blog
Disaster Recovery Options for PostgreSQL Deployed to a Hybrid Cloud

In our previous Hybrid Cloud blogs, we often mention that one of the primary options of availing the Hybrid Cloud topology setup is to use this as your disaster recovery target. It’s common for an organizational structure that a Disaster Recovery Plan (DRP) is always addressed before the architectural implementation of your database setup, either in the cloud or on-prem. You might think that everything shall fail unpredictably and can affect your business tragically if it’s not addressed and understood correctly. Overcoming these challenges requires an effective DRP (Disaster Recovery Plan), for which your system is well configured according to your application, infrastructure, and business requirements. The key to success in these types of situations is how fast we can fix or recover from the issue.
While DRP addresses the disaster circumstances, Business Continuity will make sure that DRP is tested and operational at all times when necessary. Your Disaster Recovery options for your databases must ensure continuous operations and bounds to the limits of expectations. It has to be in line with your desired RTO and RPO. It is imperative to ensure that production databases are available for the applications even during disasters; otherwise, it could end up being an expensive deal. DBAs, the Architects, need to ensure that database environments can sustain disasters and are disaster recovery SLA compliant. Database deployments must be configured correctly to ensure disasters do not affect database availability and business continuity.
Disaster Recovery Options
Your PostgreSQL cluster must be configured with a systematic approach that commits to the best practices and is acceptable to the industry standards. Along with the systematic approaches, the following processes or mechanisms helps you ensure that your PostgreSQL deployed to a Hybrid Cloud has these presences:
-
Failover/Switchover
-
Automated Backup
-
Highly Available
-
Load Balancing
-
Highly Distributed Environment
Failover/Switchover
Failover is an automated process in case your master fails; either hot standby or warm standby server is promoted to the role of primary/master. It is a best practice that affords a high availability environment to have at least a secondary node to act as a candidate for a failover node. Once the primary server fails, the standby server should begin the failover procedures, and then the secondary or standby server shall take the role of a master. A failover system utilizes a minimum of two servers in common practice, which serves as the primary and the standby. Its connectivity check is assisted by a heartbeat mechanism that does non-stop checks and verifies if both are in a good state and communication is alive. However, in some cases, the connectivity can give a false alarm. Therefore, in some setups and environments, a presence of a third system such as a monitoring node lies on a separate network or datacenter. This is a foolproof option to prevent inappropriate or unwanted failover. A foolproof verification node can possess extra features and checks, which adds complexity. This setup requires full and rigorous testing to ensure failover is done right when there is a change in the implementation. Also, this is important to prevent any deterioration of your PostgreSQL
Let’s say you have your secondary or standby cluster on a different datacenter with a different hardware setup; you might not want to failover abruptly, especially if it’s not an ideal case because of just a false positive. However, in this scenario, your data recovery target node or cluster must have the same resources and specifications as your primary node or cluster. If your data recovery target is in a public cloud and primary is on-prem, ensure that it has been already covered in your capacity planning and resources have almost the same specifications to avoid unwanted results.
When utilizing and preparing for your failover mechanism in your PostgreSQL Cluster within a Hybrid Cloud, you have to make sure that your tool is a perfect fit to carry the job that is supposed to achieve. There are third-party tools that are not bundled in PostgreSQL with regards to advance failover. For example, there’s ClusterControl, pg_auto_failover by CitusData (c/o Microsoft), Pgpool-II, Bucardo and others. These advanced utility tools provide node fencing or famously known as STONITH (shoot the other node in the head). This ensures that your failed primary or master node shall avoid accepting writes or coming back online as its previous state to serve normal transactions. This issue is commonly known as split-brain scenario. It loses data synchronization due to a failure (hardware or resource level) but still your primary servers, which is supposedly only one primary server, act as if doing normal recipients of data write requests causing cluster-wide data corruption.
Automated Backup
Backups always provide high assurance and safeguards against data loss. Backup maximises your RPO as it aids to minimize data loss when disaster strikes. Things you have to consider and prepare for your automated backup covers your backup appliance/hardware, backup data redundancy, security, performance, speed, and data storage.
