blog
Hybrid OLTP/Analytics Database Workloads in Galera Cluster Using Asynchronous Slaves

Using Galera cluster is a great way of building a highly available environment for MySQL or MariaDB. It is a shared-nothing cluster environment which can be scaled even beyond 12-15 nodes. Galera has some limitations, though. It shines in low-latency environments and even though it can be used across WAN, the performance is limited by network latency. Galera performance can also be impacted if one of the nodes starts to behave incorrectly. For example, excessive load on one of the nodes may slow it down, resulting in slower handling of the writes and that will impact all of the other nodes in the cluster. On the other hand, it is quite impossible to run a business without analyzing your data. Such analysis, typically, requires running heavy queries, which is quite different from an OLTP workload. In this blog post, we will discuss an easy way of running analytical queries for data stored in Galera Cluster for MySQL or MariaDB, in a way that it does not impact the performance of the core cluster.
How to run Analytical Queries on Galera Cluster?
As we stated, running long running queries directly on a Galera cluster is doable, but perhaps not so good idea. Hardware-dependant, this can be acceptable solution (if you use strong hardware and you will not run a multi-threaded analytical workload) but even if CPU utilization will not be a problem, the fact that one of the nodes will have mixed workload (OLTP and OLAP) will alone pose some performance challenges. OLAP queries will evict data required for your OLTP workload from the buffer pool, and this will slow down your OLTP queries. Luckily, there is a simple yet efficient way of separating analytical workload from regular queries – an asynchronous replication slave.
