blog
What's New in MariaDB MaxScale 2.4

MaxScale 2.4 was released on December 21st, 2019, and ClusterControl 1.7.6 supports the monitoring and managing up to this version. However, for deployment, ClusterControl only supports up to version 2.3. One has to manually upgrade the instance manually, and fortunately, the upgrade steps are very straightforward. Just download the latest version from MariaDB MaxScale download page and perform the package installation command.
The following commands show how to upgrade from an existing MaxScale 2.3 to MaxScale 2.4 on a CentOS 7 box:
$ wget https://dlm.mariadb.com/1067184/MaxScale/2.4.10/centos/7/x86_64/maxscale-2.4.10-1.centos.7.x86_64.rpm
$ systemctl stop maxscale
$ yum localinstall -y maxscale-2.4.10-1.centos.7.x86_64.rpm
$ systemctl start maxscale
$ maxscale --version
MaxScale 2.4.10In this blog post, we are going to highlight some of the notable improvements and new features of this version and how it looks like in action. For a full list of changes in MariaDB MaxScale 2.4, check out its changelog.
Interactive Mode Command History
This is basically a small improvement with a major impact on MaxScale administration and monitoring task efficiency. The interactive mode for MaxCtrl now has its command history. Command history easily allows you to repeat the executed command by pressing the up or down arrow key. However, Ctrl+R functionality (recall the last command matching the characters you provide) is still not there.
In the previous versions, one has to use the standard shell mode to make sure the commands are captured by .bash_history file.
GTID Monitoring for galeramon
This is a good enhancement for those who are running on Galera Cluster with geographical redundancy via asynchronous replication, also known as cluster-to-cluster replication, or MariaDB Galera Cluster replication over MariaDB Replication.
In MaxScale 2.3 and older, this is what it looks like if you have enabled master-slave replication between MariaDB Clusters:
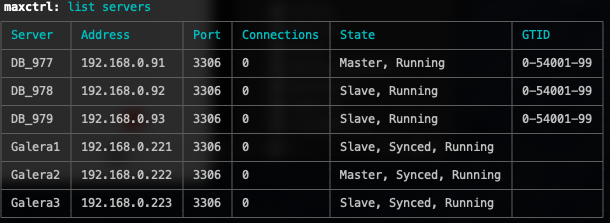
For MaxScale 2.4, it is now looking like this (pay attention to Galera1’s row):
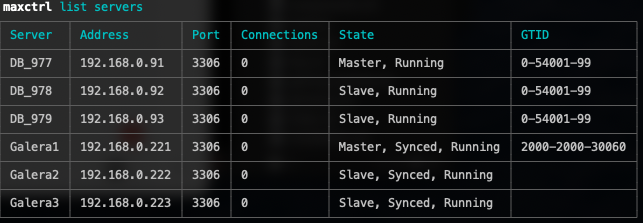
It’s now easier to see the replication state for all nodes from MaxScale, without the need to check on individual nodes repeatedly.
SmartRouter
This is one of the new major features in MaxScale 2.4, where MaxScale is now smart enough to learn which backend MariaDB backend server is the best to process the query. SmartRouter keeps track of the performance, or the execution time, of queries to the clusters. Measurements are stored with the canonical of a query as the key. The canonical of a query is the SQL with all user-defined constants replaced with question marks, for example:
UPDATE `money_in` SET `accountholdername` = ? , `modifiedon` = ? , `status` = ? , `modifiedby` = ? WHERE `id` = ? This is a very useful feature if you are running MariaDB on a multi-site geographical replication or a mix of MariaDB storage engines in one replication chain, for example, a dedicated slave to handle transaction workloads (OLTP) with InnoDB storage engine and another dedicated slave to handle analytics workloads (OLAP) with Columnstore storage engine.
