blog
Improve Performance of Galera Cluster for MySQL or MariaDB

Galera Cluster comes with many notable features that are not available in standard MySQL replication (or Group Replication); automatic node provisioning, true multi-master with conflict resolutions and automatic failover. There are also a number of limitations that could potentially impact cluster performance. Luckily, if you are not aware of these, there are workarounds. And if you do it right, you can minimize the impact of these limitations and improve overall performance.
We have previously covered many tips and tricks related to Galera Cluster, including running Galera on AWS Cloud. This blog post distinctly dives into the performance aspects, with examples on how to get the most out of Galera.
Replication Payload
A bit of introduction – Galera replicates writesets during the commit stage, transferring writesets from the originator node to the receiver nodes synchronously through the wsrep replication plugin. This plugin will also certify writesets on the receiver nodes. If the certification process passes, it returns OK to the client on the originator node and will be applied on the receiver nodes at a later time asynchronously. Else, the transaction will be rolled back on the originator node (returning error to the client) and the writesets that have been transferred to the receiver nodes will be discarded.
A writeset consists of write operations inside a transaction that changes the database state. In Galera Cluster, autocommit is default to 1 (enabled). Literally, any SQL statement executed in Galera Cluster will be enclosed as a transaction, unless you explicitly start with BEGIN, START TRANSACTION or SET autocommit=0. The following diagram illustrates the encapsulation of a single DML statement into a writeset:
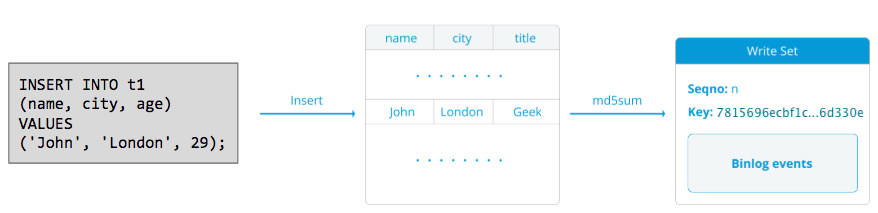
For DML (INSERT, UPDATE, DELETE..), the writeset payload consists of the binary log events for a particular transaction while for DDLs (ALTER, GRANT, CREATE..), the writeset payload is the DDL statement itself. For DMLs, the writeset will have to be certified against conflicts on the receiver node while for DDLs (depending on wsrep_osu_method, default to TOI), the cluster cluster runs the DDL statement on all nodes in the same total order sequence, blocking other transactions from committing while the DDL is in progress (see also RSU). In simple words, Galera Cluster handles DDL and DML replication differently.
Round Trip Time
Generally, the following factors determine how fast Galera can replicate a writeset from an originator node to all receiver nodes:
- Round trip time (RTT) to the farthest node in the cluster from the originator node.
- The size of a writeset to be transferred and certified for conflict on the receiver node.
For example, if we have a three-node Galera Cluster and one of the nodes is located 10 milliseconds away (0.01 second), it’s very unlikely you might be able to write more than 100 times per second to the same row without conflicting. There is a popular quote from Mark Callaghan which describes this behaviour pretty well:
“[In a Galera cluster] a given row can’t be modified more than once per RTT”
To measure RTT value, simply perform ping on the originator node to the farthest node in the cluster:
$ ping 192.168.55.173 # the farthest nodeWait for a couple of seconds (or minutes) and terminate the command. The last line of the ping statistic section is what we are looking for:
--- 192.168.55.172 ping statistics ---
65 packets transmitted, 65 received, 0% packet loss, time 64019ms
rtt min/avg/max/mdev = 0.111/0.431/1.340/0.240 msThe max value is 1.340 ms (0.00134s) and we should take this value when estimating the minimum transactions per second (tps) for this cluster. The average value is 0.431ms (0.000431s) and we can use to estimate the average tps while min value is 0.111ms (0.000111s) which we can use to estimate the maximum tps. The mdev means how the RTT samples were distributed from the average. Lower value means more stable RTT.
