blog
Failover for PostgreSQL Replication 101

Failover might sound like a buzzword for anyone within the IT industry, but what’s behind it? What is a failover? What can I use it for? Is it important to have it? How can I do it?
While those questions may seem pretty basic, it’s essential to answer them to ensure the proper functioning of any database environment. Let’s dive in!
What is Failover?
Failover is the ability of a system to continue functioning even if a failure occurs. It suggests that secondary components assume the system’s functions if the primary components fail.
In the case of PostgreSQL, there are different tools that allow you to implement a database cluster that is resilient to failures. One redundancy mechanism available natively in PostgreSQL is replication. And the novelty in PostgreSQL 10 is the implementation of logical replication.
What is Replication?
Replication is a process of copying and keeping the data updated in one or more database nodes. It uses a concept of a primary node that receives the modifications, and replication nodes where they are replicated.
We Have Several Ways of Categorizing Replication:
- Synchronous Replication: There is no loss of data even if our master node is lost, but the commits in the master must wait for a confirmation from the slave, which can affect the performance.
- Asynchronous Replication: There is a possibility of data loss in case we lose our master node. If the replica for some reason is not updated at the time of the incident, the information that has not been copied may be lost.
- Physical Replication: Disk blocks are copied.
- Logical Replication: Streaming of the data changes.
- Warm Standby Slaves: They do not support connections.
- Hot Standby Slaves: Support read-only connections, useful for reports or queries.
What is Failover Used for?
There are several possible uses of failover. Let’s see some examples.
Migration
If we want to migrate from one datacenter to another by minimizing our downtime, we can use failover.
Suppose that our master is in datacenter A, and we want to migrate our systems to datacenter B.
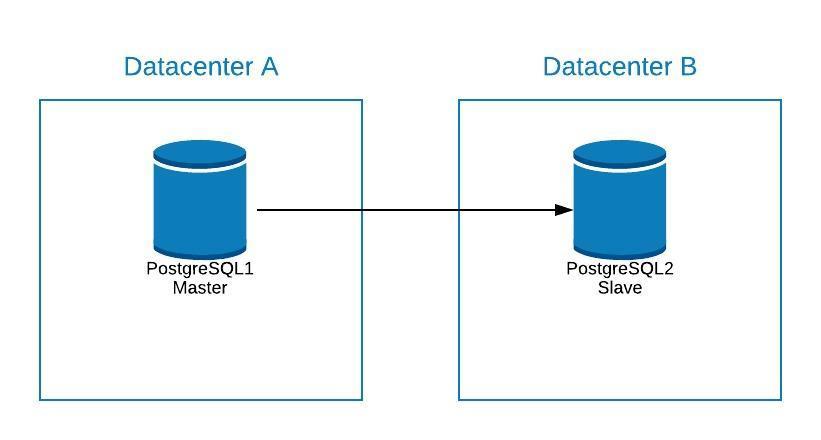
We can create a replica in datacenter B. Once it is synchronized, we must stop our system, promote our replica to new master and failover, before we point our system to the new master in datacenter B.
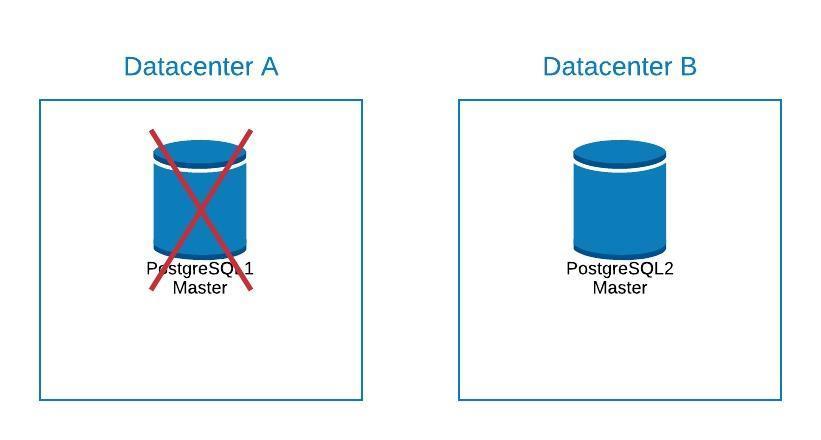
Failover is not just about the database, but also the application(s). How do they know which database to connect to? We certainly do not want to have to modify our application, as this will only extend our downtime.. So, we can configure a load balancer so that when we take down our master, it will automatically point to the next server that is promoted.
Another option is the use of DNS. By promoting the master replica in the new datacenter, we directly modify the IP address of the hostname that points to the master. In this way we avoid having to modify our application, and although it can not be done automatically, it is an alternative if we do not want to implement a load balancer.
Having a single load balancer instance is not great as it can become a single point of failure. Therefore, you can also implement failover for the load balancer, using a service such as keepalived. In this way, if we have a problem with our primary load balancer, keepalived is responsible for migrating the IP to our secondary load balancer, and everything continues to work transparently.
Maintenance
If you need to perform any maintenance on your PostgreSQL primary server, you can promote your replica, perform the task, and rebuild a standby node on your old primary.