Supposed we are having two sites – Sydney and Singapore as illustrated in the following diagram:
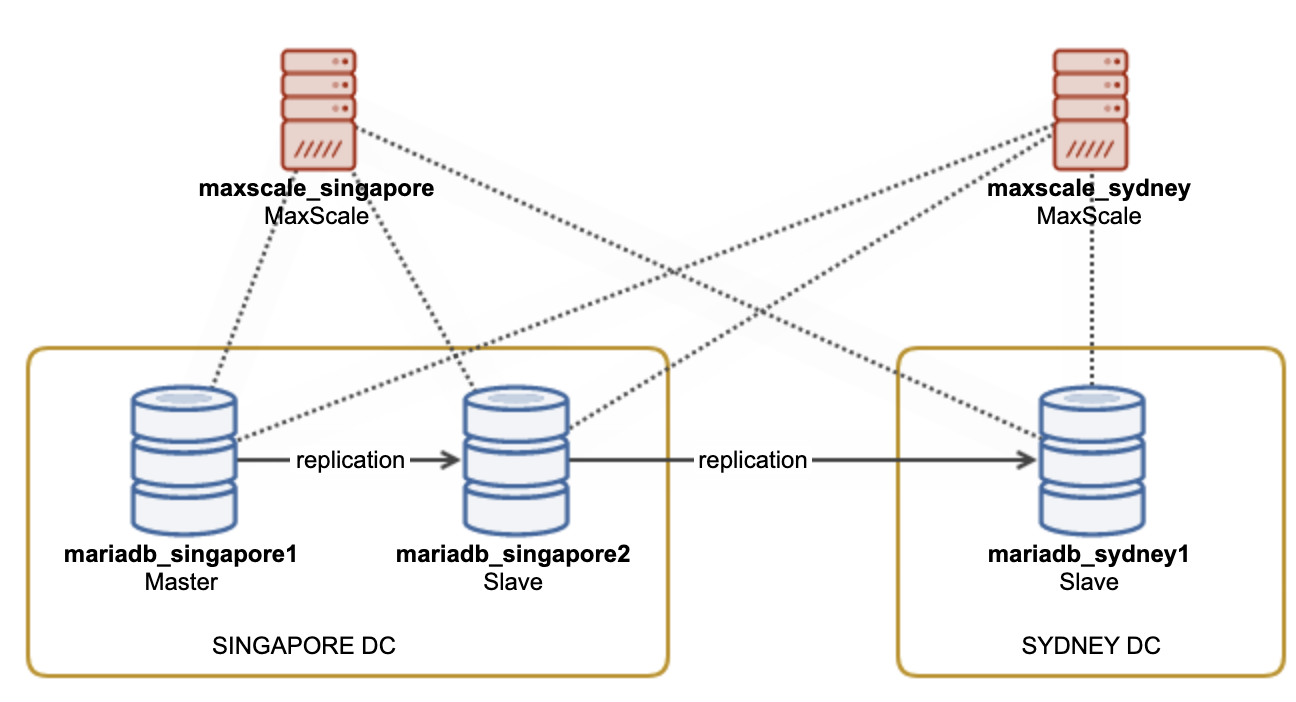
The primary site is located in Singapore and has a MariaDB master and a slave, while another read-only slave is located in Sydney. The application connects to the MaxScale instance located in its respective country with the following port settings:
- Read-write split: 3306
- Round robin: 3307
- Smart router: 3308
Our SmarRouter service and listener definitions are:
[SmartQuery]
type=service
router=smartrouter
servers=DB_1,DB_2,DB_5
master=DB_1
user=maxscale
password=******[SmartQuery-Listener]
type = listener
service = SmartQuery
protocol = mariadbclient
port = 3308Restart MaxScale and start sending a read-only query to both MaxScale nodes located in Singapore and Sydney. If the query is processed by the round-robin router (port 3307), we would see the query is being routed based on the round-robin algorithm:
(app)$ mysql -usbtest -p -h maxscale_sydney -P3307 -e 'SELECT COUNT(id),@@hostname FROM sbtest.sbtest1'
+-----------+--------------------+
| count(id) | @@hostname |
+-----------+--------------------+
| 1000000 | mariadb_singapore2 |
+-----------+--------------------+From the above, we can tell that Sydney’s MaxScale forwarded the above query to our Singapore’s slave, which is not the best routing option per se.
