blog
How to do Point-in-Time Recovery of MySQL & MariaDB Data Using ClusterControl

Backups are crucial when it comes to safety of data. They are the ultimate disaster recovery solution – you have no database nodes reachable and your datacenter could literally have gone up in smoke, but as long as you have a backup of your data, you can still recover from such situation.
Typically, you will use backups to recover from different types of cases:
- accidental DROP TABLE or DELETE without a WHERE clause, or with a WHERE clause that was not specific enough.
- a database upgrade that fails and corrupts the data
- storage media failure/corruption
Is restoring from backup not enough? What does it have to be point-in-time? We have to keep in mind that a backup is a snapshot of data taken at a given point in time. If you take a backup at 1:00 am and a table was removed accidently at 11:00 am, you can restore your data up to 1:00 am but what about changes which happened between 1:00 am and 11:00 am? Those changes would be lost unless you can replay modifications that happened in between. Luckily, MySQL has such a mechanism for storing changes – binary logs. You may know those logs are used for replication – MySQL uses them to store all of the changes which happened on the master, and a slave uses them to replay those changes and apply them to its dataset. As the binlogs store all of the changes, you can also use them to replay traffic. In this blog post, we will take a look at how ClusterControl can help you perform Point-In-Time Recovery (PITR).
Creating Backup Compatible With Point-In-Time Recovery
First of all, let’s talk about prerequisites. A host where you take backups from has to have binary logs enabled. Without them, PITR is not possible. Second requirement – a host where you take backups from should have all the binary logs required in order to restore to a given point in time. If you use too aggressive binary log rotation, this could become a problem.
So, let us see how to use this feature in ClusterControl. First of all, you have to take a backup which is compatible with PITR. Such backup has to be full, complete and consistent. For xtrabackup, as long it contains full dataset (you didn’t include just a subset of schemas), it will be PITR-compatible.
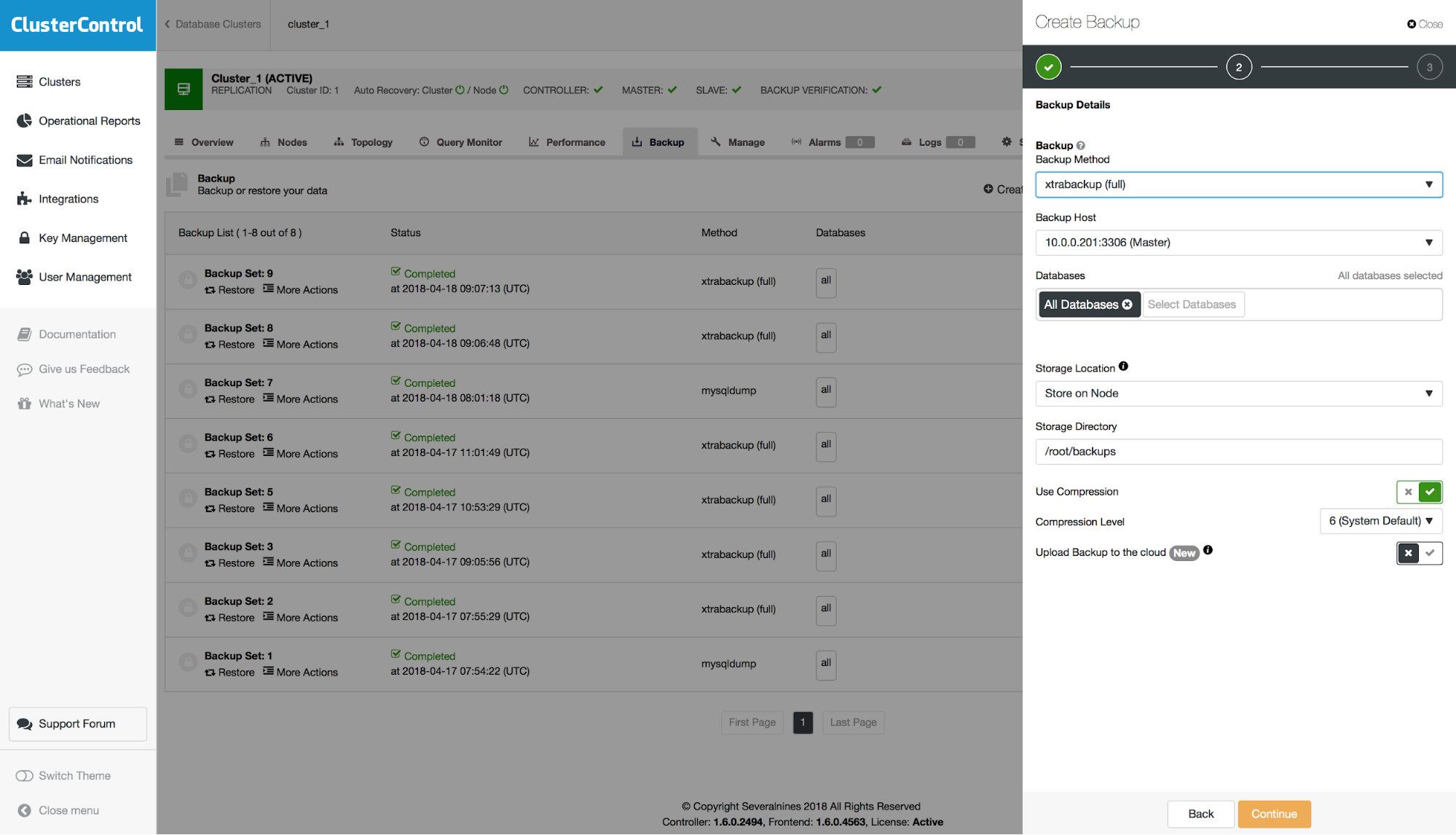
For mysqldump, there is an option to make it PITR-compatible. When you enable this option, all necessary options will be configured (for example, you won’t be able to pick separate schemas to include in the dump) and backup will be marked as available for point-in-time recovery.
Point-In-Time Recovery From a Backup
First, you have to pick a backup to restore.
