blog
Deploying Highly Available Databases and Clusters with ClusterControl

We get some nice feedback with regards to our product ClusterControl, especially how easy it is to install and get going. Installing new software is one thing, but using it properly is another.
It is not uncommon to be impatient to test new software and one would rather toy around with a new exciting application than to read documentation before getting started. That is a bit unfortunate as you may miss important features or misunderstand how to use them.
This blog series covers all the basic operations of ClusterControl for MySQL, MongoDB & PostgreSQL with examples on how to make the most of your setup. It provides you with a deep dive on different topics to save you time.
These are the topics covered in this series:
- Deploying the first clusters
- Adding your existing infrastructure
- Performance and health monitoring
- Making your components HA
- Workflow management
- Safeguarding your data
- Protecting your data
- In depth use case
In today’s post, we’ll cover installing ClusterControl and deploying your first clusters.
Preparations
In this series, we will make use of a set of Vagrant boxes but you can use your own infrastructure if you like. In case you do want to test it with Vagrant, we made an example setup available from the following Github repository: https://github.com/severalnines/vagrant
Clone the repo to your own machine:
$ git clone [email protected]:severalnines/vagrant.gitThe topology of the vagrant nodes is as follows:
- vm1: clustercontrol
- vm2: database node1
- vm3: database node2
- vm4: database node3
You can easily add additional nodes if you like by changing the following line:
4.times do |n|The Vagrant file is configured to automatically install ClusterControl on the first node and forward the user interface of ClusterControl to port 8080 on your host that runs Vagrant. So if your host’s ip address is 192.168.1.10, you will find the ClusterControl UI here: http://192.168.1.10:8080/clustercontrol/
Installing ClusterControl
You can skip this if you chose to use the Vagrant file, and get the automatic installation. But installation of ClusterControl is straightforward and will take less than five minutes.
With the package installation, all you have to do is to issue the following three commands on the ClusterControl node to get it installed:
$ wget https://severalnines.com/downloads/cmon/install-cc
$ chmod +x install-cc
$ ./install-cc # as root or sudo userThat’s it: it can’t get easier than this. If the installation script has not encountered any issues, then ClusterControl should be installed and up and running. You can now log into ClusterControl on the following URL: http://192.168.1.210/clustercontrol
After creating an administrator account and logging in, you will be prompted to add your first cluster.
Deploy a Galera cluster
You will be prompted to create a new database server/cluster or import an existing (i.e., already deployed) server or cluster:
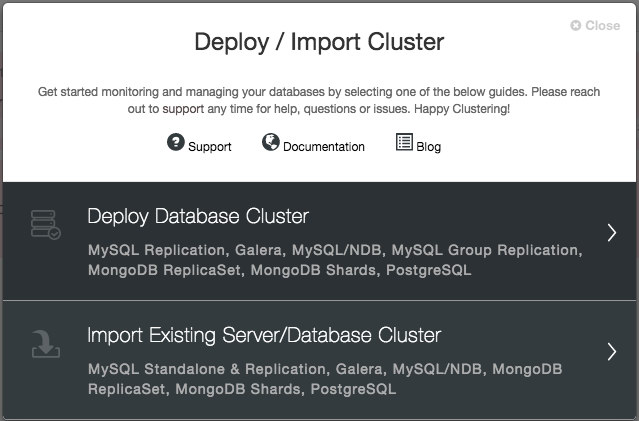
We are going to deploy a Galera cluster. There are two sections that need to be filled in. The first tab is related to SSH and general settings:
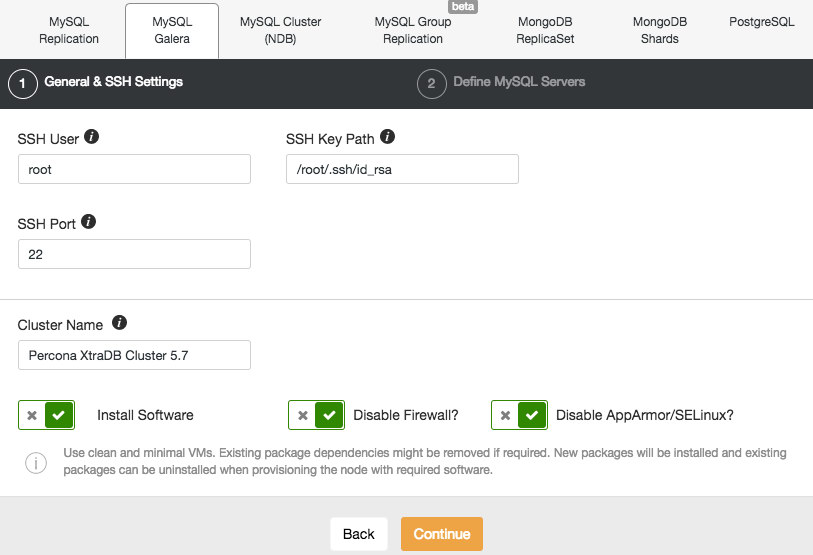
To allow ClusterControl to install the Galera nodes, we use the root user that was granted SSH access by the Vagrant bootstrap scripts. In case you chose to use your own infrastructure, you must enter a user here that is allowed to do passwordless SSH to the nodes that ClusterControl will control. Just keep in mind that you have to setup passwordless SSH from ClusterControl to all database nodes by yourself beforehand.
Also make sure you disable AppArmor/SELinux. See here why.
Then, proceed to the second stage and specify the database related information and the target hosts:
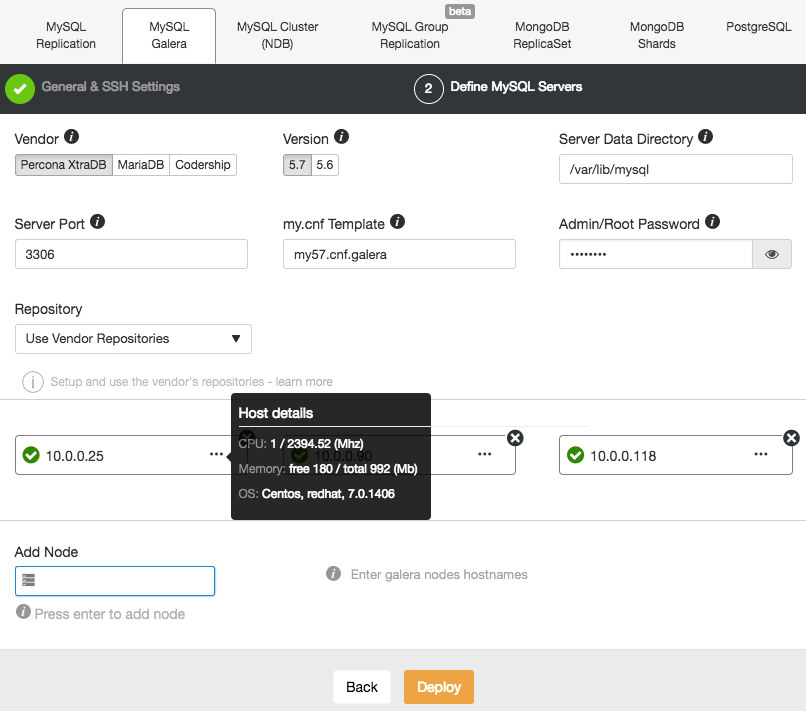
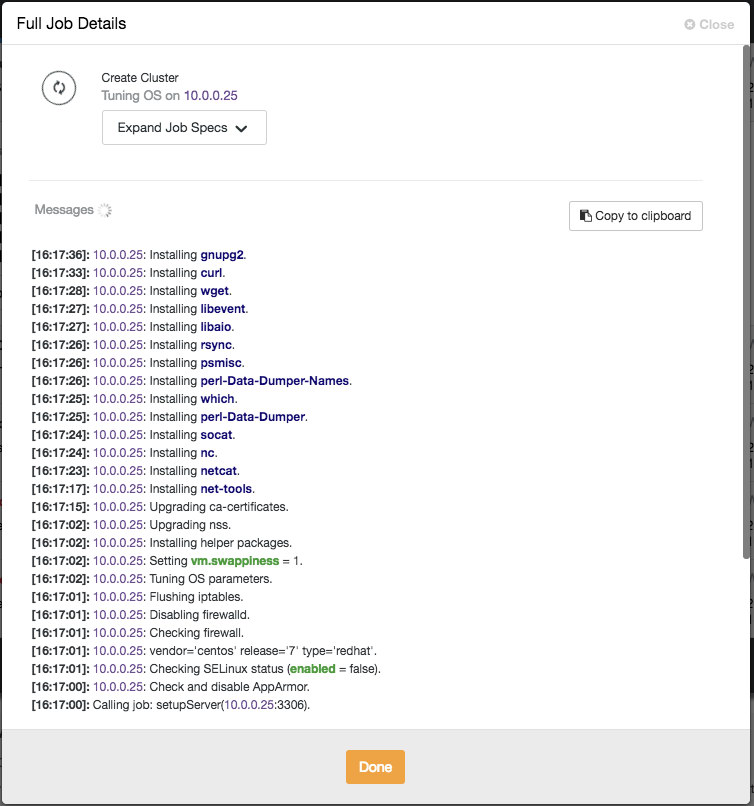
ClusterControl will immediately perform some sanity checks each time you press Enter when adding a node. You can see the host summary by hovering over each defined node. Once everything is green, it means that ClusterControl has connectivity to all nodes, you can click Deploy. A job will be spawned to build the new cluster. The nice thing is that you can keep track of the progress of this job by clicking on the Activity -> Jobs -> Create Cluster -> Full Job Details:
Once the job has finished, you have just created your first cluster. The cluster overview should look like this:
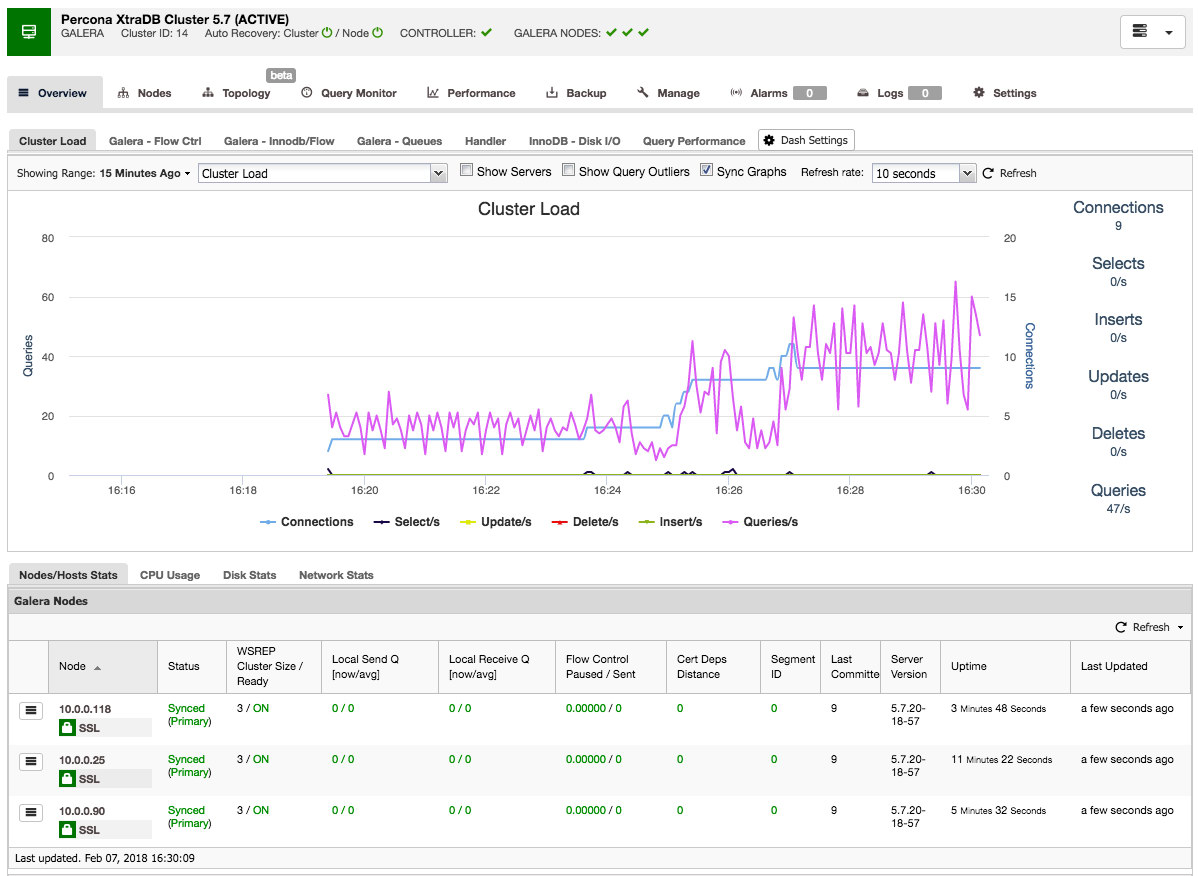
In the nodes tab, you can do about any operation you normally would do on a cluster. The query monitor gives you a good overview of both running and top queries. The performance tab will help you keep a close eye on the performance of your cluster and also features the advisors that help you act proactively on trends in data. The backup tab enables you to easily schedule backups and store them on local or cloud storage. The manage tab enables you to expand your cluster or make it highly available for your applications through a load balancer.
All this functionality will be covered in later blog posts in this series.
Deploy a MySQL Replication Cluster
Deploying a MySQL Replication setup is similar to Galera database deployment, except that it has an additional tab in the deployment dialog where you can define the replication topology:
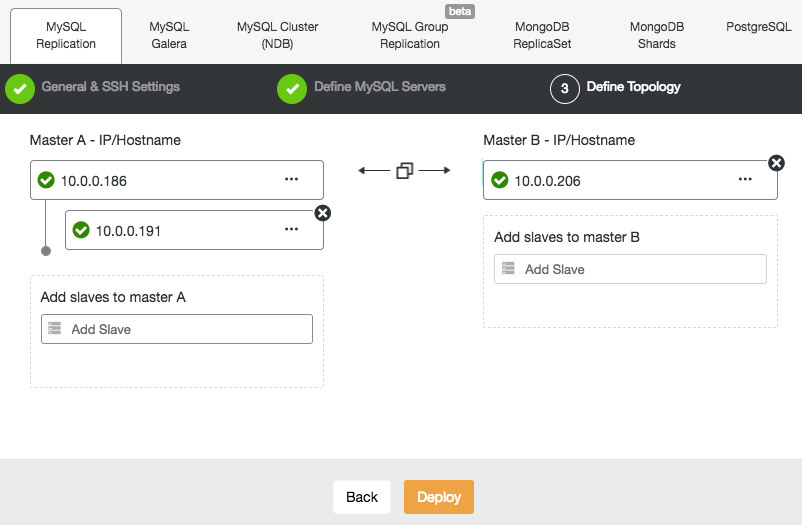
You can set up standard master-slave replication, as well as master-master replication. In case of the latter, only one master will remain writable at a time. Keep in mind that master-master replication doesn’t come with conflict resolution and guaranteed data consistency, as in the case of Galera. Use this setup with caution, or look into Galera cluster. Once everything is green and you have clicked Deploy, a job will be spawned to build the new cluster.
Again, the deployment progress is available under Activity -> Jobs.
