blog
Running Big Data Analytics Queries Using SQL and Presto

Presto is an open-source, parallel distributed, SQL engine for big data processing. It was developed from the ground-up by Facebook. The first internal release took place in 2013 and was quite a revolutionary solution for their big data problems.
With the hundreds of geo-located servers and petabytes of data, Facebook started to look for an alternative platform for their Hadoop clusters. Their infrastructure team wanted to reduce the time needed to run analytics batch jobs and simplify pipeline development by using programming language widely known in the organization – SQL.
According to Presto foundation, “Facebook uses Presto for interactive queries against several internal data stores, including their 300PB data warehouse. Over 1,000 Facebook employees use Presto daily to run more than 30,000 queries that in total scan over a petabyte each per day.”
While Facebook has an exceptional data warehouse environment, the same challenges are present in many organizations dealing with big data.
In this blog, we will take a look at how to set up a basic presto environment using a Docker server from the tar file. As a data source, we will focus on the MySQL data source, but it could be any other popular RDBMS.
Running Presto in Big Data Environment
Before we start, let’s take a quick look at its main architecture principles. Presto is an alternative to tools that query HDFS using pipelines of MapReduce jobs – such as Hive. Unlike Hive Presto doesn’t use MapReduce. Presto runs with a special-purpose query execution engine with high-level operators and in-memory processing.
In contrast to Hive Presto can stream data through all the stages at once running data chunks concurrently. It is designed to run ad-hoc analytic queries against single or distributed heterogeneous data sources. It can reach out from a Hadoop platform to query relational databases or other data stores like flat files.
Presto uses standard ANSI SQL including aggregations, joins or analytic window functions. SQL is well known and much easier to use comparing to MapReduce written in Java.
Deploying Presto to Docker
The basic Presto configuration can be deployed with a pre-configured Docker image or presto server tarball.
The docker server and Presto CLI containers can be easily deployed with:
docker run -d -p 127.0.0.1:8080:8080 --name presto starburstdata/presto
docker exec -it presto presto-cliYou may choose between two Presto server versions. Community version and Enterprise version from Starburst. Since we are going to run it in a non-production sandbox environment, we will use the Apache version in this article.
Pre-requirements
Presto is implemented entirely in Java and requires JVM to be installed on your system. It runs on both OpenJDK and Oracle Java. The minimum version is Java 8u151 or Java 11.
To download JAVA JDK visit https://openjdk.java.net/ or https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
You can check your Java version with
$ java -version
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.222-b10, mixed mode)Presto Installation
To install Presto we are going to download server tar and Presto CLI jar executable.
The tarball will contain a single top-level directory, presto-server-0.223, which we will call the installation directory.
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.223/presto-server-0.223.tar.gz
$ tar -xzvf presto-server-0.223.tar.gz
$ cd presto-server-0.223/
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.223/presto-cli-0.223-executable.jar
$ mv presto-cli-0.223-executable.jar presto
$ chmod +x prestoAdditionally, Presto needs a data directory for storing logs, etc.
It’s recommended to create a data directory outside of the installation directory.
$ mkdir -p ~/data/presto/This location is the place when we start our troubleshooting.
Configuring Presto
Before we start our first instance we need to create a bunch of configuration files. Start with the creation of an etc/ directory inside the installation directory. This location will hold the following configuration files:
etc/
- Node Properties – node environmental configuration
- JVM Config (jvm.config) – Java Virtual Machine config
- Config Properties(config.properties) -configuration for the Presto server
- Catalog Properties – configuration for Connectors (data sources)
- Log Properties – Loggers configuration
Below you can find some basic configuration to run Presto sandbox. For more details visit documentation.
vi etc/config.properties
Config.properties
coordinator = true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = http://localhost:8080
vi etc/jvm.config
-server
-Xmx8G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
vi etc/log.properties
com.facebook.presto = INFOvi etc/node.properties
node.environment = production
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir = /Users/bartez/data/prestoThe basic etc/ structure may look as follows:

The next step is to set up the MySQL connector.
We are going to connect to one of the 3 nodes MariaDB Cluster.