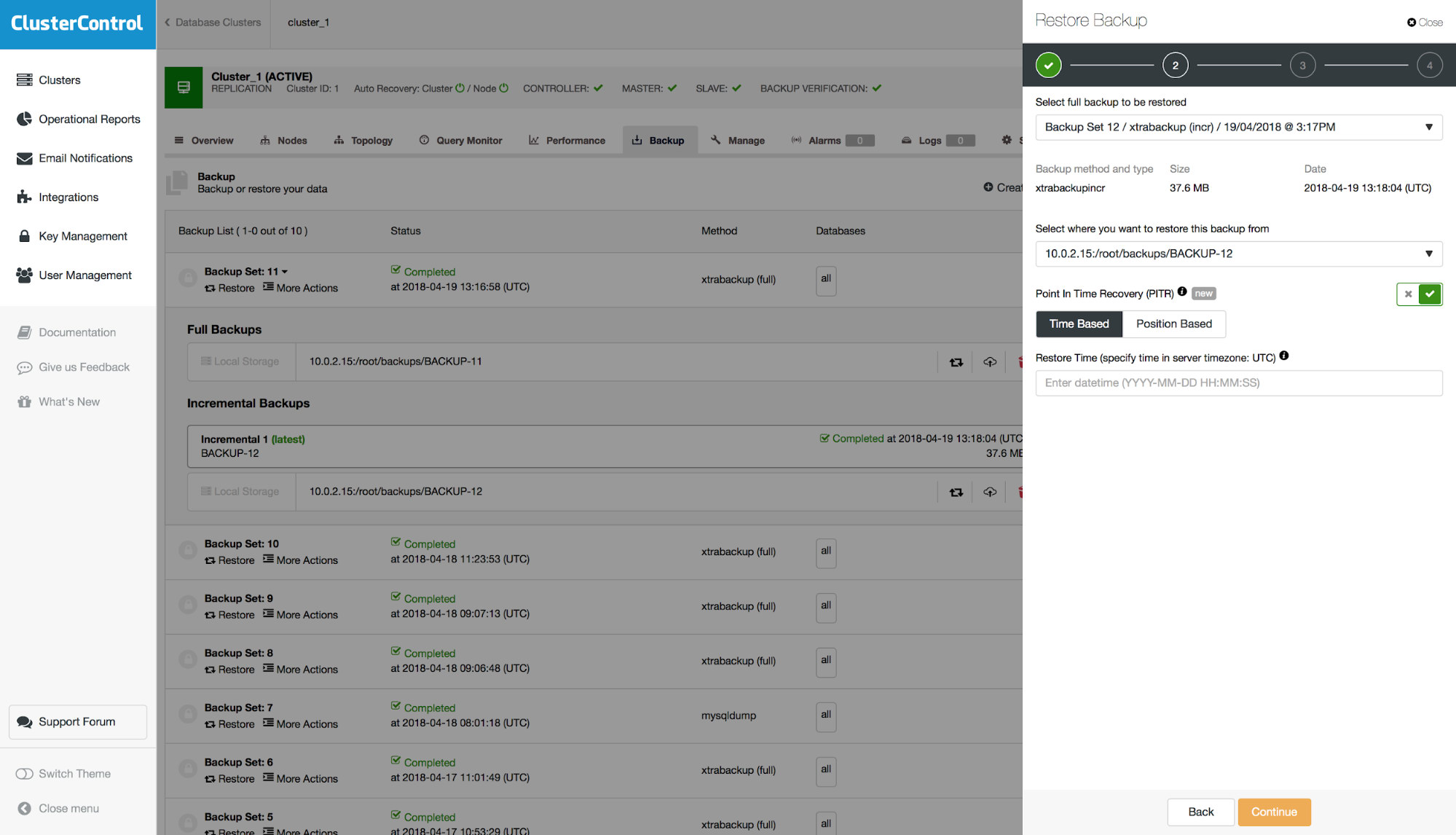
If the backup is compatible with PITR, an option will be presented to perform a Point-In-Time Recovery. You will have two options for that – “Time Based” and “Position Based”. Let’s discuss the difference between those two options.
“Time Based” PITR
With this option you can pass a date and time, up to which the backup should be restored. It can be defined within one second resolution. It does not guarantee that all of the data will be restored because, even if you are very precise in defining the time, during one second multiple events could be recorded in the binary log. Let’s say that you know that the data loss happened on 18th of April, at 10:00:01. You pass the following date and time to the form: ‘2018-04-18 10:00:00’. Please keep in mind that you should be using a time that is based on the timezone settings on the database server on which the backup was created.
It still may happen that the data loss even wasn’t the first one which happened at 10:00:01 so some of the events will be lost in the process. Let’s look at what that means.
During one second, multiple events may be logged in binlogs. Let’s consider such case:
10:00:00 – events A,B,C,D,E,F
10:00:01 – events V,W,X,Y,Z
where X is the data loss event. With a granularity of a second, you can either restore up to everything which happened at 10:00:00 (so up to F) or up to 10:00:01 (up to Z). The later case is of no use as X would be re-executed. In the former case, we miss V and W.
That’s why position based restore is more precise. You can tell “I want to restore up to W”.
Time based restore is the most precise you can get without having to go to the binary logs and define the exact position to where you want to restore. This leads us to the second method of doing PITR.
“Position Based” PITR
Here some experience with command line tools for MySQL, namely mysqlbinlog utility, is required. On the other hand, you will have the best control over how the recovery will be made.
