blog
Cluster-Wide Database Maintenance and Why You Need It

Undoubtedly, there is a long list of maintenance tasks that have to be performed by system administrators, especially when it comes to critical systems. Some of the tasks have to be performed at regular intervals, like daily, weekly, monthly and yearly. Some have to be done right away, urgently. Nevertheless, any maintenance operation should not lead to another bigger problem, and any maintenance has to be handled with extra care to avoid any interruption to the business. Therefore, planning, scheduling and reporting are important aspects.
ClusterControl, as a cluster automation and management tool, is smart enough to plan and schedule maintenance windows in advance. This can help avoid unpleasant surprises during production operations, for instance unnecessary recovery procedure, failovers and alarms being triggered. This blog showcases some of the new maintenance mode features that come with ClusterControl 1.7.5.
Maintenance Mode pre v1.7.5
Maintenance mode has been in ClusterControl logic since v1.4.0, where one could set a maintenance duration to an individual node, which allows ClusterControl to disable recovery/failover and alarms on that node during a set period. The maintenance mode can be activated immediately or scheduled to run in the future. Alarms and notifications will be turned off when maintenance mode is active, which is expected in an environment where the corresponding node is undergoing maintenance.
Some of the weaknesses that we found out and also reported by our users:
- Maintenance mode was bound per node. This means if one would want to perform maintenance on all nodes in the cluster, one had to repeatedly configure the maintenance mode for every node in the cluster. For larger environments, scheduling a major maintenance window for all nodes on multiple clusters could be repetitive.
- Activating maintenance mode did not deactivate the automatic recovery feature. This would cause an unhealthy node to be recovered automatically while maintenance is ongoing. False alarms might be raised.
- Maintenance mode could not be activated periodically per schedule. Therefore, regular maintenance had to be defined manually for every approaching date. There was no way to schedule a cron-based (with iteration) maintenance mode.
ClusterControl new maintenance mode and job implementations solve all of the key problems mentioned, which are shown in the next sections.
Database Cluster-Wide Maintenance Mode
Cluster-wide maintenance mode comes handy in an environment where you have multiple clusters, and multiple nodes per cluster managed by a single ClusterControl instance. For example, a common production setup of a MySQL Galera Cluster could have up to 7 nodes – A three-node Galera Cluster could have one additional host for asynchronous slave, with two ProxySQL/Keepalived nodes and one backup verification server. For older ClusterControl versions where only node maintenance was supported, if a major maintenance is required, for example upgrading OS kernel on all hosts, the scheduling had to be repeated 7 times for every monitored node. We have covered this issue in detail in this blog post, with some workarounds.
Cluster-wide maintenance mode is the super-set of node maintenance mode as in the previous versions. An activated cluster-wide maintenance mode will activate maintenance mode on all nodes in the particular cluster. Simply click on the Cluster Actions > Schedule Maintenance Mode and you will be presented with the following dialog:
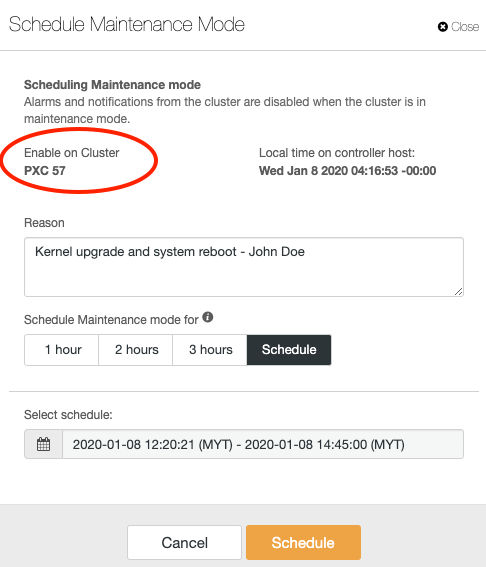
The fields in this dialog are almost identical with scheduling maintenance dialog for single node, except its domain is the particular cluster, as highlighted in the red oval. You can activate the maintenance immediately, or schedule it to run in the future. Once scheduled, you should see the following notification under the summary bar with status “Scheduled” for all clusters:

Once the maintenance mode is activated, you should see the blue maintenance icon on the summary bar of the cluster, together with the green ‘Active’ icon notification in the ClusterControl UI:

All active maintenance mode can be deactivated at any time via the UI, just go to the Cluster Actions > Disable Maintenance Mode.
