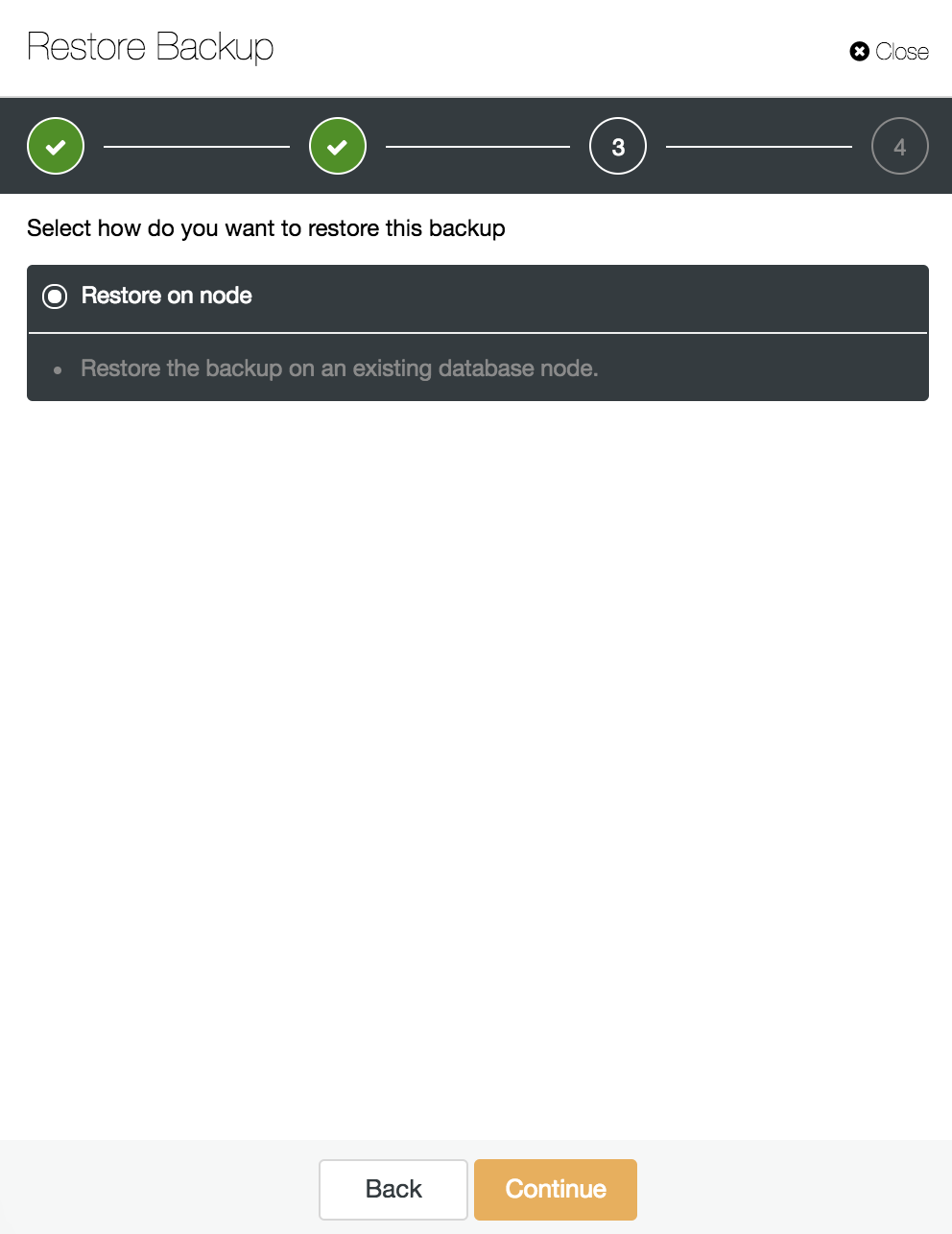
We leave the “Restore on node” option selected and continue.