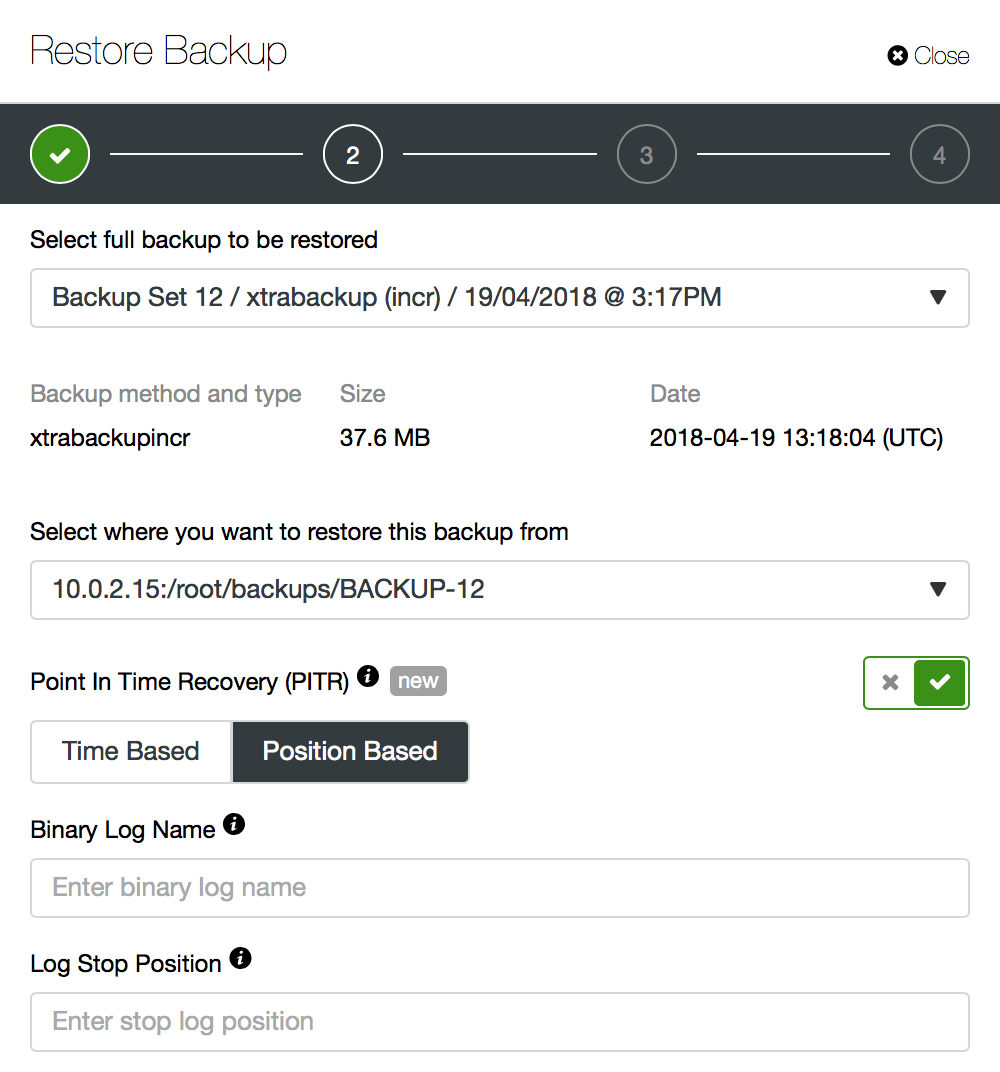
Let’s go through a simple example. As you can see in the screenshot above, you will have to pass a binary log name and binary log position up to which point the backup should be restored. Most of the time, this should be the last position before the data loss event.
Someone executed a SQL command which resulted in a serious data loss:
mysql> DROP TABLE sbtest1;
Query OK, 0 rows affected (0.02 sec)Our application immediately started to complain:
sysbench 1.1.0-ecf1191 (using bundled LuaJIT 2.1.0-beta3)
Running the test with following options:
Number of threads: 2
Report intermediate results every 1 second(s)
Initializing random number generator from current time
Initializing worker threads...
Threads started!
FATAL: mysql_drv_query() returned error 1146 (Table 'sbtest.sbtest1' doesn't exist) for query 'DELETE FROM sbtest1 WHERE id=5038'
FATAL: `thread_run' function failed: /usr/local/share/sysbench/oltp_common.lua:490: SQL error, errno = 1146, state = '42S02': Table 'sbtest.sbtest1' doesn't existWe have a backup but we want to restore all of the data up to that fatal moment. First of all, we assume that the application does not work so we can discard all of the writes which happened after the DROP TABLE as non-important. If your application works to some extent, you would have to merge the remaining changes later on. Ok, let’s examine the binary logs to find the position of the DROP TABLE statement. As we want to avoid parsing all of the binary logs, let’s find what was the position our latest backup covered. You can check that by examining logs for the latest backup set and look for a line similar to this one:
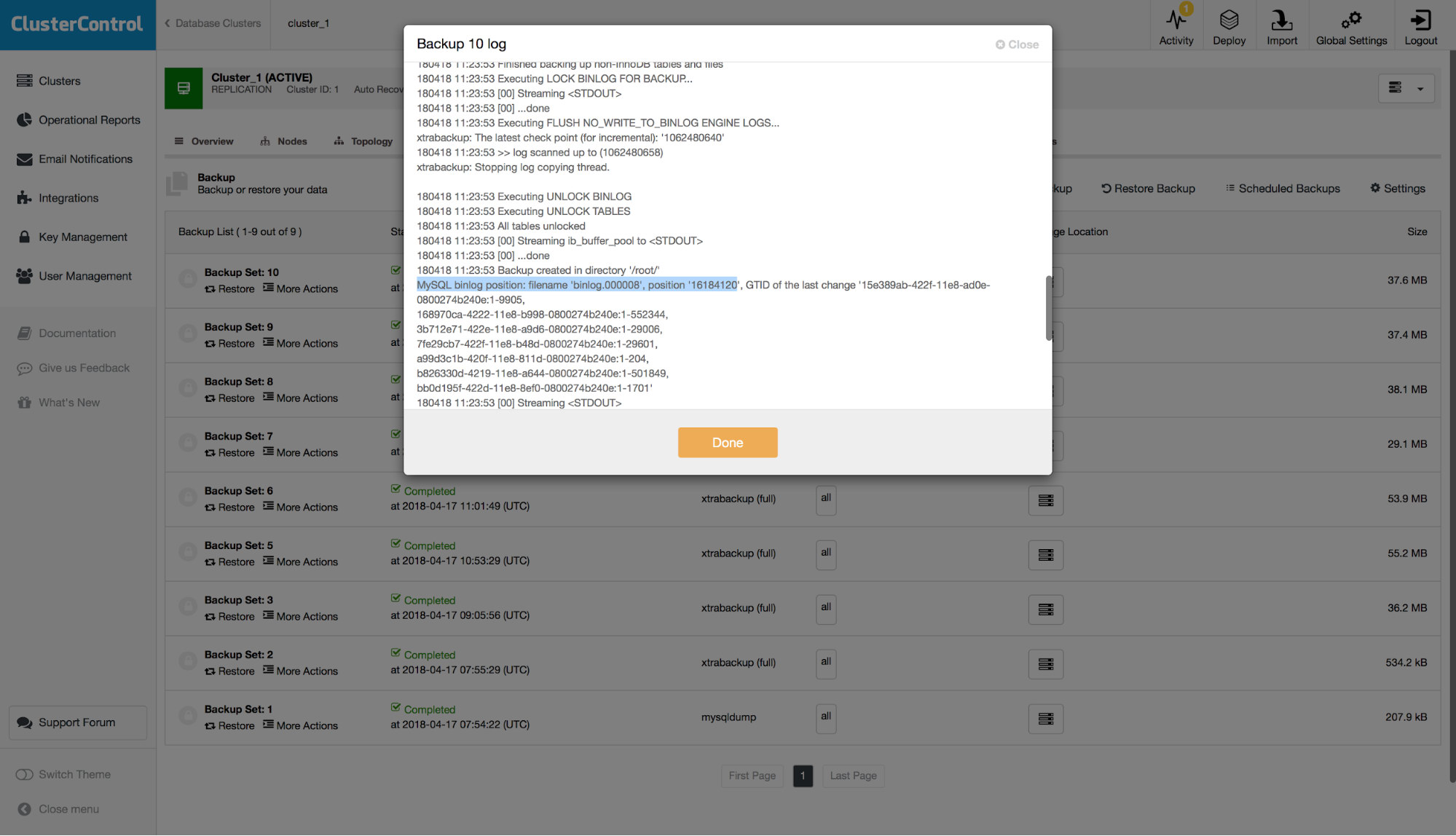
So, we are talking about filename ‘binlog.000008’ and position ‘16184120’. Let’s use this as our starting point. Let’s check what binary log files we have:
root@vagrant:~# ls -alh /var/lib/mysql/binlog.*