Hence, transactions per second can be estimated by dividing RTT (in second) into 1 second:
Resulting,
- Minimum tps: 1 / 0.00134 (max RTT) = 746.26 ~ 746 tps
- Average tps: 1 / 0.000431 (avg RTT) = 2320.19 ~ 2320 tps
- Maximum tps: 1 / 0.000111 (min RTT) = 9009.01 ~ 9009 tps
Note that this is just an estimation to anticipate replication performance. There is not much we can do to improve this on the database side, once we have everything deployed and running. Except, if you move or migrate the database servers closer to each other to improve the RTT between nodes, or upgrade the network peripherals or infrastructure. This would require maintenance window and proper planning.
Chunk Up Big Transactions
Another factor is the transaction size. After the writeset is transferred, there will be a certification process. Certification is a process to determine whether or not the node can apply the writeset. Galera generates MD5 checksum pseudo keys from every full row. The cost of certification depends on the size of the writeset, which translates into a number of unique key lookups into the certification index (a hash table). If you update 500,000 rows in a single transaction, for example:
# a 500,000 rows table
mysql> UPDATE mydb.settings SET success = 1;The above will generate a single writeset with 500,000 binary log events in it. This huge writeset does not exceed wsrep_max_ws_size (default to 2GB) so it will be transferred over by Galera replication plugin to all nodes in the cluster, certifying these 500,000 rows on the receiver nodes for any conflicting transactions that are still in the slave queue. Finally, the certification status is returned to the group replication plugin. The bigger the transaction size, the higher risk it will be conflicting with other transactions that come from another master. Conflicting transactions waste server resources, plus cause a huge rollback to the originator node. Note that a rollback operation in MySQL is way slower and less optimized than commit operation.
The above SQL statement can be re-written into a more Galera-friendly statement with the help of simple loop, like the example below:
(bash)$ for i in {1..500}; do
mysql -uuser -ppassword -e "UPDATE mydb.settings SET success = 1 WHERE success != 1 LIMIT 1000";
sleep 2;
doneThe above shell command would update 1000 rows per transaction for 500 times and wait for 2 seconds between executions. You could also use a stored procedure or other means to achieve a similar result. If rewriting the SQL query is not an option, simply instruct the application to execute the big transaction during a maintenance window to reduce the risk of conflicts.
For huge deletes, consider using pt-archiver from the Percona Toolkit – a low-impact, forward-only job to nibble old data out of the table without impacting OLTP queries much.
Parallel Slave Threads
In Galera, the applier is a multithreaded process. Applier is a thread running within Galera to apply the incoming write-sets from another node. Which means, it is possible for all receivers to execute multiple DML operations that come right from the originator (master) node simultaneously. Galera parallel replication is only applied to transactions when it is safe to do so. It improves the probability of the node to sync up with the originator node. However, the replication speed is still limited to RTT and writeset size.
To get the best out of this, we need to know two things:
- The number of cores the server has.
- The value of wsrep_cert_deps_distance status.
The status wsrep_cert_deps_distance tells us the potential degree of parallelization. It is the value of the average distance between highest and lowest seqno values that can be possibly applied in parallel. You can use the wsrep_cert_deps_distance status variable to determine the maximum number of slave threads possible. Take note that this is an average value across time. Hence, in order get a good value, you have to hit the cluster with writes operations through test workload or benchmark until you see a stable value coming out.
To get the number of cores, you can simply use the following command:
$ grep -c processor /proc/cpuinfo
4Ideally, 2, 3 or 4 threads of slave applier per CPU core is a good start. Thus, the minimum value for the slave threads should be 4 x number of CPU cores, and must not exceed the wsrep_cert_deps_distance value:
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_cert_deps_distance';
+--------------------------+----------+
| Variable_name | Value |
+--------------------------+----------+
| wsrep_cert_deps_distance | 48.16667 |
+--------------------------+----------+You can control the number of slave applier threads using wsrep_slave_thread variable. Even though this is a dynamic variable, only increasing the number would have an immediate effect. If you reduce the value dynamically, it would take some time, until the applier thread exits after it finishes applying. A recommended value is anywhere between 16 to 48:
mysql> SET GLOBAL wsrep_slave_threads = 48;Take note that in order for parallel slave threads to work, the following must be set (which is usually pre-configured for Galera Cluster):
innodb_autoinc_lock_mode=2Galera Cache (gcache)
Galera uses a preallocated file with a specific size called gcache, where a Galera node keeps a copy of writesets in circular buffer style. By default, its size is 128MB, which is rather small. Incremental State Transfer (IST) is a method to prepare a joiner by sending only the missing writesets available in the donor’s gcache. IST is faster than state snapshot transfer (SST), it is non-blocking and has no significant performance impact on the donor. It should be the preferred option whenever possible.