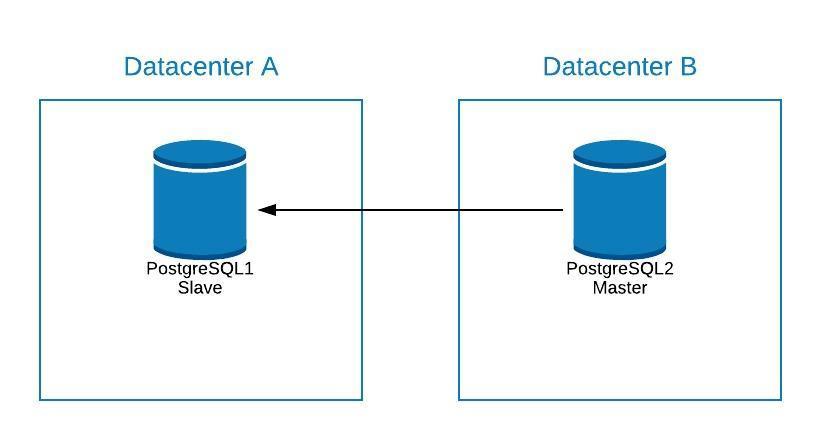
After this, you can re-promote the old primary (now replica), and repeat the rebuild process of the replication node, returning to the initial state.
In this way, we could work on our server, without running the risk of being offline or losing information while performing maintenance.
Upgrade
Since PostgreSQL 10, it is possible to upgrade by using logical replication, as it can be done with other engines.
The steps would be the same as migrating to a new datacenter (See Migration Section), only that your replication node would be in a new PostgreSQL version.
Issues
The most important function of the failover is to minimize your downtime or avoid loss of information when having a problem with your primary database.
If for some reason you lose your primary node, you can failover promoting your standby node and keep your systems running.
To do this, PostgreSQL does not provide any automated solution. You can do it manually, or automate it by means of a script or an external tool.
To promote your standby node:
- Run pg_ctl promote
bash-4.2$ pg_ctl promote -D /var/lib/pgsql/10/data/ waiting for server to promote.... done server promoted - Create a file trigger_file that we must have added in the recovery.conf of our data directory.
bash-4.2$ cat /var/lib/pgsql/10/data/recovery.conf standby_mode = 'on' primary_conninfo = 'application_name=pgsql_node_0 host=postgres1 port=5432 user=replication password=****' recovery_target_timeline = 'latest' trigger_file = '/tmp/failover.trigger' bash-4.2$ touch /tmp/failover.trigger
In order to implement a failover strategy, you need to plan it and thoroughly test it through different failure scenarios. As failures can happen in different ways, and the solution should ideally work for most of the common scenarios, it will be a time-consuming task.
If you are looking for a way to automate this, you can take a look at what ClusterControl has to offer.
ClusterControl for PostgreSQL Failover
ClusterControl has a number of features related to PostgreSQL replication and automated failover.
Add Replication Node
If you want to add a replication node, either as a contingency or to migrate your systems, you can go to Cluster Actions and select “Add Replication Slave”.
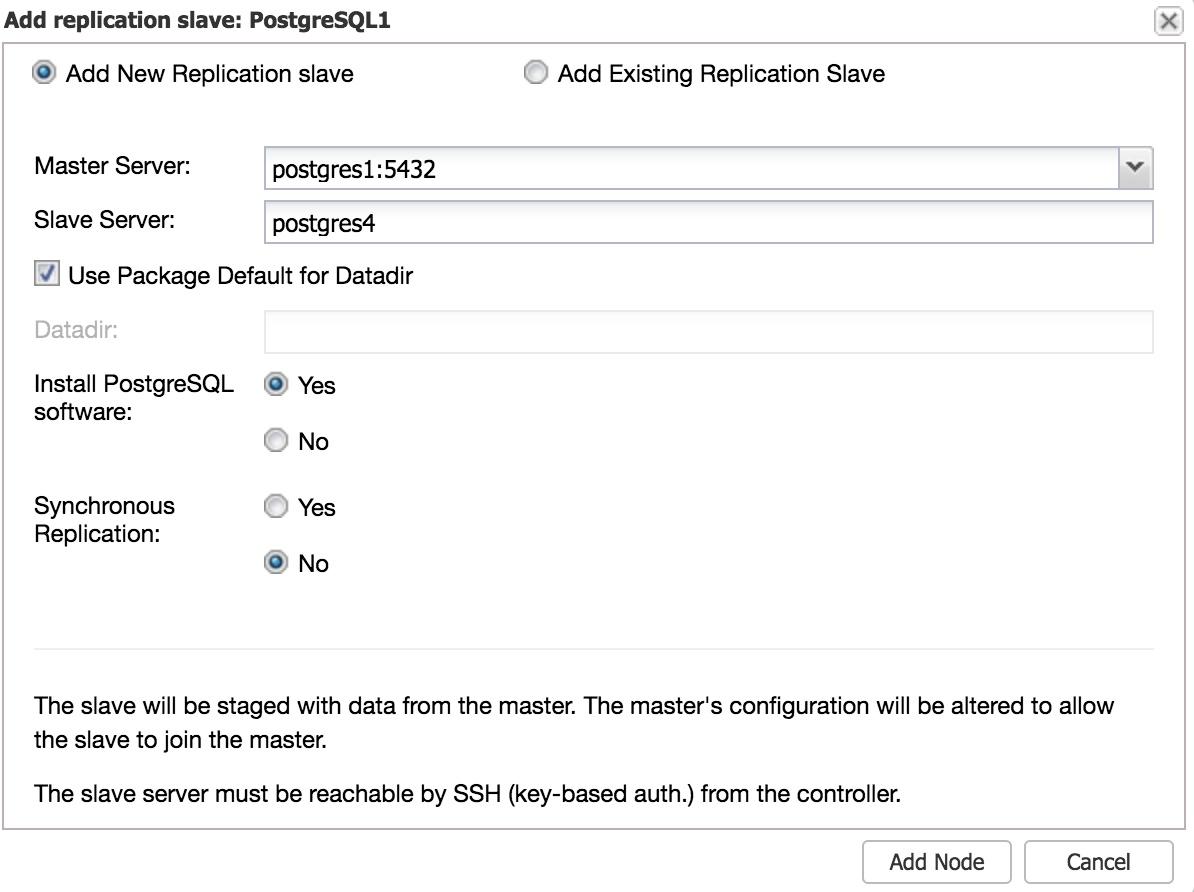
You will need to enter some basic data, such as IP address or hostname, data directory (optional), and synchronous or asynchronous replication. That’s it, you will have your replica up and running after a few seconds.