-rw-r----- 1 mysql mysql 58M Apr 17 08:31 /var/lib/mysql/binlog.000001
-rw-r----- 1 mysql mysql 116M Apr 17 08:59 /var/lib/mysql/binlog.000002
-rw-r----- 1 mysql mysql 379M Apr 17 09:30 /var/lib/mysql/binlog.000003
-rw-r----- 1 mysql mysql 344M Apr 17 10:54 /var/lib/mysql/binlog.000004
-rw-r----- 1 mysql mysql 892K Apr 17 10:56 /var/lib/mysql/binlog.000005
-rw-r----- 1 mysql mysql 74M Apr 17 11:03 /var/lib/mysql/binlog.000006
-rw-r----- 1 mysql mysql 5.2M Apr 17 11:06 /var/lib/mysql/binlog.000007
-rw-r----- 1 mysql mysql 21M Apr 18 11:35 /var/lib/mysql/binlog.000008
-rw-r----- 1 mysql mysql 59K Apr 18 11:35 /var/lib/mysql/binlog.000009
-rw-r----- 1 mysql mysql 144 Apr 18 11:35 /var/lib/mysql/binlog.indexSo, in addition to ‘binlog.000008’ we also have ‘binlog.000009’ to examine. Let’s run the command which will convert binary logs into SQL format starting from the position we found in the backup log:
root@vagrant:~# mysqlbinlog --start-position='16184120' --verbose /var/lib/mysql/binlog.000008 /var/lib/mysql/binlog.000009 > binlog.outPlease node ‘–verbose’ is required to decode row-based events. This is not necessarily required for the DROP TABLE we are looking for, but for other type of events it may be needed.
Let’s search our output for the DROP TABLE query:
root@vagrant:~# grep -B 7 -A 1 "DROP TABLE" binlog.out
# at 20885489
#180418 11:24:32 server id 1 end_log_pos 20885554 CRC32 0xb89f2e66 GTID last_committed=38168 sequence_number=38170 rbr_only=no
SET @@SESSION.GTID_NEXT= '7fe29cb7-422f-11e8-b48d-0800274b240e:38170'/*!*/;
# at 20885554
#180418 11:24:32 server id 1 end_log_pos 20885678 CRC32 0xb38a427b Query thread_id=54 exec_time=0 error_code=0
use `sbtest`/*!*/;
SET TIMESTAMP=1524050672/*!*/;
DROP TABLE `sbtest1` /* generated by server */
/*!*/;In this sample we can see two events. First, at the position of 20885489, sets GTID_NEXT variable.
