blog
Database User Management With ClusterControl

In the previous posts of this blog series, we covered deployment of clustering/replication (MySQL / Galera, MySQL Replication, MongoDB & PostgreSQL), management & monitoring of your existing databases and clusters, performance monitoring and health, how to make your setup highly available through HAProxy and MaxScale, how to prepare yourself against disasters by scheduling backups, how to manage your database configurations and in the last post how to manage your log files.
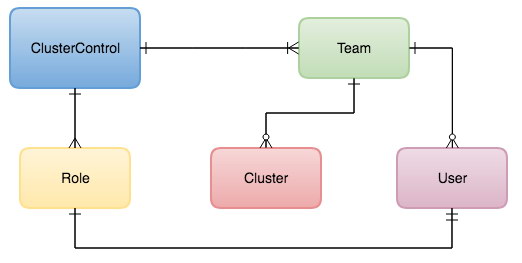
One of the most important aspects of becoming a ClusterControl DBA is to be able to delegate tasks to team members, and control access to ClusterControl functionality. This can be achieved by utilizing the User Management functionality, that allows you to control who can do what. You can even go a step further by adding teams or organizations to ClusterControl and map them to your DevOps roles.
Teams
Teams can be seen either as a full organization or groups of users. Clusters can be assigned to teams and in this way the cluster is only visible for the users in the team it has been assigned to. This allows you to run multiple teams or organizations within one ClusterControl environment. Obviously the ClusterControl admin account will still be able to see and manage all clusters.
You can create a new Team via Side Menu -> User Management -> Teams and clicking on the plus sign on the left side under Teams section:
After adding a new Team, you can assign users to the team.
Users
After selecting the newly created team, you can add new users to this team by pressing the plus sign on the right dialogue:
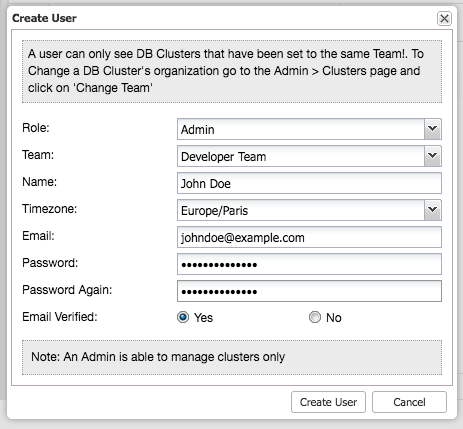
By selecting the role, you can limit the functionality of the user to either an Super Admin, Admin or User. You can extend these default roles in the Access Control section.
Access Control
Standard Roles
Within ClusterControl the default roles are: Super Admin, Admin and User. The Super Admin is the only account that can administer teams, users and roles. The Super Admin is also able to migrate clusters across across teams or organizations. The admin role belongs to a specific organization and is able to see all clusters in this organization. The user role is only able to see the clusters he/she created.
User Roles
You can add new roles within the role based access control screen. You can define the privileges per functionality whether the role is allowed (read-only), denied (deny), manage (allow change) or modify (extended manage).
If we create a role with limited access:
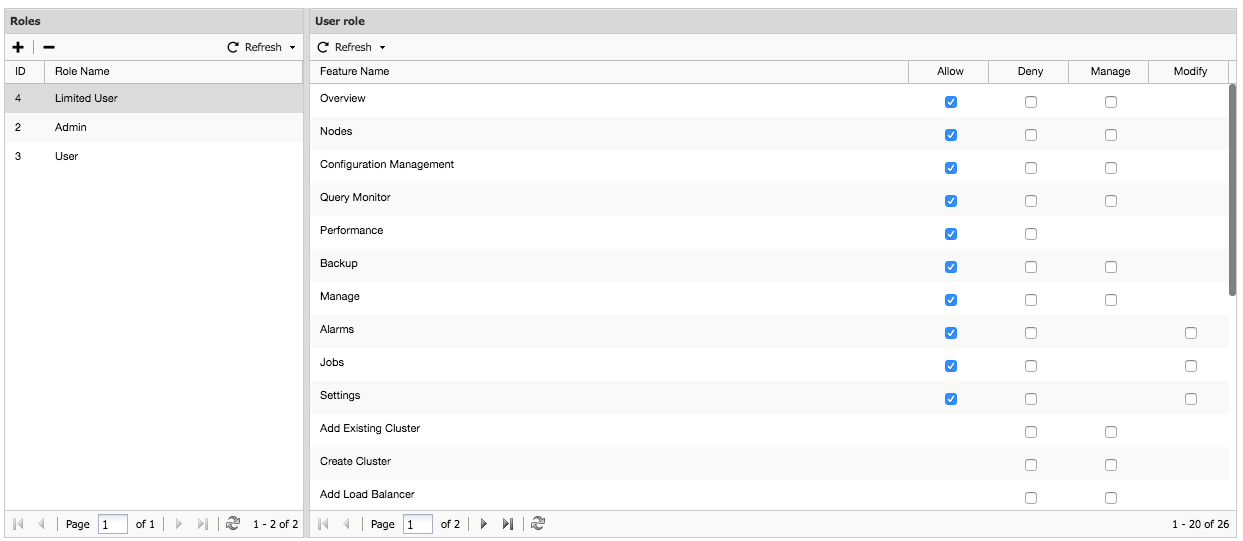
As you can see, we can create a user with limited access rights (mostly read-only) and ensure this user does not break anything. This also means we could add non-technical roles like Manager here.
