blog
Multiple Data Center Setups Using Galera Cluster for MySQL or MariaDB

Building High Availability, one Step at a Time
When it comes to database infrastructure, we all want it. We all strive to build a highly available setup. Redundancy is the key. We start to implement redundancy at the lowest level and continue up the stack. It starts with hardware – redundant power supplies, redundant cooling, hot-swap disks. Network layer – multiple NIC’s bonded together and connected to different switches which are using redundant routers. For storage we use disks set in RAID, which gives better performance but also redundancy. Then, on the software level, we use clustering technologies: multiple database nodes working together to implement redundancy: MySQL Cluster, Galera Cluster.
All of this is no good if you have everything in a single datacenter: when a datacenter goes down, or part of the services (but important ones) go offline, or even if you lose connectivity to the datacenter, your service will go down – no matter the amount of redundancy in the lower levels. And yes, those things happens.
- S3 service disruption wreaked havoc in US-East-1 region in February, 2017
- EC2 and RDS Service Disruption in US-East region in April, 2011
- EC2, EBS and RDS were disrupted in EU-West region in August, 2011
- Power outage brought down Rackspace Texas DC in June, 2009
- UPS failure caused hundreds of servers to go offline in Rackspace London DC in January, 2010
This is by no means a complete list of failures, it’s just the result of a quick Google search. These serve as examples that things may and will go wrong if you put all your eggs into the same basket. One more example would be Hurricane Sandy, which caused enormous exodus of data from US-East to US-West DC’s – at that time you could hardly spin up instances in US-West as everyone rushed to move their infrastructure to the other coast in expectation that North Virginia DC will be seriously affected by the weather.
So, multi-datacenter setups are a must if you want to build a high availability environment. In this blog post, we will discuss how to build such infrastructure using Galera Cluster for MySQL/MariaDB.
Galera Concepts
Before we look into particular solutions, let us spend some time explaining two concepts which are very important in highly available, multi-DC Galera setups.
Quorum
High availability requires resources – namely, you need a number of nodes in the cluster to make it highly available. A cluster can tolerate the loss of some of its members, but only to a certain extent. Beyond a certain failure rate, you might be looking at a split-brain scenario.