# at 20885489
#180418 11:24:32 server id 1 end_log_pos 20885554 CRC32 0xb89f2e66 GTID last_committed=38168 sequence_number=38170 rbr_only=no
SET @@SESSION.GTID_NEXT= '7fe29cb7-422f-11e8-b48d-0800274b240e:38170'/*!*/;Second, at the position of 20885554 is our DROP TABLE event. This leads to the conclusion that we should perform the PITR up to the position of 20885489. The only question to answer is which binary log we are talking about. We can check that by searching for binlog rotation entries:
root@vagrant:~# grep "Rotate to binlog" binlog.out
#180418 11:35:46 server id 1 end_log_pos 21013114 CRC32 0x2772cc18 Rotate to binlog.000009 pos: 4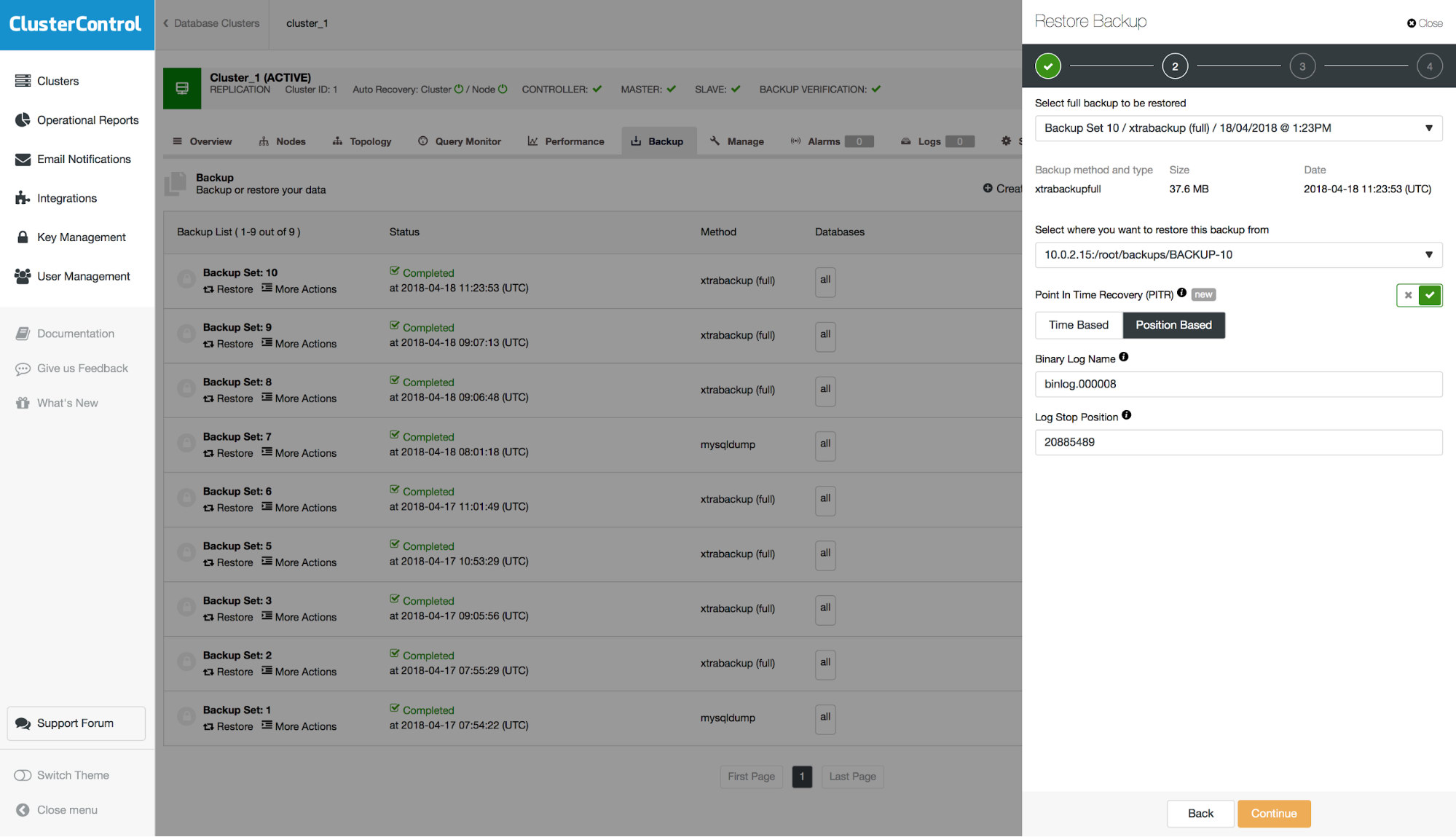
As it can be clearly seen by comparing dates, rotation to binlog.000009 happened later therefore we want to pass binlog.000008 as the binlog file in the form.
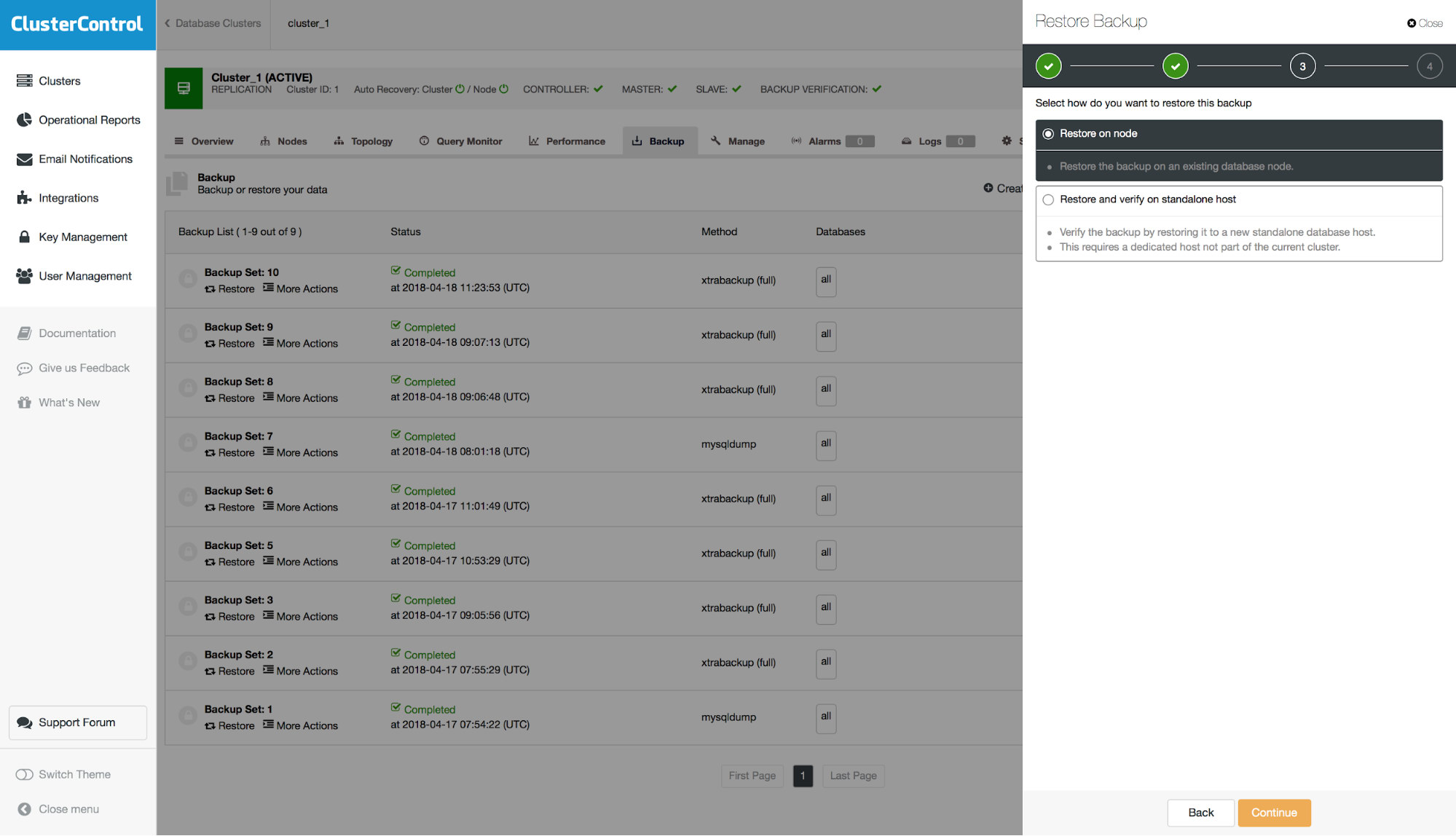
Next, we have to decide if we are going to restore the backup on the cluster or do we want to use external server to restore it. This second option could be useful if you want to restore just a subset of data. You can restore full physical backup on a separate host and then use mysqldump to dump the missing data and load it up on the production server.