To scale out the slave (read copy), simply use the “Add Node” option in the cluster list:
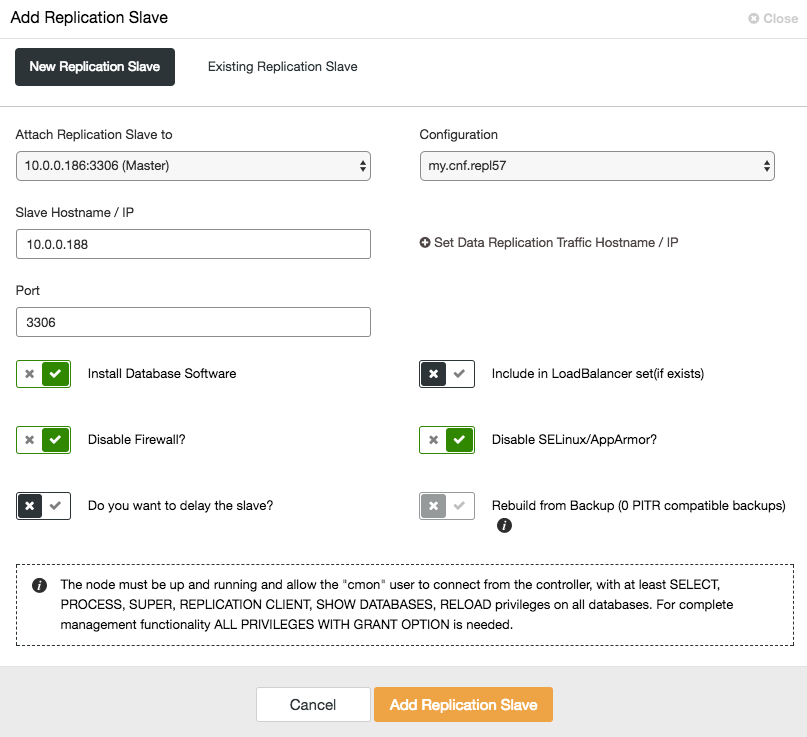
After adding the slave node, ClusterControl will provision the slave with a copy of the data from its master using Xtrabackup or from any existing PITR compatible backups for that cluster.
Deploy PostgreSQL Replication
ClusterControl supports the deployment of PostgreSQL version 9.x and higher. The steps are similar with MySQL Replication deployment, where at the end of the deployment step, you can define the database topology when adding the nodes:
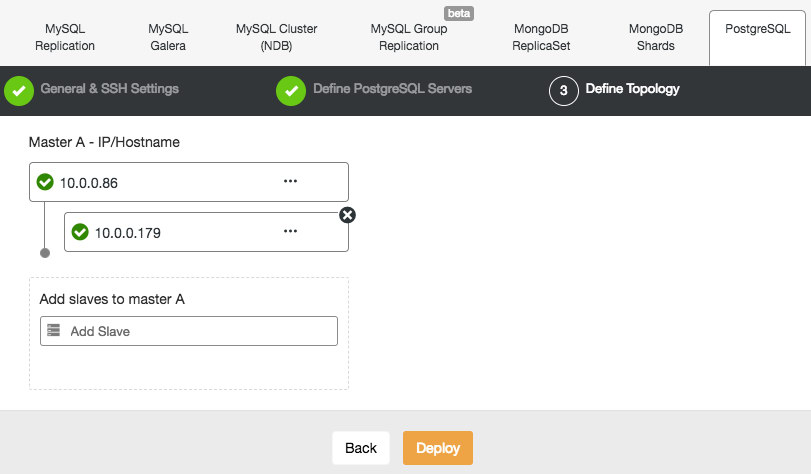