With SmartRouter listening on port 3308, we would see the query is being routed to the nearest slave in Sydney:
(app)$ mysql -usbtest -p -h maxscale_sydney -P3308 -e 'SELECT COUNT(id),@@hostname FROM sbtest.sbtest1'
+-----------+-----------------+
| count(id) | @@hostname |
+-----------+-----------------+
| 1000000 | mariadb_sydney1 |
+-----------+-----------------+And if the same query is executed in our Singapore site, it will be routed to the MariaDB slave located in Singapore:
(app)$ mysql -usbtest -p -h maxscale_singapore -P3308 -e 'SELECT COUNT(id),@@hostname FROM sbtest.sbtest1'
+-----------+--------------------+
| count(id) | @@hostname |
+-----------+--------------------+
| 1000000 | mariadb_singapore2 |
+-----------+--------------------+There is a catch though. When SmartRouter sees a read-query whose canonical has not been seen before, it will send the query to all clusters. The first response from a cluster will designate that cluster as the best one for that canonical. Also, when the first response is received, the other queries are canceled. The response is sent to the client once all clusters have responded to the query or the cancel.
This means, to keep track of the canonical query (normalized query) and measure its performance, you probably will see the very first query fails in its first execution, for example:
(app)$ mysql -usbtest -p -h maxscale_sydney -P3308 -e 'SELECT COUNT(id),@@hostname FROM sbtest.sbtest1'
ERROR 2013 (HY000) at line 1: Lost connection to MySQL server during queryFrom the general log in MariaDB Sydney, we can tell that the first query (ID 74) was executed successfully (connect, query and quit), despite the “Lost connection” error from MaxScale:
74 Connect [email protected] as anonymous on
74 Query SELECT COUNT(id),@@hostname FROM sbtest.sbtest1
74 QuitWhile the identical subsequent query was correctly processed and returned with the correct response:
(app)$ mysql -usbtest -p -h maxscale_sydney -P3308 -e 'SELECT COUNT(id),@@hostname FROM sbtest.sbtest1'
+-----------+------------------------+
| count(id) | @@hostname |
+-----------+------------------------+
| 1000000 | mariadb_sydney.cluster |
+-----------+------------------------+Looking again at the general log in MariaDB Sydney (ID 75), the same processing events happened just like the first query:
75 Connect [email protected] as anonymous on
75 Query SELECT COUNT(id),@@hostname FROM sbtest.sbtest1
75 QuitFrom this observation, we can conclude that occasionally, MaxScale has to fail the first query in order to measure performance and become smarter for the subsequent identical queries. Your application must be able to handle this “first error” properly before returning to the client or retry the transaction once more.
UNIX Socket for Server
There are multiple ways to connect to a running MySQL or MariaDB server. You could use the standard networking TCP/IP with host IP address and port (remote connection), named pipes/shared memory on Windows or Unix socket files on Unix-based systems. The UNIX socket file is a special kind of file that facilitates communications between different processes, which in this case is the MySQL client and the server. The socket file is a file-based communication, and you can’t access the socket from another machine. It provides a faster connection than TCP/IP (no network overhead) and a more secure connection approach because it can be used only when connecting to a service or process on the same computer.
Supposed the MaxScale server is also installed on the MariaDB Server itself, we can use the socket UNIX socket file instead. Under the Server section, remove or comment the “address” line and add the socket parameter with the location of the socket file:
[DB_2]
type=server
protocol=mariadbbackend
#address=54.255.133.39
socket=/var/lib/mysql/mysql.sockBefore applying the above changes, we have to create a MaxScale axscale user from localhost. On the master server:
MariaDB> CREATE USER 'maxscale'@'localhost' IDENTIFIED BY 'maxscalep4ss';
MariaDB> GRANT SELECT ON mysql.user TO 'maxscale'@'localhost';
MariaDB> GRANT SELECT ON mysql.db TO 'maxscale'@'localhost';
MariaDB> GRANT SELECT ON mysql.tables_priv TO 'maxscale'@'localhost';
MariaDB> GRANT SHOW DATABASES ON *.* TO 'maxscale'@'localhost';After a restart, MaxScale will show the UNIX socket path instead of the actual address, and the server listing will be shown like this:
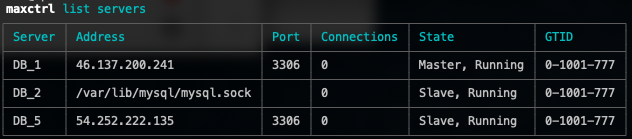
As you can see, the state and GTID information are retrieved correctly through a socket connection. Note that this DB_2 is still listening to port 3306 for the remote connections. It just shows that MaxScale uses a socket to connect to this server for monitoring.