In the case of using another datacenter, we recommend creating an asynchronous replication, otherwise, the latency can affect performance considerably.
Manual failover
With ClusterControl, failover can be done manually or automatically. To perform a manual failover, go to ClusterControl -> Select Cluster -> Nodes, and in the Node Actions of one of your replication nodes, select “Promote Slave”. In this way, after a few seconds, your replica becomes primary, and what was your primary previously, is turned into a replica.
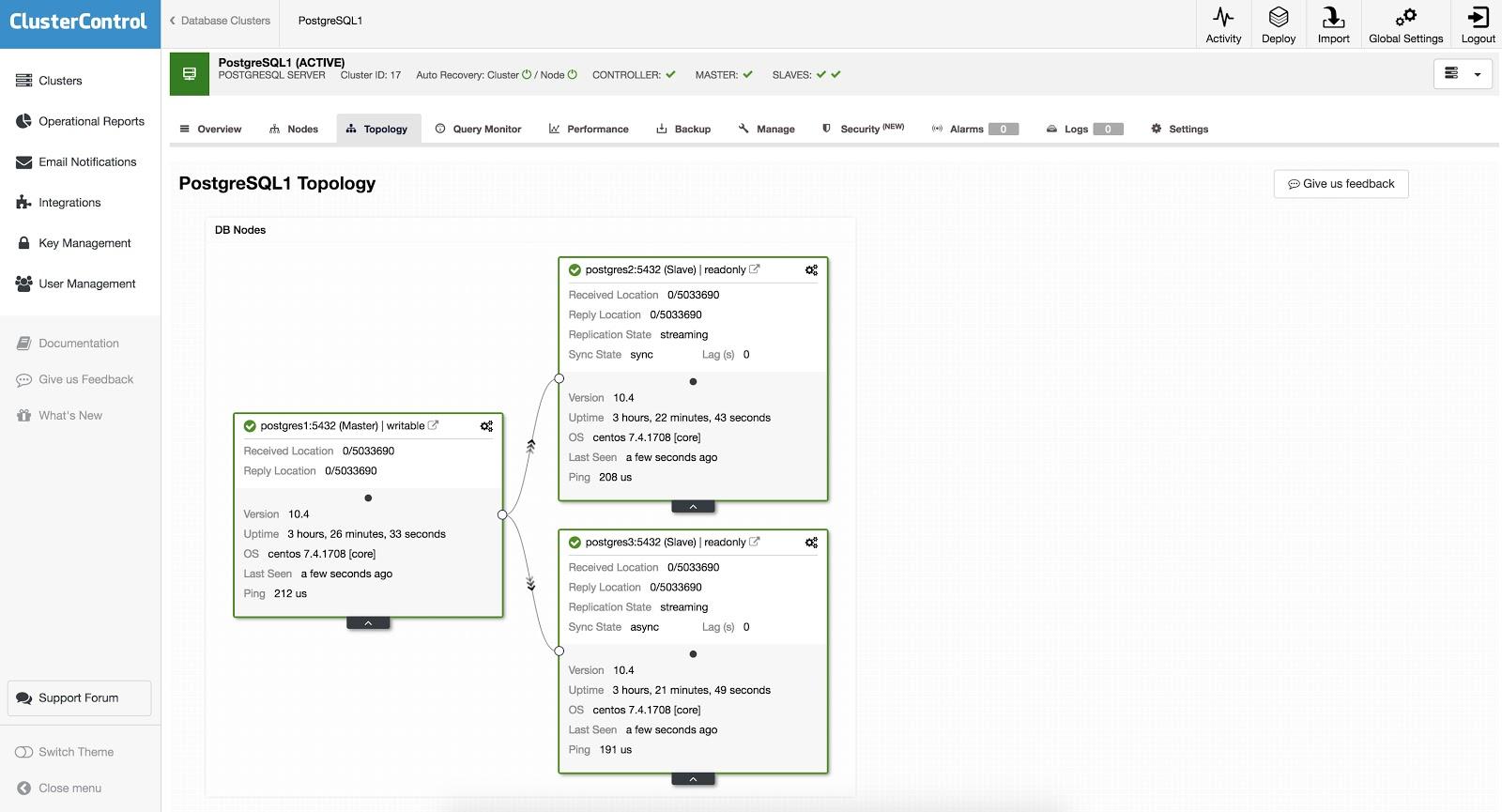
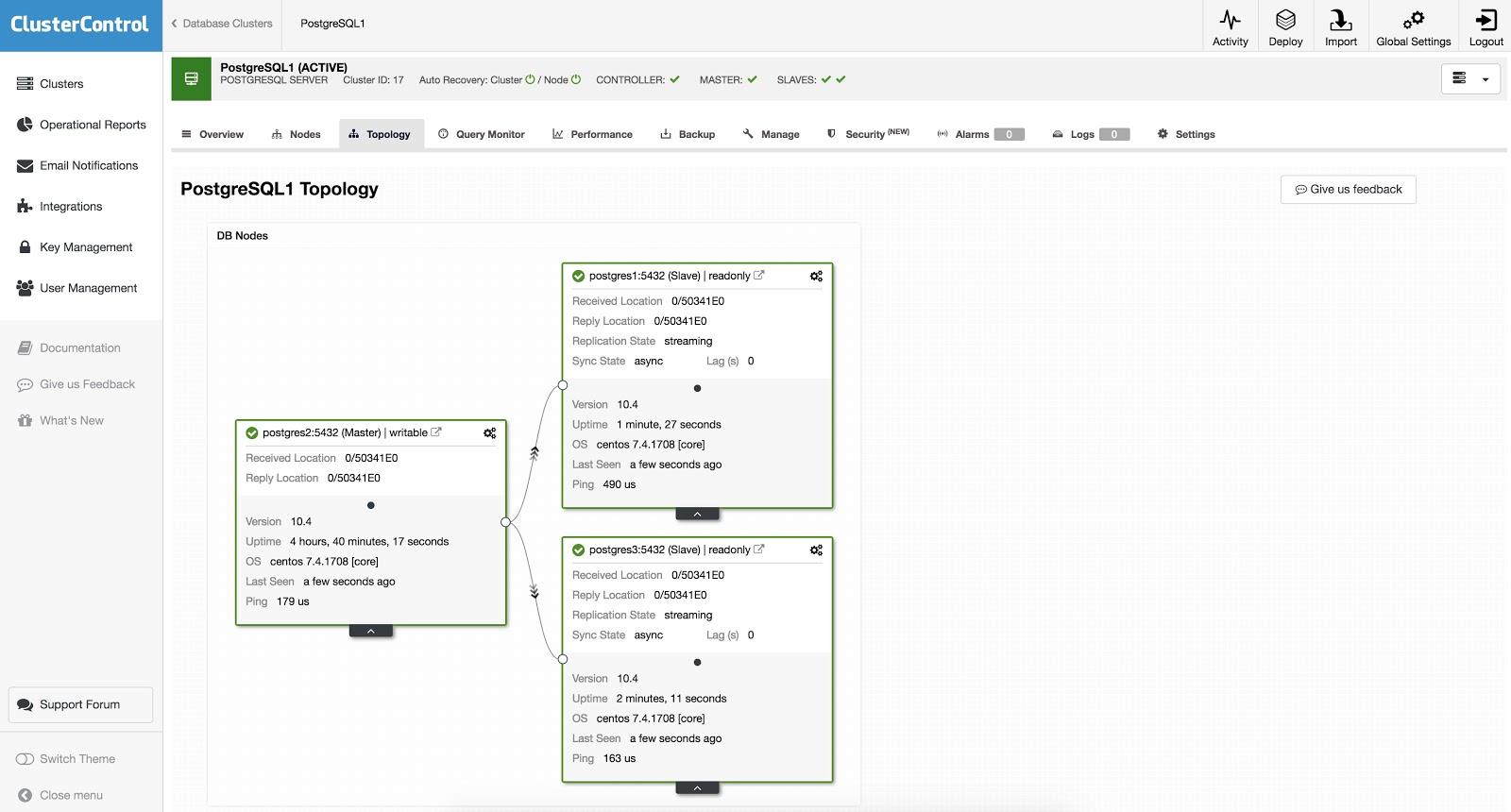
The above is useful for the tasks of migration, maintenance and upgrades that we saw previously.
Automatic failover
In the case of automatic failover, ClusterControl detects primary failures and promotes a replica with the most current data as the new primary. It also works on the rest of the replication nodes to have them replicate from the new primary.
