blog
Safeguarding your Data with ClusterControl

In the past four posts of the blog series, we covered deployment of clustering/replication (MySQL/Galera, MySQL Replication, MongoDB & PostgreSQL), management & monitoring of your existing databases and clusters, performance monitoring and health and in the last post, how to make your setup highly available through HAProxy and ProxySQL.
So now that you have your databases up and running and highly available, how do you ensure that you have backups of your data?
You can use backups for multiple things: disaster recovery, to provide production data to test against development or even to provision a slave node. This last case is already covered by ClusterControl. When you add a new (replica) node to your replication setup, ClusterControl will make a backup/snapshot of the master node and use it to build the replica. It can also use an existing backup to stage the replica, in case you want to avoid that extra load on the master. After the backup has been extracted, prepared and the database is up and running, ClusterControl will automatically set up replication.
Creating an Instant Backup
In essence, creating a backup is the same for Galera, MySQL replication, PostgreSQL and MongoDB. You can find the backup section under ClusterControl > Backup and by default you would see a list of created backup of the cluster (if any). Otherwise, you would see a placeholder to create a backup:
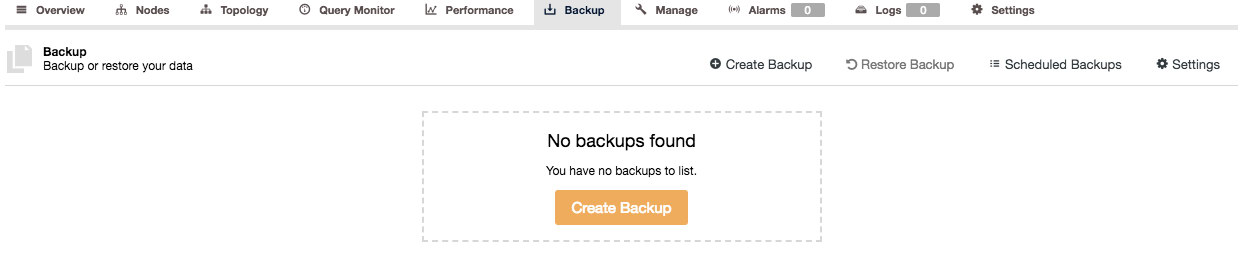
From here you can click on the “Create Backup” button to make an instant backup or schedule a new backup:
All created backups can also be uploaded to cloud by toggling “Upload Backup to the Cloud”, provided you supply working cloud credentials. By default, all backups older than 31 days will be deleted (configurable via Backup Retention settings) or you can choose to keep it forever or define a custom period.
“Create Backup” and “Schedule Backup” share similar options except the scheduling part and incremental backup options for the latter. Therefore, we are going to look into Create Backup feature (a.k.a instant backup) in more depth.
As all these various databases have different backup tools, there is obviously some difference in the options you can choose. For instance with MySQL you get to choose between mysqldump and xtrabackup (full and incremental). For MongoDB, ClusterControl supports mongodump and mongodb-consistent-backup (beta) while PostgreSQL, pg_dump and pg_basebackup are supported. If in doubt which one to choose for MySQL, check out this blog about the differences and use cases for mysqldump and xtrabackup.
Backing up MySQL and Galera
As mentioned in the previous paragraph, you can make MySQL backups using either mysqldump or xtrabackup (full or incremental). In the “Create Backup” wizard, you can choose which host you want to run the backup on, the location where you want to store the backup files, and its directory and specific schemas (xtrabackup) or schemas and tables (mysqldump).
