blog
Tips for Performing Database Maintenance with ClusterControl

Database Maintenance is a set of tasks that requires work on your database or set of database servers that involves improvement for its security, performance, optimization, upgrades, or even test such as benchmarking after changes made such as hardware or software updates. Obviously, these tasks involve a lot of things to be done and has to be planned carefully especially if it’s in a production environment. Database maintenance is not always necessary to be done periodically as there can be reasonable actions why it has to stay unchanged for a period of time. But it’s not the best case to stay dormant and stay unchanged especially if security and bugs do exist. For this case, most database servers nowadays are inclined to apply maintenance especially those serving high traffic volumes of data and involve storing sensitive data which is mostly accompanied by security and vulnerability factors. By that means, your best route is to take care of your data and of course this means it requires careful planning on how you can get off the production grid for a number of hours so that it won’t affect your normal operations and production workload while isolating the database server(s) that is targeted for maintenance.
Common routines for performing a database maintenance such as updating the database version (either major or minor), patches and fixes for your database or OS kernel, OS upgrades especially that comes with security and vulnerability patches. Upgrading your hardware such as memory or disk which majority of these actions requires a system reboot. Oftentimes, drastic situations require you to proceed with maintenance ASAP because your hardware or parts of your hardware is not functioning properly and it has to be replaced immediately. While these are going to happen and will always going to happen, there’s no reason that you don’t have to be prepared ahead of time.
Database Maintenance is a general term for doing these particular tasks and it varies on what actions have to take. There are actions that are quite simple to achieve, yet there are maintenance tasks that require careful planning and cannot proceed without caution. Technology nowadays supplements these types of situations and automation tools are created or made to satisfy these technical requirements. A lot of automation tools such as Puppet, Chef, Ansible, Salt, or Terraform can be your choices. Yet, database maintenance varies. That means there are certain cases that you have to create your own recipes or sets of actions in