Replication slave is a very simple solution – all you need is just another host which can be provisioned and asynchronous replication has to be configured from Galera Cluster to that node. With asynchronous replication, the slave will not impact the rest of the cluster in any way. No matter if it is heavily loaded, uses different (less powerful) hardware, it will just continue replicating from the core cluster. The worst case scenario is that the replication slave will start lagging behind but then it is up to you to implement multi-threaded replication or, eventually to scale up the replication slave.
Once the replication slave is up and running, you should run the heavier queries on it and offload the Galera cluster. This can be done in multiple ways, depending on your setup and environment. If you use ProxySQL, you can easily direct queries to the analytical slave based on the source host, user, schema or even the query itself. Otherwise it will be up to your application to send analytical queries to the correct host.
Setting up a replication slave is not very complex but it still can be tricky if you are not proficient with MySQL and tools like xtrabackup. The whole process would consist of setting up the repository on a new server and installing the MySQL database. Then you will have to provision that host using data from Galera cluster. You can use xtrabackup for that but other tools like mydumper/myloader or even mysqldump will work as well (as long as you execute them correctly). Once the data is there, you will have to setup the replication between a master Galera node and the replication slave. Finally, you would have to reconfigure your proxy layer to include the new slave and route the traffic towards it or make tweaks in how your application connects to the database in order to redirect some of the load to the replication slave.
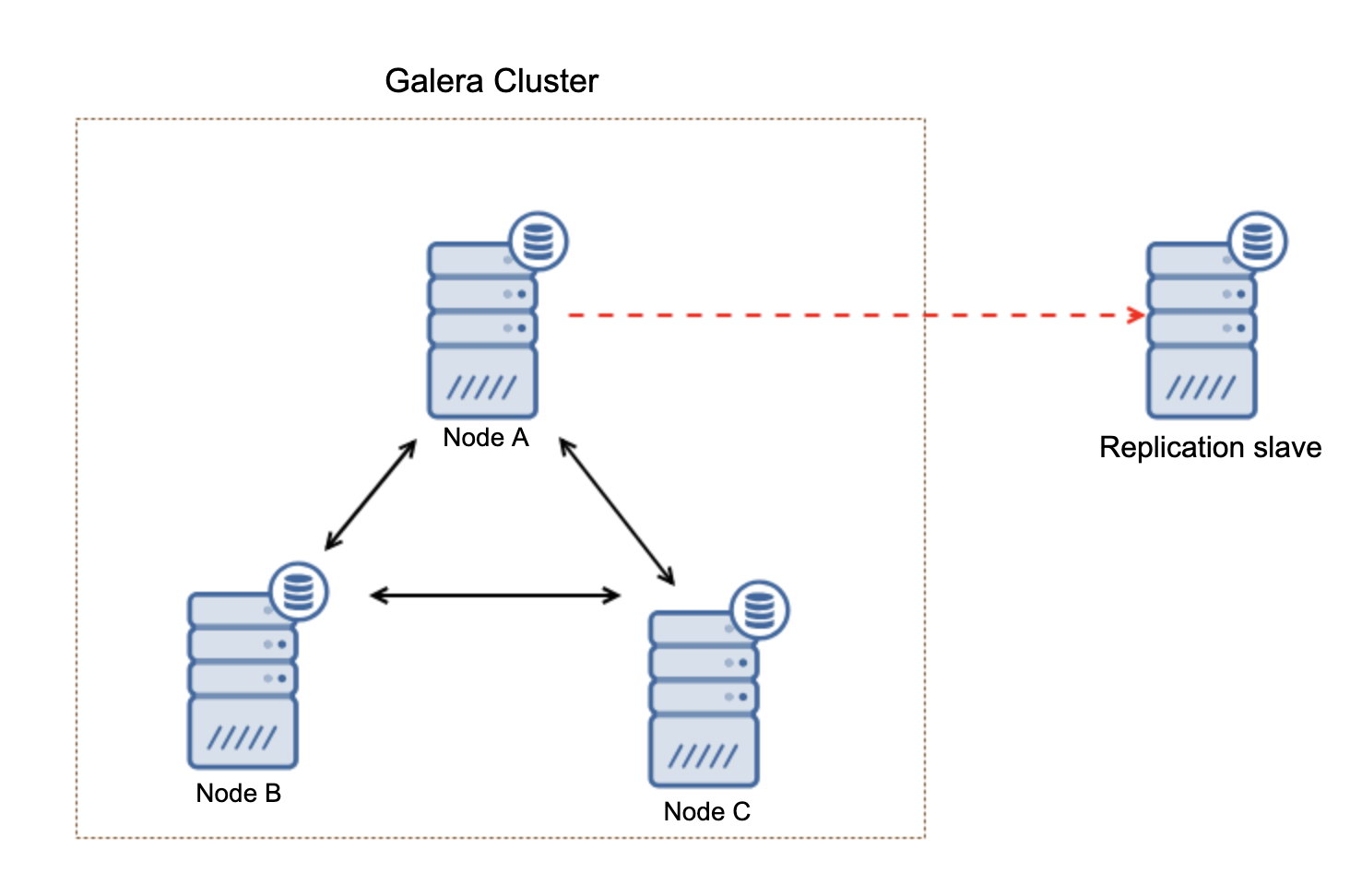
What is important to keep in mind, this setup is not resilient. If the “master” Galera node would go down, the replication link will be broken and it will take a manual action to slave the replica off another master node in the Galera cluster.
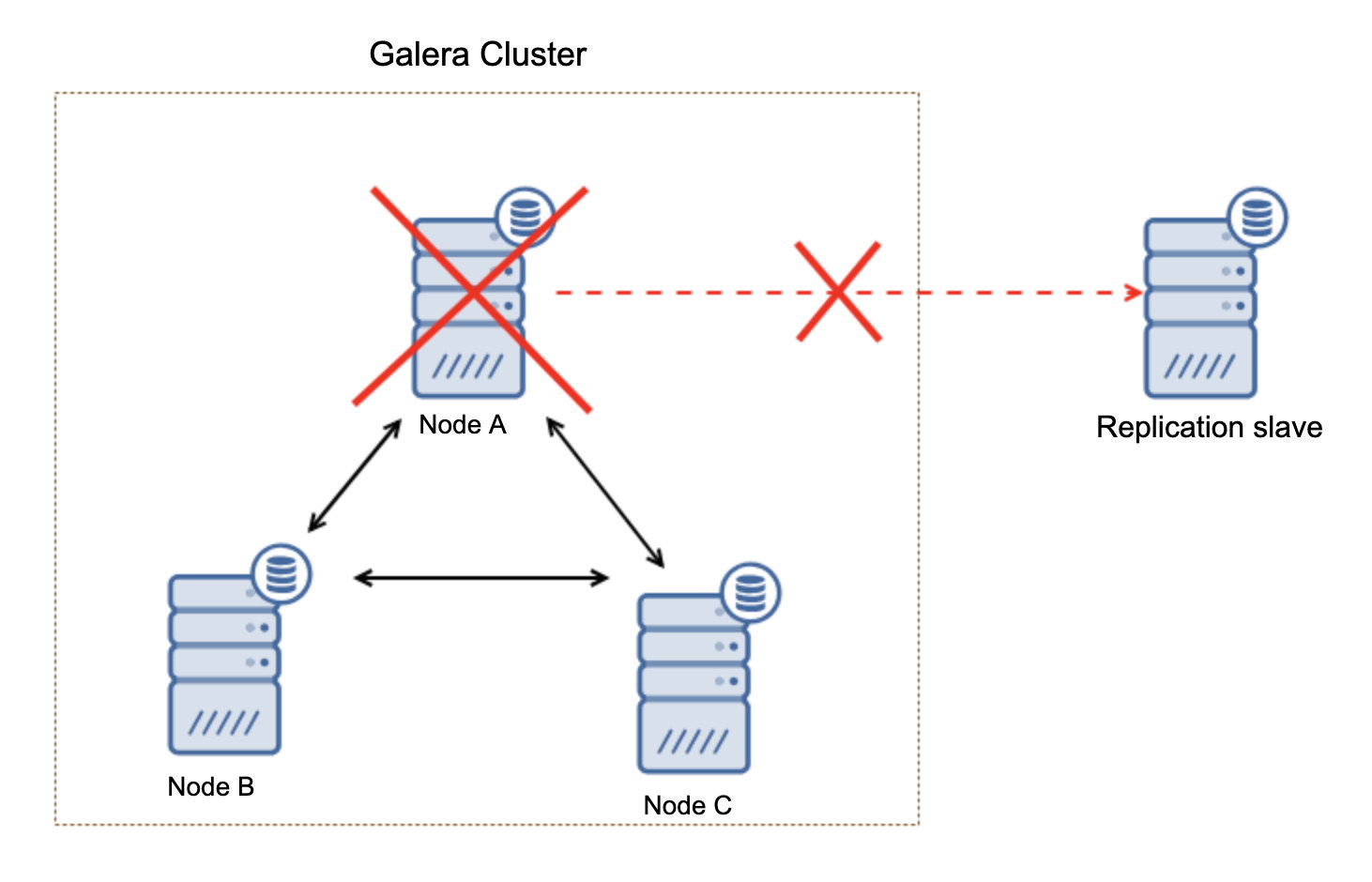
This is not a big deal, especially if you use replication with GTID (Global Transaction ID) but you have to identify that the replication is broken and then take the manual action.
