blog
Why Did My MySQL Database Crash? Get Insights with the New MySQL Freeze Frame
In case you haven’t seen it, we just released ClusterControl 1.7.5 with major improvements and new useful features. Some of the features include Cluster Wide Maintenance, support for version CentOS 8 and Debian 10, PostgreSQL 12 Support, MongoDB 4.2 and Percona MongoDB v4.0 support, as well as the new MySQL Freeze Frame.
Wait, but What is a MySQL Freeze Frame? Is This Something New to MySQL?
Well it’s not something new within the MySQL Kernel itself. It’s a new feature we added to ClusterControl 1.7.5 that is specific to MySQL databases. The MySQL Freeze Frame in ClusterControl 1.7.5 will cover these following things:
- Snapshot MySQL status before cluster failure.
- Snapshot MySQL process list before cluster failure (coming soon).
- Inspect cluster incidents in operational reports or from the s9s command line tool.
These are valuable sets of information that can help trace bugs and fix your MySQL/MariaDB clusters when things go south. In the future, we are planning to include also snapshots of the SHOW ENGINE InnoDB status values as well. So please stay tuned to our future releases.
Note that this feature is still in beta state, we expect to collect more datasets as we work with our users. In this blog, we will show you how to leverage this feature, especially when you need further information when diagnosing your MySQL/MariaDB cluster.
ClusterControl on Handling Cluster Failure
For cluster failures, ClusterControl does nothing unless Auto Recovery (Cluster/Node) is enabled just like below:
Once enabled, ClusterControl will try to recover a node or recover the cluster by bringing up the entire cluster topology.
For MySQL, for example in a master-slave replication, it must have at least one master alive at any given time, regardless of the number of available slave/s. ClusterControl attempts to correct the topology at least once for replication clusters, but provides more retries for multi-master replication like NDB Cluster and Galera Cluster. Node recovery attempts to recover a failing database node, e.g. when the process was killed (abnormal shutdown), or the process suffered an OOM (Out-of-Memory). ClusterControl will connect to the node via SSH and try to bring up MySQL. We have previously blogged about How ClusterControl Performs Automatic Database Recovery and Failover, so please visit that article to learn more about the scheme for ClusterControl auto recovery.
In the previous version of ClusterControl < 1.7.5, those attempted recoveries triggered alarms. But one thing our customers missed was a more complete incident report with state information just before the cluster failure. Until we realized this shortfall and added this feature in ClusterControl 1.7.5. We called it the “MySQL Freeze Frame”. The MySQL Freeze Frame, as of this writing, offers a brief summary of incidents leading to cluster state changes just before the crash. Most importantly, it includes at the end of the report the list of hosts and their MySQL Global Status variables and values.
How Does MySQL Freeze Frame Differs With Auto Recovery?
The MySQL Freeze Frame is not part of the auto recovery of ClusterControl. Whether Auto Recovery is disabled or enabled, the MySQL Freeze Frame will always do its work as long as a cluster or node failure has been detected.
How Does MySQL Freeze Frame Work?
In ClusterControl, there are certain states that we classify as different types of Cluster Status. MySQL Freeze Frame will generate an incident report when these two states are triggered:
- CLUSTER_DEGRADED
- CLUSTER_FAILURE
In ClusterControl, a CLUSTER_DEGRADED is when you can write to a cluster, but one or more nodes are down. When this happens, ClusterControl will generate the incident report.
For CLUSTER_FAILURE, though its nomenclature explains itself, it is the state where your cluster fails and is no longer able to process reads or writes. Then that is a CLUSTER_FAILURE state. Regardless of whether an auto-recovery process is attempting to fix the problem or whether it’s disabled, ClusterControl will generate the incident report.
How Do You Enable MySQL Freeze Frame?
ClusterControl’s MySQL Freeze Frame is enabled by default and only generates an incident report only when the states CLUSTER_DEGRADED or CLUSTER_FAILURE are triggered or encountered. So there’s no need on the user end to set any ClusterControl configuration setting, ClusterControl will do it for you automagically.
Locating the MySQL Freeze Frame Incident Report
As of this writing, there are 4-ways you can locate the incident report. These can be found by doing the following sections below.