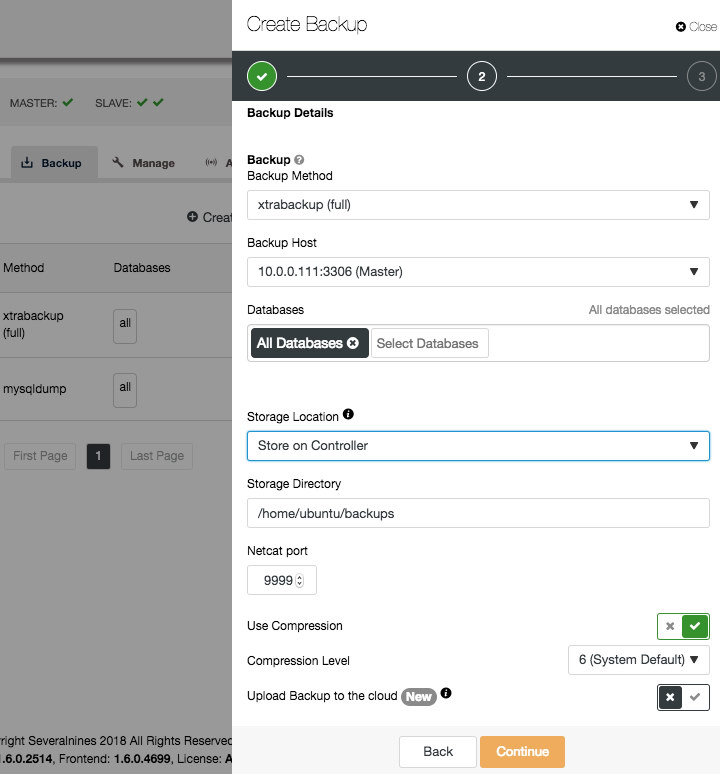
If the node you are backing up is receiving (production) traffic, and you are afraid the extra disk writes will become intrusive, it is advised to send the backups to the ClusterControl host by choosing “Store on Controller” option. This will cause the backup to stream the files over the network to the ClusterControl host and you have to make sure there is enough space available on this node and the streaming port is opened on the ClusterControl host.
There are also several other options whether you would want to use compression and the compression level. The higher the compression level is, the smaller the backup size will be. However, it requires higher CPU usage for the compression and decompression process.
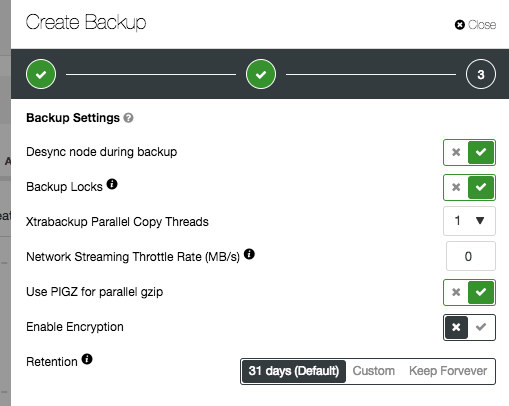
If you would choose xtrabackup as the method for the backup, it would open up extra options: desync, backup locks, compression and xtrabackup parallel threads/gzip. The desync option is only applicable to desync a node from a Galera cluster. Backup locks uses a new MDL lock type to block updates to non-transactional tables and DDL statements for all tables which is more efficient for InnoDB-specific workload. If you are running on Galera Cluster, enabling this option is recommended.
After scheduling an instant backup you can keep track of the progress of the backup job in the Activity > Jobs:
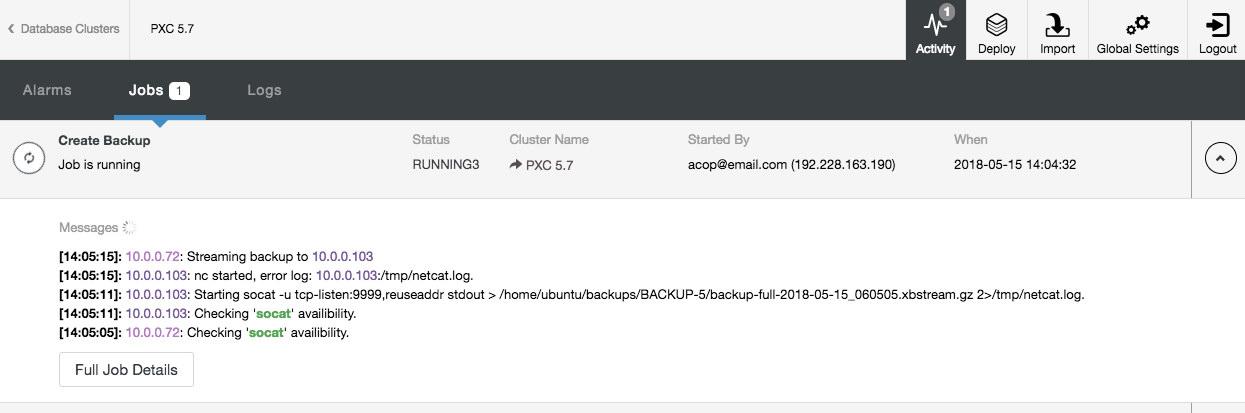
After it has finished, you should be able to see the a new entry under the backup list.