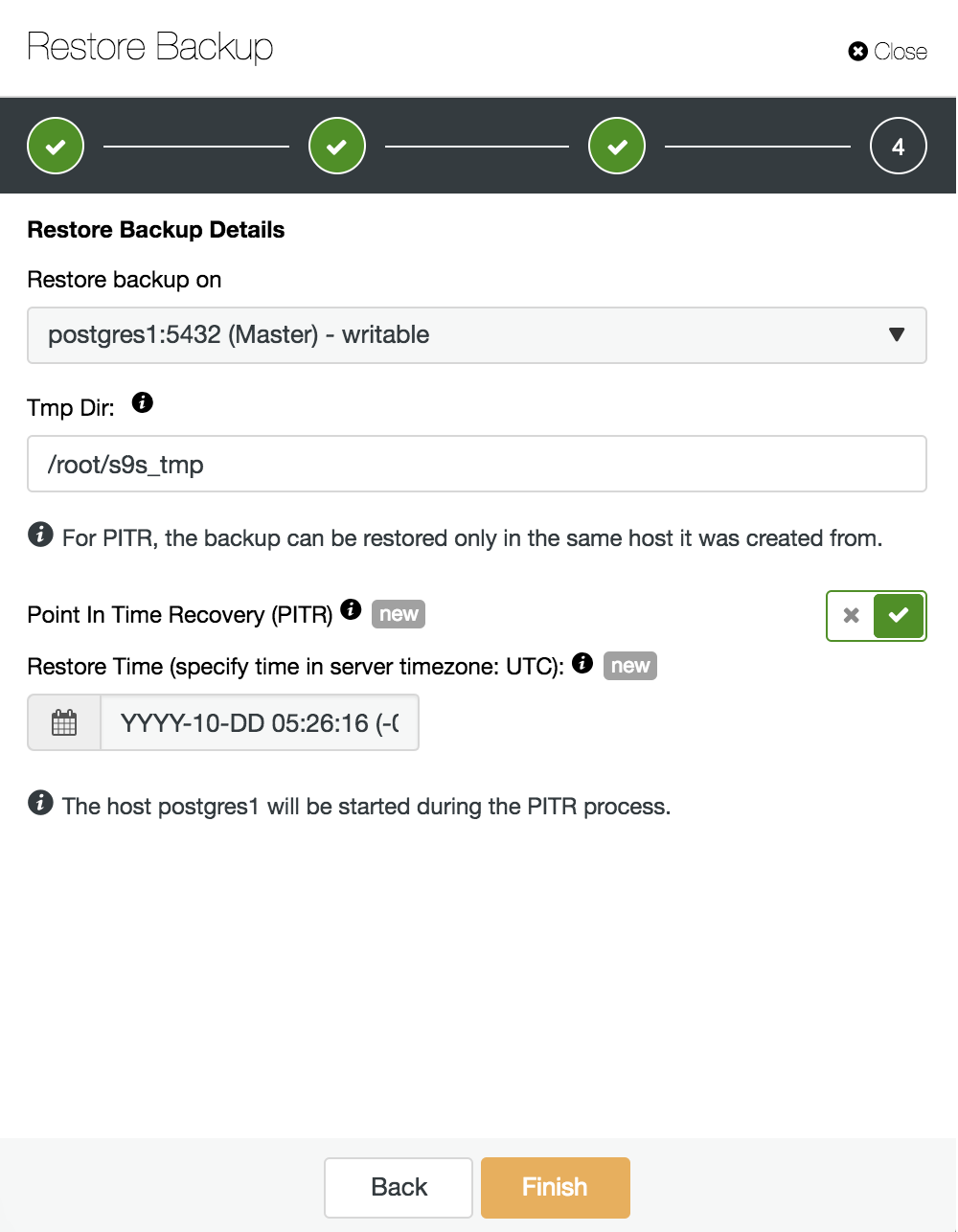
Now we must choose where to restore our backup and enable the PITR option. By specifying the time, it will be the time until when we’ll recover. Take into account that the UTC timezone is used and that our PostgreSQL service in the master will be restarted.