order to automate the job and avoid human errors. Human errors can cause to prolong the maintenance window set for the specific task and that is not acceptable especially on a production system and on a high traffic database environment.
ClusterControl offers Database Maintenance features which you can benefit from avoiding your production systems to be affected and avoid such drastic problems such as human errors. This blog will provide you tips on how to proceed with your database maintenance especially when it’s highly necessary to proceed.
Identify Your Targets
ClusterControl allows you to choose your database node to put under maintenance mode. The maintenance feature has been a long part of the ClusterControl software’s logic since the early versions of the software. The maintenance feature has been kept improving as the software improves with cluster wide maintenance apart from single-node maintenance selection. Whereas it offers this, there are various procedures that you can deal with ClusterControl to minimize hassle and long work activities but instead rely on ClusterControl which handles the automation procedures to deal with.
For example, in a master <-> master or chains replication environment. Let’s say you are going to upgrade your Linux kernel for new security patches and OS updates and this affects a master or a slave which is also a master of another slave (applicable only for MySQL/MariaDB database variants). This can affect other nodes that are replicating from it. If you take the node down and off the cluster, then in ClusterControl, you have the following procedures you can do. See below:
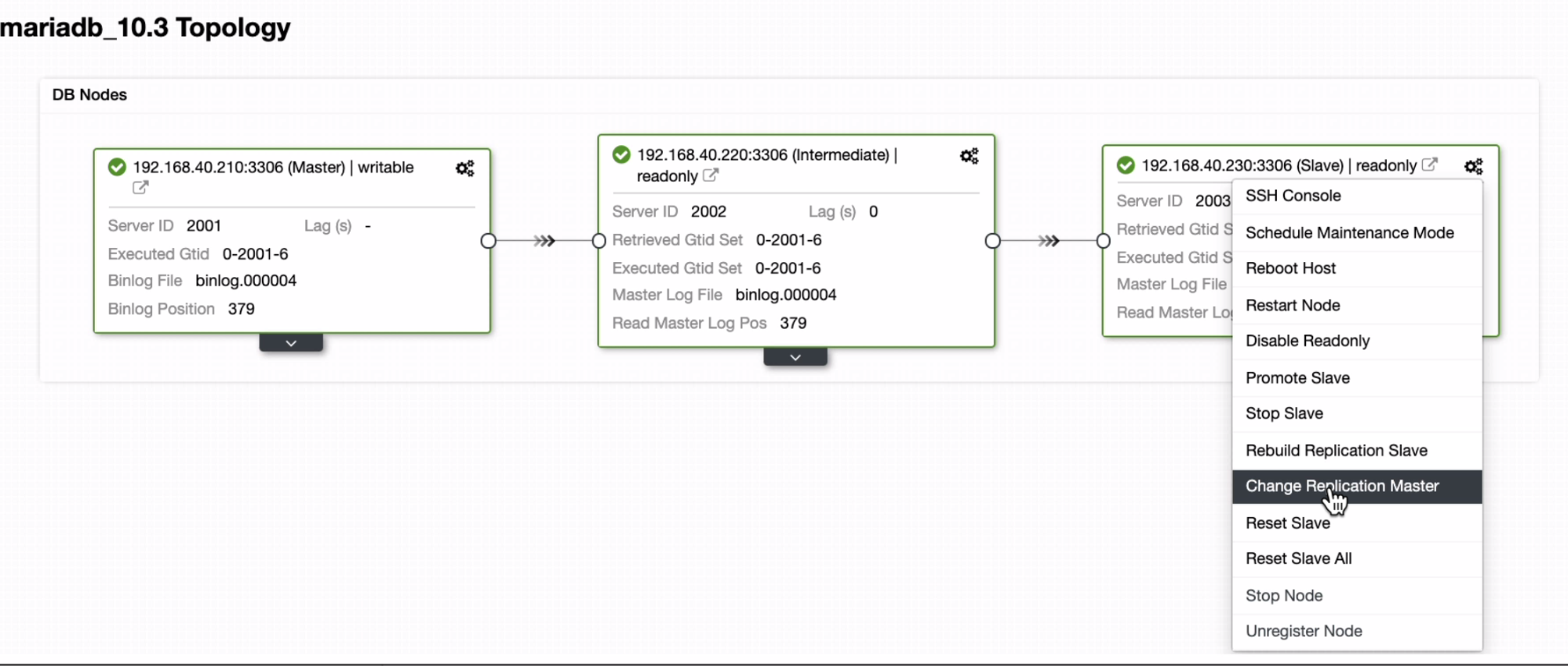
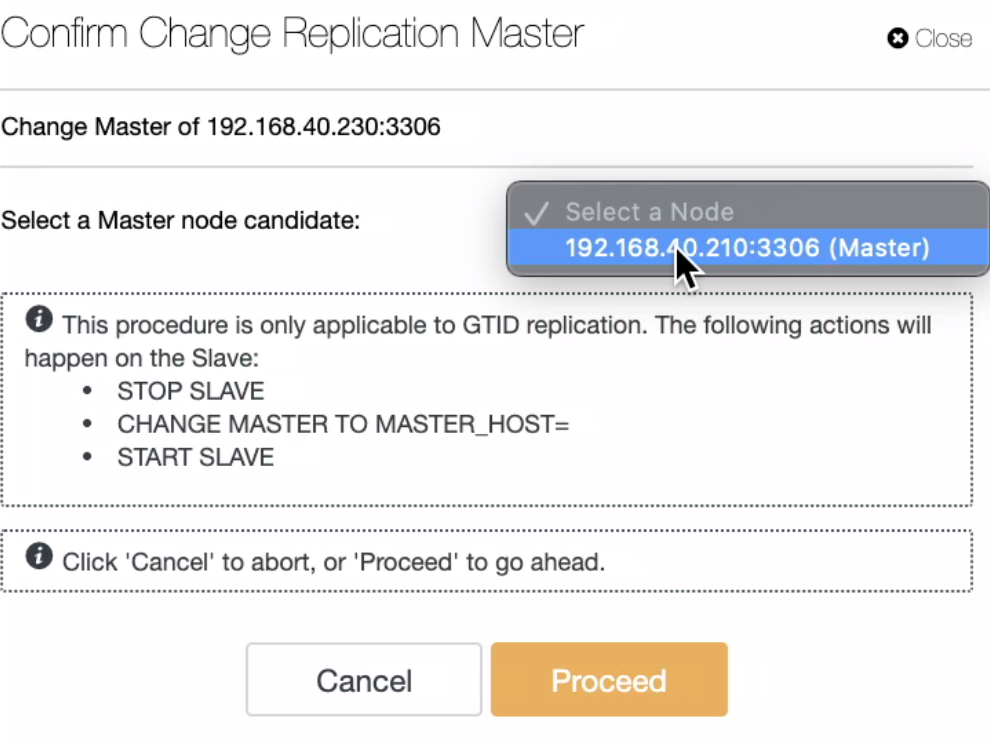
In the screenshot above, we have a master -> slave -> slave chained replication. Given the example that you have to place the node 192.168.40.220 under maintenance mode, you can move its replication master to the other node. Let say on 192.168.40.210,
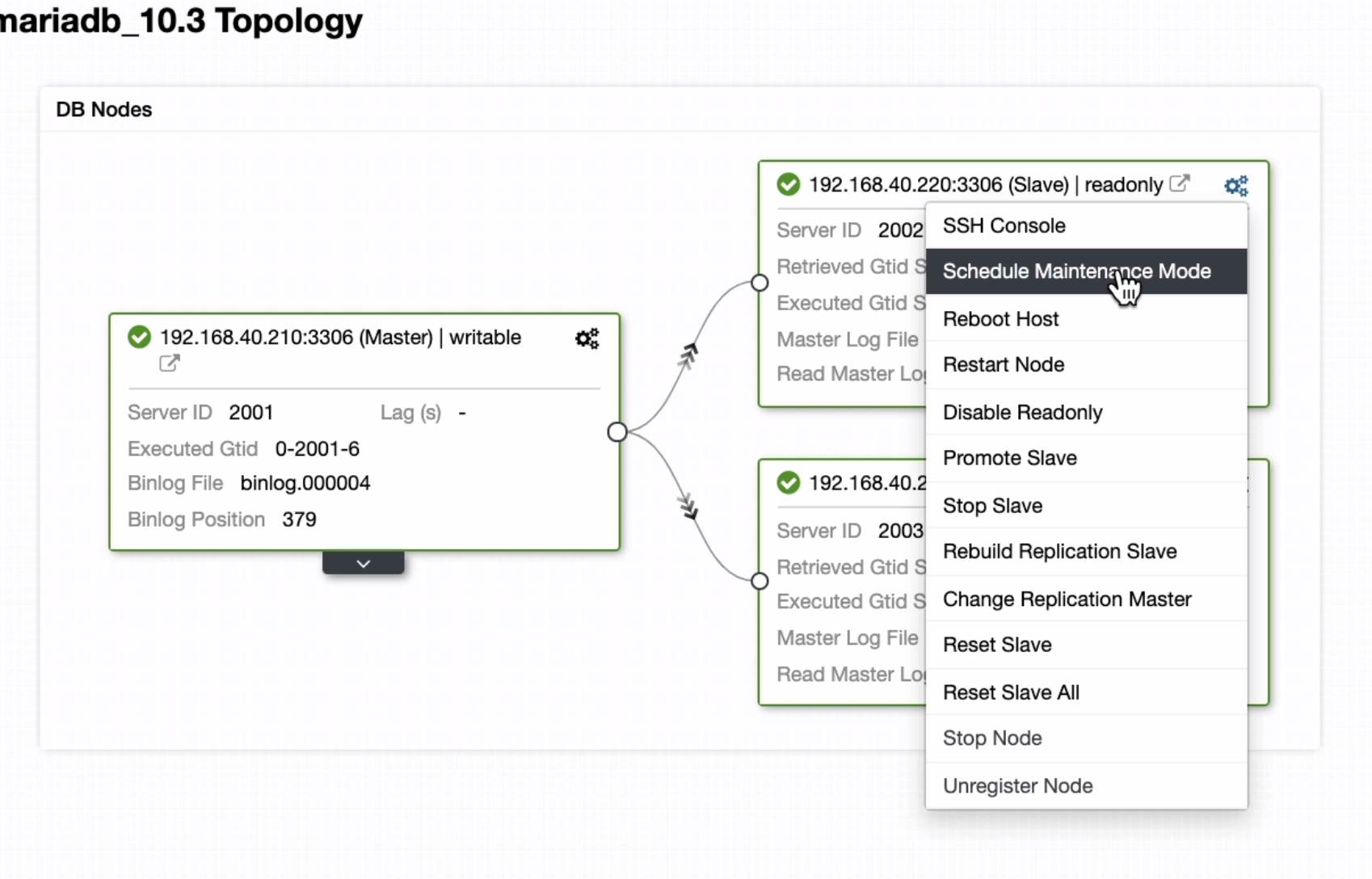
Once node is pointed to another master, then you can proceed with your target node to be placed under maintenance mode. Such as below,
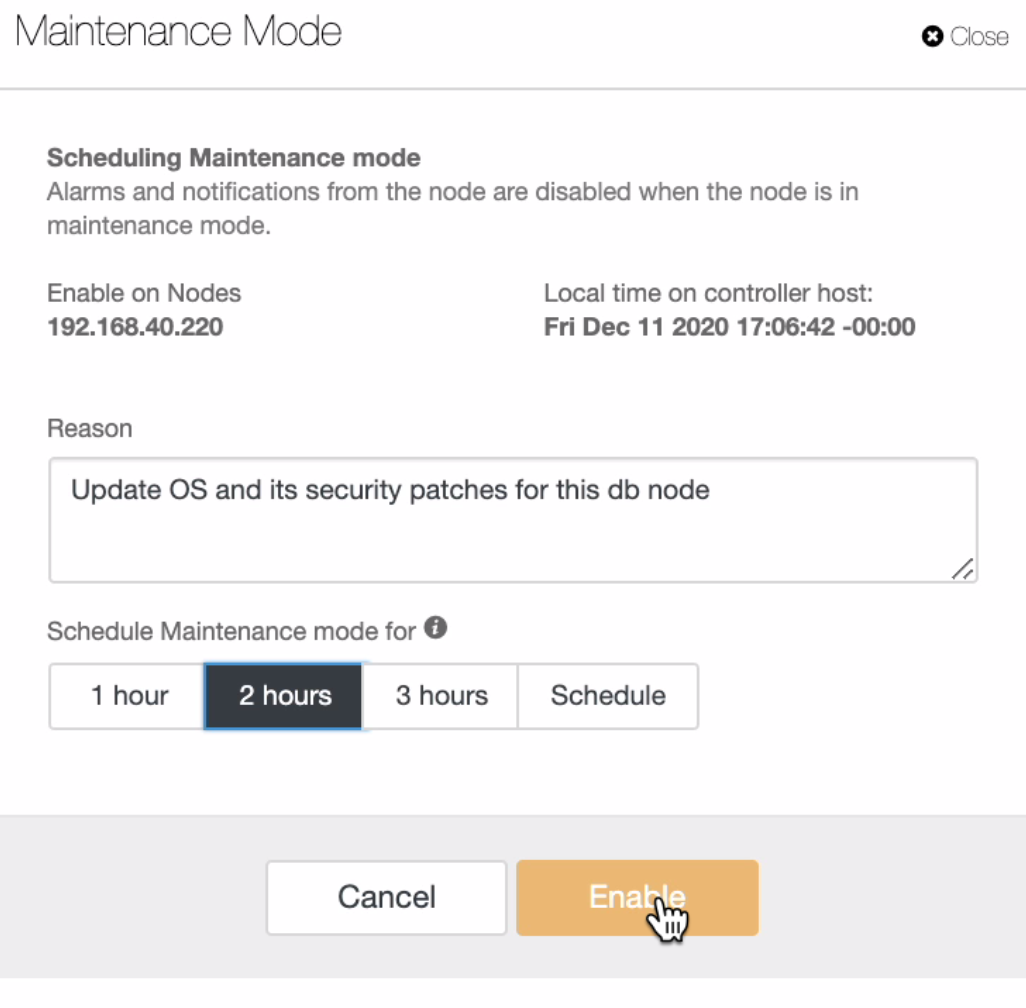
Then, choose the schedule or hours of maintenance
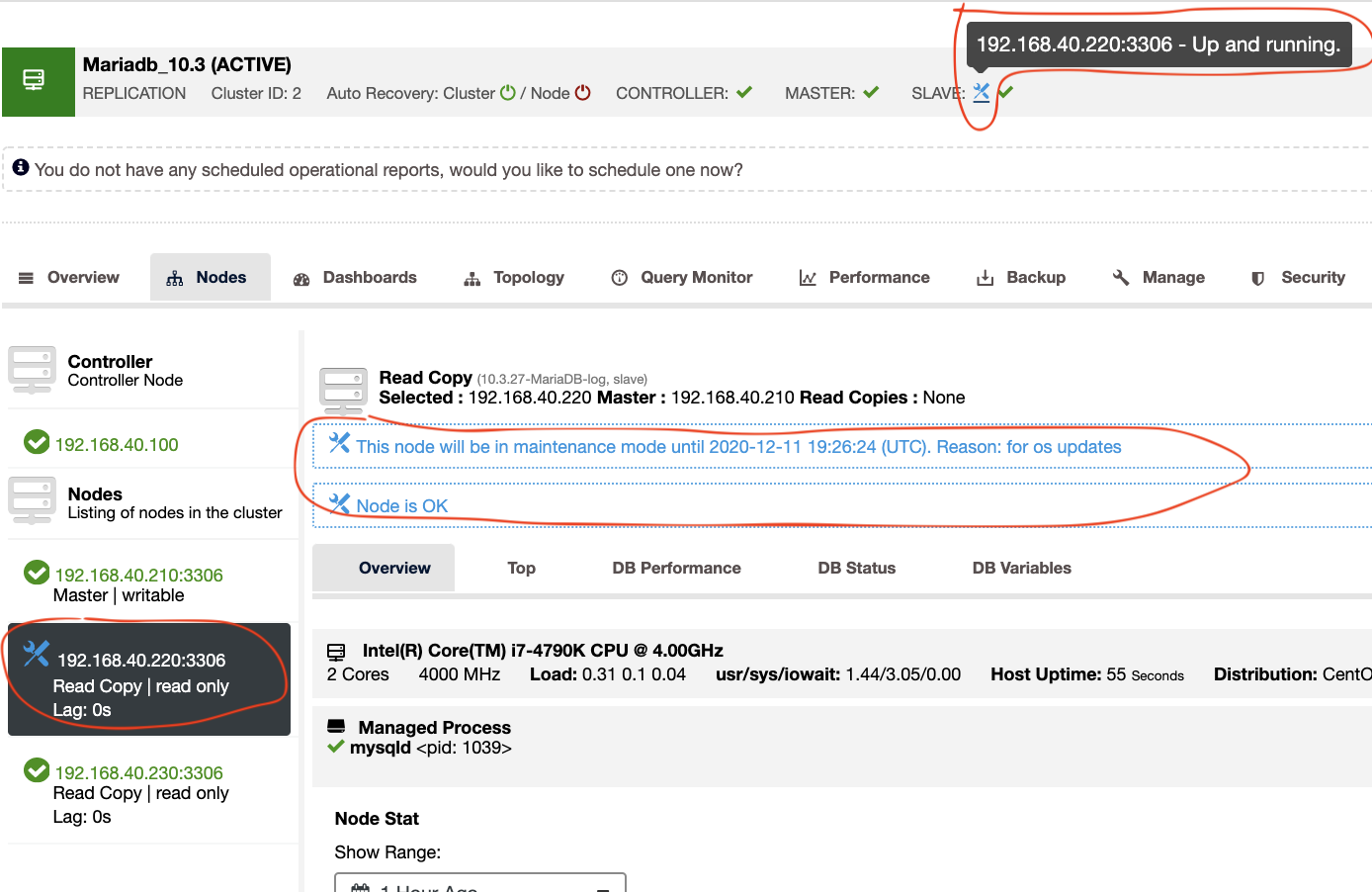
Markers or icons will allow you to determine of a node that is under maintenance. Maintenance in ClusterControl means that it automatically disables alarms and notifications. That means, any false alarms cannot pass through for those monitored targets (such as disk space issue, server is offline, etc.) shall be triggered. This pattern or procedure shall silence noise and avoid disturbing your perks for any e-mails sent in case the maintenance is ongoing.
Disable The Recovery Process
If you are new to ClusterControl, our software is a pure management and deployment for database tool which allows observability for nodes, not just monitoring alone but it reacts proactively based on unwanted events such as node failure. This comes up with an Auto Recovery feature. It does a cluster wide or only by node recovery. Based on the screenshots we have earlier, the auto recovery shows cluster recovery is enabled but not for a node. Since we are performing maintenance, the ClusterControl will not perform a node recovery for that particular node.
For a cluster-wide maintenance, then it shall make sense that the Auto Recovery for ClusterControl shall be disabled. This means that ClusterControl does not interfere with your maintenance task procedure. So if you have Auto Recovery mode either enabled or disabled, ClusterControl will not change nor affect how the recovery procedure shall be. It has to be ruled out by the DBA or the administrator applying the maintenance procedure, but there’s a way to handle this (we’ll talk on this later).
Node Recovery Disabled: How About My Other Nodes Will Recover If Failure Occurs?