Backing up PostgreSQL
Similar to the instant backups of MySQL, you can run a backup on your Postgres database. With Postgres backups there are two backup methods supported – pg_dumpall or pg_basebackup. Take note that ClusterControl will always perform a full backup regardless of the chosen backup method.
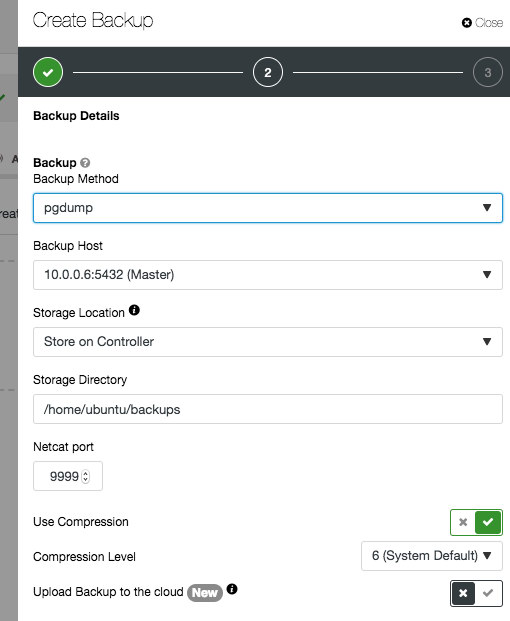
We have covered this aspect in this details in Become a PostgreSQL DBA – Logical & Physical PostgreSQL Backups.
Backing up MongoDB
For MongoDB, ClusterControl supports the standard mongodump and mongodb-consistent-backup developed by Percona. The latter is still in beta version which provides cluster-consistent point-in-time backups of MongoDB suitable for sharded cluster setups. As the sharded MongoDB cluster consists of multiple replica sets, a config replica set and shard servers, it is very difficult to make a consistent backup using only mongodump.
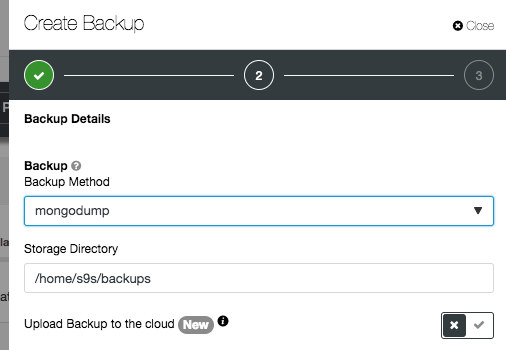
Note that in the wizard, you don’t have to pick a database node to be backed up. ClusterControl will automatically pick the healthiest secondary replica as the backup node. Otherwise, the primary will be selected. When the backup is running, the selected backup node will be locked until the backup process completes.
Scheduling Backups
Now that we have played around with creating instant backups, we now can extend that by scheduling the backups.
The scheduling is very easy to do: you can select on which days the backup has to be made and at what time it needs to run.
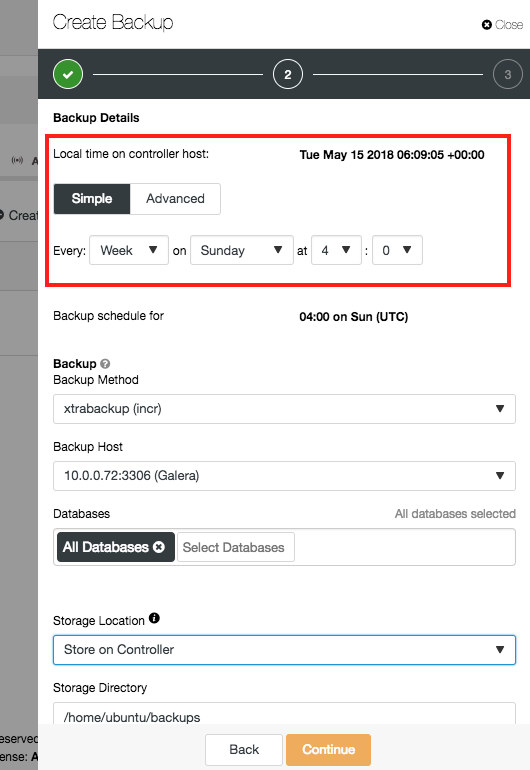
For xtrabackup there is an additional feature: incremental backups. An incremental backup will only backup the data that changed since the last backup. Of course, the incremental backups are useless if there would not be full backup as a starting point. Between two full backups, you can have as many incremental backups as you like. But restoring them will take longer.