IST can only be achieved if all changes missed by the joiner are still in the gcache file of the donor. The recommended setting for this is to be as big as the whole MySQL dataset. If disk space is limited or costly, determining the right size of the gcache size is crucial, as it can influence the data synchronization performance between Galera nodes.
The below statement will give us an idea of the amount of data replicated by Galera. Run the following statement on one of the Galera nodes during peak hours (tested on MariaDB >10.0 and PXC >5.6, galera >3.x):
mysql> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;
+--------+---------+-----------------+-----------------------+
| MB/min | MB/hour | gcache Size(MB) | Time to full(minutes) |
+--------+---------+-----------------+-----------------------+
| 7.95 | 477.00 | 128 | 16.10 |
+--------+---------+-----------------+-----------------------+We can estimate that the Galera node can have approximately 16 minutes of downtime, without requiring SST to join (unless Galera cannot determine the joiner state). If this is too short time and you have enough disk space on your nodes, you can change the wsrep_provider_options=”gcache.size=
It’s also recommended to use gcache.recover=yes in wsrep_provider_options (Galera >3.19), where Galera will attempt to recover the gcache file to a usable state on startup rather than delete it, thus preserving the ability to have IST and avoiding SST as much as possible. Codership and Percona have covered this in details in their blogs. IST is always the best method to sync up after a node rejoins the cluster. It is 50% faster than xtrabackup or mariabackup and 5x faster than mysqldump.
Asynchronous Slave
Galera nodes are tightly-coupled, where the replication performance is as fast as the slowest node. Galera use a flow control mechanism, to control replication flow among members and eliminate any slave lag. The replication can be all fast or all slow on every node and is adjusted automatically by Galera. If you want to know about flow control, read this blog post by Jay Janssen from Percona.
In most cases, heavy operations like long running analytics (read-intensive) and backups (read-intensive, locking) are often inevitable, which could potentially degrade the cluster performance. The best way to execute this type of queries is by sending them to a loosely-coupled replica server, for instance, an asynchronous slave.
An asynchronous slave replicates from a Galera node using the standard MySQL asynchronous replication protocol. There is no limit on the number of slaves that can be connected to one Galera node, and chaining it out with an intermediate master is also possible. MySQL operations that execute on this server won’t impact the cluster performance, apart from the initial syncing phase where a full backup must be taken on the Galera node to stage the slave before establishing the replication link (although ClusterControl allows you to build the async slave from an existing backup first, before connecting it to the cluster).
GTID (Global Transaction Identifier) provides a better transactions mapping across nodes, and is supported in MySQL 5.6 and MariaDB 10.0. With GTID, the failover operation on a slave to another master (another Galera node) is simplified, without the need to figure out the exact log file and position. Galera also comes with its own GTID implementation but these two are independent to each other.
Scaling out an asynchronous slave is one-click away if you are using ClusterControl -> Add Replication Slave feature:

Take note that binary logs must be enabled on the master (the chosen Galera node) before we can proceed with this setup. We have also covered the manual way in this previous post.
