blog
Dealing with Unreliable Networks When Crafting an HA Solution for MySQL or MariaDB

Long gone are the days when a database was deployed as a single node or instance – a powerful, standalone server which was tasked to handle all the requests to the database. Vertical scaling was the way to go – replace the server with another, even more powerful one. During these times, one didn’t really have to be bothered by network performance. As long as the requests were coming in, all was good.
But nowadays, databases are built as clusters with nodes interconnected over a network. It is not always a fast, local network. With businesses reaching global scale, database infrastructure has also to span across the globe, to stay close to customers and to reduce latency. It comes with additional challenges that we have to face when designing a highly available database environment. In this blog post, we will look into the network issues that you may face and provide some suggestions on how to deal with them.
Two Main Options for MySQL or MariaDB HA
We covered this particular topic quite extensively in one of the whitepapers, but let’s look at the two main ways of building high availability for MySQL and MariaDB.
Galera Cluster
Galera Cluster is shared-nothing, virtually synchronous cluster technology for MySQL. It allows to build multi-writer setups that can span across the globe. Galera thrives in low-latency environments but it can also be configured to work with long WAN connections. Galera has a built-in quorum mechanism which ensures that data will not be compromised in case of the network partitioning of some of the nodes.
MySQL Replication
MySQL Replication can be either asynchronous or semi-synchronous. Both are designed to build large scale replication clusters. Like in any other master-slave or primary-secondary replication setup, there can be only one writer, the master. Other nodes, slaves, are used for failover purposes as they contain the copy of the data set from the maser. Slaves can also be used for reading the data and offloading some of the workload from the master.
Both solutions have their own limits and features, both suffer from different problems. Both can be affected by unstable network connections. Let’s take a look at those limitations and how we can design the environment to minimize the impact of an unstable network infrastructure.
Galera Cluster – Network Problems
First, let’s take a look at Galera Cluster. As we discussed, it works best in a low-latency environment. One of the main latency-related problems in Galera is the way how Galera handles the writes. We will not go into all the details in this blog, but further reading in our Galera Cluster for MySQL tutorial. The bottom line is that, due to the certification process for writes, where all nodes in the cluster have to agree on whether the write can be applied or not, your write performance for single row is strictly limited by the network roundtrip time between the writer node and the most far away node. As long as the latency is acceptable and as long as you do not have too many hot spots in your data, WAN setups may work just fine. The problem starts when the network latency spikes from time to time. Writes will then take 3 or 4 times longer than usual and, as a result, databases may start to be overloaded with long-running writes.
One of great features of Galera Cluster is its ability to detect the cluster state and react upon network partitioning. If a node of the cluster cannot be reached, it will be evicted from the cluster and it will not be able to perform any writes. This is crucial in maintaining the integrity of the data during the time when the cluster is split – only the majority of the cluster will accept writes. Minority will complain. To handle this, Galera introduces a vast array of checks and configurable timeouts to avoid false alerts on very transient network issues. Unfortunately, if the network is unreliable, Galera Cluster will not be able to work correctly – nodes will start to leave the cluster, join it later. It will be especially problematic when we have Galera Cluster spanning across WAN – separated pieces of the cluster may disappear randomly if the interconnecting network will not work properly.