Once scheduled the job(s) should become visible under the “Scheduled Backup” tab and you can edit them by clicking on the “Edit” button. Like with the instant backups, these jobs will schedule the creation of a backup and you can keep track of the progress via the Activity tab.
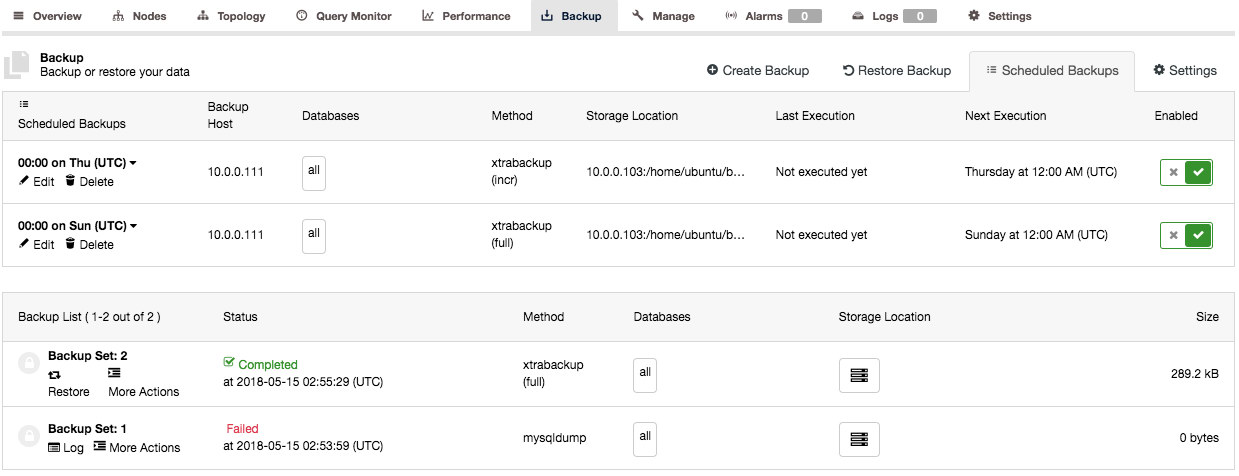
Backup List
You can find the Backup List under ClusterControl > Backup and this will give you a cluster level overview of all backups made. Clicking on each entry will expand the row and expose more information about the backup:
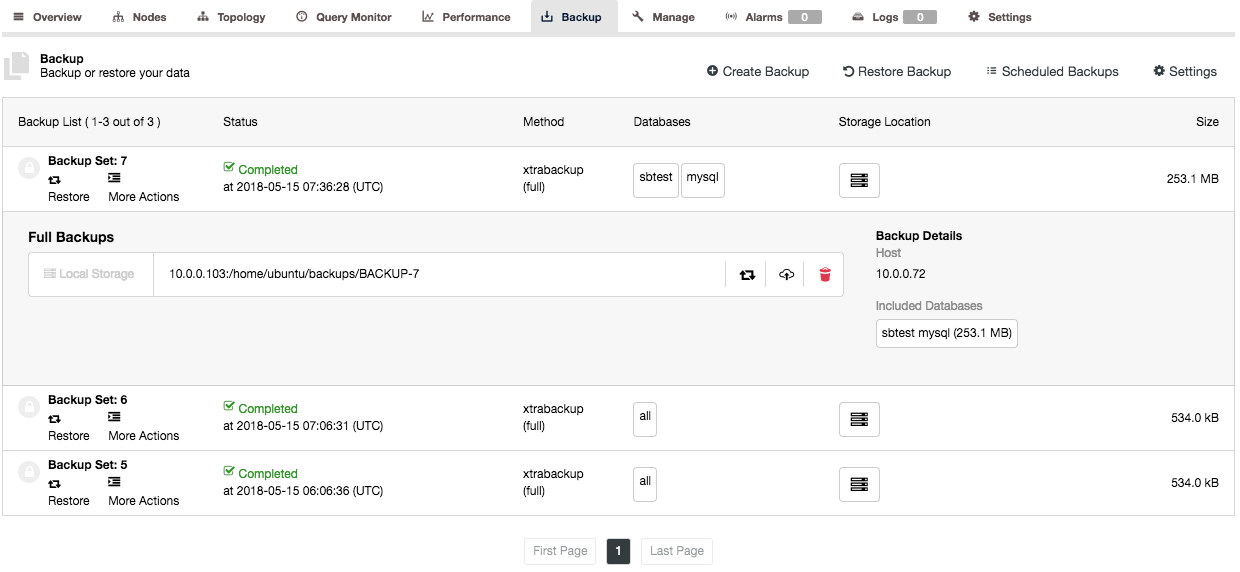
Each backup is accompanied with a backup log when ClusterControl executed the job, which is available under “More Actions” button.