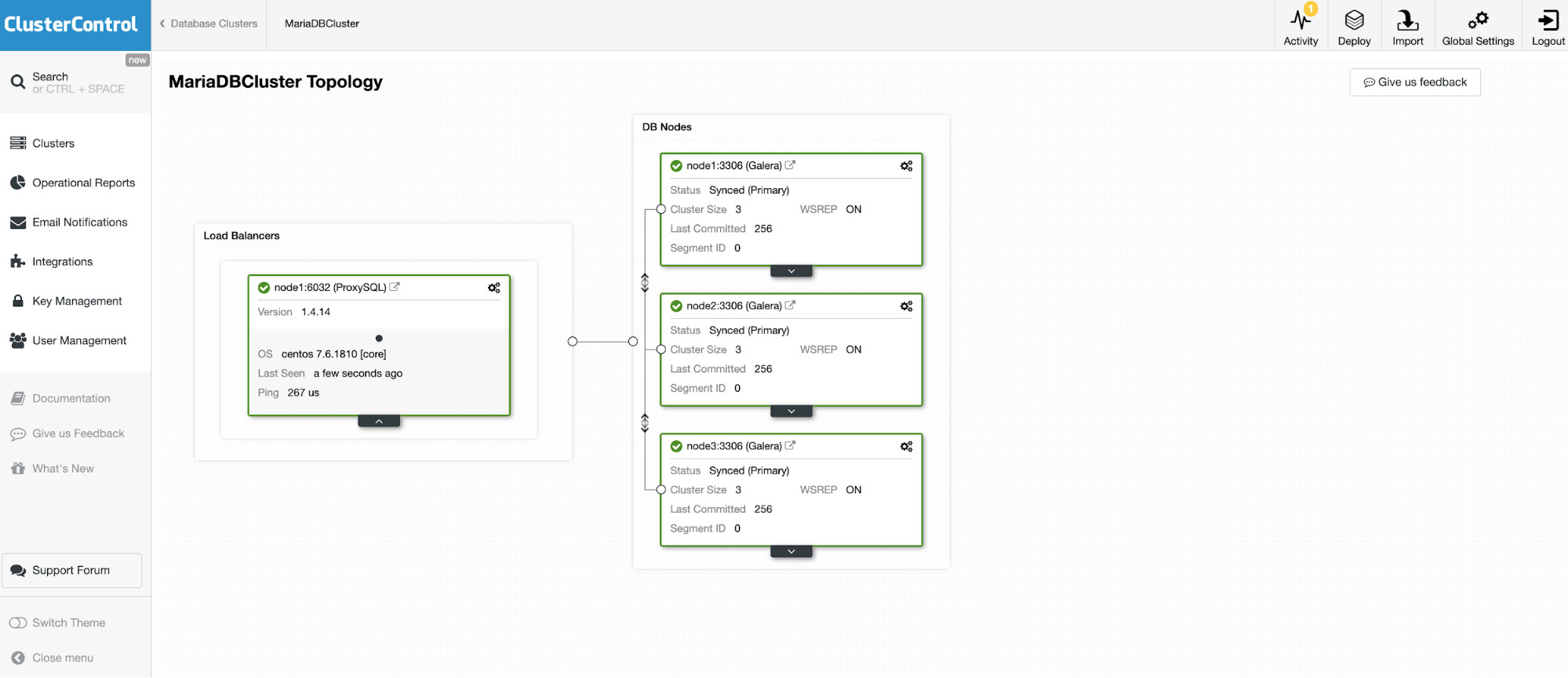
And another standalone instance running Oracle MySQL 5.7.