Using socket is always better due to the fact that it only allows local connections and it is more secure. You could also close down your MariaDB server from the network (e.g, –skip-networking) and let MaxScale handle the “external” connections and forward them to the MariaDB server via UNIX socket file.
Server Draining
In MaxScale 2.4, the backend servers can be drained, which means existing connections can continue to be used, but no new connections will be created to the server. With the drain feature, we can perform a graceful maintenance activity without affecting the user experience from the application side. Note that draining a server can take a longer time, depending on the running queries that need to be gracefully closed.
To drain a server, use the following command:
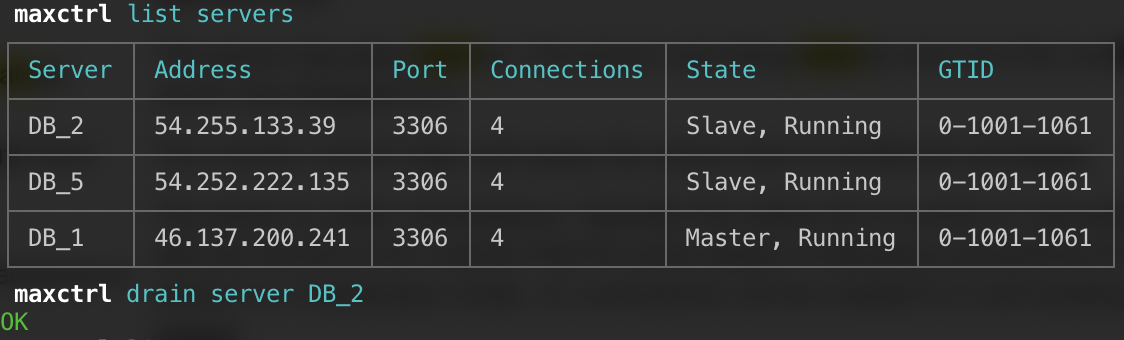
The after-effect could be one of the following states:
- Draining – The server is being drained.
- Drained – The server has been drained. The server was being drained and now the number of connections to the server has dropped to 0.
- Maintenance – The server is under maintenance.
After a server has been drained, the state of the MariaDB server from MaxScale point of view is “Maintenance”:
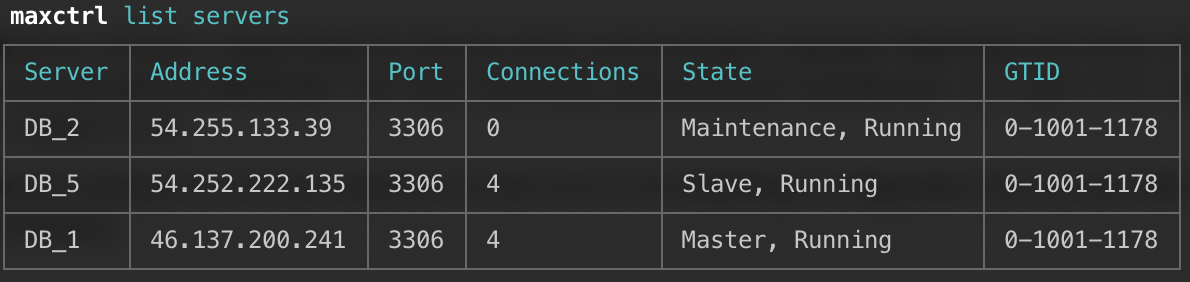
When a server is in maintenance mode, no connections will be created to it and existing connections will be closed.
Conclusion
MaxScale 2.4 brings a lot of improvements and changes over the previous version and it’s the best database proxy to handle MariaDB servers and all of its components.