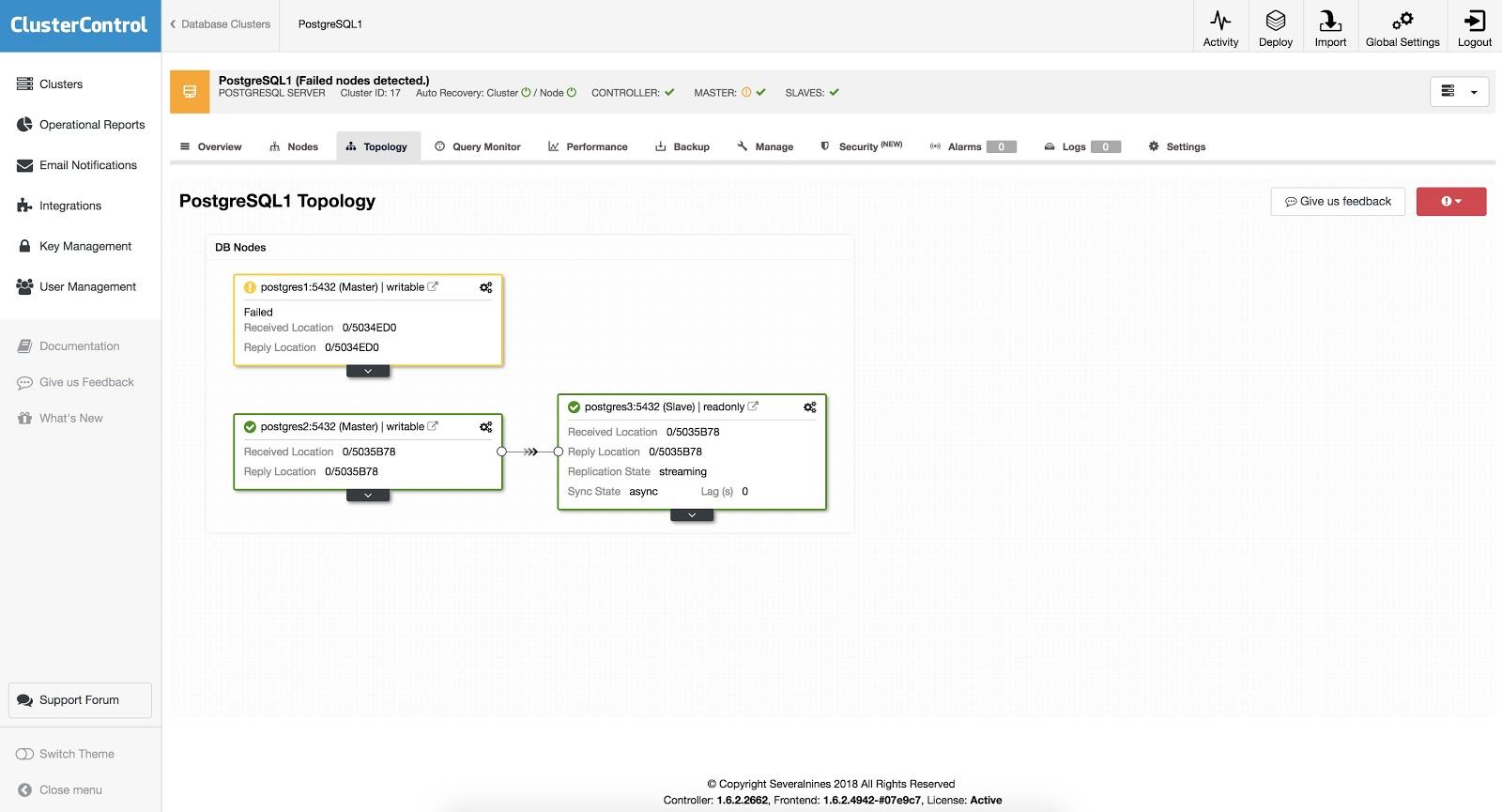
Having the “Autorecovery” option ON, our ClusterControl will perform an automatic failover as well as notify us of the problem. In this way, our systems can recover in seconds, and without our intervention.
ClusterControl offers you the possibility to configure a whitelist/blacklist to define how you want your servers to be taken (or not to be taken) into account when deciding on a primary candidate.
From the ones available according to the above configuration, ClusterControl will pick the most advanced one, using for this purpose the pg_current_wal_lsn.
ClusterControl also performs several checks over the failover process to avoid some common mistakes. One example is that if you recover your old failed primary node, by default, it will NOT be reintroduced automatically to the cluster, neither as a primary nor as a replica. You need to do it manually. This would avoid data loss or inconsistency if your replica (that was promoted) was delayed at the time of the failure. You should also analyze the issue in detail, but you could lose diagnostic information when adding it to your cluster. If you don’t care about this, you can change this default behavior and configure ClusterControl to re-add the failed node automatically.
Also, if failover fails, no further attempts are made, and manual intervention is required to analyze the problem and perform the corresponding actions. This is to avoid the situation where ClusterControl, as the high availability manager, tries to promote the next replica and the next one.
Load Balancers
As we mentioned earlier, the load balancer is an important tool to consider for our failover, especially if we want to use automatic failover in our database topology.
In order for the failover to be transparent for both the user and the application, we need a component in-between, since it is not enough to promote a master to a slave. For this, we can use HAProxy + Keepalived.
What is HAProxy?
HAProxy is a load balancer that distributes traffic from one origin to one or more destinations and can define specific rules and/or protocols for this task. If any of the destinations stops responding, it is marked as offline, and the traffic is sent to the rest of the available destinations. This prevents traffic from being sent to an inaccessible destination, and prevents the loss of this traffic by directing it to a valid destination.
What is Keepalived?
Keepalived allows you to configure a virtual IP within an active/passive group of servers. This virtual IP is assigned to an active “Primary” server. If this server fails, the IP is automatically migrated to the “Secondary” server that was found to be passive, allowing it to continue working with the same IP in a transparent way for our systems.
To implement this solution with ClusterControl, we started as if we were going to add a slave. Go to Cluster Actions and select Add Load Balancer (see ClusterControl Add Slave 1 image).