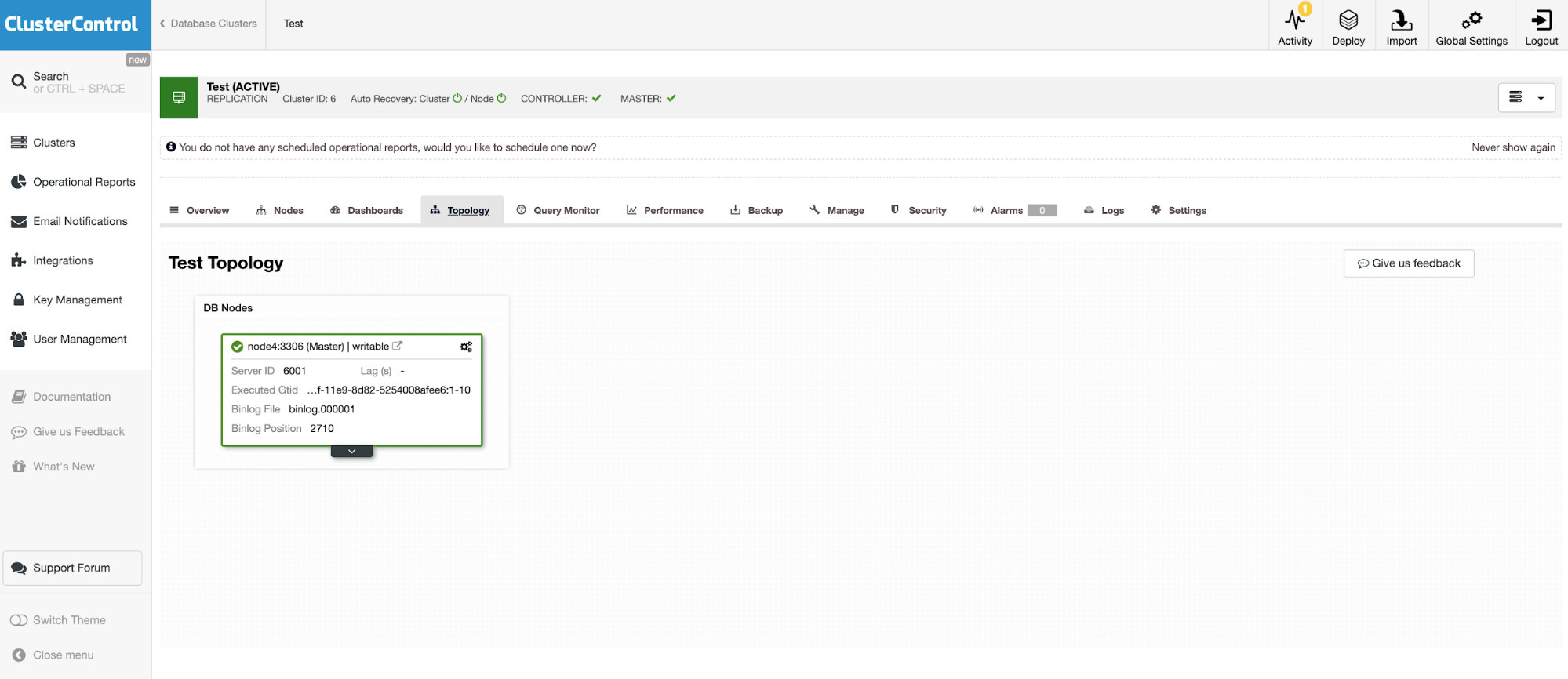
The MySQL connector allows querying and creating tables in an external MySQL database. This can be used to join data between different systems like MariaDB and MySQL from Oracle.
Presto uses pluggable connectors and the configuration is very easy. To configure the MySQL connector, create a catalog properties file in etc/catalog named, for example, mysql.properties, to mount the MySQL connector as the mysql catalog. Each of the files representing a connection to other server. In this case, we have two files:
vi etc/catalog/mysq.properties:
connector.name=mysql
connection-url=jdbc:mysql://node1.net:3306
connection-user=bart
connection-password=secretvi etc/catalog/mysq2.properties
connector.name=mysql
connection-url=jdbc:mysql://node4.net:3306
connection-user=bart2
connection-password=secretRunning Presto
When all is set it’s time to start Presto instance. To start presto go to the bin directory under preso installation and run the following:
$ bin/launcher start
Started as 18363To stop Presto run
$ bin/launcher stopNow when the server is up and running we can connect to Presto with CLI and query MySQL database.
To start Presto console run:
./presto --server localhost:8080 --catalog mysql --schema employeesNow we can query our databases via CLI.
presto:mysql> select * from mysql.employees.departments;
dept_no | dept_name
---------+--------------------
d009 | Customer Service
d005 | Development
d002 | Finance
d003 | Human Resources
d001 | Marketing
d004 | Production
d006 | Quality Management
d008 | Research
d007 | Sales
(9 rows)
Query 20190730_232304_00019_uq3iu, FINISHED, 1 node
Splits: 17 total, 17 done (100,00%)
0:00 [9 rows, 0B] [81 rows/s, 0B/s]Both databases MariaDB cluster and MySQL has been feed with employees database.