Using the Operational Reports Tab
The Operational Reports from the previous versions are used only to create, schedule, or list the operational reports that have been generated by users. Since version 1.7.5, we included the incident report generated by our MySQL Freeze Frame feature. See the example below:
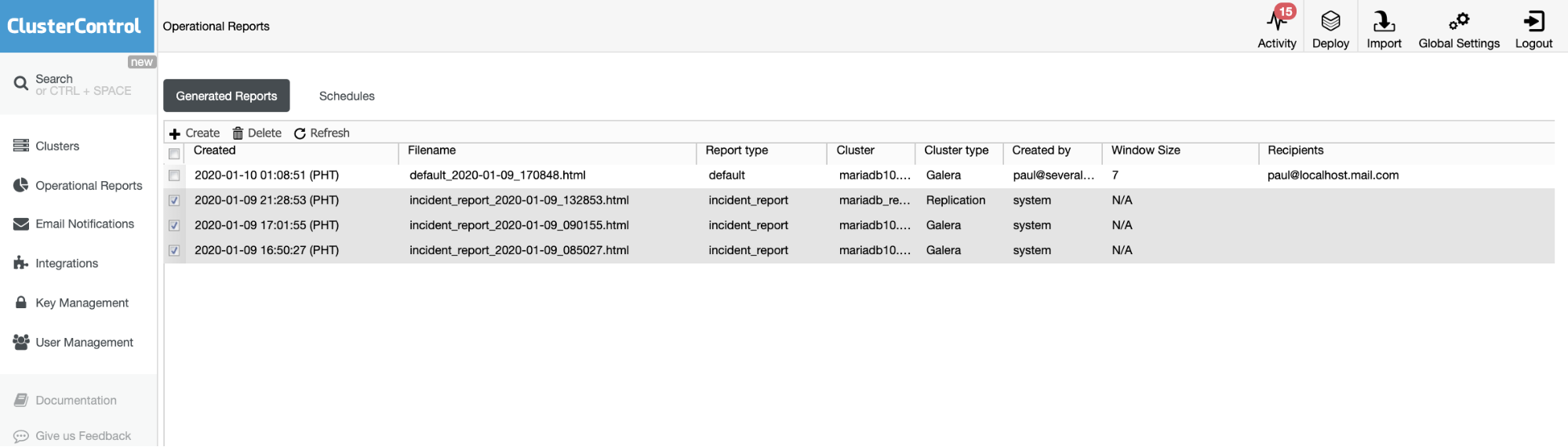
The checked items or items with Report type == incident_report, are the incident reports generated by MySQL Freeze Frame feature in ClusterControl.
Using Error Reports
By selecting the cluster and generating an error report, i.e. going through this process:
s9s report –cat –report-id=N
So if you want to locate and generate an error report, you can use this approach:
[vagrant@testccnode ~]$ s9s report –list –long –cluster-id=60
ID CID TYPE CREATED TITLE
19 60 incident_report 16:50:27 Incident Report – Cluster Failed
20 60 incident_report 17:01:55 Incident Report
If I want to grep the wsrep_* variables on a specific host, I can do the following:
[vagrant@testccnode ~]$ s9s report –cat –report-id=20 –cluster-id=60|sed -n ‘/WSREP.*/p’|sed ‘s/ */ /g’|grep ‘192.168.10.80’|uniq -d
| WSREP_APPLIER_THREAD_COUNT | 4 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_CONF_ID | 18446744073709551615 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_SIZE | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_DELAYED | 27ac86a9-3254-11ea-b104-bb705eb13dde:tcp://192.168.10.100:4567:1,9234d567-3253-11ea-92d3-b643c178d325:tcp://192.168.10.90:4567:1,9234d567-3253-11ea-92d4-b643c178d325:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25e-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25f-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b260-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b261-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b262-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b263-cfcbda888ea9:tcp://192.168.10.90:4567:1,b0b7cb15-3241-11ea-bdbc-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbd-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbe-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbf-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdc0-1a21deddc100:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b321-9a836d562a47:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b322-9a836d562a47:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ab-e298880f3348:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ac-e298880f3348:tcp://192.168.10.100:4567:1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_GCOMM_UUID | 781facbc-3241-11ea-8a22-d74e5dcf7e08 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LAST_COMMITTED | 443 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_CACHED_DOWNTO | 98 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_RECV_QUEUE_MAX | 2 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROTOCOL_VERSION | 10 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROVIDER_VERSION | 26.4.3(r4535) | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED | 112 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED_BYTES | 14413 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED_BYTES | 40592 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_DATA_BYTES | 31734 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS_BYTES | 2752 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_ROLLBACKER_THREAD_COUNT | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_THREAD_COUNT | 5 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_REPL_LATENCY | 4.508e-06/4.508e-06/4.508e-06/0/1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
Manually Locating via System File Path
ClusterControl generates these incident reports in the host where ClusterControl runs. ClusterControl creates a directory in the /home//s9s_tmp or /root/s9s_tmp if you are using the root system user. The incident reports can be located, for example, by going to /home/vagrant/s9s_tmp/60/galera/cmon-reports/incident_report_2020-01-09_085027.html where the format explains as, /home//s9s_tmp///cmon-reports/.html. The full path of the file is also displayed when you hover your mouse in the item or file you want to check under the Operational Reports Tab just like below:
Are There Any Dangers or Caveats When Using MySQL Freeze Frame?