Notice that the Super Admin role is not listed here as it is a default role with the highest level of privileges within ClusterControl and thus can’t be changed.
LDAP Access
ClusterControl supports Active Directory, FreeIPA and LDAP authentication. This allows you to integrate ClusterControl within your organization without having to recreate the users. In earlier blog posts we described how to set up ClusterControl to authenticate against OpenLDAP, FreeIPA and Active Directory.
Once this has been set up authentication against ClusterControl will follow the chart below:
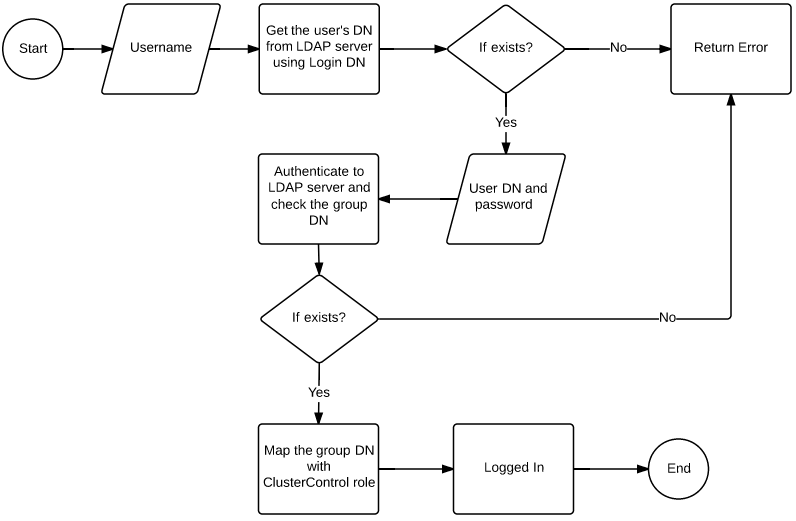
Basically the most important part here is to map the LDAP group to the ClusterControl role. This can be done fairly easy in the LDAP Settings page under User Management.
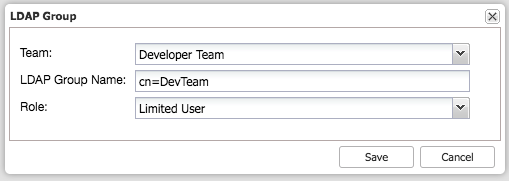
The dialog above would map the DevopsTeam to the Limited User role in ClusterControl. Then repeat this for any other group you wish to map. After this any user authenticating against ClusterControl will be authenticated and authorized via the LDAP integration.
Final Thoughts
Combining all the above allows you to integrate ClusterControl better into your existing organization, create specific roles with limited or full access and connect users to these roles. The beauty of this is that you are now much more flexible in how you organize around your database infrastructure: who is allowed to do what? You could for instance offload the task of backup checking to a site reliability engineer instead of having the DBA check them daily. Allow your developers to check the MySQL, Postgres and MongoDB log files to correlate them with their monitoring. You could also allow a senior developer to scale the database by adding more nodes/shards or have a seasoned DevOps engineer write advisors.
As you can see the possibilities here are endless, it is only a question of how to unlock them. In the Developer Studio blog series, we dive deeper into automation with ClusterControl and for DevOps integration we recently released CCBot.