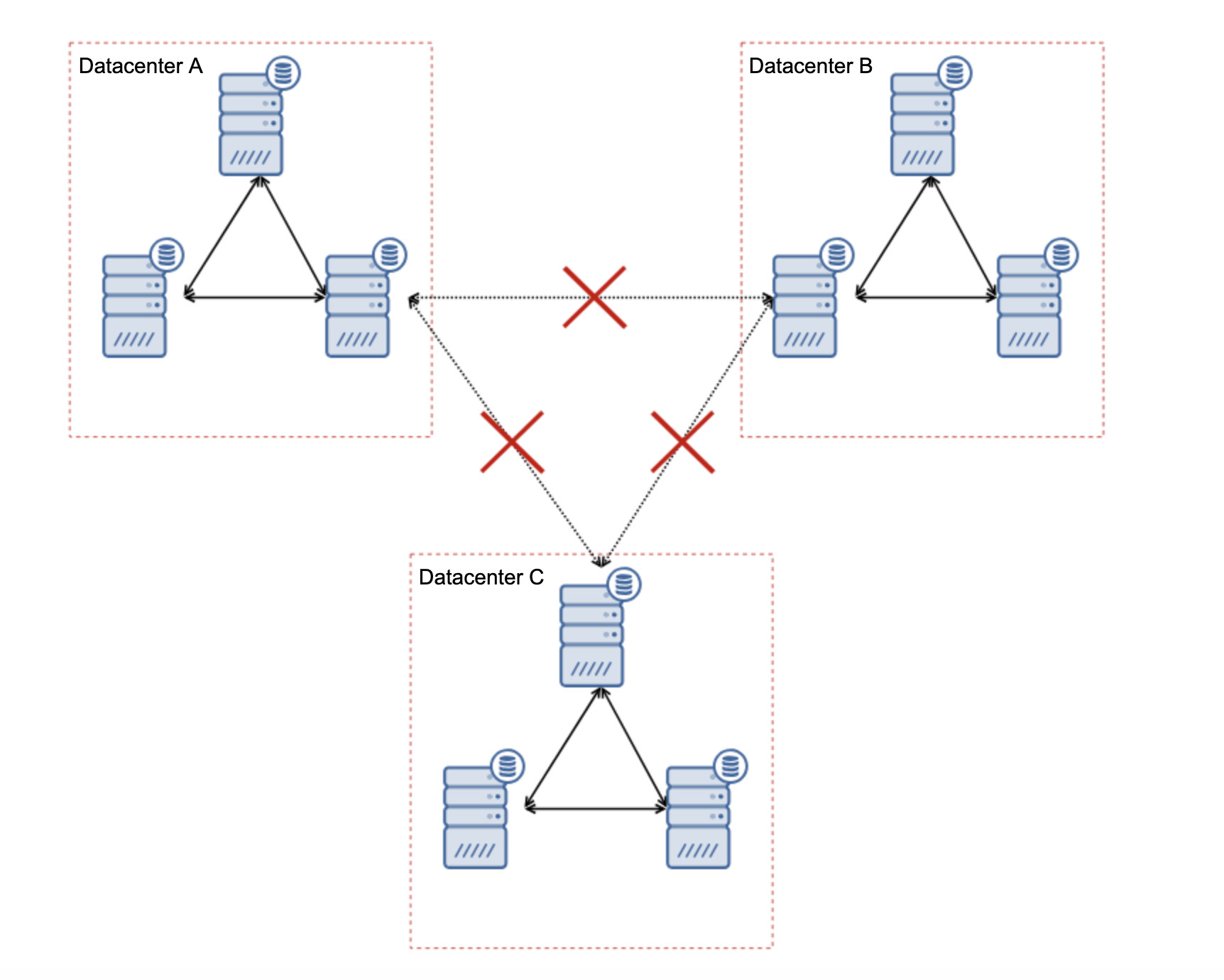
How to Design Galera Cluster for an Unstable Network?
First things first, if you have network problems within the single datacenter, there is not much you can do unless you will be able to solve those issues somehow. Unreliable local network is a no go for Galera Cluster, you have to reconsider using some other solution (even though, to be honest, unreliable network will always be a problematic). On the other hand, if the problems are related to WAN connections only (and this is one of the most typical cases), it may be possible to replace WAN Galera links with regular asynchronous replication (if the Galera WAN tuning did not help).