How to set up the asynchronous slave to Galera Cluster using ClusterControl?
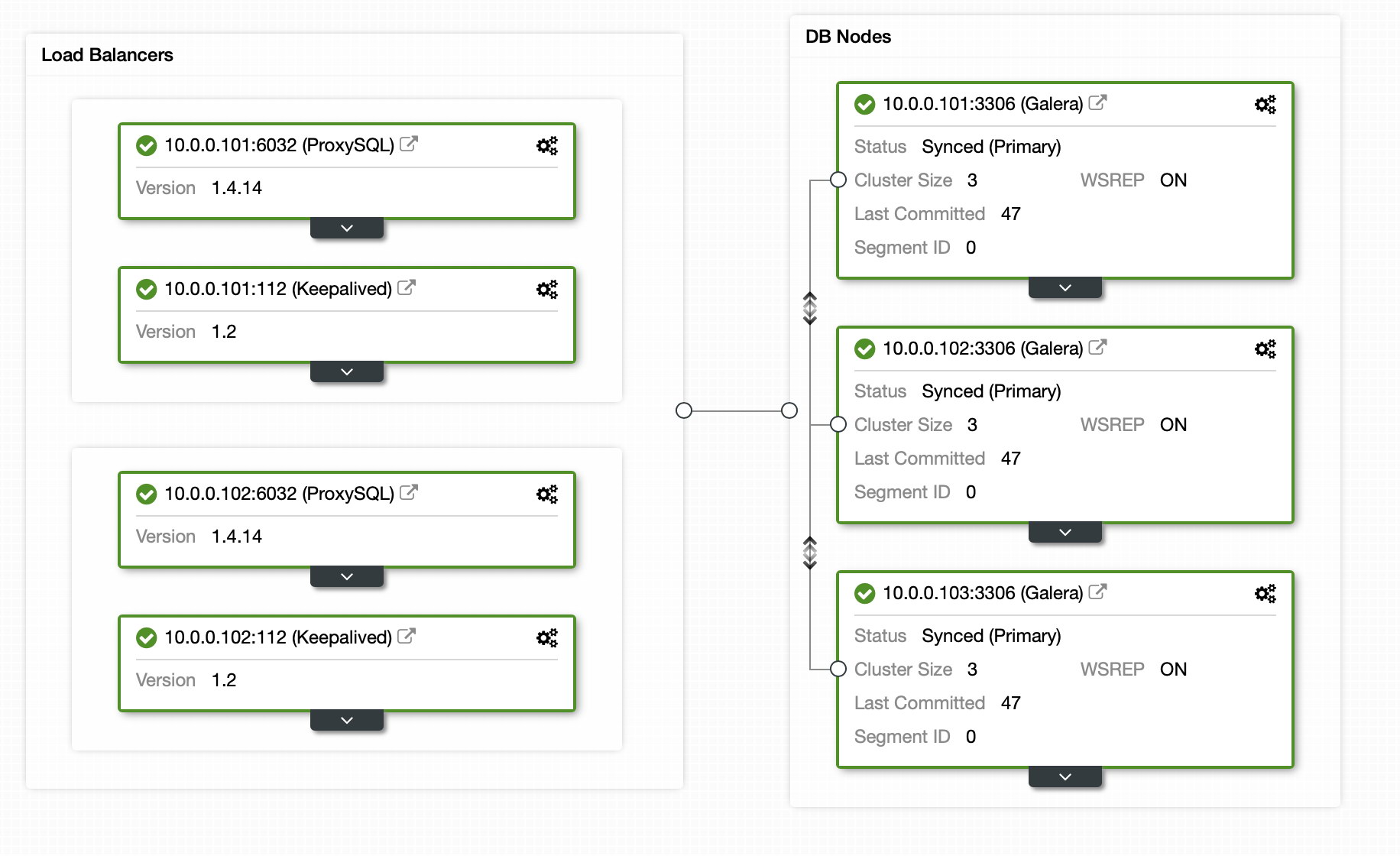
Luckily, if you use ClusterControl, the whole process can be automated and it requires just a handful of clicks. The initial state has already been set up using ClusterControl – a 3 node Galera cluster with 2 ProxySQL nodes and 2 Keepalived nodes for high availability of both database and proxy layer.