That can be a good question. Now there’s no way you can do this using the ClusterControl UI. On the other hand, ClusterControl has a bunch of features that you can do under the hood. This can be done by setting the variable node_recovery_lock_file. The variable means as stated in our manual,
|
node_recovery_lock_file= |
Specify a lock file and if present on a node, the node will not recover. The administrator is responsible to create/remove the file. Example: node_recovery_lock_file=/root/do_not_recover. |
Cluster-Wide Database Maintenance
When performing a cluster-wide maintenance such that all nodes are all fine to take down to perform a maintenance procedure. Although this is likely not the case for every production environment, this can be a possible case to proceed. For example, if you have clusters running on different regions globally but each of them has a specific role, i.e. a current active cluster and then some can work as its disaster recovery (DR) environment. Yet, taking down the role of a DR cluster is fine since the backup DR’s and an active cluster is still online and unharmed. Of course, depending on the co-relationship with the other clusters when it comes to monitoring. There can be noise such as the other cluster shall fire up alarms or notification as the DR replication fails. So you have to take care of that as well, if that is the type of your monitoring process.
As mentioned earlier, ClusterControl has a cluster-wide maintenance feature. When performing a cluster-wide, it makes sense that you can disable the auto recovery both cluster and node recovery.
Silencing Alarms, Alerts, or Notifications
We have mentioned earlier that the Maintenance feature of ClusterControl disables alarms and notifications when set to a node or even on a cluster. Based on my experience working with database management procedures, there are cases that a specific cluster has been set isolated yet the ideal procedure is that it still allows sending emails, notifications, alarms but on a level of priority. In ClusterControl, it offers high flexibility which you can isolate your cluster for example and remain it dorman yet still functioning as normal. You can adjust the level of emails on how you can receive as part of notifications for alarms triggered. See below,
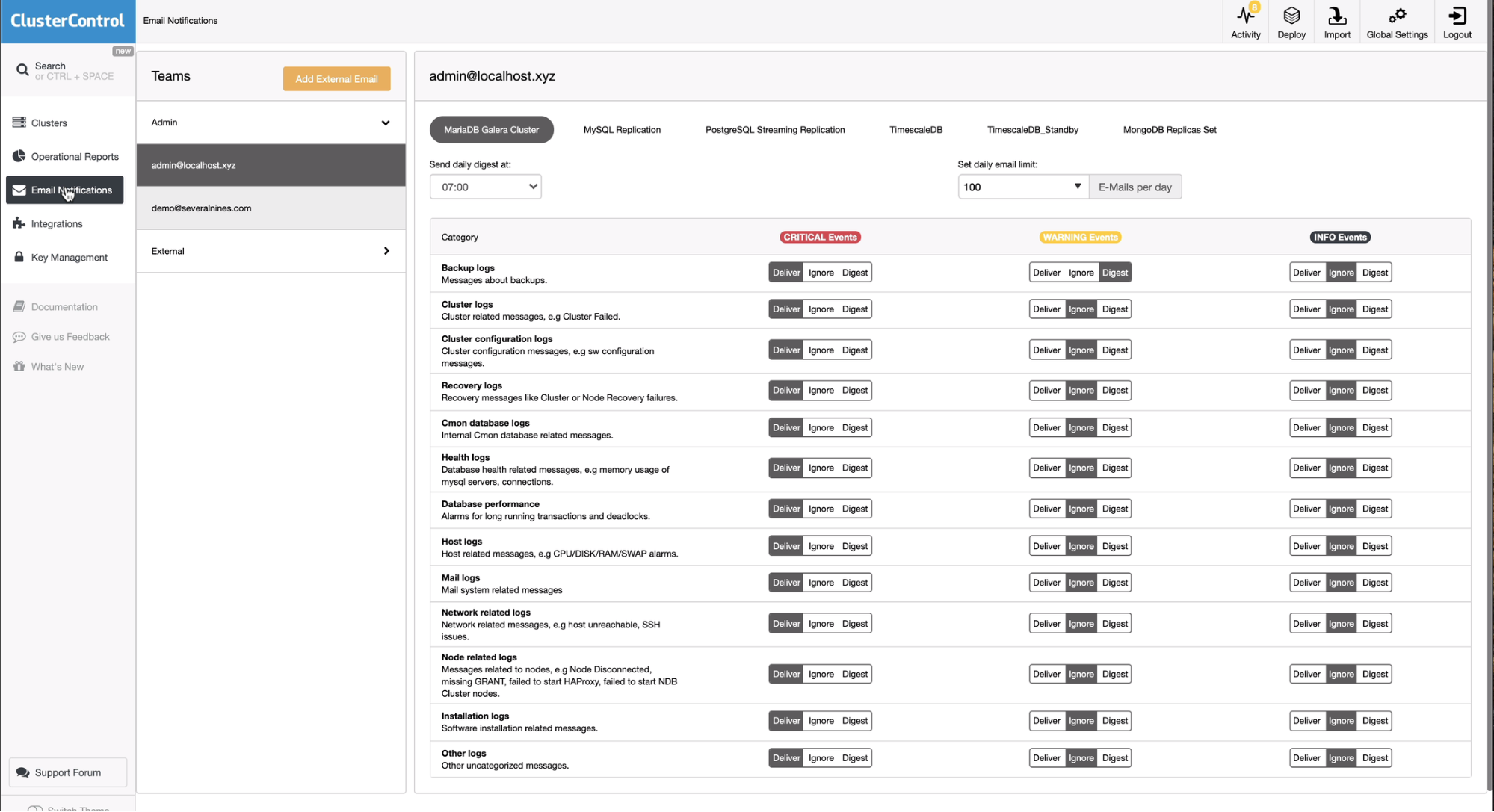
By going to the Email Notifications, you can select which cluster and then set the desired category of alarms or alerts. Either you can ignore it or send as digest as Deliver is not a desired option.
If you have set 3rd party integrations, you can also filter the cluster or set the type of events to be sent. See below,
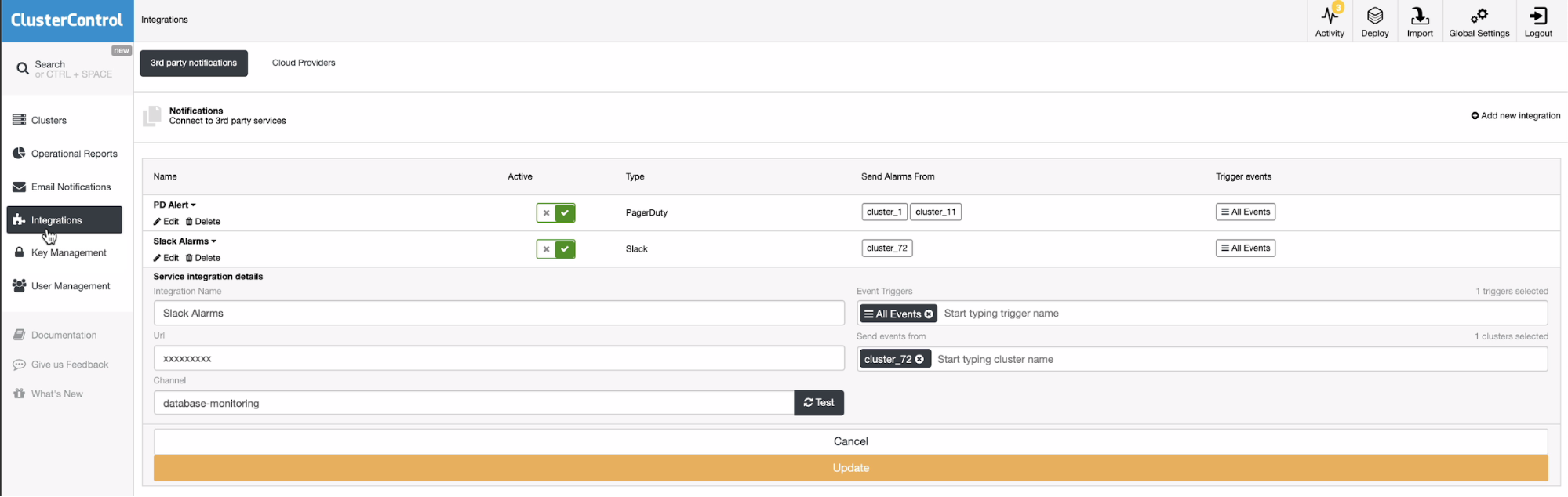
This type of procedure is possible to happen on a certain occasion of maintenance but what we are showing here offers more flexibility so that less noise and disturbance from your DBA’s and administrator’s work priority.