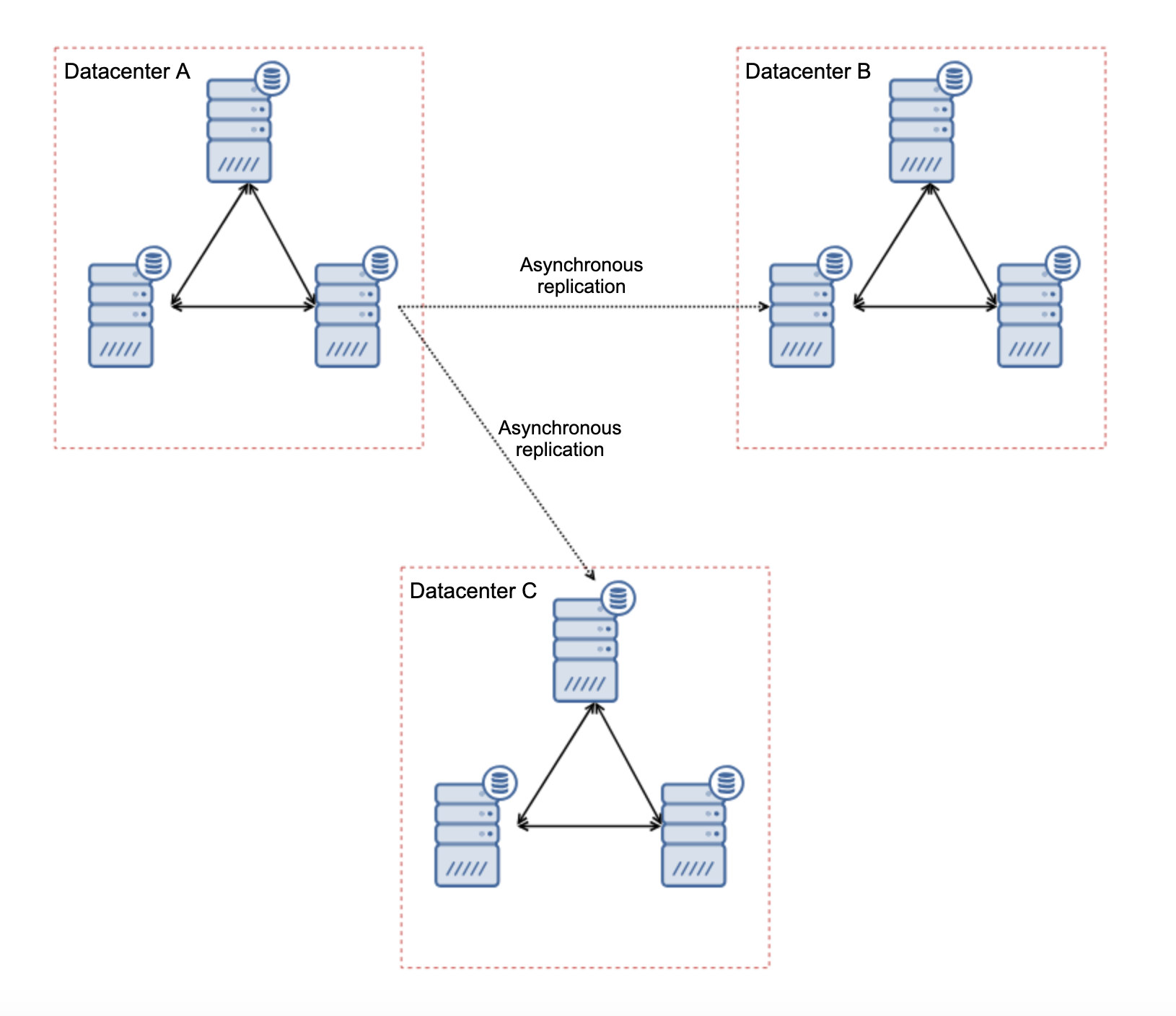
There are several inherent limitations in this setup – the main issue is that the writes used to happen locally. Now, all the writes will have to head to the “master” datacenter (DC A in our case). This is not as bad as it sounds. Please keep in mind that in an all-Galera environment, writes will be slowed down by the latency between nodes located in different datacenters. Even local writes will be affected. It will be more or less the same slowdown as with asynchronous setup in which you would send the writes across WAN to the “master” datacenter.
Using asynchronous replication comes with all of the problems typical for the asynchronous replication. Replication lag may become a problem – not that Galera would be more performant, it’s just that Galera would slow down the traffic via flow control while replication does not have any mechanism to throttle the traffic on the master.