Adding the replication slave is just a click away:
Replication, obviously, requires binary logs to be enabled. If you do not have binlogs enabled on your Galera nodes, you can do it also from the ClusterControl. Please keep in mind that enabling binary logs will require a node restart to apply the configuration changes.
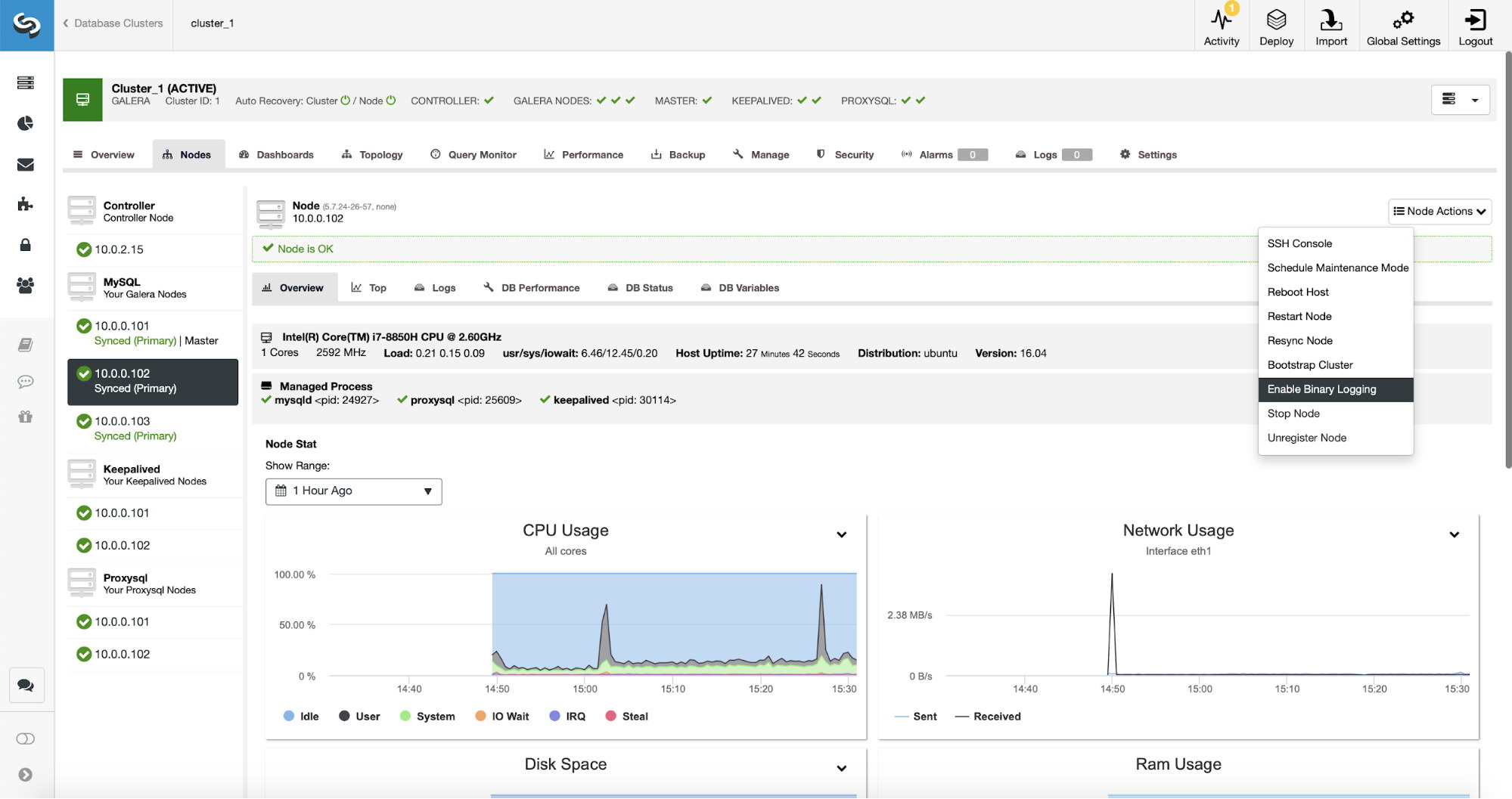
Even if one node in the cluster has binary logs enabled (marked as “Master” on the screenshot above), it’s still good to enable binary log on at least one more node. ClusterControl can automatically failover the replication slave after it detects that the master Galera node crashed, but for that, another master node with binary logs enabled is required or it won’t have anything to fail over to.