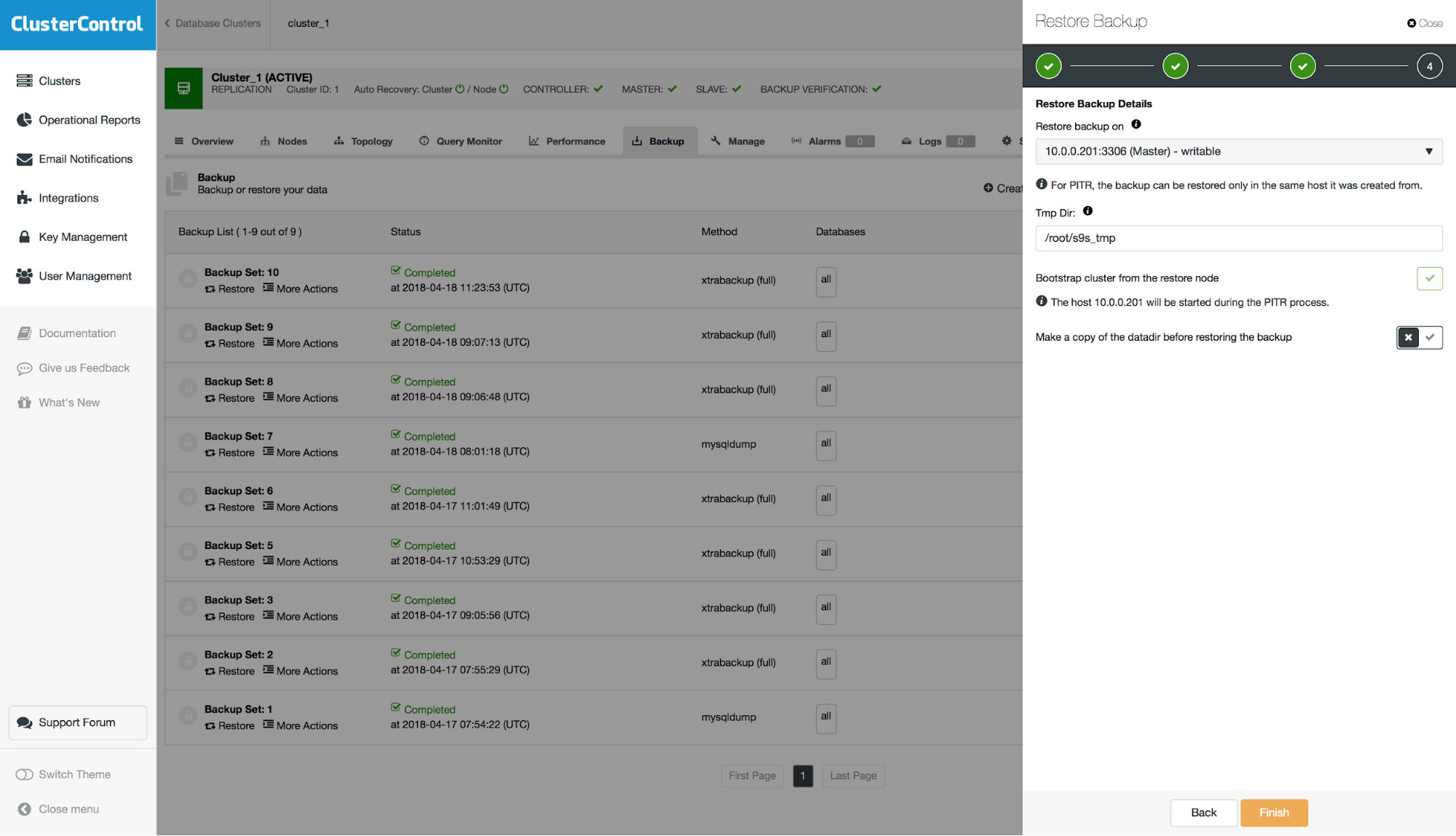
Keep in mind that when you restore the backup on your cluster, you will have to rebuild nodes other than the one you recovered. In master – slave scenario you will typically want to restore backup on the master and then rebuild slaves from it.