Let’s take an example with a 2 node setup. If one of the nodes goes down, how can the other one know that its peer crashed and it’s not a network failure? In that case, the other node might as well be up and running, serving traffic. There is no good way to handle such case… This is why fault tolerance usually starts from three nodes. Galera uses a quorum calculation to determine if it is safe for the cluster to handle traffic, or if it should cease operations. After a failure, all remaining nodes attempt to connect to each other and determine how many of them are up. It’s then compared to the previous state of the cluster, and as long as more than 50% of the nodes are up, the cluster can continue to operate.
This results in following:
2 node cluster – no fault tolerance
3 node cluster – up to 1 crash
4 node cluster – up to 1 crash (if two nodes would crash, only 50% of the cluster would be available, you need more than 50% nodes to survive)
5 node cluster – up to 2 crashes
6 node cluster – up to 2 crashes
You probably see the pattern – you want your cluster to have an odd number of nodes – in terms of high availability there’s no point in moving from 5 to 6 nodes in the cluster. If you want better fault tolerance, you should go for 7 nodes.
Segments
Typically, in a Galera cluster, all communication follows the all to all pattern. Each node talks to all the other nodes in the cluster.
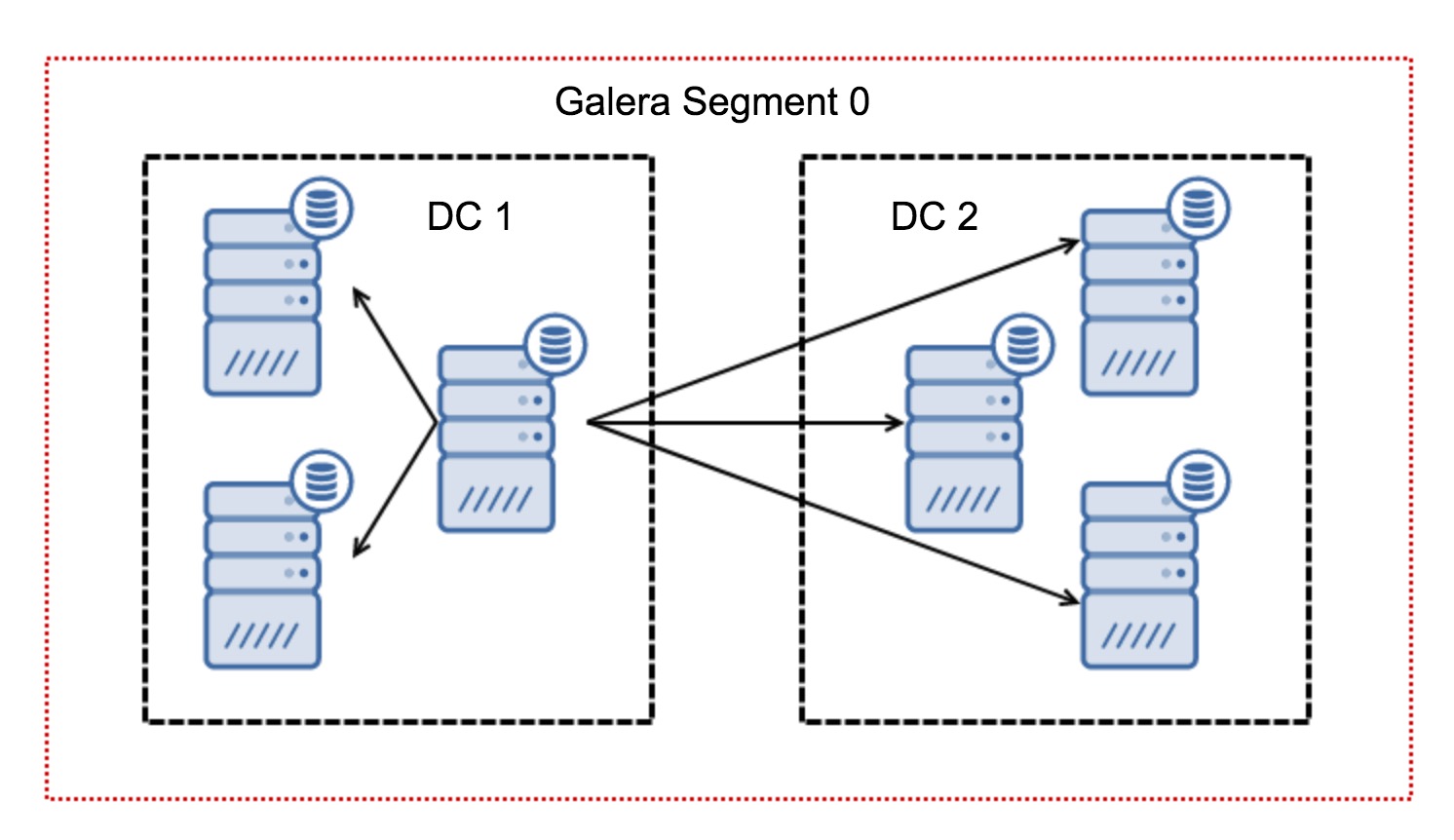
As you may know, each writeset in Galera has to be certified by all of the nodes in the cluster – therefore every write that happened on a node has to be transferred to all of the nodes in the cluster. This works ok in a low-latency environment. But if we are talking about multi-DC setups, we need to consider much higher latency than in a local network. To make it more bearable in clusters spanning over Wide Area Networks, Galera introduced segments.
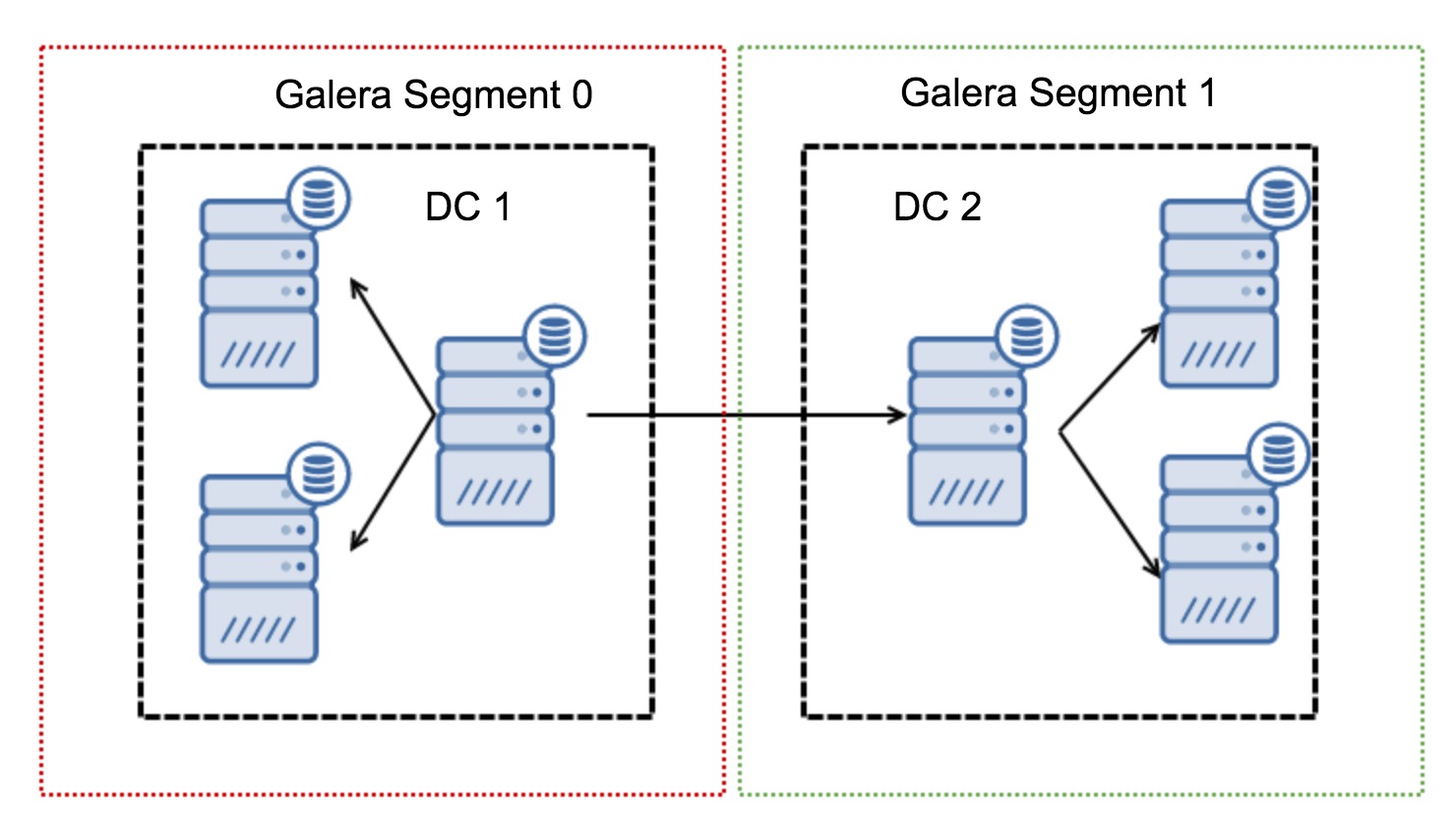
They work by containing the Galera traffic within a group of nodes (segment). All nodes within a single segment act as if they were in a local network – they assume one to all communication. For cross-segment traffic, things are different – in each of the segments, one “relay” node is chosen, all of the cross-segment traffic goes through those nodes. When a relay node goes down, another node is elected. This does not reduce latency by much – after all, WAN latency will stay the same no matter if you make a connection to one remote host or to multiple remote hosts, but given that WAN links tend to be limited in bandwidth and there might be a charge for the amount of data transferred, such approach allows you to limit the amount of data exchanged between segments. Another time and cost-saving option is the fact that nodes in the same segment are prioritized when a donor is needed – again, this limits the amount of data transferred over the WAN and, most likely, speeds up SST as a local network almost always will be faster than a WAN link.