Advance Maintenance Procedures
Since the release of ClusterControl 1.7.5, it offers more powerful features and flexibility when performing maintenance. We suggest that you read our previous blog Cluster-Wide Database Maintenance and Why You Need It. Most of the advanced features can be benefited by using our s9s CLI tool. For example, the common process is applying a maintenance procedure and disable recovery modes. See the example with the following command you can use to apply this,
[root@pupnode10 ~]# s9s cluster --disable-recovery --log --cluster-id=2 --maintenance-minutes=60 --reason='OS update and database upgrade'
Using SSH credentials from cluster.
Cluster ID is 2.
The username is 'vagrant'.
Registering maintenance for 60 minute(s) for cluster 2.
Cluster ID is 2.
Cluster recovery is currently enabled.
Node recovery is currently enabled.
Disabling cluster auto recovery.
Disabling node auto recovery.The UI will be updated as well showing you the following alerts,
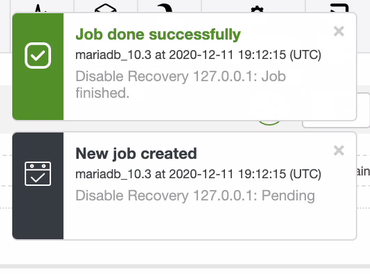
and as well marks the cluster as under maintenance.
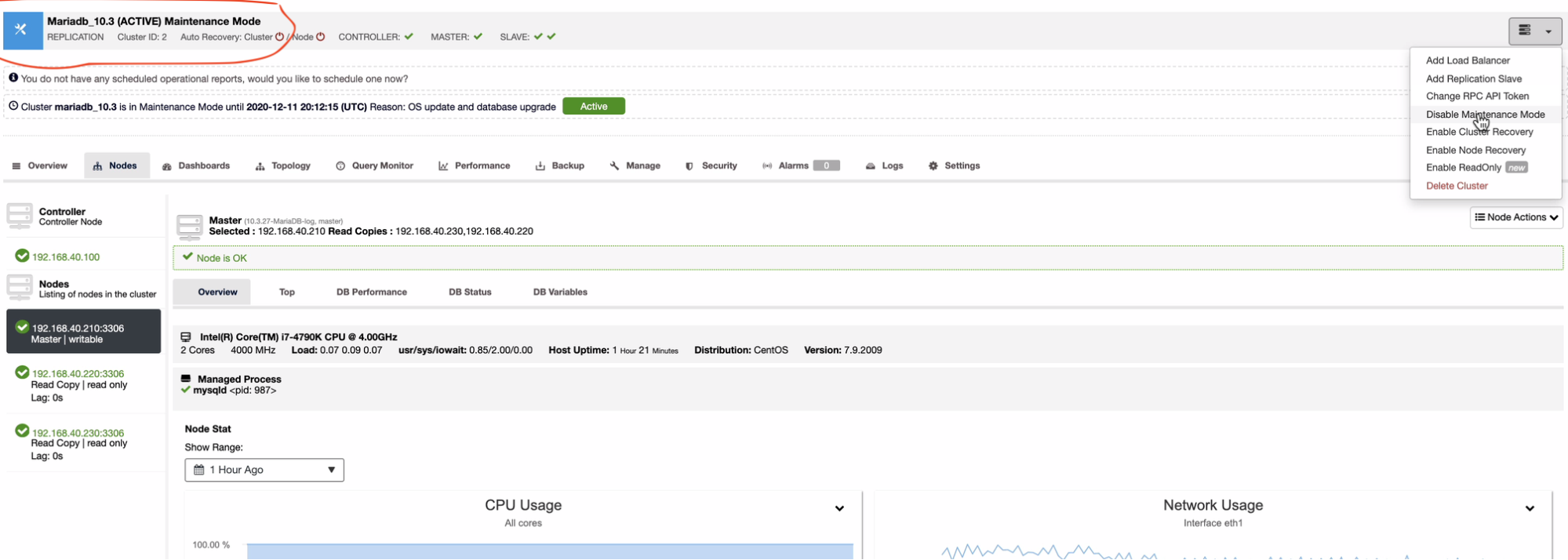
If the maintenance window is finished, you can just click the Disable Maintenance Mode as shown above, very feasible and easy to be done without any hassle or long task of work for the DBA’s.
Conclusion
ClusterControl offers flexibility when it comes to database maintenance. We have briefly shown you the common procedures and how to apply database maintenance. Yet, every maintenance practice differs and has to be carefully planned. This blog shows you ClusterControl does not interfere with any plans but only reacts based on the DBA or administrators plans.