Similar to MySQL Replication, once the deployment completes, you can scale out by adding replications slave to the cluster. The step is as simple as selecting the master and filling in the FQDN for the new slave:
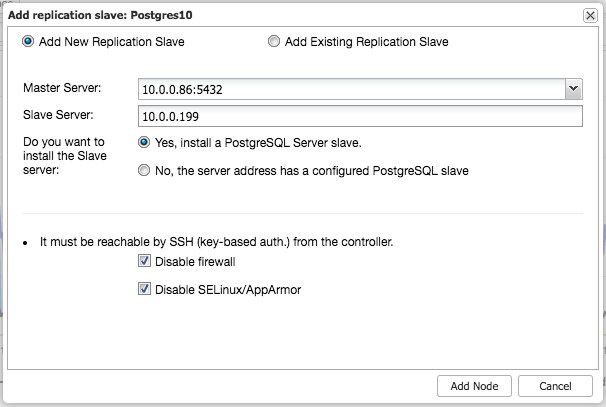
ClusterControl will then perform the necessary data staging from the chosen master using pg_basebackup, configure the replication user and enable the streaming replication. The PostgreSQL cluster overview gives you some insight into your setup:
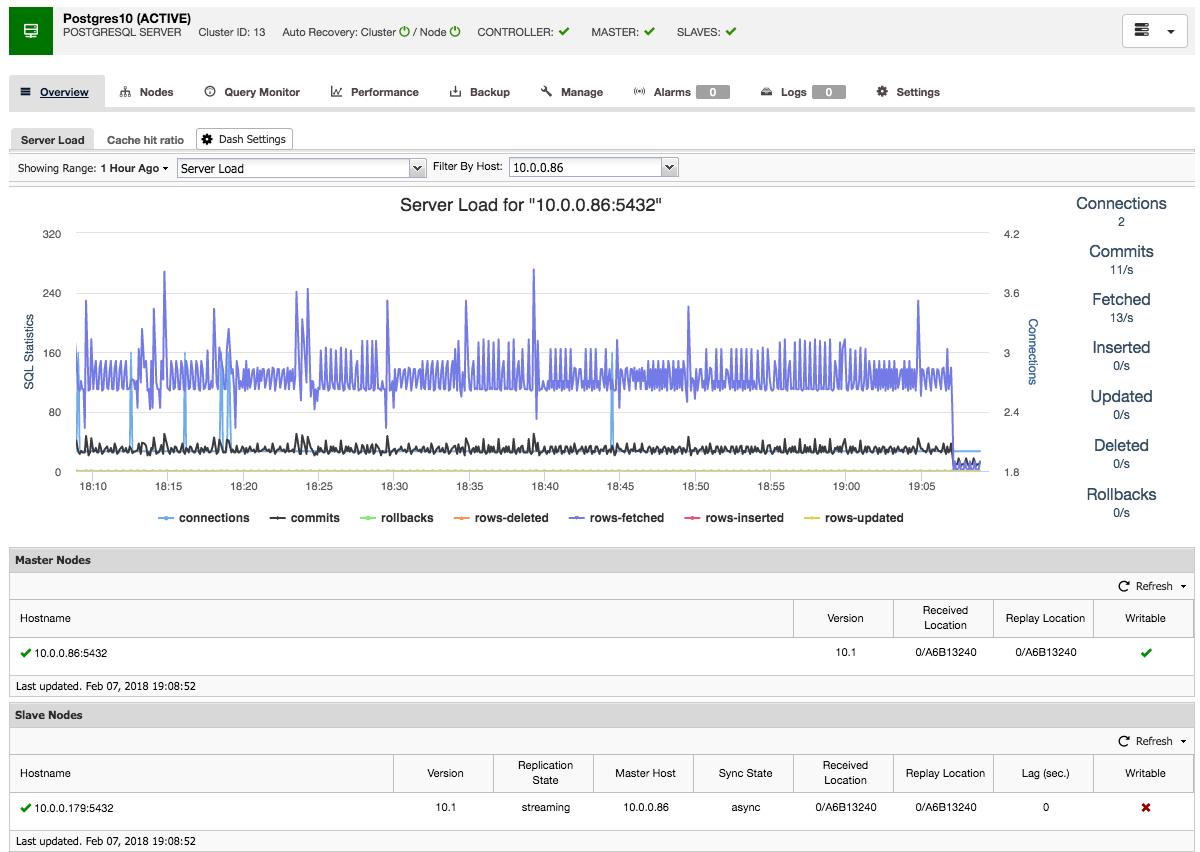
Just like with the Galera and MySQL cluster overviews, you can find all the necessary tabs and functions here: the query monitor, performance, backup tabs all enable you to do the necessary operations.