Now that we’ve got some of these concepts out of the way, let’s look at some other important aspects of multi-DC setups for Galera cluster.
Issues you are About to Face
When working in environments spanning across WAN, there are a couple of issues you need to take under consideration when designing your environment.
Quorum Calculation
In the previous section, we described how a quorum calculation looks like in Galera cluster – in short, you want to have an odd number of nodes to maximize survivability. All of that is still true in multi-DC setups, but some more elements are added into the mix. First of all, you need to decide if you want Galera to automatically handle a datacenter failure. This will determine how many datacenters you are going to use. Let’s imagine two DC’s – if you’ll split your nodes 50% – 50%, if one datacenter goes down, the second one doesn’t have 50%+1 nodes to maintain its “primary” state. If you split your nodes in an uneven way, using the majority of them in the “main” datacenter, when that datacenter goes down, the “backup” DC won’t have 50% + 1 nodes to form a quorum. You can assign different weights to nodes but the result will be exactly the same – there’s no way to automatically failover between two DC’s without manual intervention. To implement automated failover, you need more than two DC’s. Again, ideally an odd number – three datacenters is a perfectly fine setup. Next, the question is – how many nodes you need to have? You want to have them evenly distributed across the datacenters. The rest is just a matter of how many failed nodes your setup has to handle.
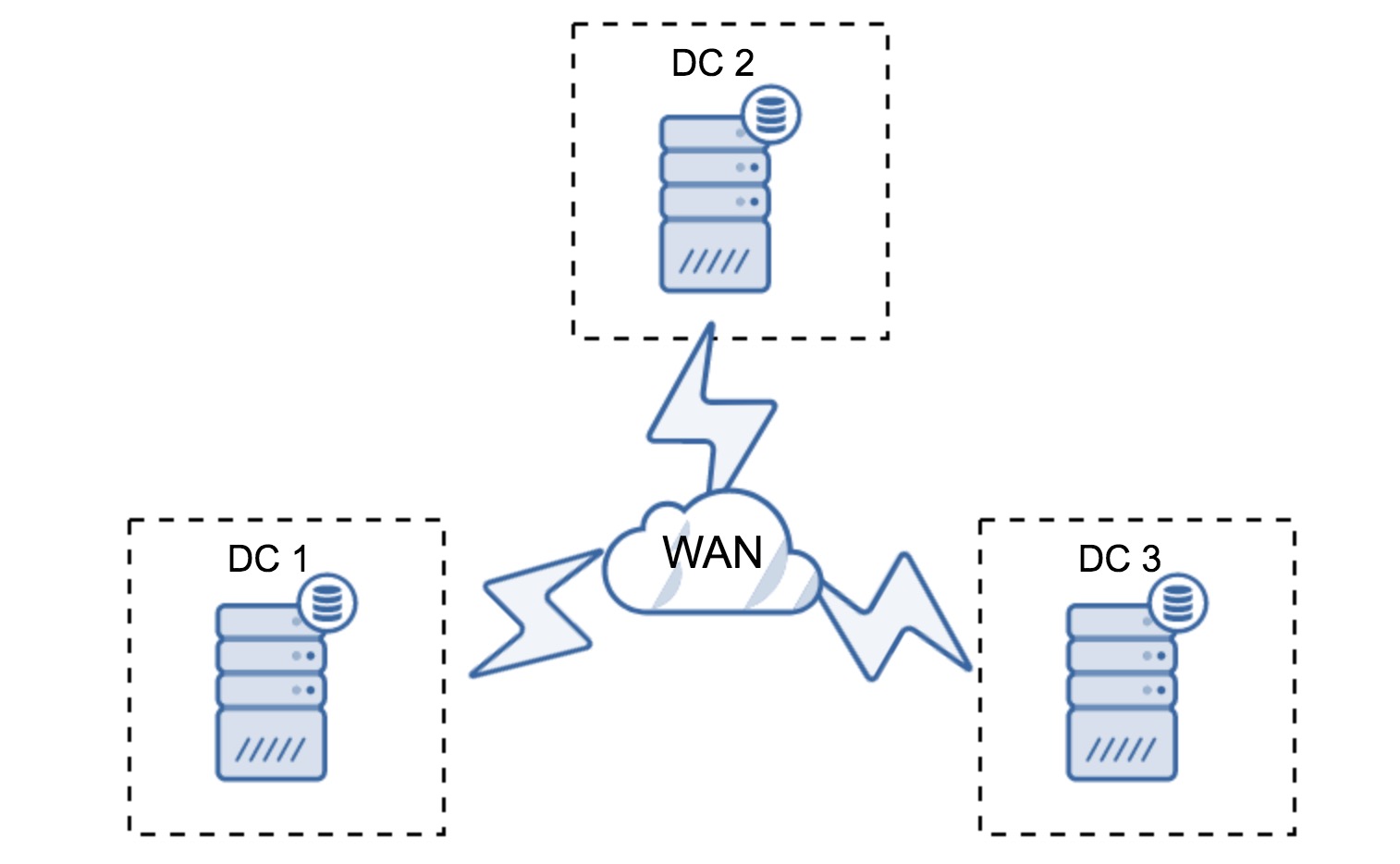
Minimal setup will use one node per datacenter – it has serious drawbacks, though. Every state transfer will require moving data across the WAN and this results in either longer time needed to complete SST or higher costs.