Backup Appliance
You must have the best choice for your backup appliance here. Speed, significant storage volume, and highly available can be your desired choice. Some rely on SAN or NAS storage or spread out their data to other third-party backup storage providers. It’s essential that your backup appliance offers speed for writing and reading data, especially if you apply compression and encryption for your data at rest. Decompression and decryption require resources, so you have to consider when you have to use data recovery. During this state, you have to determine that you have to achieve your maximum RPO and commit the achievable SLA (Service-Level Agreement) to your customers. It’s also ideal that you might have to isolate your backup from your local network or store it in a remote location. An alternative approach is to engage with third-party providers. For instance, storing your backup in the cloud can be an option, and their facility is highly sophisticated and satisfies your requirements.
Backup Data Redundancy
Spreading your data in multiple locations is an ideal solution. This strengthens your data recovery chances, for example, a human error or a software logic error causing you to delete old copies of backup but mistakenly deleting the whole crucial backup copies. In some sophisticated environments, such as storing in a cloud environment such as Amazon S3, Cloud Storage by Google, or Azure Blob Storage offers replication of your file stored. This provides more redundancy and can be setup in a flexible manner that fits your requirements.
Highly Available
A highly available PostgreSQL cluster in a Hybrid Cloud always assures that your database communication ensures uptime. The ideal case of high availability depends on the measurement of your availability. In this case, a common setup for a PostgreSQL deployed in a hybrid cloud can be either your database hosted in a public cloud can be your secondary cluster acting as your data recovery cluster in case the primary cluster fails or suffers a network disaster and can take much downtime. In some setup, it is possible that the secondary cluster lying in the public cloud might not be exactly as sophisticated as the primary, lets say this is your on-prem or private cloud. Your application can play around to limit the visitors or traffic that can connect to your database. This type of scenario can lessen your setup cost, but of course, this only depends on your requirements. If your application type is massive and has to be non-stop receiving normal to busy traffic situations, make sure your secondary cluster resources have to be as powerful as the primary to ensure high availability, i.e. 99.9999999%.
To achieve a highly available PostgreSQL cluster in a hybrid cloud environment, you need to have a failover mechanism. In case of a failure and a primary cluster or primary server goes down, a secondary or standby server can then take the role of a master whichever its location can be. The most important thing is the functionality, and the performance, especially from the application or client standpoint, are not affected at all or at least very minimal.
Load Balancing
Load balancing mechanism for your PostgreSQL cluster aids your hybrid cloud setup, which is more manageable and less risky, especially when high traffic load occurs. In many situations,a server is receiving a severe high load cause the server to panic. This leads to a server unusable state due to busy resources consumed by a lot of threads running in the background. This situation can be improved by fixing bad queries and the design architecture of your database. This should include how you distribute the read against write load and a depth understanding of your application requirements like master-master setup or just one master but scaling it vertically to provide higher computing and memory resources. There is also a great selection of third party tools such as pgbouncer and Pgpool II to aid your PostgreSQL deployment in a hybrid cloud environment.
Highly Distributed Environment
Scalability wise, being highly distributed in multiple locations or different cloud providers (on-prem or private and public cloud) provides more flexibility and tolerability in a hybrid cloud environment and this is great for disaster recovery. It is flexible when it needs to failover on a particular cloud location favourable to natural disaster or catastrophe, especially if your designated region where your primary cluster resides is currently devastated or affected by a natural cause. This is an inevitable cause which you have to understand and be reliable of the current situation. Your application and clients have to be served continuously non-stop. This serves the purpose of being available publicly in the cloud while also serving in a private or on-premise environment. This setup adds more high complexity and requires advanced knowledge on the database side and security and networking. Optimization and tuning are crucial to success here since it’s very important that while serving a tightened security to encapsulate your data while travelling on the internet, performance has to be proven to stabilise and’s not affected by the implemented setup.
Due to setup complexity, having a tool is ideal for managing the deployment and facilitating your databases’ overall status, overseeing the one aspect of your cluster but on the whole level from on-prem, private cloud, and on the public cloud aspect. All setups must be kept at a manageable and straightforward level so that in case of alarms and alerts, it’s easy to fix and address the issue properly and timely.
ClusterControl For Disaster Recovery In A Hybrid Cloud Environment
ClusterControl allows the organization or companies to manage the database with flexibility and reduce the setup’s overall complexity. ClusterControl offers failover, automated backup, provides a highly available setup, load balancing, and supports a distributed environment deployment, making it easier to add nodes either in a public cloud or privately or on-prem.