Advanced Maintenance Management via ClusterControl CLI
ClusterControl CLI a.k.a s9s, comes with an extended maintenance management functionality, allowing users to improve the existing maintenance operation flow as a whole. The CLI works by sending commands as JSON messages to ClusterControl Controller (CMON) RPC interface, via TLS encryption which requires the port 9501 to be opened on controller and the client host.
With a bit of scripting knowledge, we can fully automate and synchronize the maintenance process flow especially if the exercise involves another layer/party/domain outside of ClusterControl. Note that we always incorporated our changes via the CLI first before making it to the UI. This is one of the ways to test out new functionality to find out if they would be useful to our users.
The following sections will give you a walkthrough on advanced management for maintenance mode via command line.
View Maintenance Mode
To list out all maintenance that has been scheduled for all clusters and nodes:
$ s9s maintenance --list --long
ST UUID OWNER GROUP START END HOST/CLUSTER REASON
Ah 460a97b dba admins 02:31:32 04:31:32 192.168.0.22 Switching to different racks
-h e3bf19f [email protected] 2020-01-17 02:35:00 2020-01-17 03:00:00 192.168.0.23 Change network cable - Clark Kent
-c 8f55f76 [email protected] 2020-01-17 02:34:00 2020-01-17 03:59:00 PXC 57 Kernel upgrade and system reboot - John Doe
Ac 4f4d73c dba admins 02:30:01 02:31:01 MariaDB 10.3 Test maintenance job creation every 5 minutesOwner with email address means the maintenance mode was created by ClusterControl UI user. While for owners with groups, that user is coming from the CLI with our new user/group permission currently supported on CLI only. The leftmost column is the maintenance mode status:
- The first character: ‘A’ stands for active and ‘-‘ stands for inactive.
- The second character: ‘h’ stands for host-related maintenance and ‘c’ stands for cluster-related maintenance.
To list out the current active maintenance mode:
$ s9s maintenance --current --cluster-id=32
Cluster 32 is under maintenance: Kernel upgrade and system reboot - John DoeUse the job command option to get the timestamp, and status of past maintenance mode:
$ s9s job --list | grep -i maintenance
5979 32 SCHEDULED dba admins 2020-01-09 05:29:34 0% Registering Maintenance
5980 32 FINISHED dba admins 2020-01-09 05:30:01 0% Registering Maintenance
5981 32 FINISHED dba admins 2020-01-09 05:35:00 0% Registering Maintenance
5982 32 FINISHED dba admins 2020-01-09 05:40:00 0% Registering Maintenance‘Registering Maintenance’ is the job name to schedule or activate the maintenance mode.
Create a Maintenance Mode
To create a new maintenance mode for a node, specify the host under –nodes parameter, with –begin and –end in ISO 8601 (with microsecond, UTC only thus the suffix ‘Z’) date format:
$ s9s maintenance --create
--nodes="192.168.0.21"
--begin="2020-01-09T08:50:58.000Z"
--end="2020-01-09T09:50:58.000Z"
--reason="Upgrading RAM"However, the above will require an extra effort to figure out the correct start time and end time. We can use the “date” command to translate the date and time to the supported format relative to the current time, similar to below:
$ s9s maintenance --create
--nodes="192.168.0.21"
--begin="$(date +%FT%T.000Z -d 'now')"
--end="$(date +%FT%T.000Z -d 'now + 2 hours')"
--reason="Upgrading RAM"
b348f2ac-9daa-4481-9a95-e8cdf83e81fcThe above will activate a maintenance mode for node 192.168.0.21 immediately and will end up in 2 hours from the moment it was created. An accepted command should receive a UUID, as in the above example, it was ‘b348f2ac-9daa-4481-9a95-e8cdf83e81fc’. A wrong command will simply return a blank output.