Another problem is the failover: if the “master” Galera node (the one which acts as the master to the slaves in other datacenters) would fail, some mechanism has to be created to repoint slaves to another, working master node. It might be some sort of a script, it is also possible to try something with VIP where the “slave” Galera cluster slaves off Virtual IP which is always assigned to the alive Galera node in the “master” cluster.
The main advantage of such setup is that we do remove the WAN Galera link which means that our “master” cluster will not be slowed down by the fact that some of the nodes are separated geographically. As we mentioned, we lose the ability to write in all of the data-centers but latency-wise writing across the WAN is the same as writing locally to the Galera cluster which spans across WAN. As a result the overall latency should improve. Asynchronous replication is also less vulnerable to the unstable networks. Worst case scenario, the replication link will break and it will be recreated when the networks converge.
How to Design MySQL Replication for an Unstable Network?
In the previous section, we covered Galera cluster and one solution was to use asynchronous replication. How does it look like in a plain asynchronous replication setup? Let’s look at how an unstable network can cause the biggest disruptions in the replication setup.
First of all, latency – one of the main pain points for Galera Cluster. In case of replication, it is almost a non-issue. Unless you use semi-synchronous replication that is – in such case, increased latency will slow down writes. In asynchronous replication, latency has no impact on the write performance. It may, though, have some impact on the replication lag. It is not anything as significant as it was for Galera but you may expect more lag spikes and overall less stable replication performance if the network between nodes suffers from high latency. This is mostly due to the fact that the master may as well serve several writes before data transfer to the slave can be initiated on high latency network.
The network instability may definitely impact replication links but it is, again, not that critical. MySQL slaves will attempt to reconnect to their masters and replication will commence.
The main issue with MySQL replication is actually something that Galera Cluster solves internally – network partitioning. We are talking about the network partitioning as the condition in which segments of the network are separated from each other. MySQL replication utilizes one single writer node – master. No matter how you design your environment, you have to send your writes to the master. If the master is not available (for whatever reasons), application cannot do its job unless it runs in some sort of read-only mode. Therefore there is a need to pick the new master as soon as possible. This is where the issues show up.