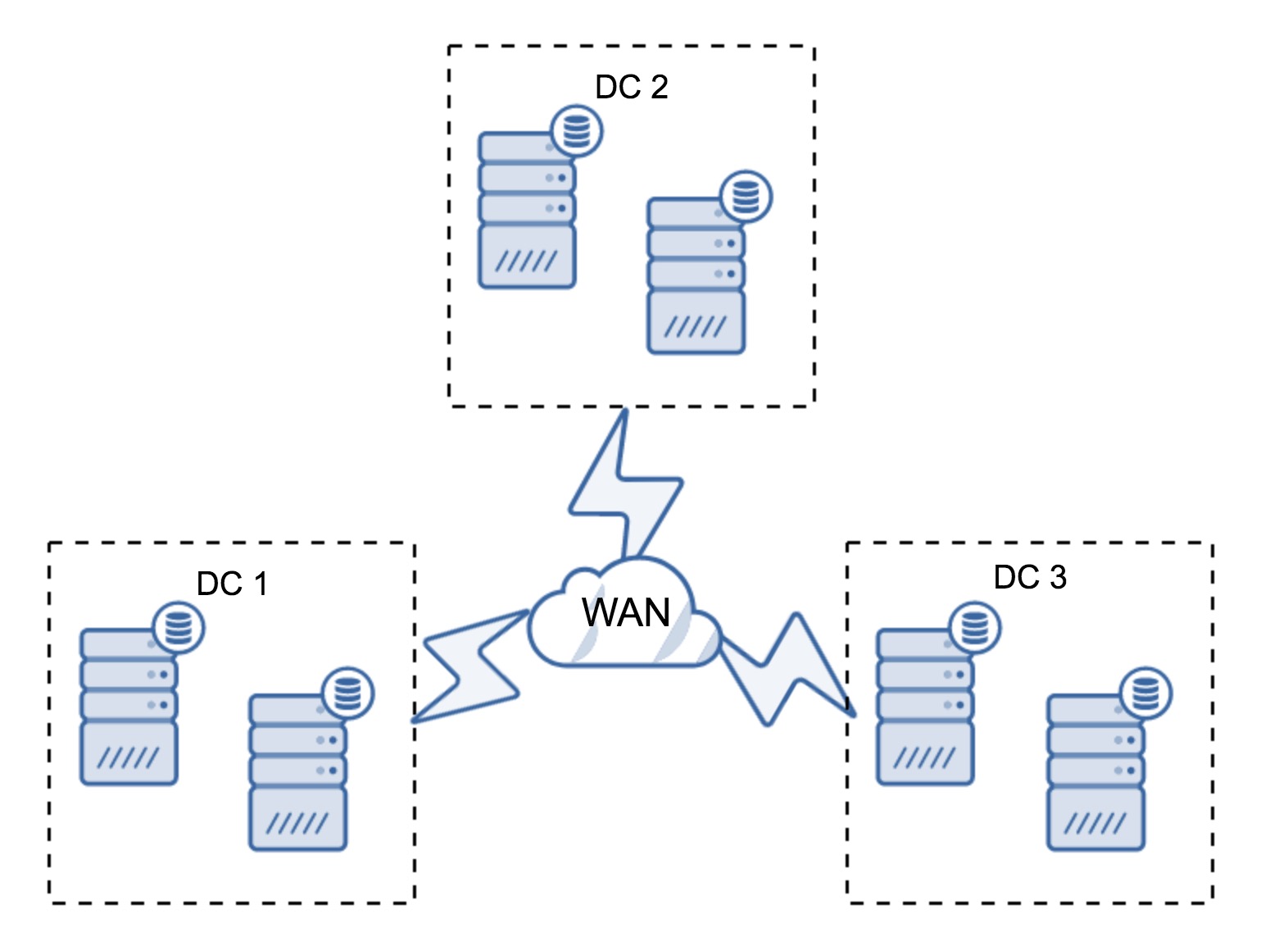
Quite typical setup is to have six nodes, two per datacenter. This setup seems unexpected as it has an even number of nodes. But, when you think of it, it might not be that big of an issue: it’s quite unlikely that three nodes will go down at once, and such a setup will survive a crash of up to two nodes. A whole datacenter may go offline and two remaining DC’s will continue operations. It also has a huge advantage over the minimal setup – when a node goes offline, there’s always a second node in the datacenter which can serve as a donor. Most of the time, the WAN won’t be used for SST.