Deploy a MongoDB Replica Set
Deploying a new MongoDB Replica Set is similar to the other clusters. From the Deploy Database Cluster dialog, pick MongoDB ReplicatSet, define the preferred database options and add the database nodes:
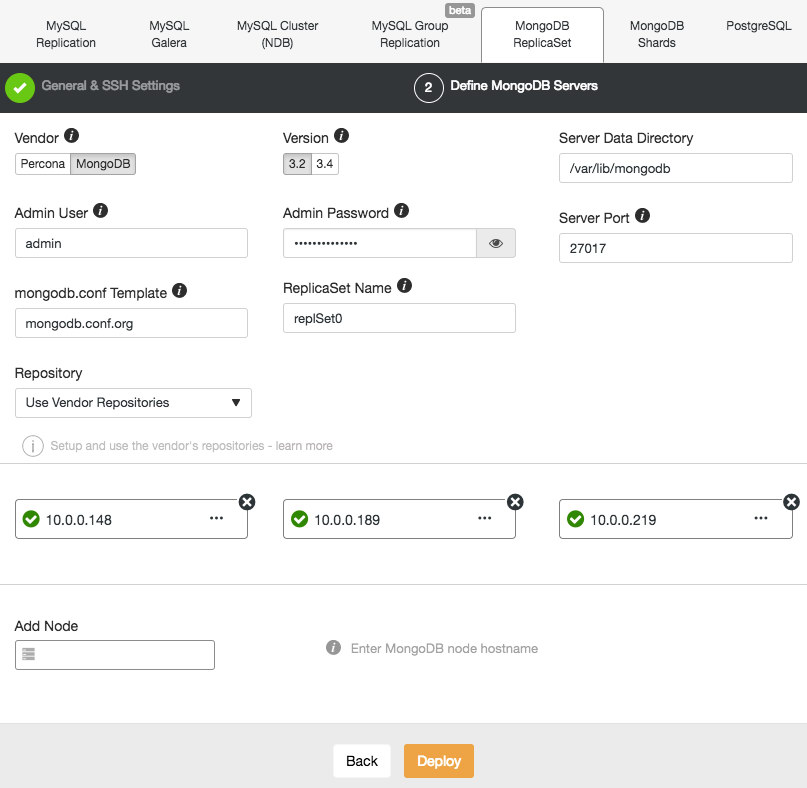
You can either choose to install Percona Server for MongoDB from Percona or MongoDB Server from MongoDB, Inc (formerly 10gen). You also need to specify the MongoDB admin user and password since ClusterControl will deploy by default a MongoDB cluster with authentication enabled.
After installing the cluster, you can add an additional slave or arbiter node into the replica set using the “Add Node” menu under the same dropdown from the cluster overview:
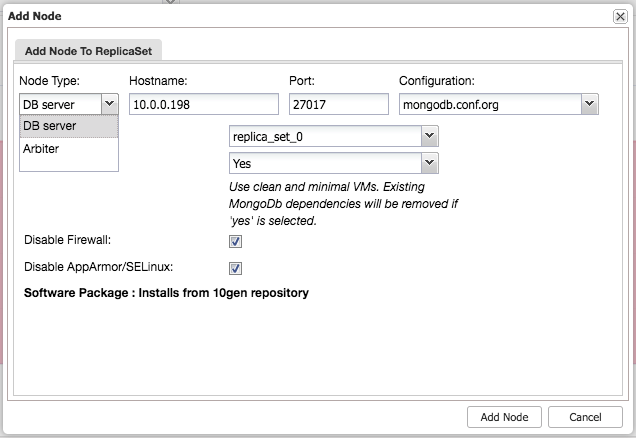
After adding the slave or arbiter to the replica set, a job will be spawned. Once this job has finished it will take a short while before MongoDB adds it to the cluster and it becomes visible in the cluster overview:
Final Thoughts
With these three examples we have shown you how easy it is to set up different clusters from scratch in only a couple of minutes. The beauty of using this Vagrant setup is that, as easy as spawning this environment, you can also take it down and then spawn again. Impress your fellow colleagues by showing how quickly you can setup a working environment.
Of course it would be equally interesting to add existing hosts and already-deployed clusters into ClusterControl, and that’s what we’ll cover next time.