First, how to tell which host is a master and which one is not. One of the usual ways is to use the “read_only” variable to distinguish slaves from the master. If node has read_only enabled (set read_only=1), it is a slave (as slaves should not handle any direct writes). If the node has read_only disabled (set read_only=0), it is a master. To make things safer, a common approach is to set read_only=1 in MySQL configuration – in case of a restart, it is safer if the node shows up as a slave. Such “language” can be understood by proxies like ProxySQL or MaxScale.
Let’s take a look at an example.
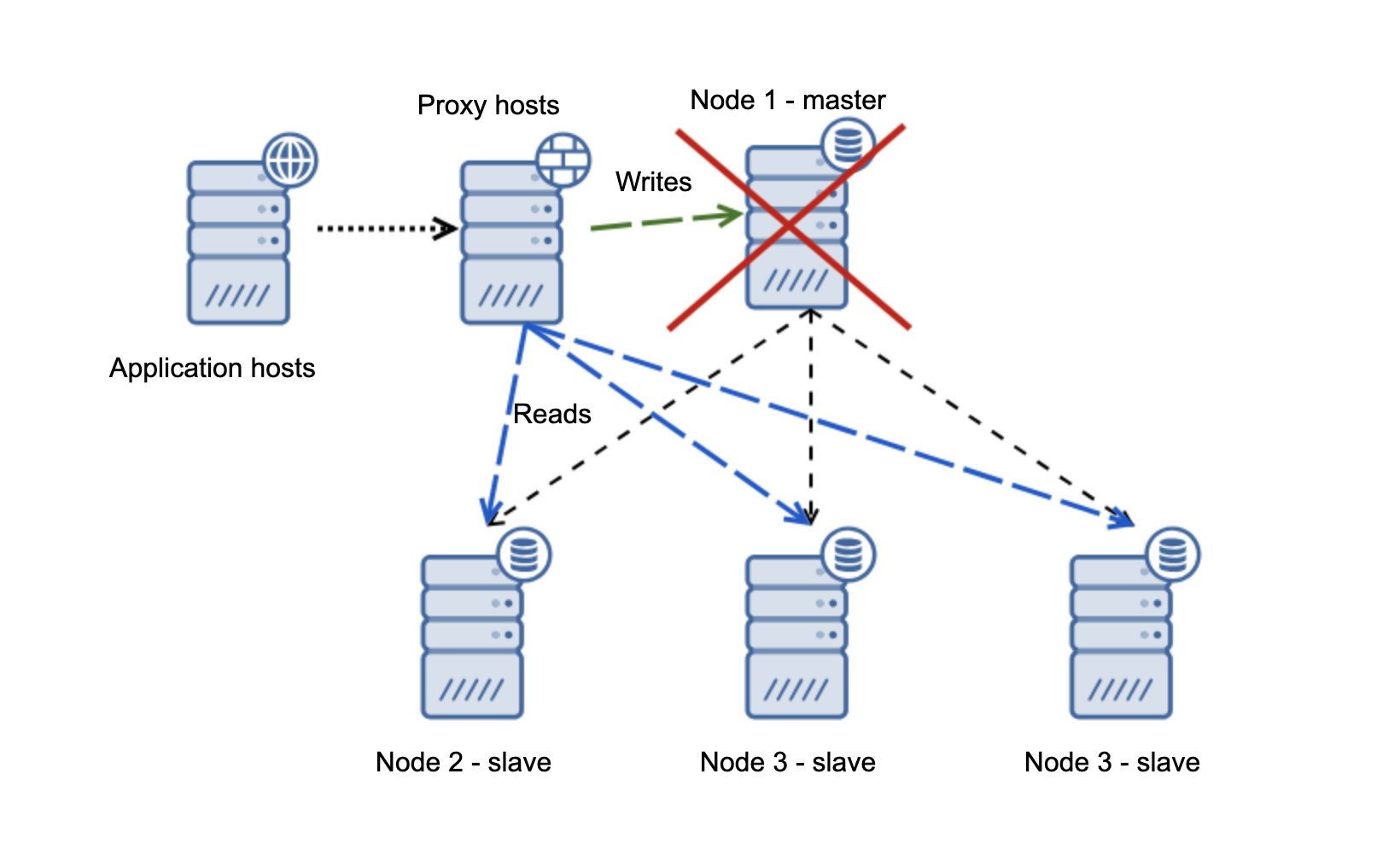
We have application hosts which connect to the proxy layer. Proxies perform the read/write split sending SELECTs to slaves and writes to master. If master is down, failover is performed, new master is promoted, proxy layer detects that and start sending writes to another node.
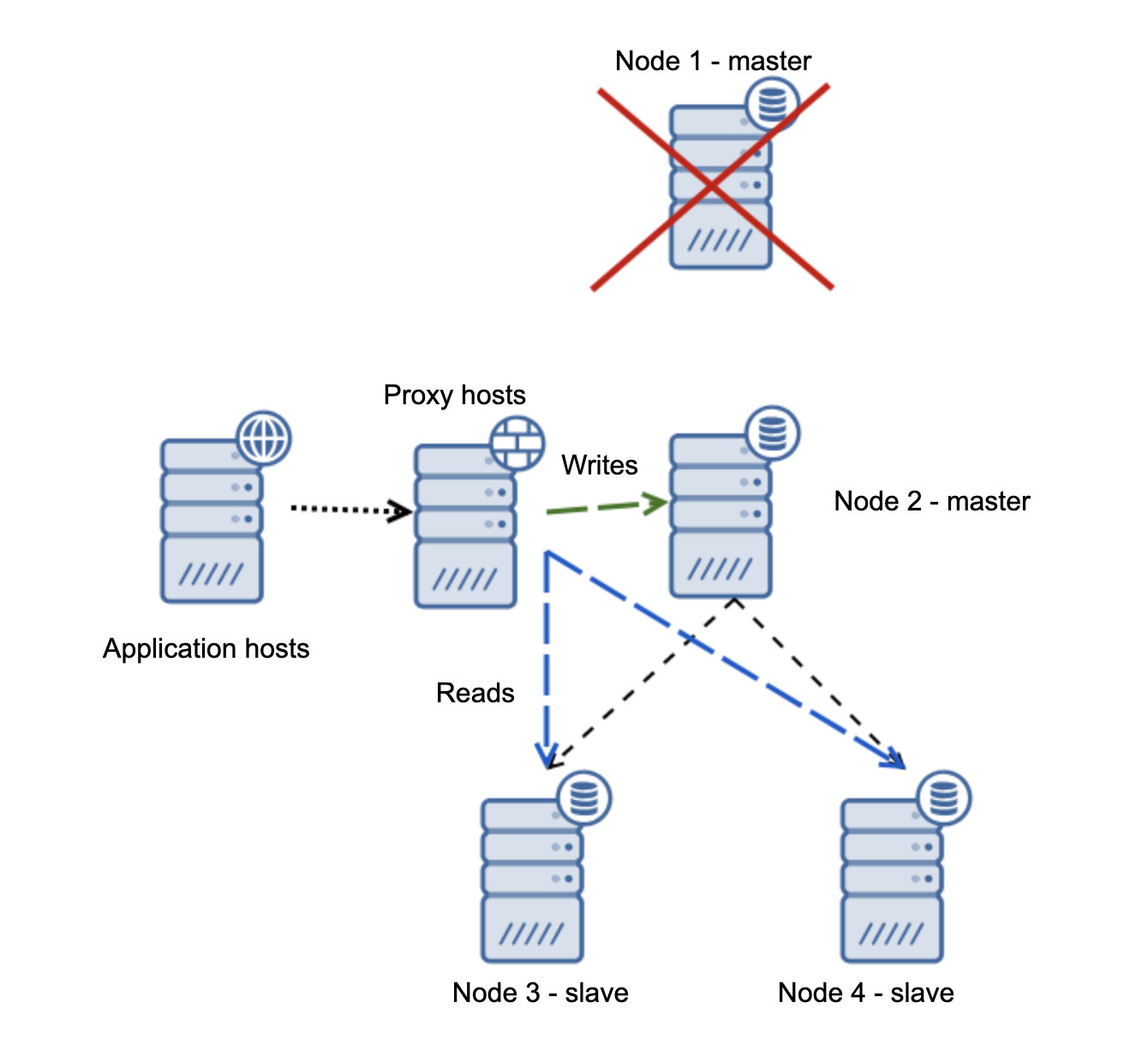
If node1 restarts, it will come up with read_only=1 and it will be detected as a slave. It is not ideal as it is not replicating but it is acceptable. Ideally, the old master should not show up at all until it is rebuilt and slaved off the new master.