Offsite Backup in Cloud
Since we have now a lot of backups stored on either the database hosts or the ClusterControl host, we also want to ensure they don’t get lost in case we face a total infrastructure outage. (e.g. DC on fire or flooded) Therefore ClusterControl allows you to store or copy your backups offsite on cloud. The supported cloud platforms are Amazon S3, Google Cloud Storage and Azure Cloud Storage.
The upload process happens right after the backup is successfully created (if you toggle “Upload Backup to the Cloud”) or you can manually click on the cloud icon button of the backup list:
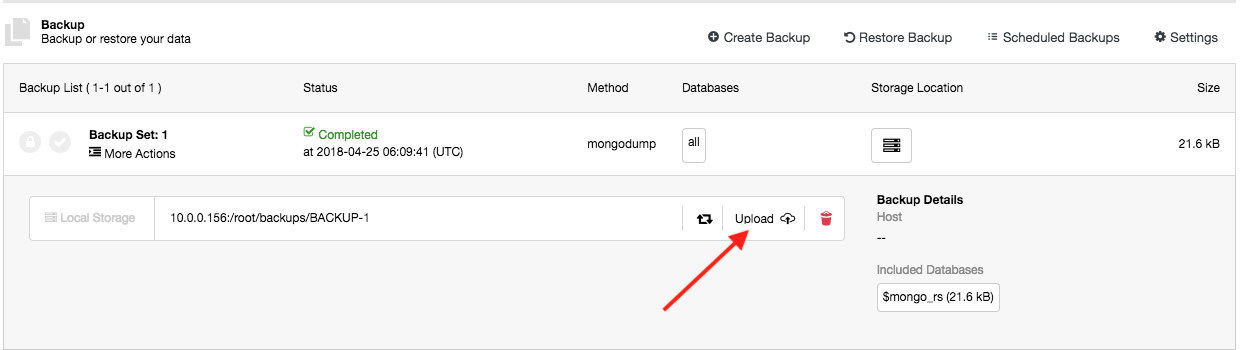
Choose the cloud credential and specify the backup location accordingly:
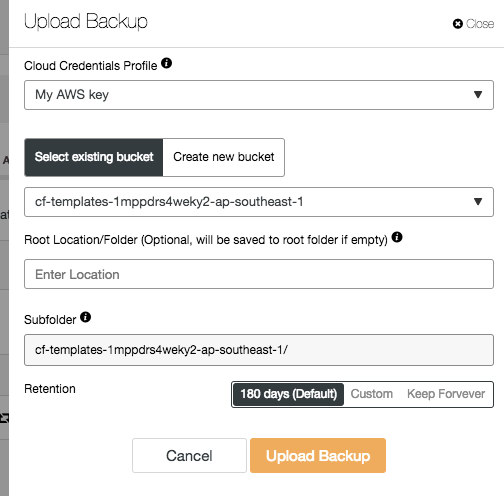
Restore and/or Verify Backup
From the Backup List interface, you can directly restore a backup to a host in the cluster by clicking on the “Restore” button for the particular backup or click on the “Restore Backup” button:
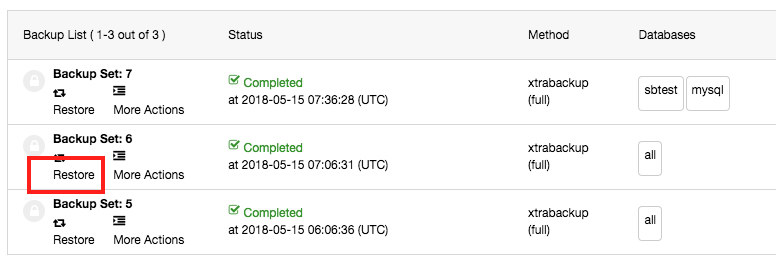
One nice feature is that it is able to restore a node or cluster using the full and incremental backups as it will keep track of the last full backup made and start the incremental backup from there. Then it will group a full backup together with all incremental backups till the next full backup. This allows you to restore starting from the full backup and applying the incremental backups on top of it.