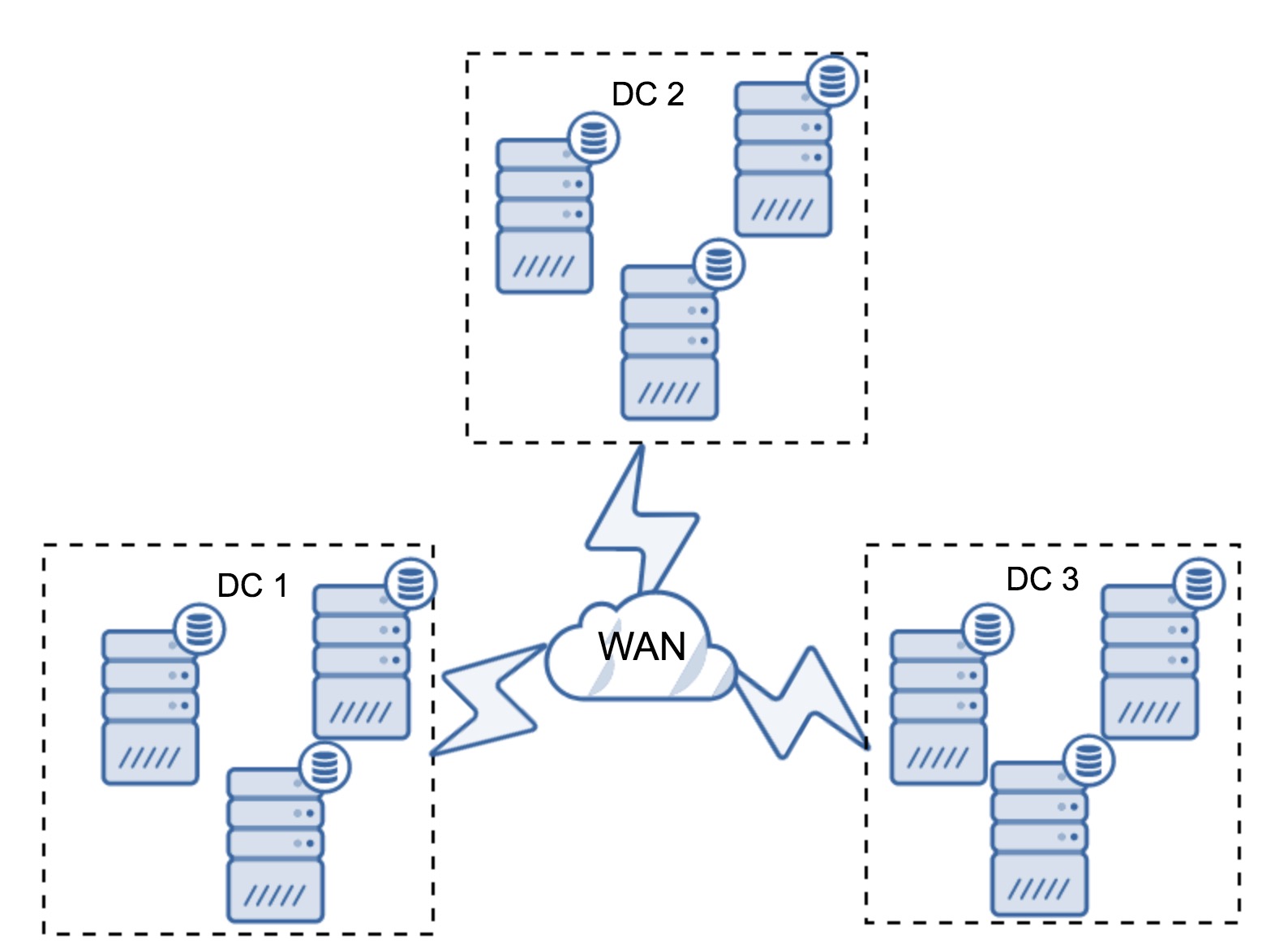
Of course, you can increase the number of nodes to three per cluster, nine in total. This gives you even better survivability: up to four nodes may crash and the cluster will still survive. On the other hand, you have to keep in mind that, even with the use of segments, more nodes means higher overhead of operations and you can scale out Galera cluster only to a certain extent.
It may happen that there’s no need for a third datacenter because, let’s say, your application is located in only two of them. Of course, the requirement of three datacenters is still valid so you won’t go around it, but it is perfectly fine to use a Galera Arbitrator (garbd) instead of fully loaded database servers.