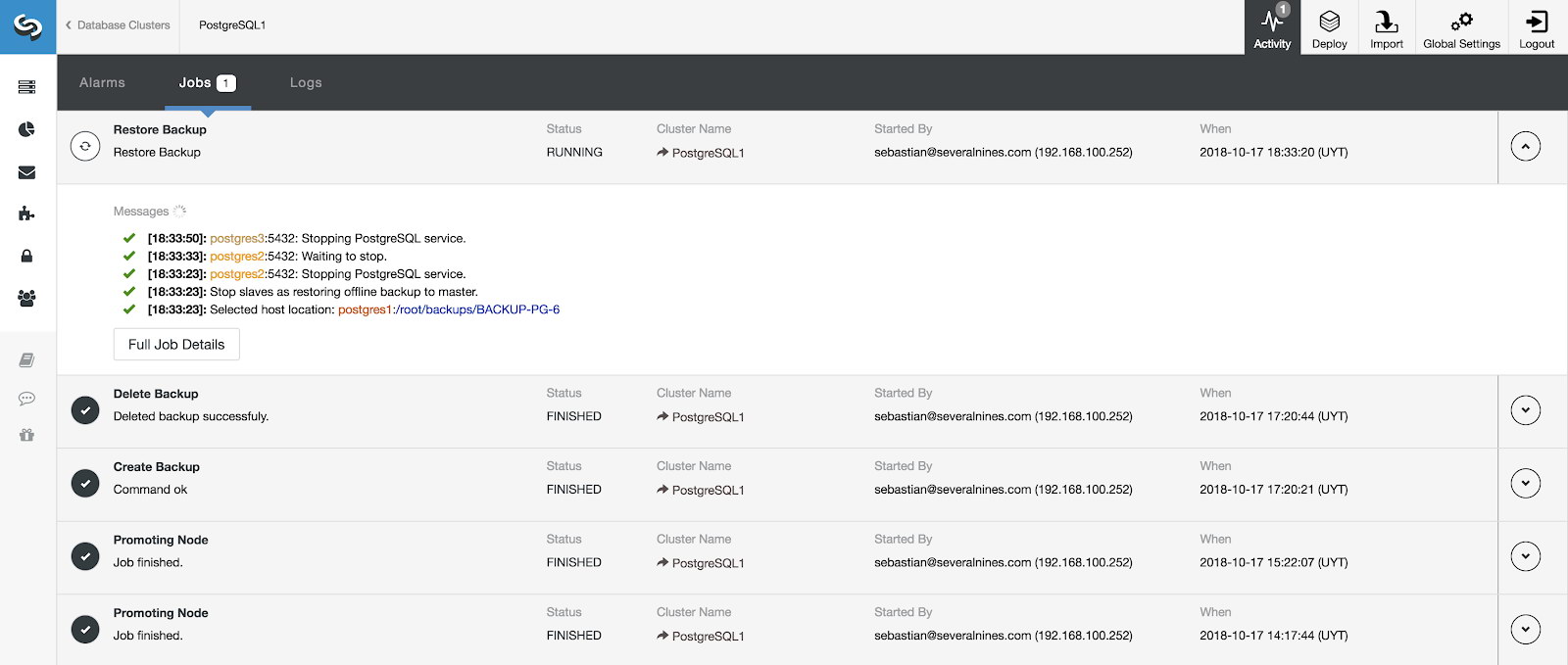
We can monitor the progress of our restore from the Activity section in our ClusterControl.
Conclusion
PITR is a needed feature to meet a tight RPO. We need to set it up correctly to ensure a correct disaster recovery plan. ClusterControl provides an easy to use interface to help you implement PITR for your PostgreSQL databases.