wget https://github.com/datacharmer/test_db/archive/master.zip
mysql -uroot -psecret < employees.sqlThe status of the query is also visible in the Presto web console: http://localhost:8080/ui/#
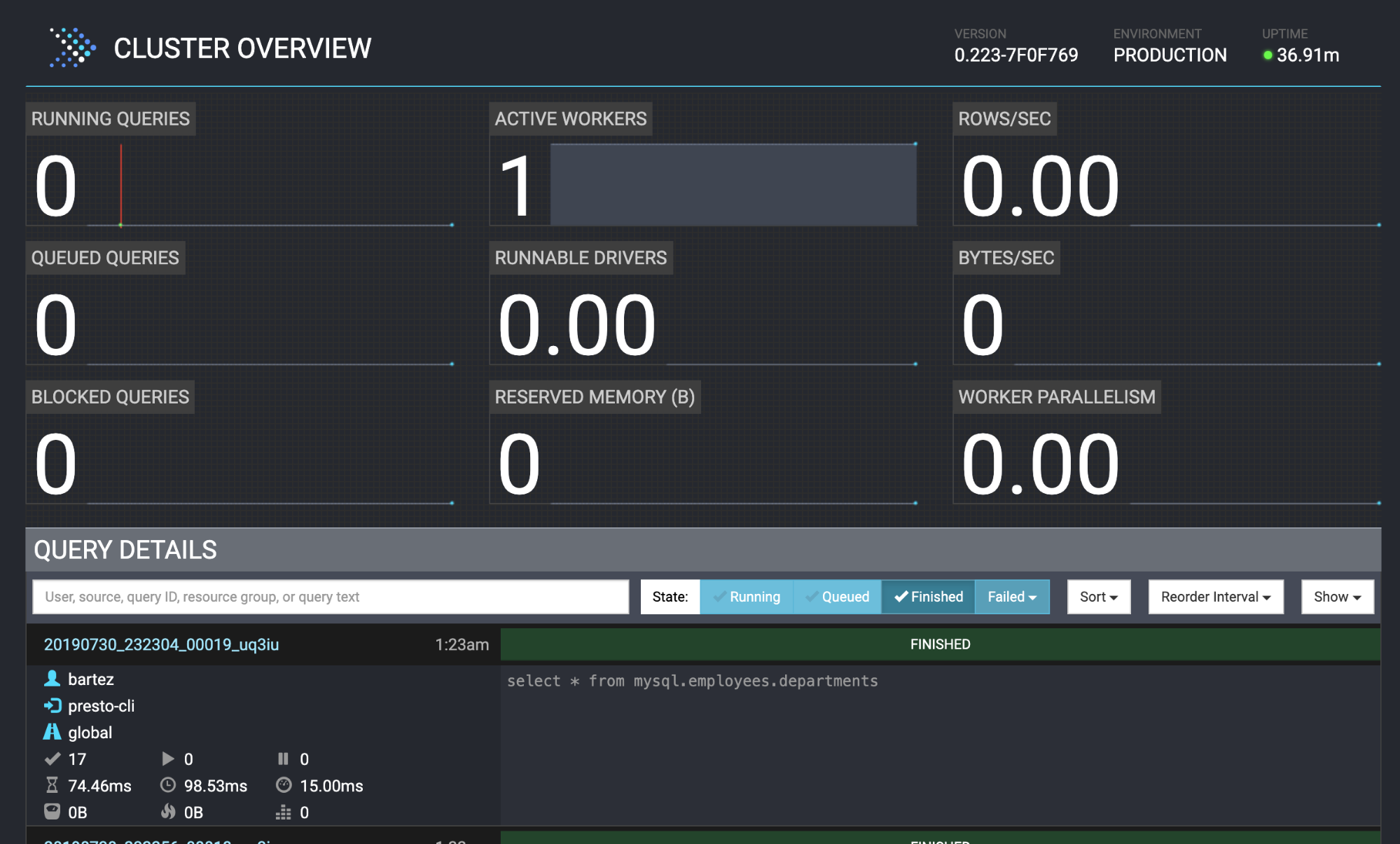
Conclusion
Many well known companies (like Airbnb, Netflix, Twitter) are adopting Presto for low latency performance. It’s without a doubt very interesting software which may eliminate the need for running heavy ETL data warehouse processes. In this blog, we just took a brief look at MySQL connector but you can use it to analyze data from HDFS, object stores, RDBMS (SQL Server, Oracle, PostgreSQL), Kafka, Cassandra, MongoDB, and many others.



