blog
Point-in-Time PostgreSQL Database Restoration

The ability to perform backup and restore of your data is one of the fundamental requirements of any DBMS. In a previous post, we discussed Postgres backups in general. In this blog post, we’ll look at how to do point-in-time recovery for PostgreSQL.
Point-in-time recovery (PITR) is a pretty useful feature. You need to keep in mind that the backup is a “snapshot” of your dataset at a given point of time. If you take backups on a daily basis, in the worst case scenario, you will have almost 24 hours of data that is not in more than you had in your last backup. So restoring from the last backup means losing a day’s worth of data. In general, it’s not really ok to lose so much data. Therefore you need to think about how you can recover all the changes that happened since you took the last backup. Let’s see how the whole process of backing up data and restoring it after an incident may look like on PostgreSQL 10.1 (which you can deploy using ClusterControl).
Setting up WAL Archiving
PostgreSQL stores all modifications in form of Write-Ahead Logs (WAL). These files can be used for replication, but they can also be used for PITR. First of all, we need to setup WAL archiving. We’ll start with creating a directory in which the WAL files will be stored. This can be in any location: on disk, on NFS mount, anywhere – as long as PostgreSQL can write to it, it’ll do.
mkdir /wal_archive
chown -R postgres.postgres /wal_archiveWe’ll create a simple directory and make sure it’s owned by ‘postgres’ user. Once this is done, we can start editing the PostgreSQL configuration.
archive_mode = on # enables archiving; off, on, or always
# (change requires restart)
archive_command = 'test ! -f /wal_archive/%f && cp %p /wal_archive/%f' # command to use to archive a logfile segment
wal_level = archive # minimal, replica, or logicalThe settings above have to be configured – you want to enable archiving (archive_mode = on), you want also to set wal_lever to archive. Archive_command requires more explanation. PostgreSQL doesn’t care where you will put the files, as long as you’ll tell it how to do it. This command will be used to copy the files to their destination. It can be a simple one-liner, as in the example above, it can be a call to a complex script or binary. What’s important is that this command should not overwrite existing files. It also should return zero exit status only when it managed to copy the file. If the return code will be different than 0, PostgreSQL will attempt to copy that file again. In our case, we verify if the file already exists or not. If not, we will copy it to the destination. ‘%p’ represents full path to the WAL file to be copied while ‘%f’ represents the filename only.