ClusterControl Auto Recovery
The Auto Recovery of ClusterControl represents tons of failover mechanism and recovery characteristics especially when a node goes down or a cluster goes into a degraded state. This can be easily done as shown in the screenshot below:
Backup And Restore
ClusterControl also has a Backup and Restore feature that allows you to manage your backup, create a backup, schedule a backup, and restore a backup. Managing your backup is very straightforward and creating or scheduling a backup is simple yet also offers advanced options. It also offers cloud backup options that allow you to have backup data redundancy,, strengthening your Disaster Recovery options. See below:
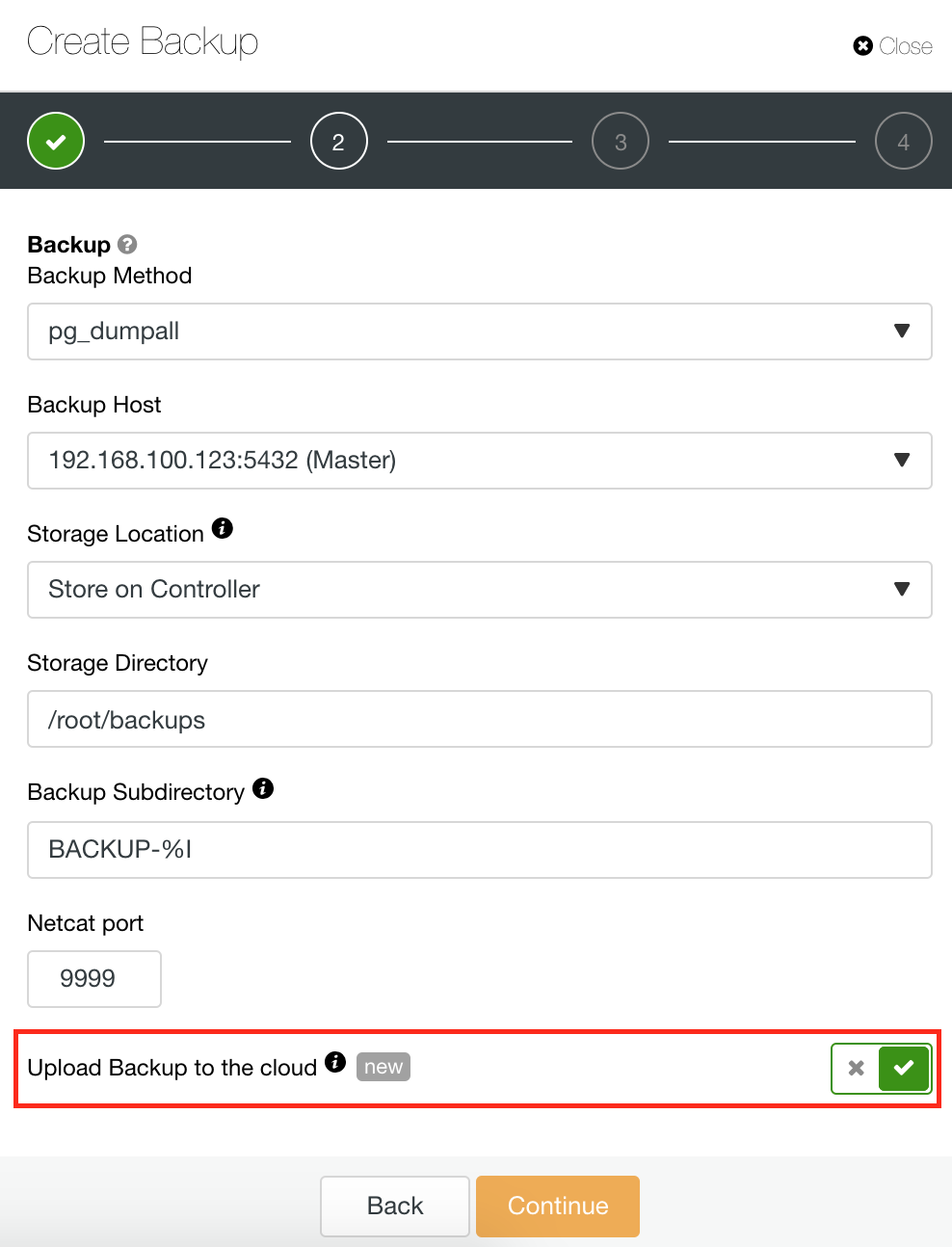
As shown below, managing your backup provides a simple UI for you to select which backup you want to restore, or you might have to drop. ClusterControl backup allows you to choose a retention period, so in case you have a long list, some of these can be deleted when it reaches its retention period.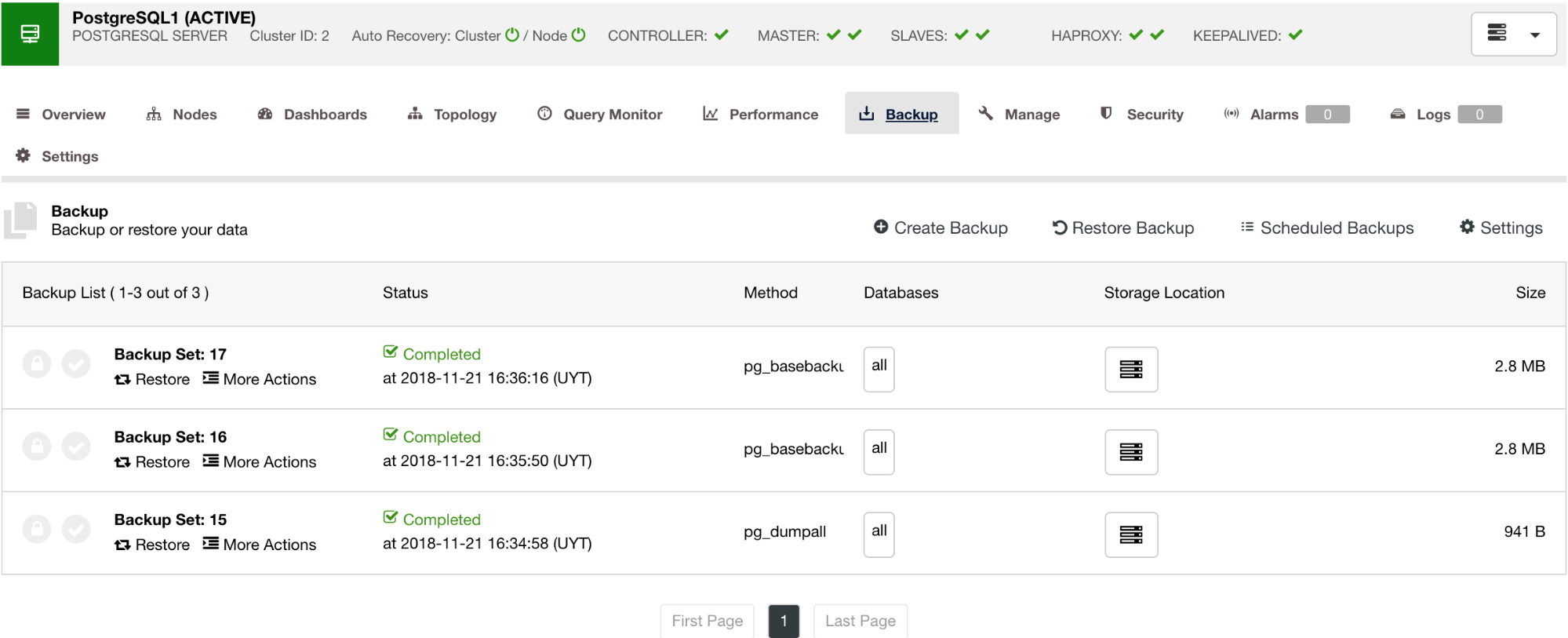
Supports High Availability (HA) and Load Balancing (LB) Mechanisms