The following command will schedule a maintenance mode for cluster ID 32 on the next day:
$ s9s maintenance --create
--cluster-id=32
--begin="$(date +%FT%T.000Z -d 'now + 1 day')"
--end="$(date +%FT%T.000Z -d 'now + 1 day + 2 hours')"
--reason="Replacing old network cable"
85128b1a-a1cd-450e-b381-2a92c03db7a0We can also see what is coming up next in the scheduled maintenance for a particular node or cluster:
$ date -d 'now'
Wed Jan 8 07:41:57 UTC 2020
$ s9s maintenance --next --cluster-id=32 --nodes='192.168.0.22'
Host 192.168.0.22 maintenance starts Jan 09 07:41:23: Replacing old network cableOmit –nodes if you just want to see the upcoming maintenance details for a particular cluster.
Delete Maintenance Mode
Firstly, retrieve the maintenance job UUID:
$ s9s maintenance --list --long
ST UUID OWNER GROUP START END HOST/CLUSTER REASON
-h 7edeabb [email protected] 04:59:00 06:59:00 192.168.0.21 Changing network cable - John Doe
-c 82b13d3 [email protected] 2020-01-10 05:02:00 2020-01-10 06:27:00 MariaDB 10.3 Replication Upgrading RAM
Total: 2Use the –uuid and specify the corresponding maintenance mode to delete:
$ s9s maintenance --delete --uuid=82b13d3
Deleted.At this point the maintenance mode has been deleted for the corresponding node or cluster.
Maintenance Mode Scheduling with Iteration
In ClusterControl 1.7.5, maintenance mode can be scheduled and iterated just like a cron job. For example, you can now schedule a maintenance mode for daily, weekly, monthly or yearly. This iteration automates the maintenance mode job creation and simplifies the maintenance workflow, especially if you are running in a fully automated infrastructures, where maintenance happens automatically and at regular intervals.
There is a special flag that we have to use called –create-with-job, where it registers the maintenance as a new job for the controller to execute. The following is a simple example where we activate maintenance mode by registering a new job:
$ s9s maintenance
--create-with-job
--cluster-id=32
--reason="testmainteannce"
--minutes=60
--log
Preparing to register maintenance.
The owner of the maintenance will be 'dba'.
The reason is: testmainteannce
The maintenance starts NOW.
Maintenance will be 60 minute(s) long.
Registering maintenance for cluster 32.
Maintenance registered.To schedule a periodic maintenance, use the –create-with-job flag, with –minutes for the maintenance duration and –recurrence flag in cron-style formatting. The following command schedules a maintenance job every Friday at 3 AM for cluster ID 32:
$ s9s maintenance
--create-with-job
--cluster-id=32
--reason="Weekly OS patch at 3 AM every Friday"
--minutes=120
--recurrence="0 3 * * 5"
--job-tags="maintenance"
Job with ID 5978 registered.You should get a job ID in the response. We can then verify if the job has been created correctly:
$ s9s job --list --job-id=5978
ID CID STATE OWNER GROUP CREATED RDY TITLE
5978 32 SCHEDULED dba admins 05:21:07 0% Registering MaintenanceWe can also use the –show-scheduled flag together with –long flag to get extended information on the scheduled job:
$ s9s job --show-scheduled --list --long
--------------------------------------------------------------------------------------------------------------------------
Registering Maintenance
Scheduled
Created : 2020-01-09 05:21:07 ID : 5978 Status : SCHEDULED
Started : User : dba Host : 127.0.0.1
Ended : Group: admins Cluster: 32
Tags : #maintenance
RPC : 2.0
--------------------------------------------------------------------------------------------------------------------------A recurring job created by the scheduled job will be tagged as “recurrence”:
--------------------------------------------------------------------------------------------------------------------------
Registering Maintenance
Job finished. [ ]
0.00%
Created : 2020-01-09 05:40:00 ID : 5982 Status : FINISHED
Started : 2020-01-09 05:40:01 User : dba Host : 127.0.0.1
Ended : 2020-01-09 05:40:01 Group: admins Cluster: 32
Tags : #recurrence