Once we are done with those changes, we need to restart PostgreSQL:
service postgresql restartAt this point, you should see WAL files appearing in your target directory. Please keep in mind that the process is triggered after a WAL file rotation – if you have very low traffic, it may take a while before WAL archiving will be started.
Base Backup
The next step will be to take a base backup that we’ll use as a base for our point-in-time restore. You can take it using pg_basebackup:
pg_basebackup -Umyuser -h127.0.0.1 --progress -D /basebackup/Or you can use ClusterControl for that:
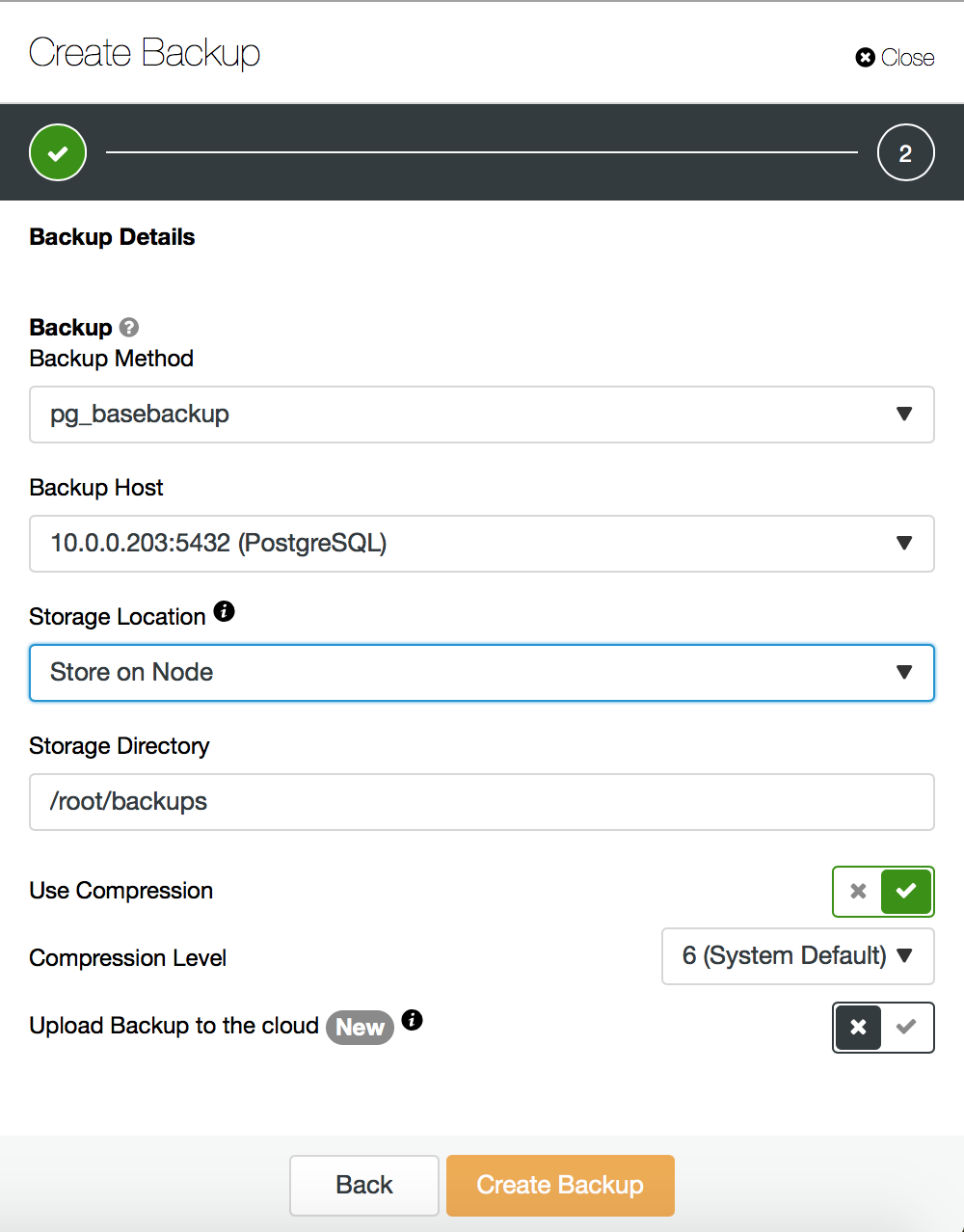
When dealing with it manually, you may need to edit your pg_hba.conf to allow replication connections for the user you’ll be using for pg_basebackup. ClusterControl will take care of it for you.
Restore
Once you have a base backup done and WAL archiving configured, you are good to go. First of all, you need to figure out the point at which you should restore your data. Ideally, you’ll be able to give an exact time. Other options are: a named restore point (pg_create_restore_point()), transaction ID or WAL location LSN. You can try to use the pg_waldump utility to parse WAL files and print them in human-readable format, but it’s actually far from being human-readable so it can still be tricky to pinpoint the exact location.
rmgr: Transaction len (rec/tot): 34/ 34, tx: 801534, lsn: 3/726587F0, prev 3/726587A8, desc: COMMIT 2017-11-30 12:39:05.086674 UTC
rmgr: Standby len (rec/tot): 42/ 42, tx: 801535, lsn: 3/72658818, prev 3/726587F0, desc: LOCK xid 801535 db 12938 rel 16450
rmgr: Storage len (rec/tot): 42/ 42, tx: 801535, lsn: 3/72658848, prev 3/72658818, desc: CREATE base/12938/16456
rmgr: Heap len (rec/tot): 123/ 123, tx: 801535, lsn: 3/72658878, prev 3/72658848, desc: UPDATE off 7 xmax 801535 ; new off 9 xmax 0, blkref #0: rel 1663/12938/1259 blk 0When you know at which point you need to restore to, you can proceed with the recovery. First, you should stop the PostgreSQL server:
service postgresql stopThen you need to remove all of the data directory, restore the base backup and then remove any existing WAL files. PostgreSQL will copy the data from our WAL archive directory.