ClusterControl does not change nor modify anything in your MySQL nodes or cluster. MySQL Freeze Frame will just read SHOW GLOBAL STATUS (as of this time) at specific intervals to save records since we cannot predict the state of a MySQL node or cluster when it can crash or when it can have hardware or disk issues. It’s not possible to predict this, so we save the values and therefore we can generate an incident report in case a particular node goes down. In that case, the danger of having this is close to none. It can theoretically add a series of client requests to the server(s) in case some locks are held within MySQL, but we have not noticed it yet.The series of tests doesn’t show this so we would be glad if you can let us know or file a support ticket in case problems arise.
There are certain situations where an incident report might not be able to gather global status variables if a network issue was the problem prior to ClusterControl freezing a specific frame to gather data. That’s completely reasonable because there’s no way ClusterControl can collect data for further diagnosis as there’s no connection to the node in the first place.
Lastly, you might wonder why not all variables are shown in the GLOBAL STATUS section? For the meantime, we set a filter where empty or 0 values are excluded in the incident report. The reason is that we want to save some disk space. Once these incident reports are no longer needed, you can delete it via Operational Reports Tab.
Testing the MySQL Freeze Frame Feature
We believe that you are eager to try this one and see how it works. But please, make sure you are not running or testing this in a live or production environment. We’ll cover 2-phases of scenario in the MySQL/MariaDB, one for master-slave setup and one for Galera-type setup.
Master-Slave Setup Test Scenario
In a master-slave(s) setup, it’s easy and simple to try.
Step One
Make sure that you have disabled the Auto Recovery modes (Cluster and Node), like below:
so it won’t try or attempt to fix the test scenario.
Step Two
Go to your Master node and try setting to read-only:
root@node1[mysql]> set @@global.read_only=1;
Query OK, 0 rows affected (0.000 sec)
Step Three
This time, an alarm was raised and so a generated incident report. See below how does my cluster looks like:
and the alarm was triggered:
and the incident report was generated:
Galera Cluster Setup Test Scenario
For Galera-based setup, we need to make sure that the cluster will be no longer available, i.e., a cluster-wide failure. Unlike the Master-Slave test, you can let Auto Recovery enabled since we’ll play around with network interfaces.
Note: For this setup, ensure that you have multiple interfaces if you are testing the nodes in a remote instance since you cannot bring the interface up when you down that interface where you are connected.
Step One
Create a 3-node Galera cluster (for example using vagrant)
Step Two
Issue the command (just like below) to simulate network issue and do this to all the nodes
[root@testnode10 ~]# ifdown eth1
Device ‘eth1’ successfully disconnected.
Step Three
Now, it took my cluster down and have this state:
raised an alarm,
and it generates an incident report:
For a sample incident report, you can use this raw file and save it as html.
It’s quite simple to try but again, please do this only in a non-live and non-prod environment.
Conclusion
MySQL Freeze Frame in ClusterControl can be helpful when diagnosing crashes. When troubleshooting, you need a wealth of information in order to determine cause and that is exactly what MySQL Freeze Frame provides.