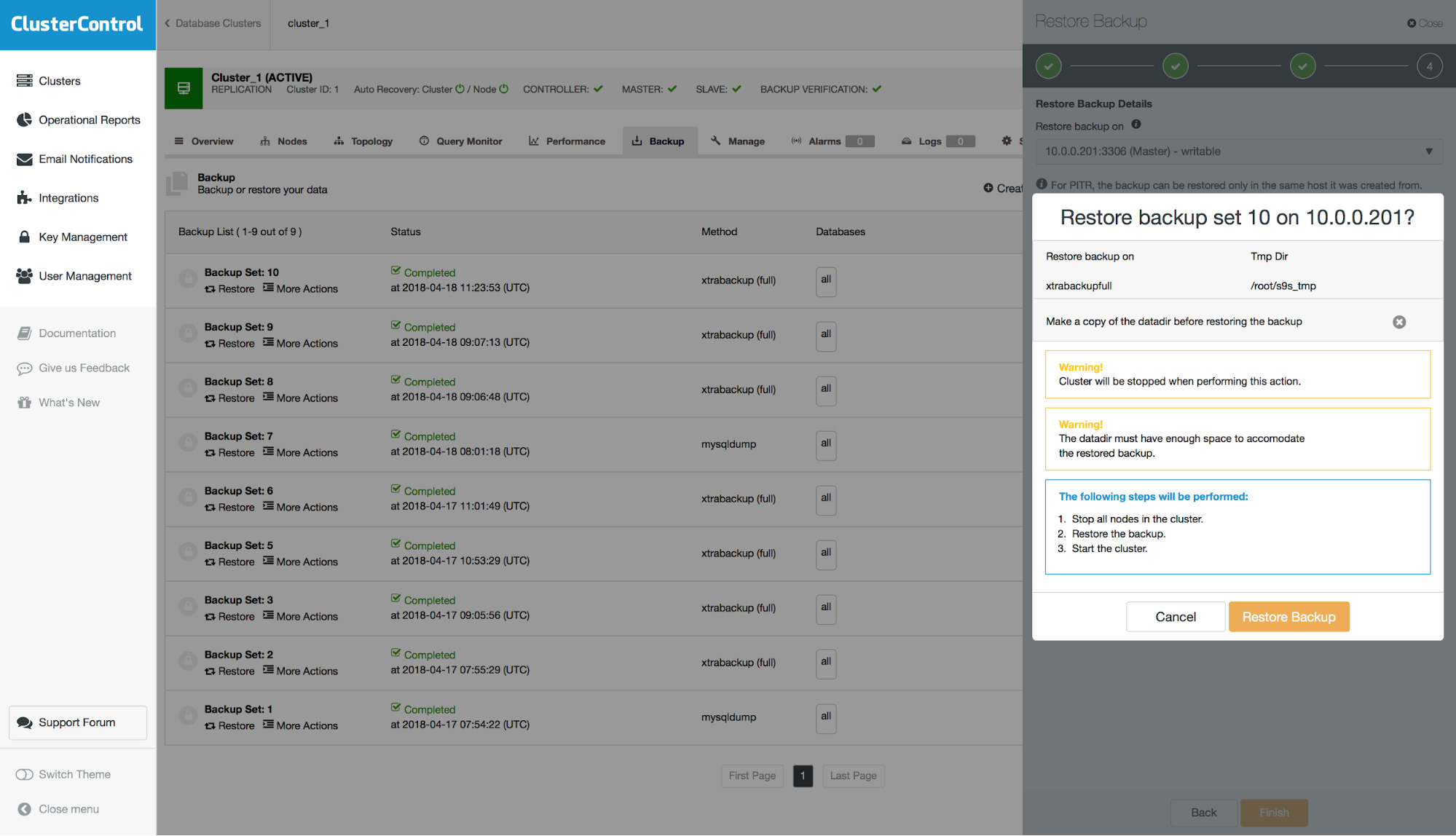
As a last step, you will see a summary of actions ClusterControl will take.
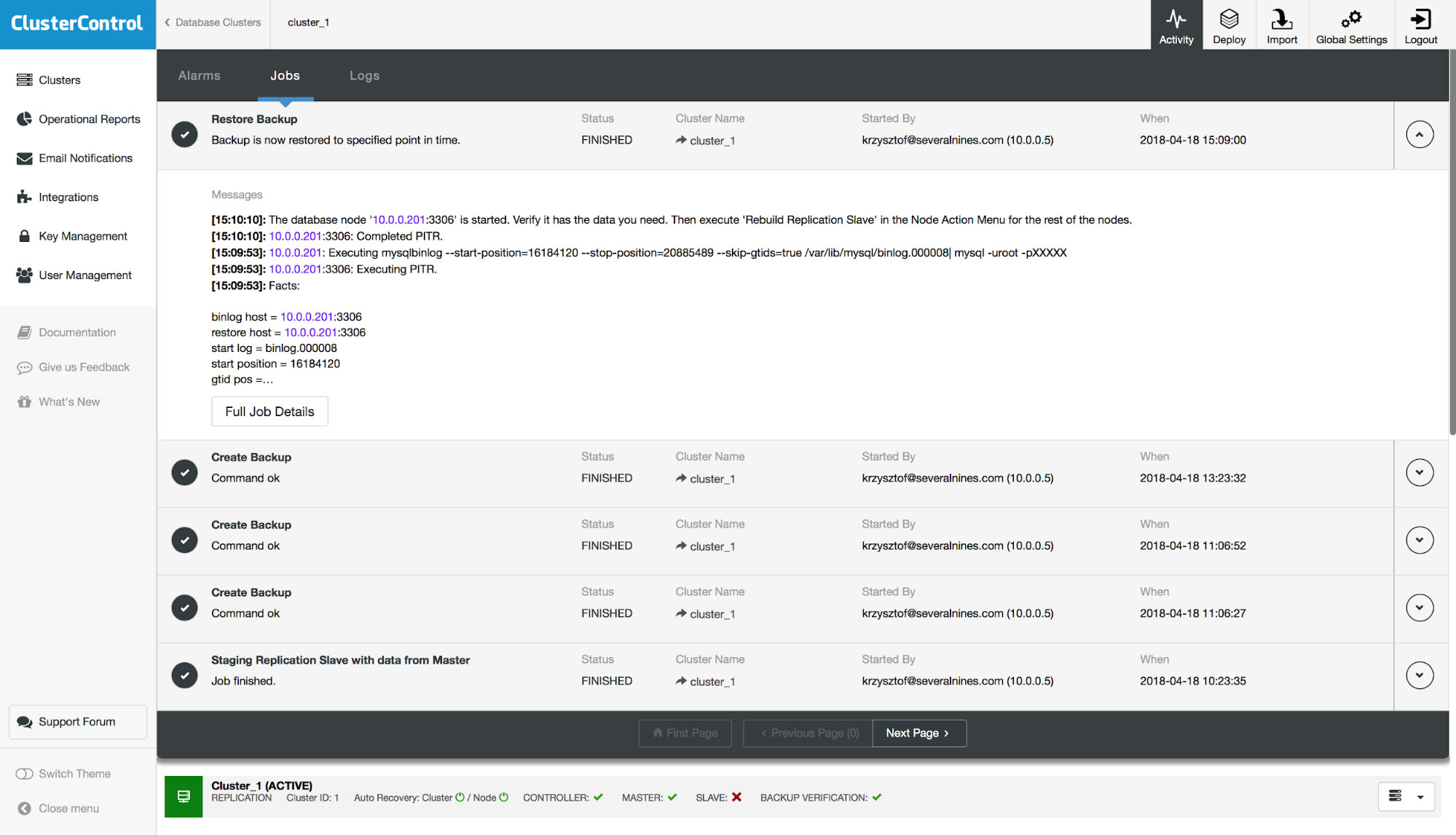
Finally, after the backup was restored, we will test if the missing table has been restored or not:
mysql> show tables from sbtest like 'sbtest1'G
*************************** 1. row ***************************
Tables_in_sbtest (sbtest1): sbtest1