rm -rf /var/lib/postgresql/10/main/*
cp -r /basebackup/* /var/lib/postgresql/10/main/
rm -rf /var/lib/postgresql/10/main/pg_wal/*Now, it’s time to prepare the recovery.conf file, which will define how the recovery process will look like.
vim /var/lib/postgresql/10/main/recovery.conf
restore_command = 'cp /wal_archive/%f "%p"'
recovery_target_lsn = '3/72658818'In the example above, we defined a restore command (simple cp from our /wal_archive directory into PostgreSQL pg_wal directory). We also should decide where to stop – we decided to use a particular LSN as a stop point, but you can also use:
recovery_target_name
recovery_target_time
recovery_target_xidfor a named restore point, timestamp and transaction ID.
Finally, make sure that all of the files in the PostgreSQL data directory have the correct owner:
chown -R postgres.postgres /var/lib/postgresql/Once this is done, we can start PostgreSQL:
service postgresql startIn the log you should see entries like this:
2017-12-01 10:45:56.362 UTC [8576] LOG: restored log file "000000010000000300000034" from archive
2017-12-01 10:45:56.401 UTC [8576] LOG: restored log file "00000001000000030000001D" from archive
2017-12-01 10:45:56.419 UTC [8576] LOG: redo starts at 3/1D9D5408
2017-12-01 10:45:56.464 UTC [8576] LOG: restored log file "00000001000000030000001E" from archive
2017-12-01 10:45:56.526 UTC [8576] LOG: restored log file "00000001000000030000001F" from archive
2017-12-01 10:45:56.583 UTC [8576] LOG: restored log file "000000010000000300000020" from archive
2017-12-01 10:45:56.639 UTC [8576] LOG: restored log file "000000010000000300000021" from archive
2017-12-01 10:45:56.695 UTC [8576] LOG: restored log file "000000010000000300000022" from archive
2017-12-01 10:45:56.753 UTC [8576] LOG: restored log file "000000010000000300000023" from archive
2017-12-01 10:45:56.812 UTC [8576] LOG: restored log file "000000010000000300000024" from archive
2017-12-01 10:45:56.870 UTC [8576] LOG: restored log file "000000010000000300000025" from archiveOnce done, the server will still be in recovery mode. You can switch it to normal operations by running:
postgres=# create database mydb;
ERROR: cannot execute CREATE DATABASE in a read-only transaction
postgres=# SELECT pg_wal_replay_resume();
pg_wal_replay_resume
----------------------
(1 row)
postgres=# create database mydb;
CREATE DATABASEYou can also define in recovery.conf how PostgreSQL should behave after the recovery using:
recovery_target_actionThere are three options:
- ‘pause’, the default, keeps the server in recovery mode. It is useful if you want to verify that everything is indeed in place before you allow normal traffic to hit the server and modify data.
- ‘promote’ will end the recovery mode as soon as the recovery itself completes.
- ‘shutdown’ will stop the PostgreSQL server after the recovery.
After recovery is complete, recovery.conf file will be renamed to recovery.done. Please keep in mind that this won’t happen with:
recovery_target_action = ‘shutdown’In this case you need to remove or rename the file manually, otherwise the server will keep restarting over and over again.
As you can see, there is good support for performing point in time recovery in PostgreSQL. We hope you that you won’t have to go through this process on your production servers. It’s still good practice to test your organization’s skills in performing point-in-time recovery every now and then, so you are prepared in case of emergency.