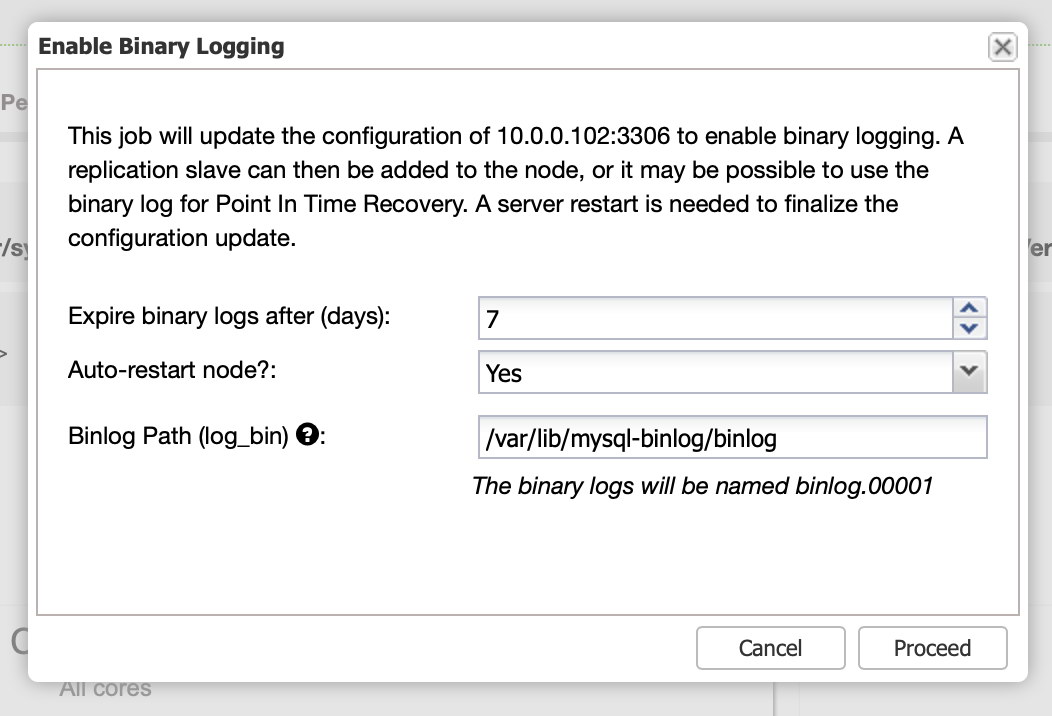
As we stated, enabling binary logs requires restart. You can either perform it straight away, or just make the configuration changes and perform the restart at some other time.
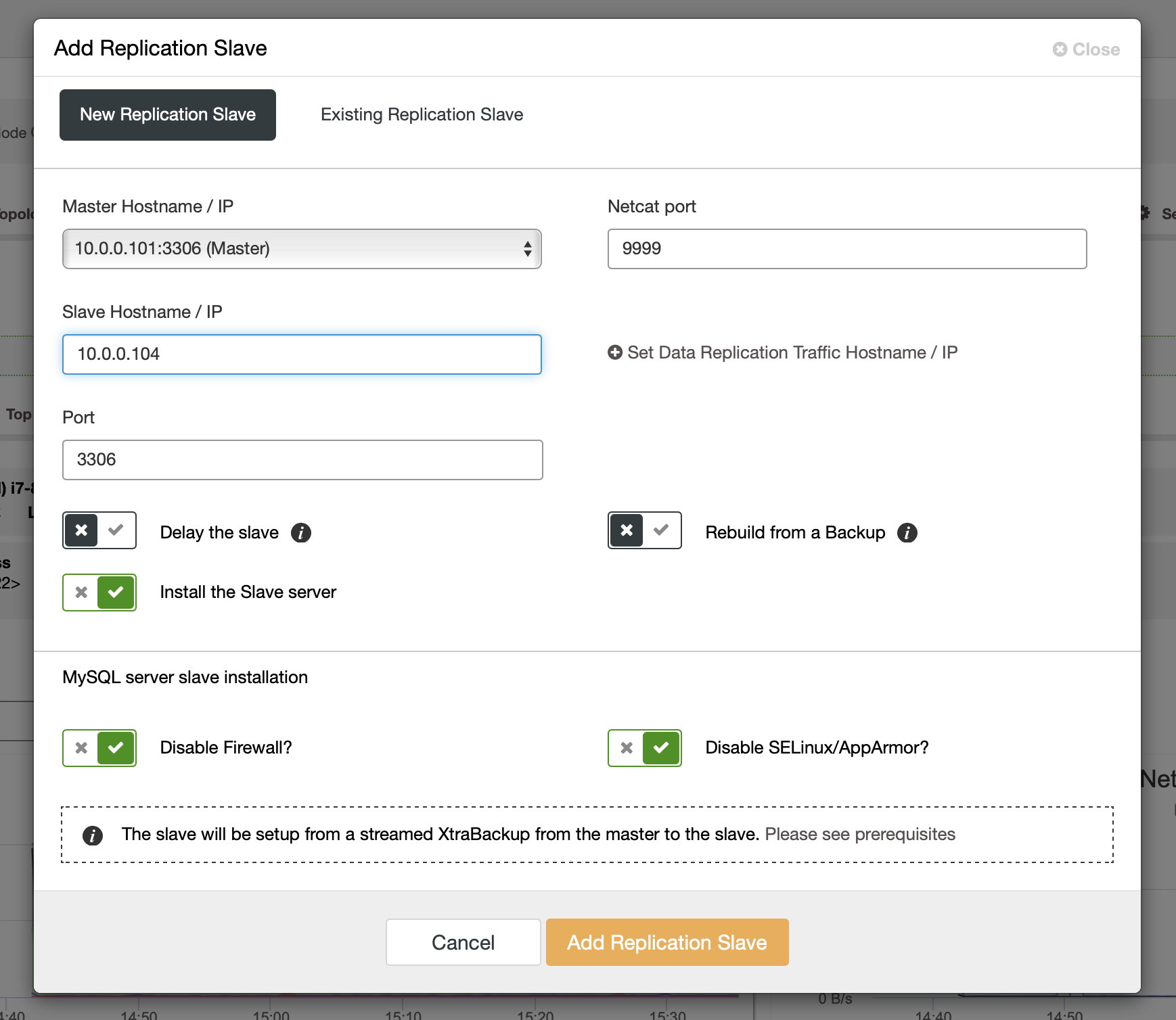
After binlogs have been enabled on some of the Galera nodes, you can proceed with adding the replication slave. In the dialog you have to pick the master host, pass the hostname or IP address of the slave. If you have recent backups at hand (which you