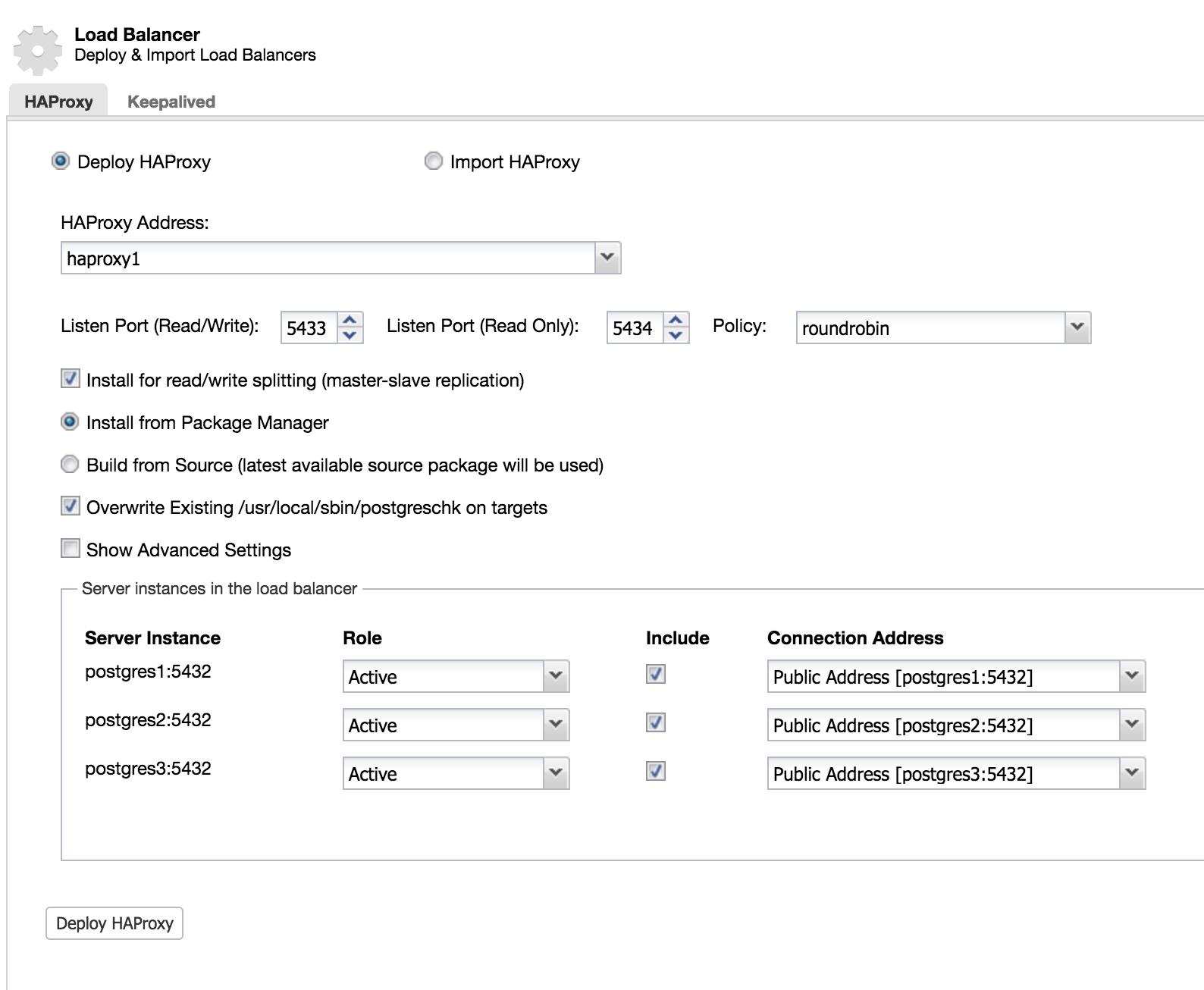
We add the information of our new load balancer and how we want it to behave (Policy).
In the case of wanting to implement failover for our load balancer, we must configure at least two instances.
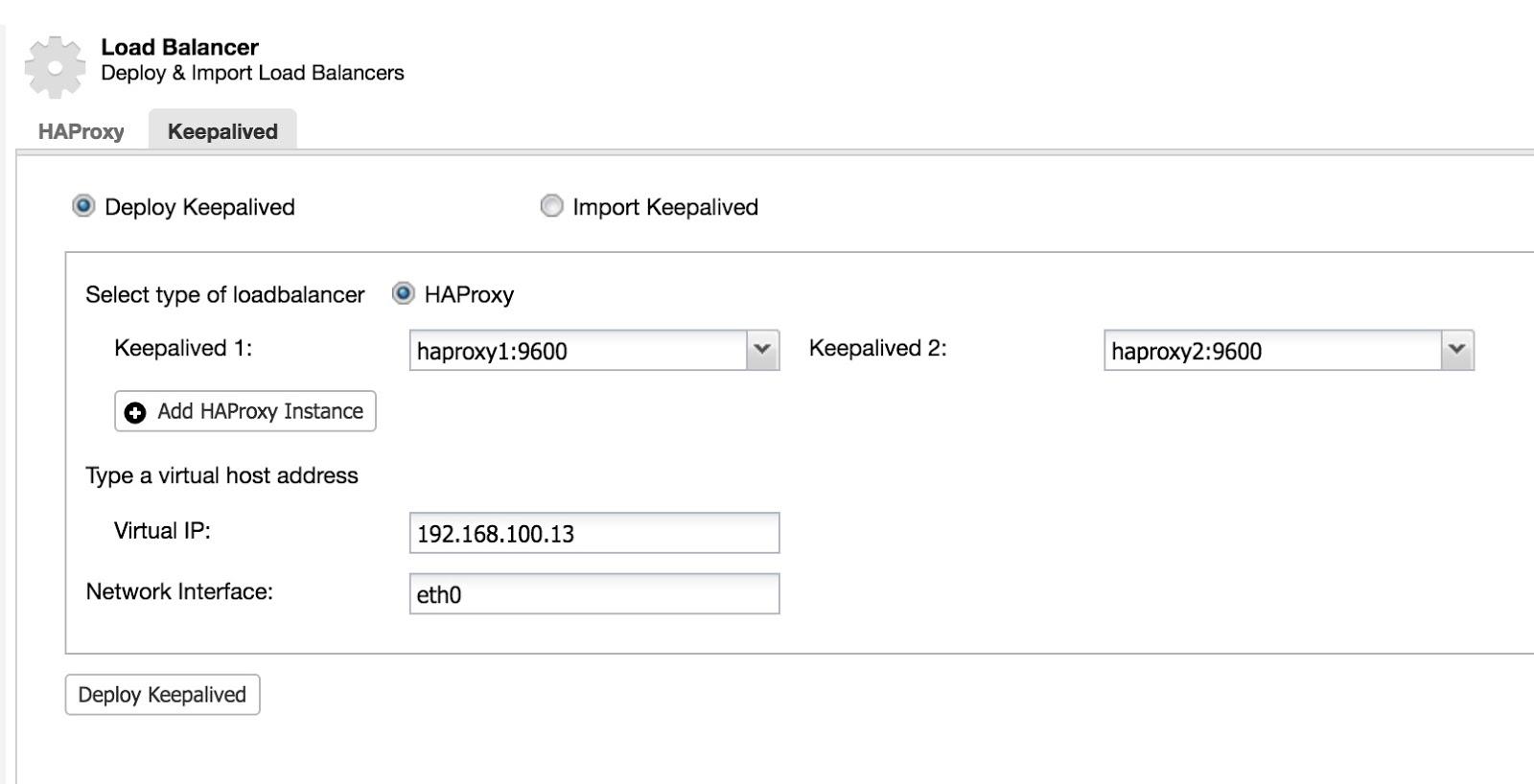