ClusterControl supports restore on an existing database node or restore and verify on a new standalone host:
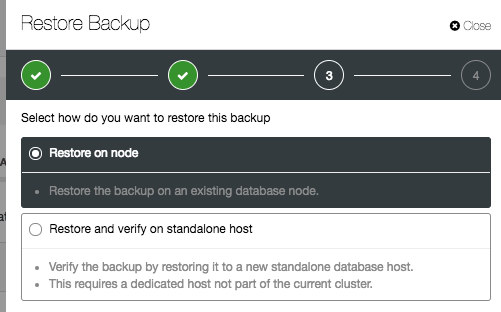
These two options are pretty similar, except the verify one has extra options for the new host information. If you follow the restoration wizard, you will need to specify a new host. If “Install Database Software” is enabled, ClusterControl will remove any existing MySQL installation on the target host and reinstall the database software with the same version as the existing MySQL server.
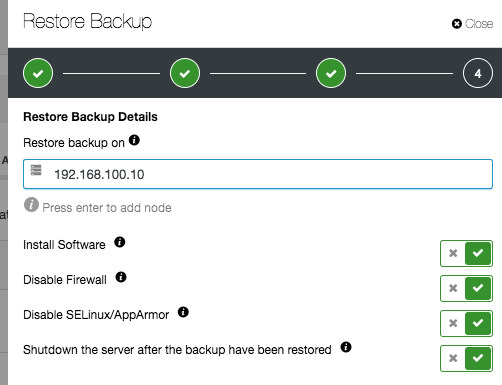
Once the backup is restored and verified, you will receive a notification on the restoration status and the node will be shut down automatically.
Point-in-Time Recovery
For MySQL, both xtrabackup and mysqldump can be used to perform point-in-time recovery and also to provision a new replication slave for master-slave replication or Galera Cluster. A mysqldump PITR-compatible backup contains one single dump file, with GTID info, binlog file and position. Thus, only the database node that produces binary log will have the “PITR compatible” option available:
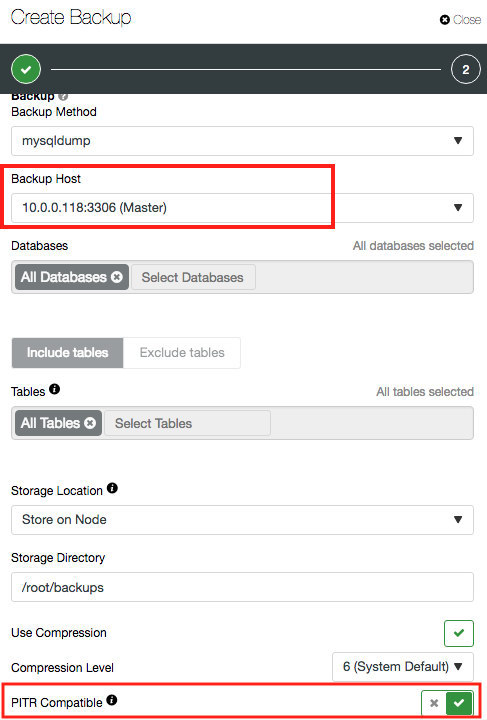
When PITR compatible option is toggled, the database and table fields are greyed out since ClusterControl will always perform a full backup against all databases, events, triggers and routines of the target MySQL server.