You don’t need to setup manually or even research some ways to add high availability in your PostgreSQL cluster. There’s an easy and convenient way to get the job done with ClusterControl. If you can see the example screenshot, it has a HAProxy and Keepalived setup. See screenshot below:
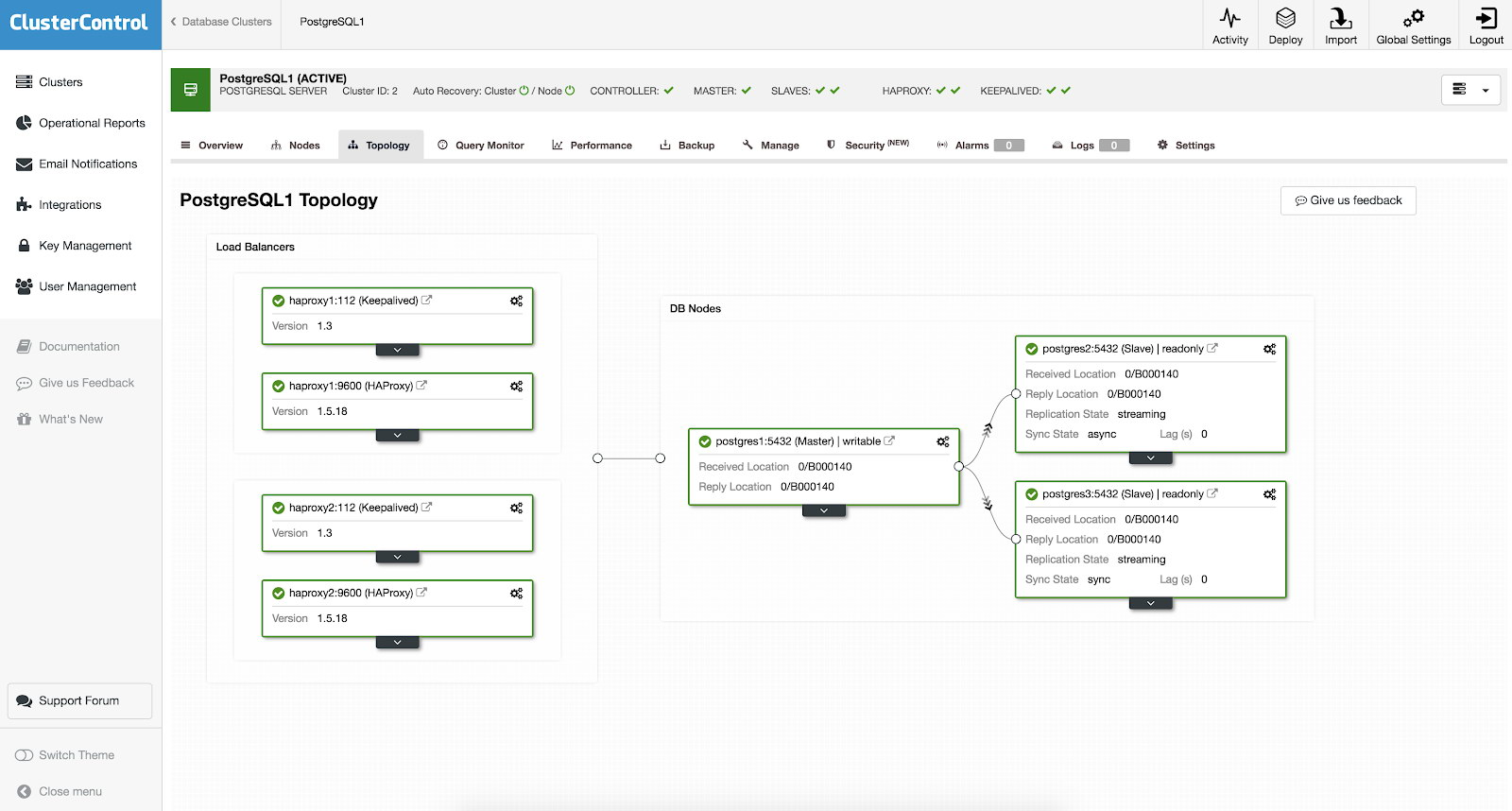
Setting up a high availability with ClusterControl can be done by getting through
Supports Distributed Environment
If you want to have distributions evenly from on-prem or private cloud to public cloud, ClusterControl also supports cloud deployment. But