Then we can configure Keepalived (Select Cluster -> Manage -> Load Balancer -> Keepalived).
After this, we have the following topology:
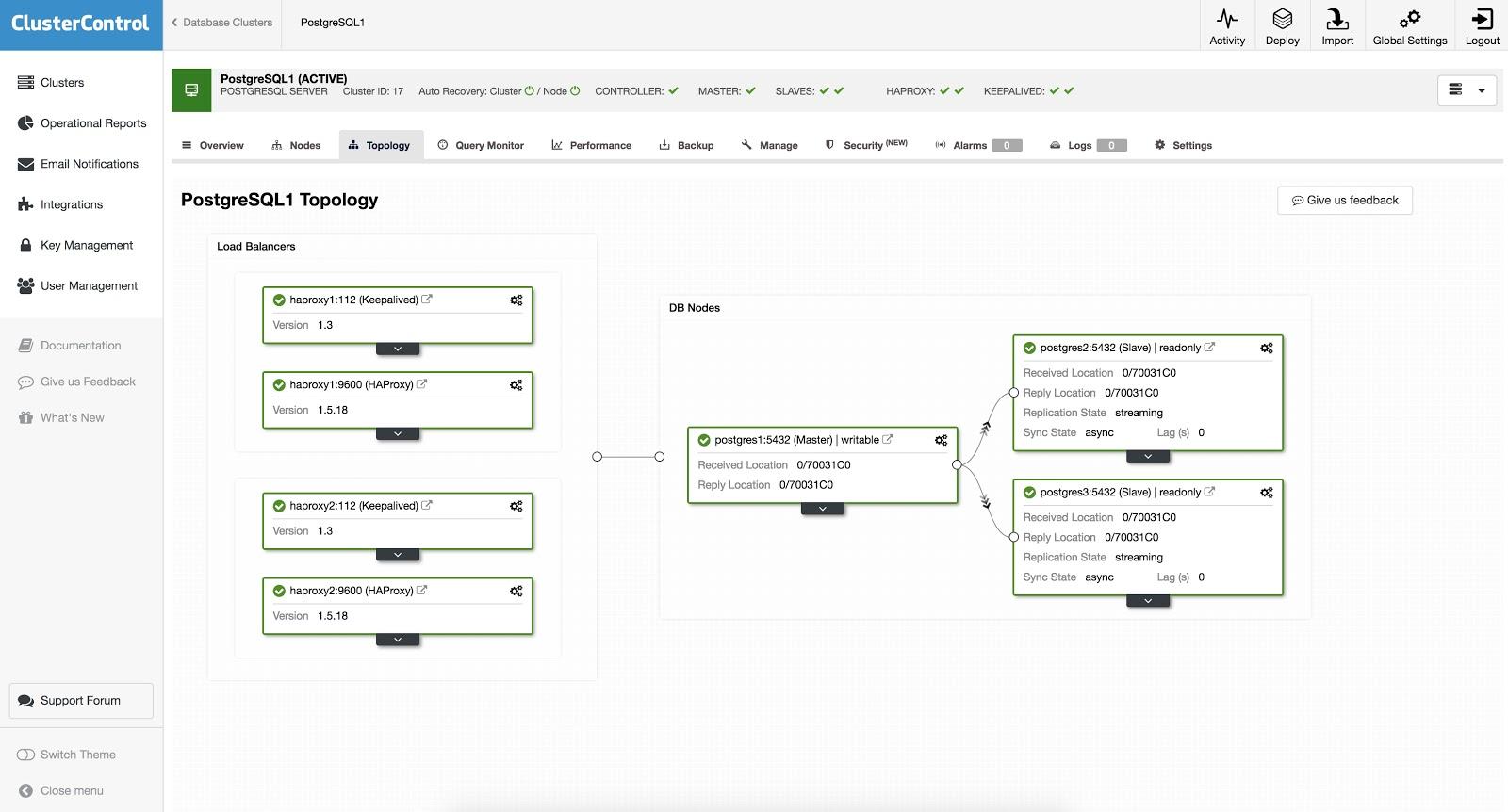
HAProxy is configured with two different ports, one read-write and one read-only.