should do), you can use one to provision the slave. Otherwise ClusterControl will provision it using xtrabackup – all the recent master data will be streamed to the slave and then the replication will be configured.
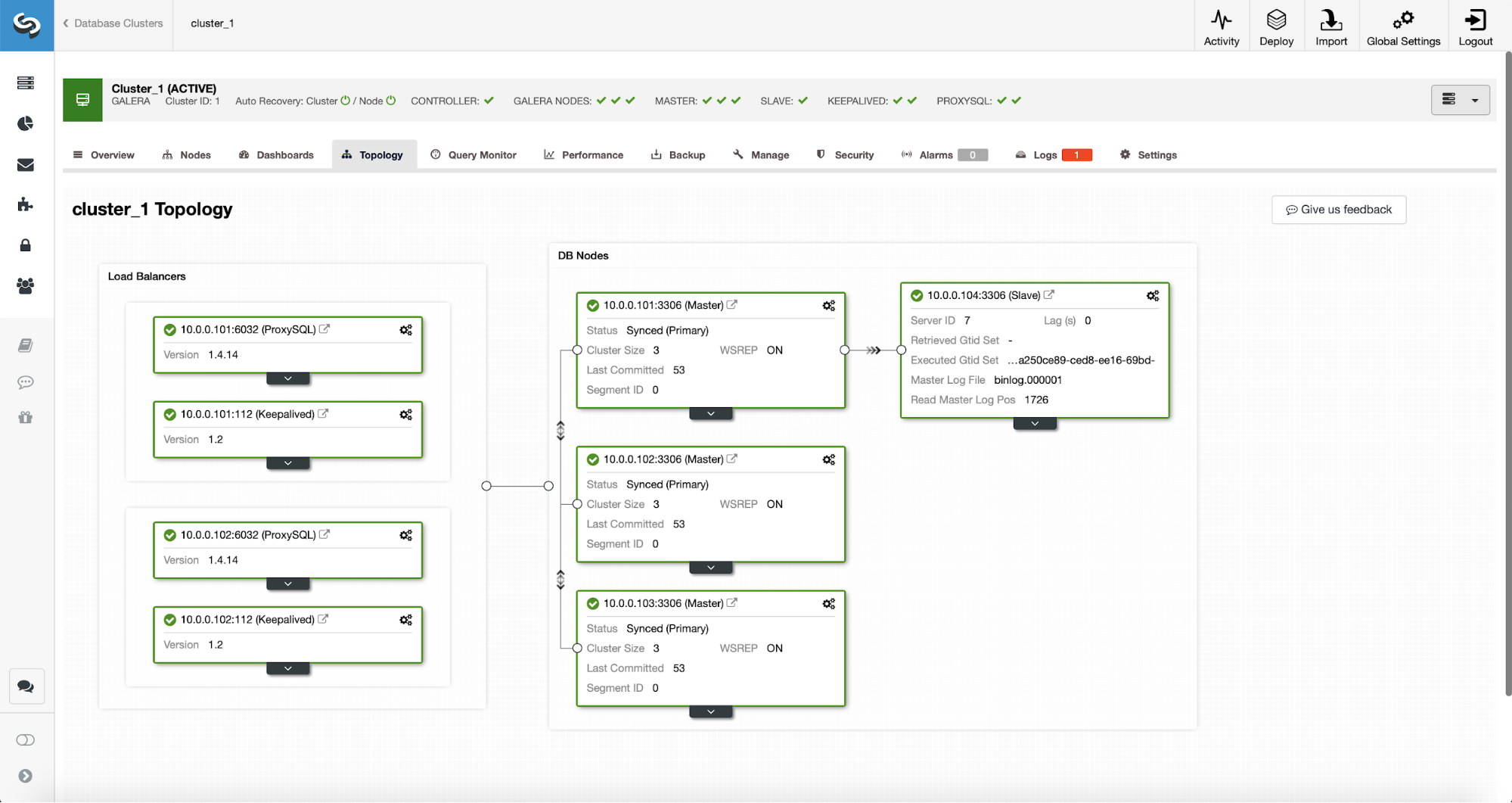
After the job completed, a replication slave has been added to the cluster. As stated earlier, should the 10.0.0.101 die, another host in the Galera cluster will be picked as the master and ClusterControl will automatically slave 10.0.0.104 off another node.