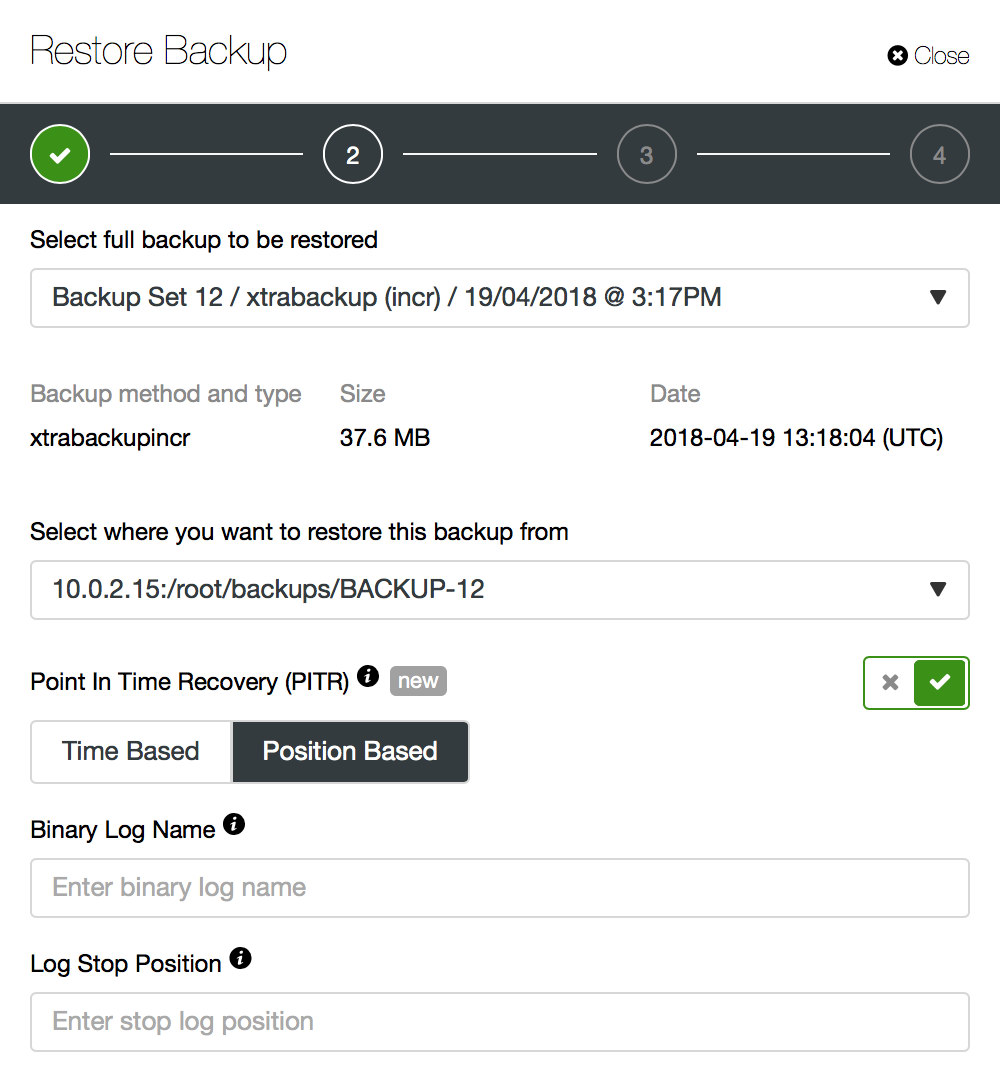
Now restoring the backup. If the backup is compatible with PITR, an option will be presented to perform a Point-In-Time Recovery. You will have two options for that – “Time Based” and “Position Based”. For “Time Based”, you can just pass the day and time. For “Position Based”, you can pass the exact position to where you want to restore. It is a more precise way to restore, although you might need to get the binlog position using the mysqlbinlog utility. More details about point in time recovery can be found in this blog.
Backup Encryption
Universally, ClusterControl supports backup encryption for MySQL, MongoDB and PostgreSQL. Backups are encrypted at rest using AES-256 CBC algorithm. An auto generated key will be stored in the cluster’s configuration file under /etc/cmon.d/cmon_X.cnf (where X is the cluster ID):
$ sudo grep backup_encryption_key /etc/cmon.d/cmon_1.cnf
backup_encryption_key='JevKc23MUIsiWLf2gJWq/IQ1BssGSM9wdVLb+gRGUv0='If the backup destination is not local, the backup files are transferred in encrypted format. This feature complements the offsite backup on cloud, where we do not have full access to the underlying storage system.
Final Thoughts
We showed you how to get your data backed up and how to store them safely off site. Recovery is always a different thing. ClusterControl can recover automatically your databases from the backups made in the past that are stored on premises or copied back from the cloud.
Obviously there is more to securing your data, especially on the side of securing your connections. We will cover this in the next blog post!