In the read-write port, you have your primary node as online and the rest of the nodes as offline. In the read-only port, you have both the primary and the replicas online. In this way, you can balance the reading traffic between your database nodes. When writing, the read-write port will be used, which will point only to the primary node.
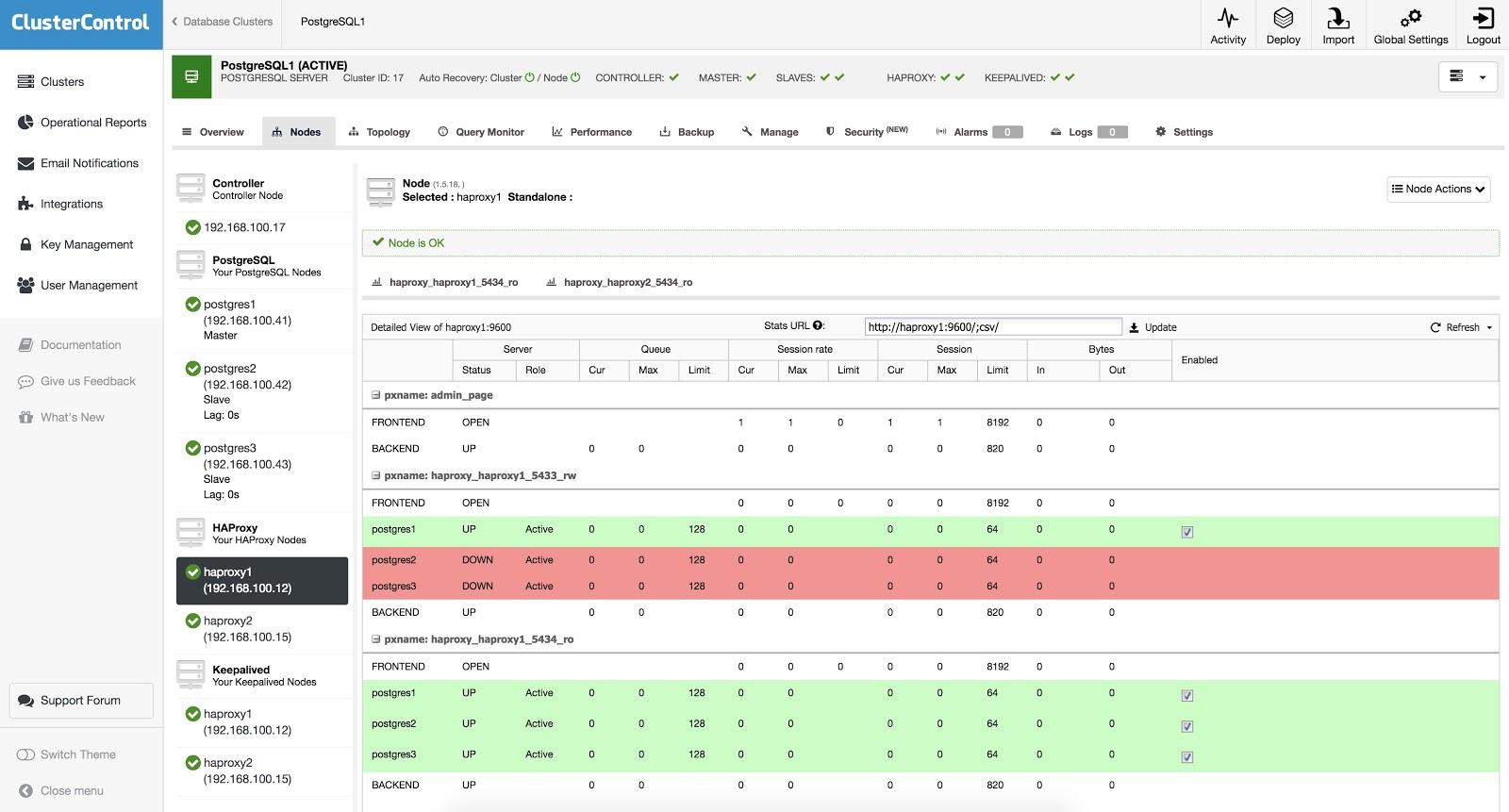
When HAProxy detects that one of the nodes, either primary or replica, is not accessible, it is marked as offline and HAProxy will not send any traffic to it. This check is done by health check scripts that are configured by ClusterControl at the time of deployment. These checks monitor if the instances are up, if they are undergoing recovery, or are read-only.
When ClusterControl promotes a replica, HAProxy marks the old primary as offline (for both read-only and read-write ports) and the promoted node as online (in the read-write port). In this way, your systems continue to operate normally.
If the active HAProxy (which has the Virtual IP address to which your systems connect) fails, Keepalived migrates this Virtual IP address to the passive HAProxy node automatically. This means that your systems are then able to continue to function normally.
Wrapping up
As you can see, failover is a fundamental part of any production database that could be especially useful for everyday maintenance tasks or migrations. It is here for you to minimize downtime and keep performance rates up, and together with ClusterControl, you can bring your failover setup to the next level.
To learn more about failover use cases, tips, and tricks – check out our blog, or visit the ClusterControl failover feature page. Failover is a broad topic that we constantly write about, so make sure you follow our Linkedin & Twitter to keep up with new content on the matter.