RPC : 2.0
--------------------------------------------------------------------------------------------------------------------------Thus, to list out the recurring job, we can use the –job-tags flag. The following example shows executed recurring jobs scheduled to run every 5 minutes:
$ s9s job --list --job-tags=recurrence
ID CID STATE OWNER GROUP CREATED RDY TITLE
5980 32 FINISHED dba admins 05:30:01 0% Registering Maintenance
5981 32 FINISHED dba admins 05:35:00 0% Registering Maintenance
5982 32 FINISHED dba admins 05:40:00 0% Registering MaintenanceAutomatic Recovery as a Job
In the previous versions, automatic recovery feature can only be enabled or disabled at runtime via the UI, through a simple switch button in the cluster’s summary bar, as shown in the following screenshot:

In ClusterControl 1.7.5, automatic recovery is also part of an internal job, where the configuration can be controlled via CLI and persistent across restarts. This means the job can be scheduled, iterated and controlled with an expiration period via ClusterControl CLI and allows users to incorporate the automatic recovery management in the maintenance automation scripts when necessary.
When a cluster-wide maintenance is ongoing, it is pretty common to see some questionable states of database hosts, which is totally acceptable during this period. The common practice is to ignore these questionable states and make no interruption to the node while maintenance is happening. If ClusterControl automatic recovery is turned on, it will automatically attempt to recover the problematic host back to the good state, regardless of the maintenance mode state. Thus, disabling ClusterControl automatic recovery during the maintenance operation is highly recommended so ClusterControl will not interrupt the maintenance as it carries on.
To disable cluster automatic recovery, simply use the –disable-recovery flag with respective cluster ID:
$ s9s cluster --disable-recovery --log --cluster-id=32
Cluster ID is 32.
Cluster recovery is currently enabled.
Node recovery is currently enabled.
Disabling cluster auto recovery.
Disabling node auto recovery.To reverse the above, use –enable-recovery flag to enable it again:
$ s9s cluster --enable-recovery --log --cluster-id=32
Cluster ID is 32.
Cluster recovery is currently disabled.
Node recovery is currently disabled.
Enabling cluster auto recovery.
Enabling node auto recovery.The CLI also supports disabling recovery together with activating maintenance mode in the same command. One has to use the –maintenance-minutes flag and optionally provide a reason:
$ s9s cluster
--disable-recovery
--log
--cluster-id=29
--maintenance-minutes=60
--reason='Disabling recovery for 1 hour to update kernel'
Registering maintenance for 60 minute(s) for cluster 32.
Cluster ID is 29.
Cluster recovery is currently enabled.
Node recovery is currently enabled.
Disabling cluster auto recovery.
Disabling node auto recovery.From the above output, we can tell that ClusterControl has disabled automatic recovery for the node, and also registered a maintenance mode for the cluster. We can then verify with the list maintenance command:
$ s9s maintenance --list --long
ST UUID OWNER GROUP START END HOST/CLUSTER REASON
Ac 687e255 system admins 06:09:57 07:09:57 MariaDB 10.3 Replication Disabling recovery for 1 hour to update kernelSimilarly, it will appear in the UI as shown in the following screenshot:

You can enable the automatic recovery feature using the –enable-recovery flag if it is no longer necessary. The maintenance mode will still be active as defined in the –maintenance-minutes option, unless you explicitly delete or deactivate the maintenance mode via GUI or CLI.
Conclusion
ClusterControl allows you to manage your maintenance window efficiently, by discarding possible false alarms and controlling the automatic recovery behaviour while maintenance is ongoing. Maintenance mode is available for free in all ClusterControl editions, so give it a try.