As we use ProxySQL, we need to configure it. We’ll add a new server into ProxySQL.
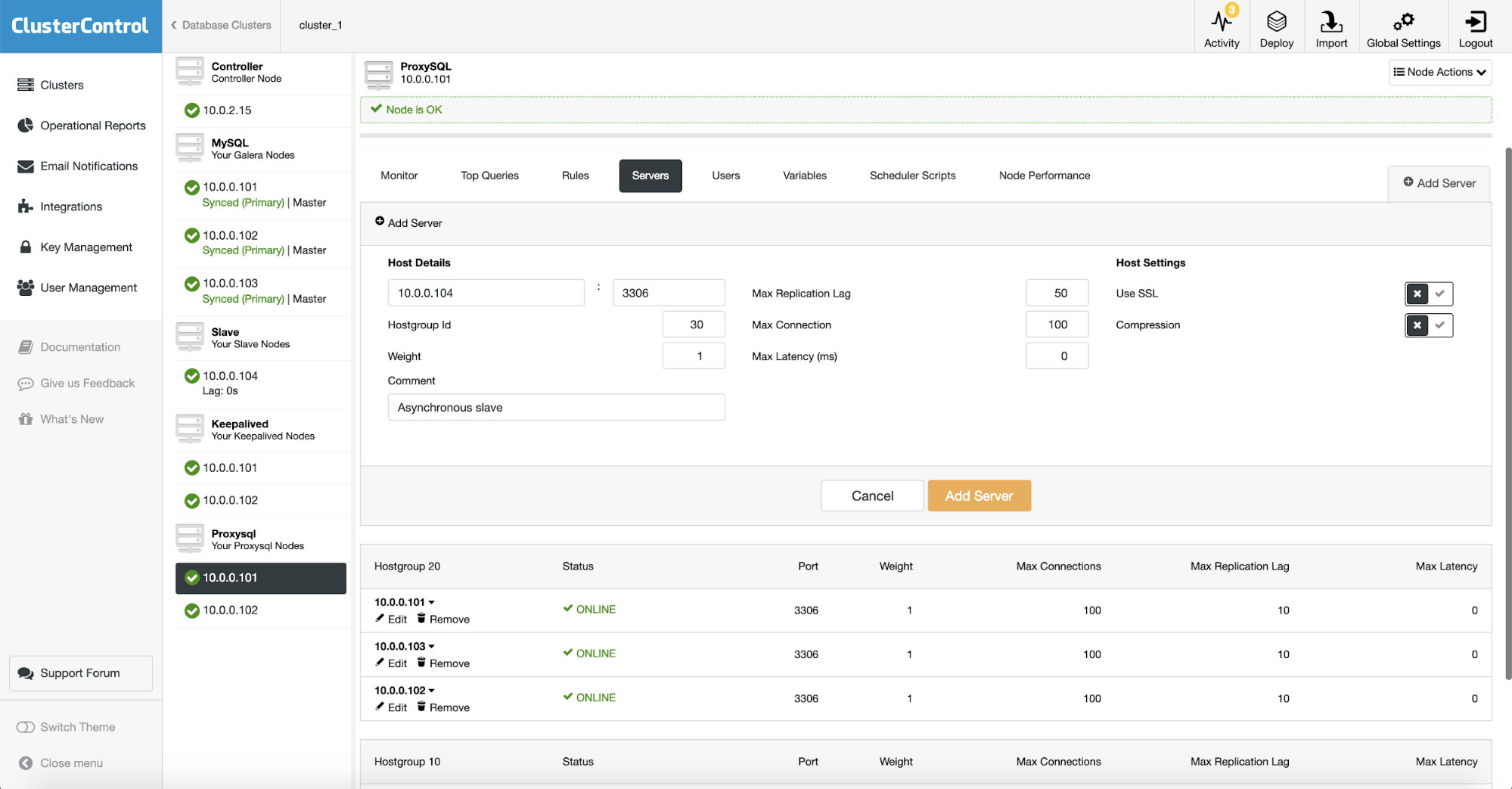
We created another hostgroup (30) where we put our asynchronous slave. We also increased “Max Replication Lag” to 50 seconds from default 10. It is up to your business requirements how badly analytics slave can be lagging before it becomes a problem.