The following screenshot from ClusterControl shows the cluster topology, it illustrates our Galera Cluster architecture with an asynchronous slave:
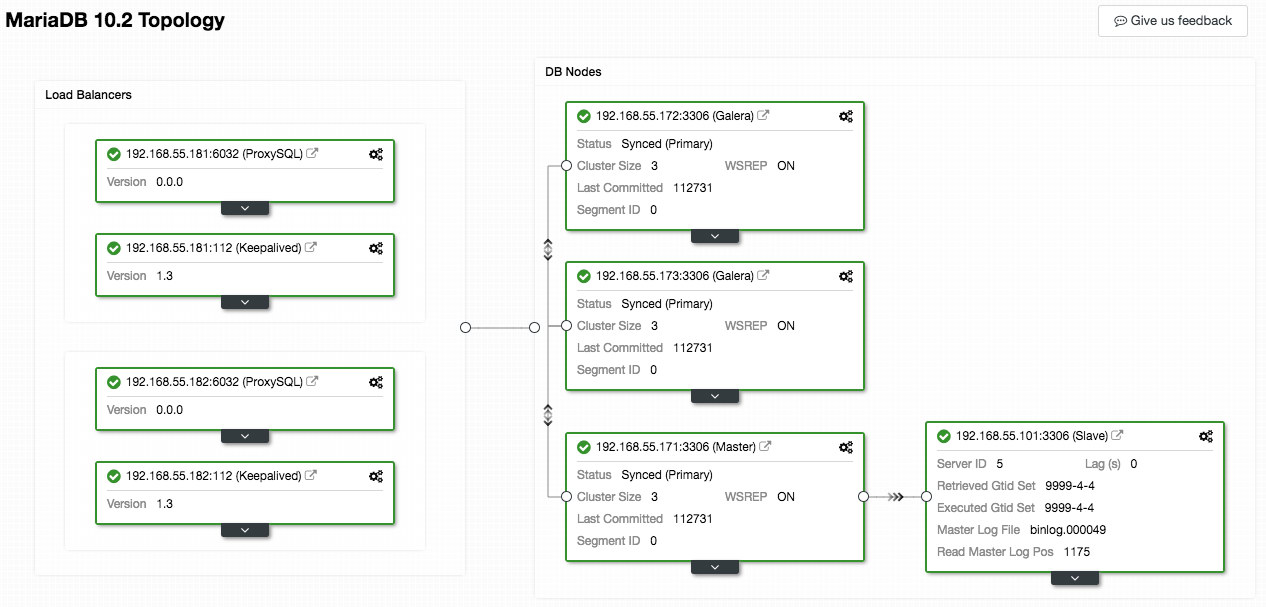
ClusterControl automatically discovers the topology and generates the super cool diagram like above. You can also perform administration tasks directly from this page by clicking on the top-right gear icon of each box.
SQL-aware Reverse Proxy
ProxySQL and MariaDB MaxScale are intelligent reverse-proxies which understand MySQL protocol and is capable of acting as a gateway, router, load balancer and firewall in front of your Galera nodes. With the help of Virtual IP Address provider like LVS or Keepalived, and combining this with Galera multi-master replication technology, we can have a highly available database service, eliminating all possible single-point-of-failures (SPOF) from the application point-of-view. This will surely improve the availability and reliability the architecture as whole.
Another advantage with this approach is you will have the ability to monitor, rewrite or re-route the incoming SQL queries based on a set of rules before they hit the actual database server, minimizing the changes on the application or client side and routing queries to a more suitable node for optimal performance. Risky queries for Galera like LOCK TABLES and FLUSH TABLES WITH READ LOCK can be prevented way ahead before they would cause havoc to the system, while impacting queries like “hotspot” queries (a row that different queries want to access at the same time) can be rewritten or being redirected to a single Galera node to reduce the risk of transaction conflicts. For heavy read-only queries like OLAP or backup, you can route them over to an asynchronous slave if you have any.