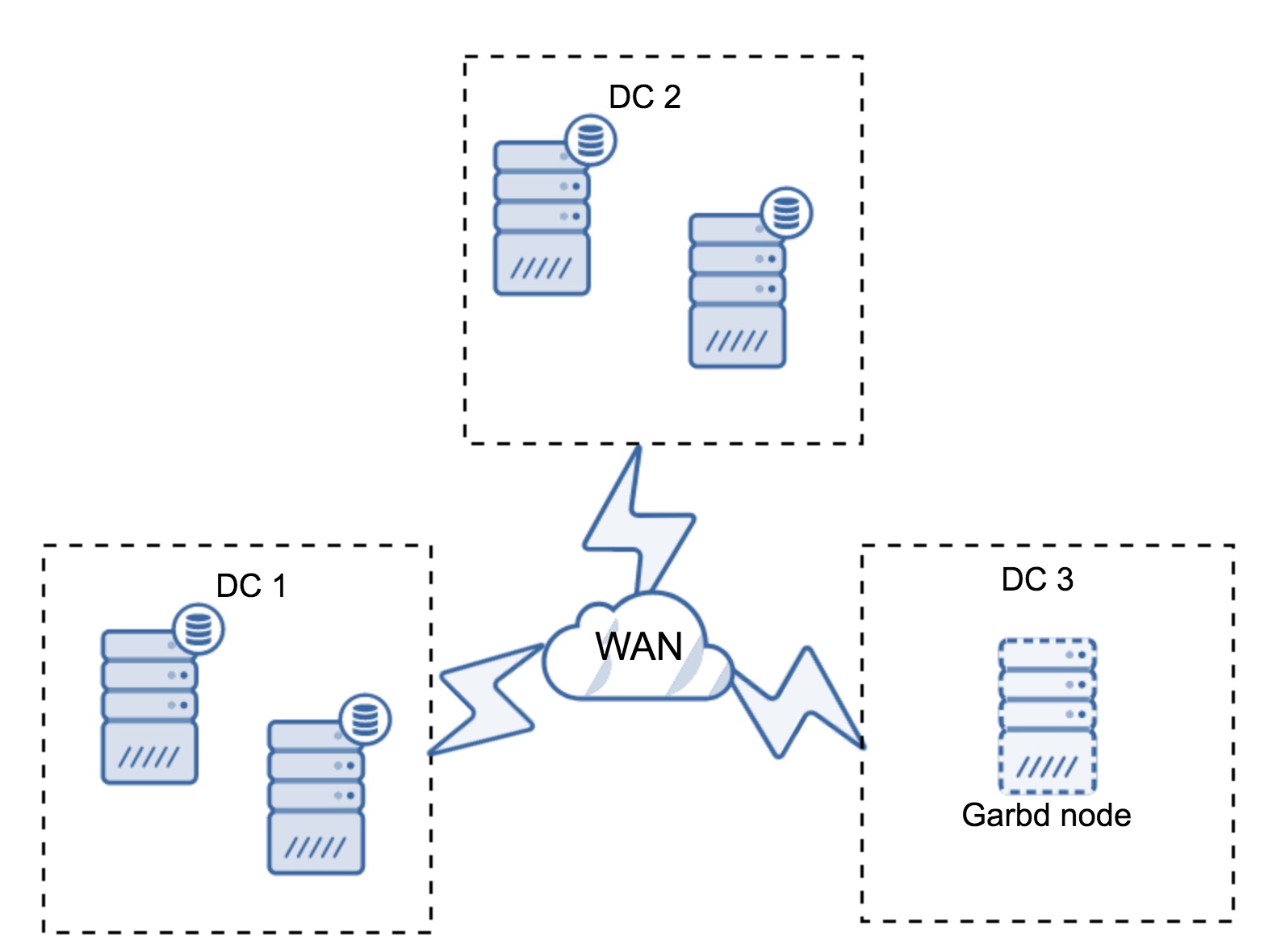
Garbd can be installed on smaller nodes, even virtual servers. It does not require powerful hardware, it does not store any data nor apply any of the writesets. But it does see all the replication traffic, and takes part in the quorum calculation. Thanks to it, you can deploy setups like four nodes, two per DC + garbd in the third one – you have five nodes in total, and such cluster can accept up to two failures. So it means it can accept a full shutdown of one of the datacenters.
Which option is better for you? There is no best solution for all cases, it all depends on your infrastructure requirements. Luckily, there are different options to pick from: more or less nodes, full 3 DC or 2 DC and garbd in the third one – it’s quite likely you’ll find something suitable for you.
Network Latency
When working with multi-DC setups, you have to keep in mind that network latency will be significantly higher than what you’d expect from a local network environment. This may seriously reduce performance of the Galera cluster when you compare it with standalone MySQL instance or a MySQL replication setup. The requirement that all of the nodes have to certify a writeset means that all of the nodes have to receive it, no matter how far away they are. With asynchronous replication, there’s no need to wait before a commit. Of course, replication has other issues and drawbacks, but latency is not the major one. The problem is especially visible when your database has hot spots – rows, which are frequently updated (counters, queues, etc). Those rows cannot be updated more often than once per network round trip. For clusters spanning across the globe, this can easily mean that you won’t be able to update a single row more often than 2 – 3 times per second. If this becomes a limitation for you, it may mean that Galera cluster is not a good fit for your particular workload.
Proxy Layer in Multi-DC Galera Cluster
It’s not enough to have Galera cluster spanning across multiple datacenters, you still need your application to access them. One of the popular methods to hide complexity of the database layer from an application is to utilize a proxy. Proxies are used as an entry point to the databases, they track the state of the database nodes and should always direct traffic to only the nodes that are available. In this section, we’ll try to propose a proxy layer design which could be used for a multi-DC Galera cluster. We’ll use ProxySQL, which gives you quite a bit of flexibility in handling database nodes, but you can use another proxy, as long as it can track the state of Galera nodes.