Way more problematic situation is if we have to deal with network partitioning. Let’s consider the same setup: application tier, proxy tier and databases.
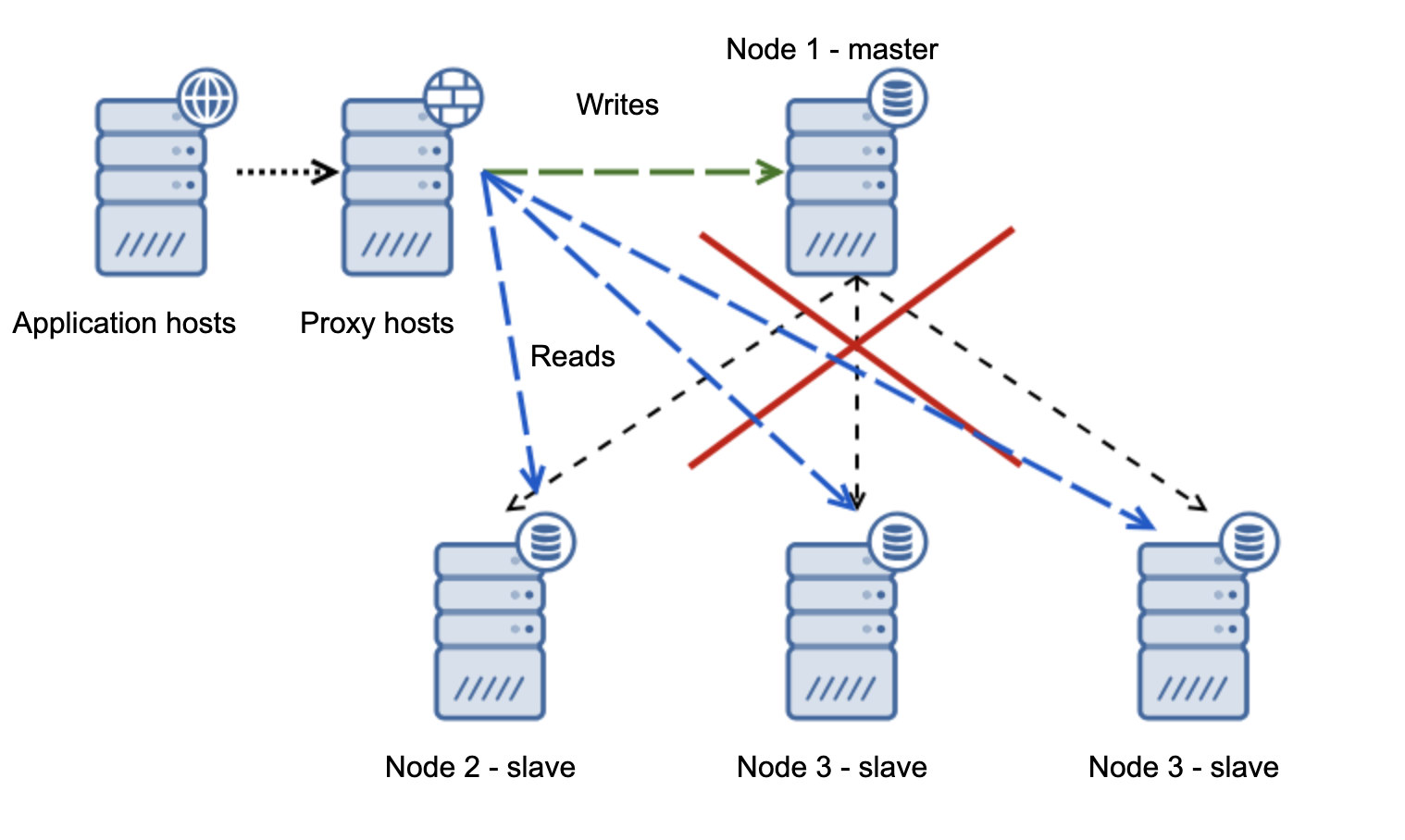
When the network makes the master not reachable, the application is not usable as no writes make it to their destination. New master is promoted, writes are redirected to it. What will happen then if the network issues cease and the old master becomes reachable? It has not been stopped, therefore it is still using read_only=0:
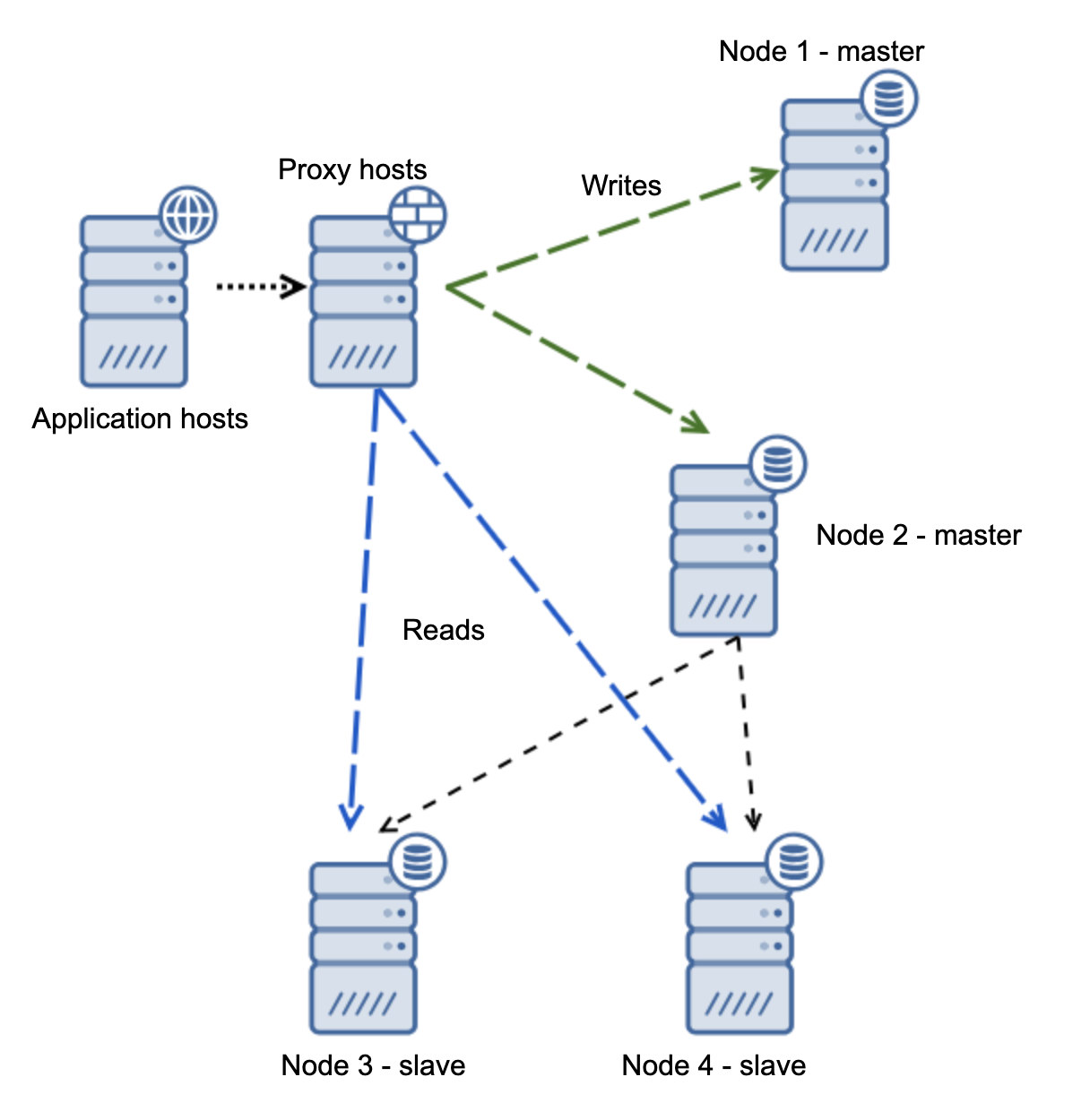
You’ve now ended up in a split brain, when writes were directed to two nodes. This situation is pretty bad as to merge diverged datasets may take a while and it is quite a complex process.
What can be done to avoid this problem? There is no silver bullet but some actions can be taken to minimize the probability of a split brain to happen.
First of all, you can be smarter in detecting the state of the master. How do the slaves see it? Can they replicate from it? Maybe some of the slaves still can connect to the master, meaning that the master is up and running or, at least, making it possible to stop it should that be necessary. What about the proxy layer? Do all of the proxy nodes see the master as unavailable? If some can still connect, than you can try to utilize those nodes to ssh into the master and stop it before the failover?
The failover management software can also be smarter in detecting the state of the network. Maybe it utilizes RAFT or some other clustering protocol to build a quorum-aware cluster. If a failover management software can detect the split brain, it can also take some actions based on this like, for example, setting all nodes in the partitioned segment to read_only ensuring that the old master will not show up as writable when the networks converge.
You can also include tools like Consul or Etcd to store the state of the cluster. The proxy layer can be configured to use data from Consul, not the state of the read_only variable. It will be then up to the failover management software to make necessary changes in Consul so that all proxies will send the traffic to a correct, new master.
Some of those hints can even be combined together to make the failure detection even more reliable. All in all, it is possible to minimize the chances that the replication cluster will suffer from unreliable networks.
As you can see, no matter if we are talking about Galera or MySQL Replication, unstable networks may become a serious problem. On the other hand, if you design the environment correctly, you can still make it work. We hope this blog post will help you to create environments which will work stable even if the networks are not.