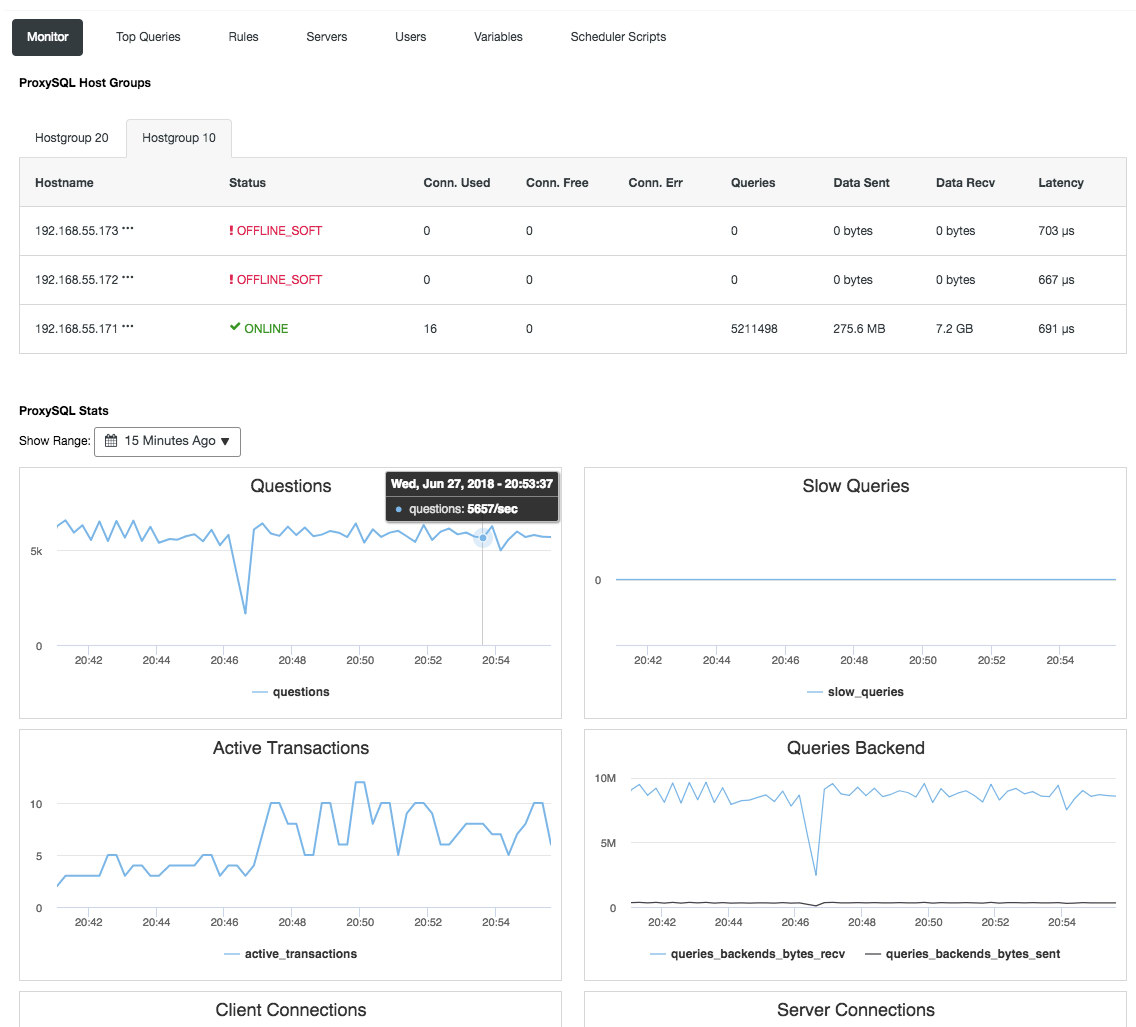
Reverse proxy also monitors the database state, queries and variables to understand the topology changes and produce an accurate routing decision to the backend servers. Indirectly, it centralizes the nodes monitoring and cluster overview without the need to check on each and every single Galera node regularly. The following screenshot shows the ProxySQL monitoring dashboard in ClusterControl:
There are also many other benefits that a load balancer can bring to improve Galera Cluster significantly, as covered in details in this blog post, Become a ClusterControl DBA: Making your DB components HA via Load Balancers.
Final Thoughts
With good understanding on how Galera Cluster internally works, we can work around some of the limitations and improve the database service. Happy clustering!