Where to Locate the Proxies?
In short, there are two common patterns here: you can either deploy ProxySQL on a separate nodes or you can deploy them on the application hosts. Let’s take a look at pros and cons of each of these setups.
Proxy Layer as a Separate set of Hosts
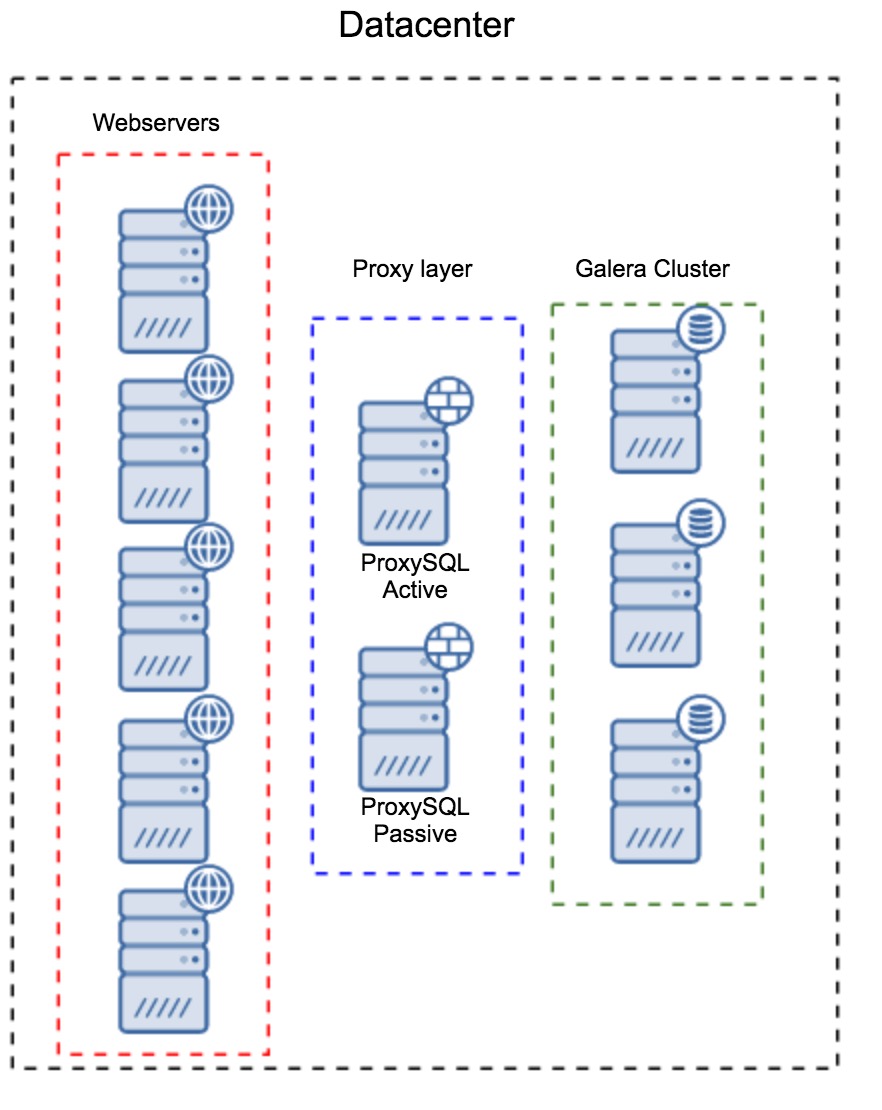
The first pattern is to build a proxy layer using separate, dedicated hosts. You can deploy ProxySQL on a couple of hosts, and use Virtual IP and keepalived to maintain high availability. An application will use the VIP to connect to the database, and the VIP will ensure that requests will always be routed to an available ProxySQL. The main issue with this setup is that you use at most one of the ProxySQL instances – all standby nodes are not used for routing the traffic. This may force you to use more powerful hardware than you’d typically use. On the other hand, it is easier to maintain the setup – you will have to apply configuration changes on all of the ProxySQL nodes, but there will be just a handful of them. You can also utilize ClusterControl’s option to sync the nodes. Such setup will have to be duplicated on every datacenter that you use.