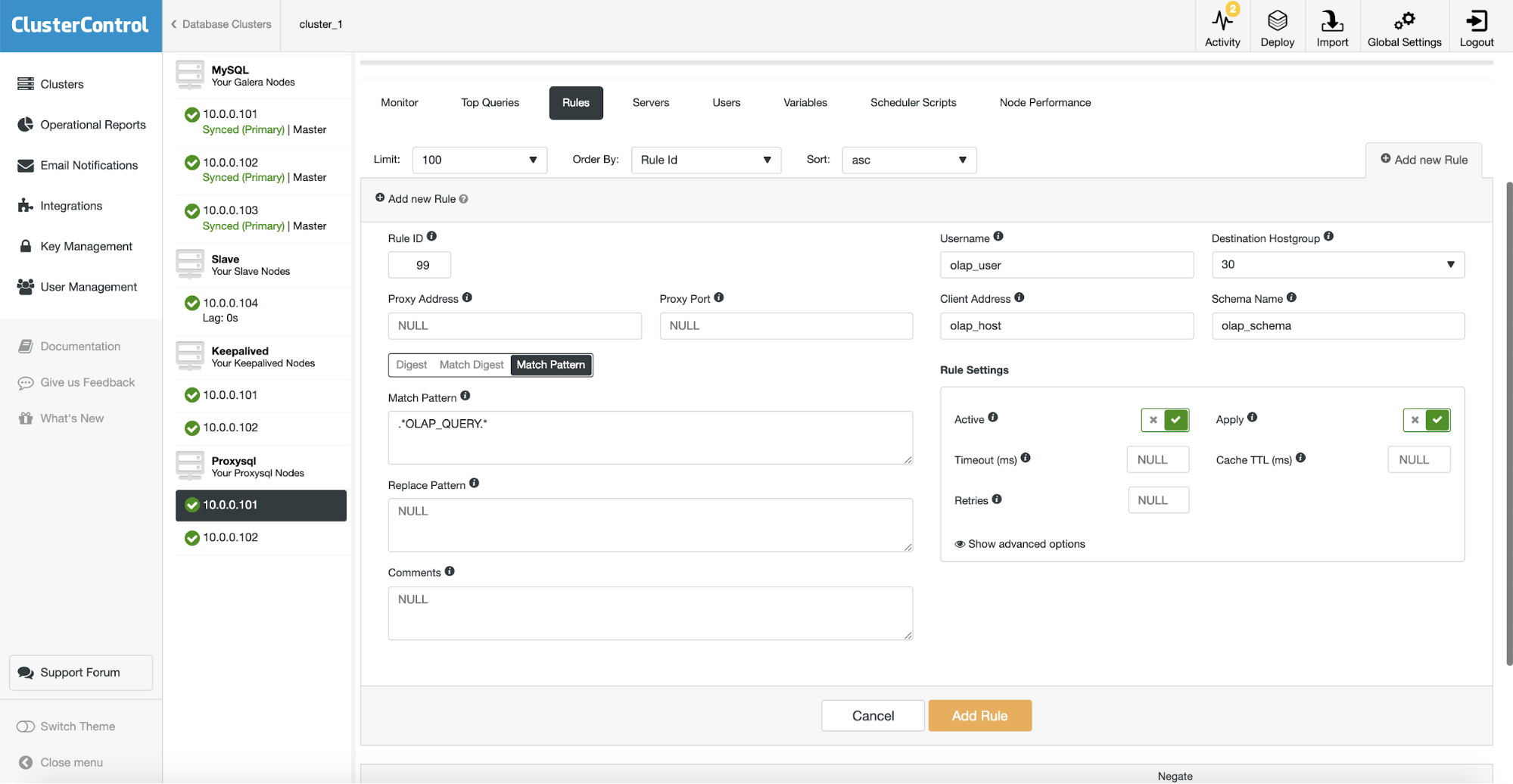
After that we have to configure a query rule that will match our OLAP traffic and route it to the OLAP hostgroup (30). On the screenshot above we filled several fields – this is not mandatory. Typically you will need to use one, two of them at most. Above screenshot serves as an example so we can easily see that you can match queries using schema (if you have a separate schema with analytical data), hostname/IP (if OLAP queries are executed from some particular host), user (if application uses particular user for analytical queries. You can also match queries directly by either passing a full query or by marking them with SQL comments and let ProxySQL route all queries with a “OLAP_QUERY” string to our analytical hostgroup.
As you can see, thanks to ClusterControl we were able to deploy a replication slave to Galera Cluster in just a couple of clicks. Some may argue that MySQL is not the most suitable database for analytical workload and we tend to agree. You can easily extend this setup using ClickHouse and by setting up a replication from asynchronous slave to ClickHouse columnar datastore for much better performance of analytical queries. We described this setup in one of the earlier blog posts.