for a PostgreSQL cluster and you plan to have a secondary slave residing on a different cloud, you can create a slave cluster as shown below,
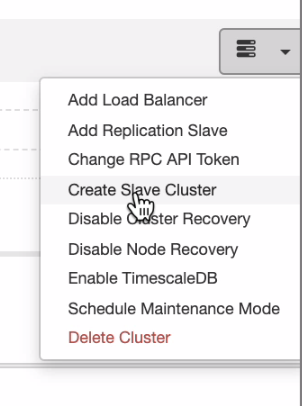
and you can arrive with the end result as shown below,

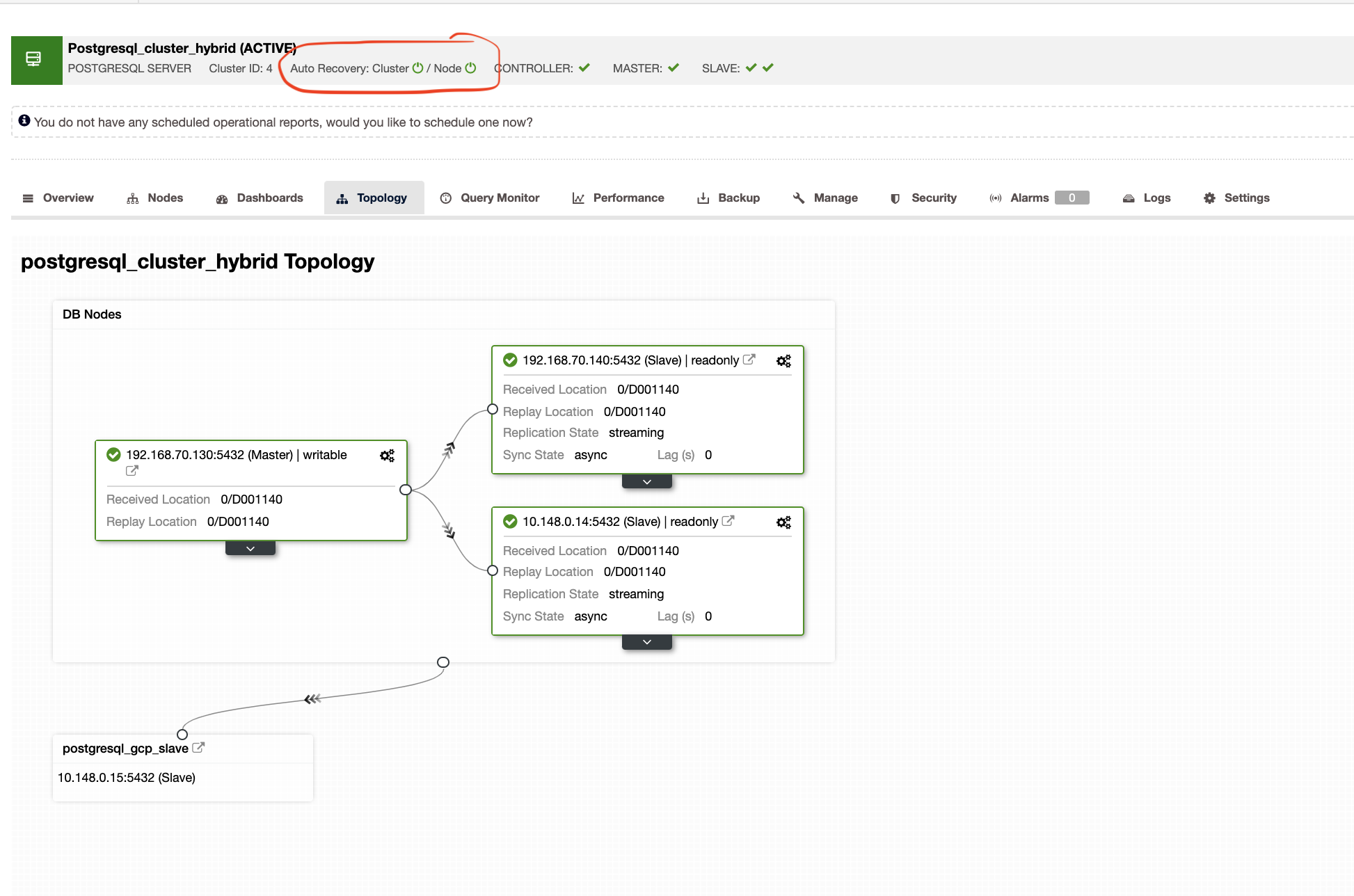
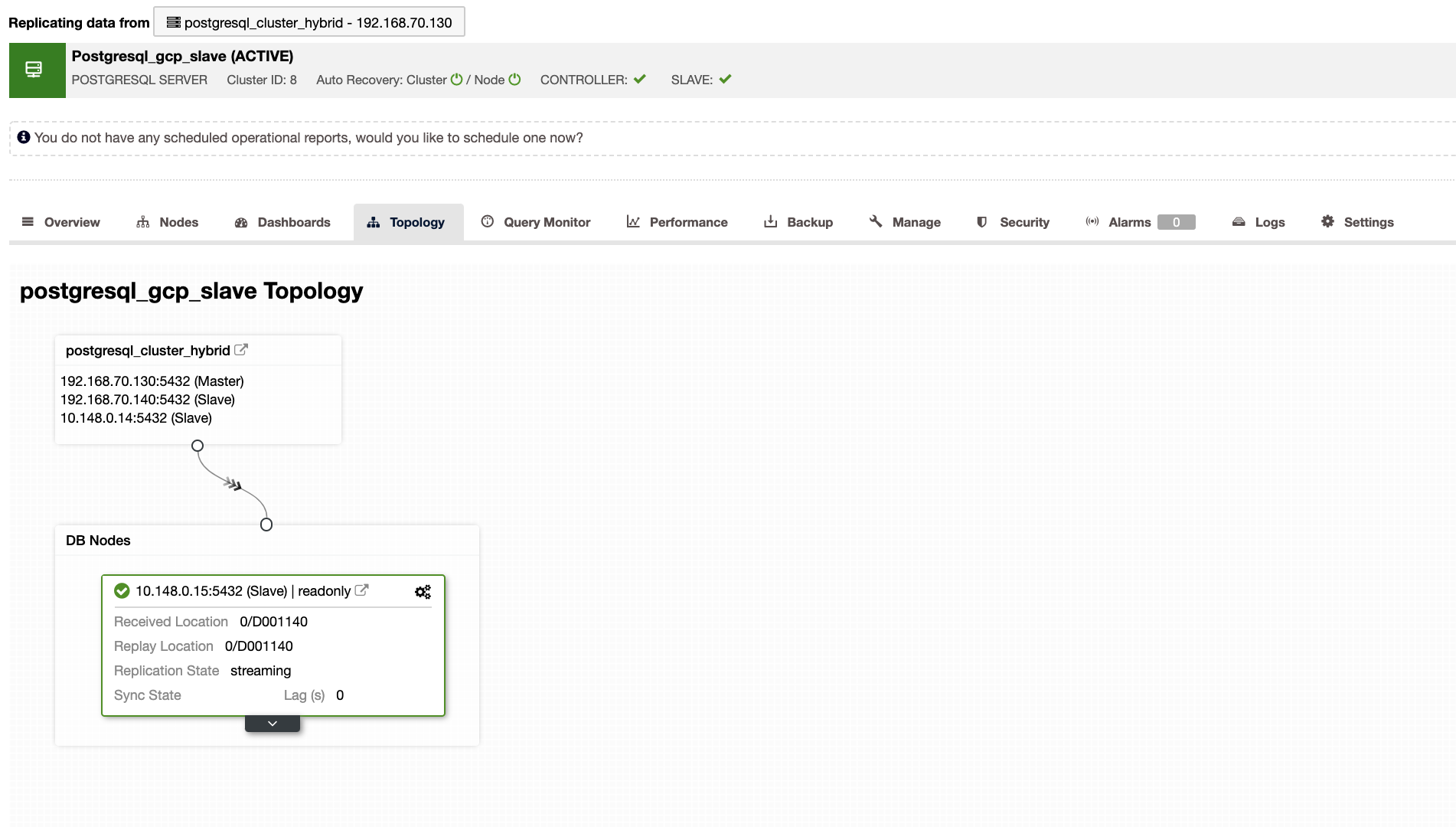
ClusterControl will also show you the right topology of your cluster whenever you have a hybrid cloud environment setup. See the following below,
Whereas in the slave cluster, the topology will show its tree of origin revealing its master. The slave here shows as it’s located in a separate network primarily located in Google Cloud, whereas the master is on-prem.
Conclusion
It is acceptable to admit that a hybrid cloud setup, especially with PostgreSQL cluster adds complexity. You must have the right tool with options present to support your disaster recovery planning. These are very important to save and avoid your business from the potential catastrophe of financial damage and losing customer’s trust. Invest in your technology’s right tools and skills, and you will save your business from negative impact.