Proxy Installed on Application Instances
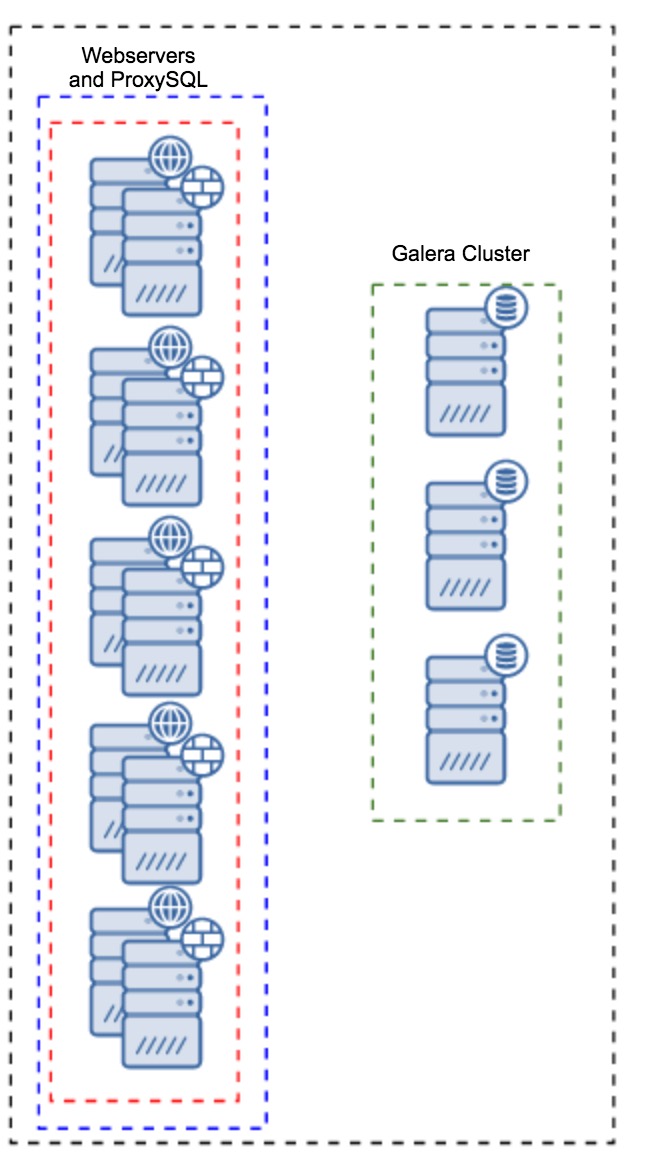
Instead of having a separate set of hosts, ProxySQL can also be installed on the application hosts. Application will connect directly to the ProxySQL on localhost, it could even use unix socket to minimize the overhead of the TCP connection. The main advantage of such a setup is that you have a large number of ProxySQL instances, and the load is evenly distributed across them. If one goes down, only that application host will be affected. The remaining nodes will continue to work. The most serious issue to face is configuration management. With a large number of ProxySQL nodes, it is crucial to come up with an automated method of keeping their configurations in sync. You could use ClusterControl, or a configuration management tool like Puppet.
Tuning of Galera in a WAN Environment
Galera defaults are designed for local network and if you want to use it in a WAN environment, some tuning is required. Let’s discuss some of the basic tweaks you can make. Please keep in mind that the precise tuning requires production data and traffic – you can’t just make some changes and assume they are good, you should do proper benchmarking.
Operating System Configuration
Let’s start with the operating system configuration. Not all of the modifications proposed here are WAN-related, but it’s always good to remind ourselves what is a good starting point for any MySQL installation.
vm.swappiness = 1Swappiness controls how aggressive the operating system will use swap. It should not be set to zero because in more recent kernels, it prevents the OS from using swap at all and it may cause serious performance issues.
/sys/block/*/queue/scheduler = deadline/noopThe scheduler for the block device, which MySQL uses, should be set to either deadline or noop. The exact choice depends on the benchmarks but both settings should deliver similar performance, better than default scheduler, CFQ.
For MySQL, you should consider using EXT4 or XFS, depending on the kernel (performance of those filesystems changes from one kernel version to another). Perform some benchmarks to find the better option for you.
In addition to this, you may want to look into sysctl network settings. We will not discuss them in detail (you can find documentation here) but the general idea is to increase buffers, backlogs and timeouts, to make it easier to accommodate for stalls and unstable WAN link.
net.core.optmem_max = 40960
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 87380 16777216
net.core.netdev_max_backlog = 50000
net.ipv4.tcp_max_syn_backlog = 30000
net.ipv4.tcp_congestion_control = htcp
net.ipv4.tcp_mtu_probing = 1
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_slow_start_after_idle = 0In addition to OS tuning you should consider tweaking Galera network – related settings.
evs.suspect_timeout
evs.inactive_timeoutYou may want to consider changing the default values of these variables. Both timeouts govern how the cluster evicts failed nodes. Suspect timeout takes place when all of the nodes cannot reach the inactive member. Inactive timeout defines a hard limit of how long a node can stay in the cluster if it’s not responding. Usually you’ll find that the default values work well. But in some cases, especially if you run your Galera cluster over WAN (for example, between AWS regions), increasing those variables may result in more stable performance. We’d suggest to set both of them to PT1M, to make it less likely that WAN link instability will throw a node out of the cluster.
evs.send_window
evs.user_send_windowThese variables, evs.send_window and evs.user_send_window, define how many packets can be sent via replication at the same time (evs.send_window) and how many of them may contain data (evs.user_send_window). For high latency connections, it may be worth increasing those values significantly (512 or 1024 for example).
evs.inactive_check_periodThe above variable may also be changed. evs.inactive_check_period, by default, is set to one second, which may be too often for a WAN setup. We’d suggest to set it to PT30S.
gcs.fc_factor
gcs.fc_limitHere we want to minimize chances that flow control will kick in, therefore we’d suggest to set gcs.fc_factor to 1 and increase gcs.fc_limit to, for example, 260.
gcs.max_packet_sizeAs we are working with the WAN link, where latency is significantly higher, we want to increase size of the packets. A good starting point would be 2097152.
As we mentioned earlier, it is virtually impossible to give a simple recipe on how to set these parameters as it depends on too many factors – you will have to do your own benchmarks, using data as close to your production data as possible, before you can say your system is tuned. Having said that, those settings should give you a starting point for the more precise tuning.
That’s it for now. Galera works pretty well in WAN environments, so do give it a try and let us know how you get on.