1 row in set (0.00 sec)Everything seems ok, we managed to restore missing data.
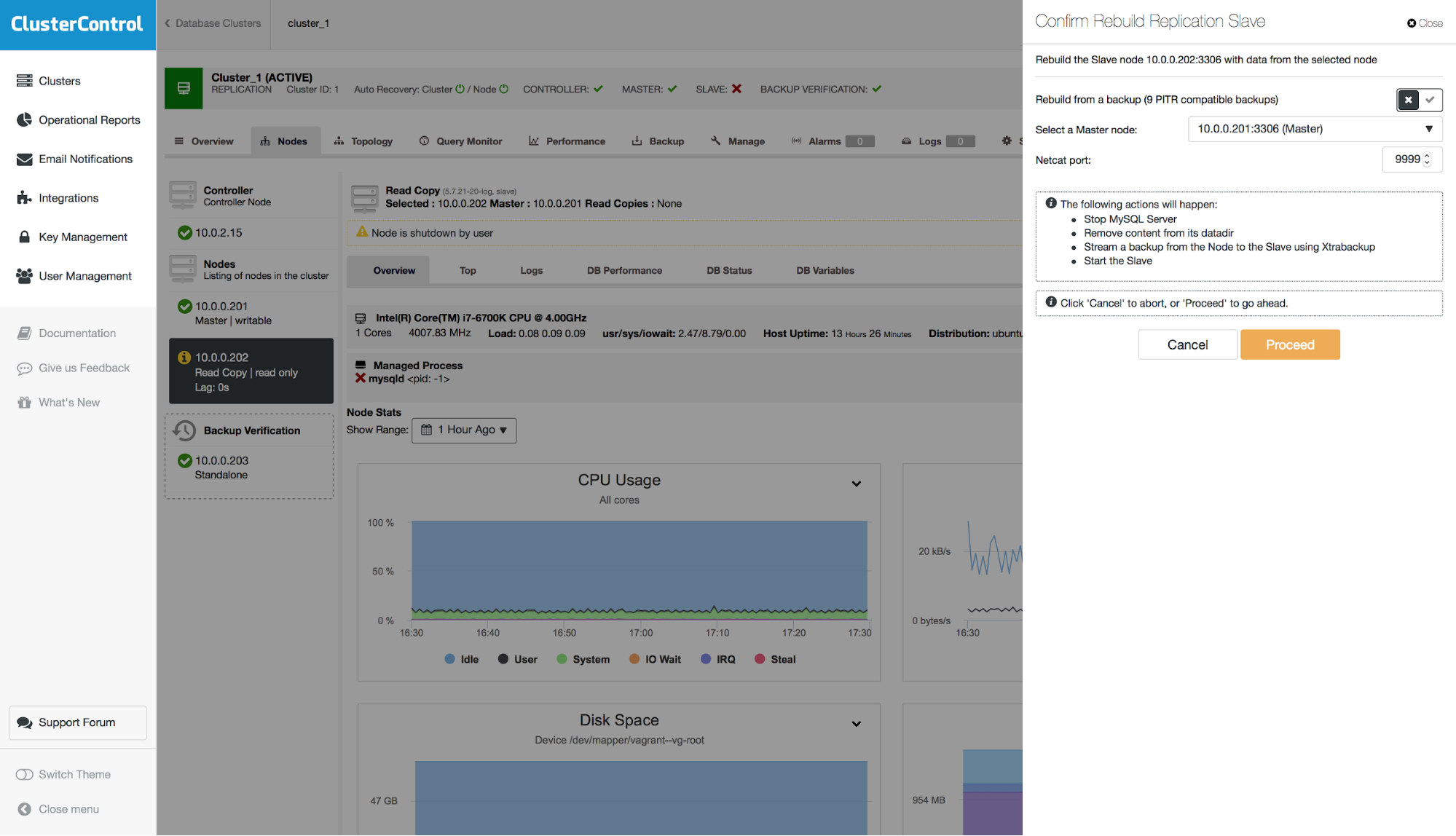
The last step we have to take is to rebuild our slave. Please note that there is an option to use a PITR backup. In the example here, this is not possible as the slave would replicate the DROP TABLE event and it would end up not being consistent with the master.



