blog
Automated Testing of the Upgrade Process for MySQL/MariaDB/Percona Server

Upgrades are always a hard and time-consuming task. First, you should test your application in a test environment, so, ideally, you will need to clone your current production environment for this. Then, you need to make a plan to perform the upgrade that, depending on the business, could be with zero downtime (or almost zero), or even schedule a maintenance window to make sure that if something goes wrong, it will affect as little as possible.
If you want to do all these things manually, there is a big chance of human error and the process will be slow. In this blog, we will see how to automate testing for upgrading your MySQL, MariaDB, or Percona Server databases using ClusterControl.
Type of Upgrades
There are two types of upgrades: Minor Upgrades and Major Upgrades.
Minor Upgrades
The first one, Minor Upgrade, is the most common and safe upgrade, and in most cases, this is performed in place. As nothing is 100% secure, you must always have backups and replication slaves nodes, so in case something goes wrong with the upgrade and for some reason you can’t rollback/downgrade, you can promote a slave node, and your systems can still work without interruption.
You can perform this kind of upgrade using ClusterControl. For this, go to ClusterControl -> Select the Cluster -> Manage -> Upgrades.
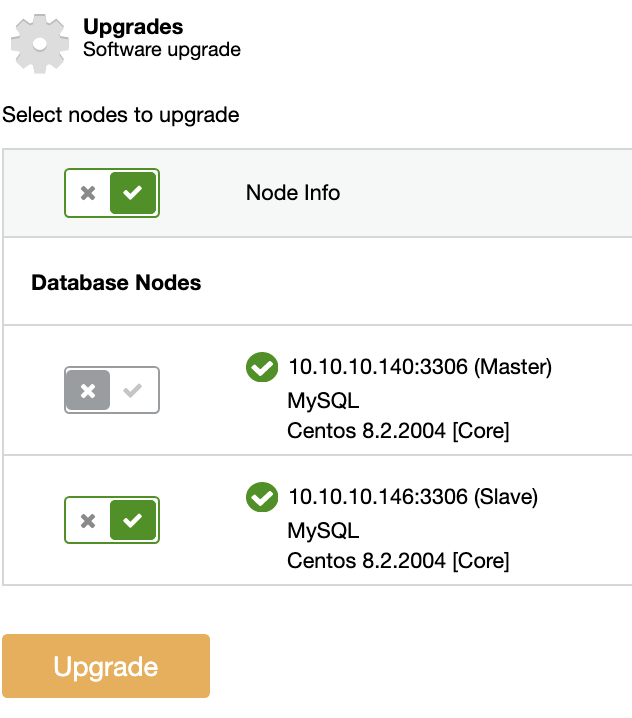
On each selected node, the upgrade procedure will:
-
Stop Node
-
Upgrade Node
-
Start Node
The Master node in a Replication Topology won’t be upgraded. To upgrade the Master, another node must be promoted to become the new Master first.
Major Upgrades
For Major Upgrades, it is not recommended the in-place upgrade, as the risk of something going wrong is too high for a production environment. Instead of this, you can clone your current database cluster and test your application there, and when you finish, you can re-create it or even create a new cluster in the new version and switch the traffic when it is ready. There are different approaches for these upgrades. You can upgrade the nodes one by one, or create a different cluster replicating the traffic from the current one, you can also use load balancers to improve High Availability, and more options. The best approach depends on the downtime tolerance and the Recovery Time Objective (RTO).
You can’t perform Major Upgrades with ClusterControl directly, because, as we mentioned, you need to test everything first, to make sure that the upgrade is safe, but you can use different ClusterControl features to make this task easier. So let’s see some of these features.
Backups
Backups are a must before any upgrade. A good backup policy can avoid big issues for the business. So, let’s see how ClusterControl can automate this.
Creating a Backup
Go to ClusterControl -> Select the Cluster -> Backup -> Create Backup.
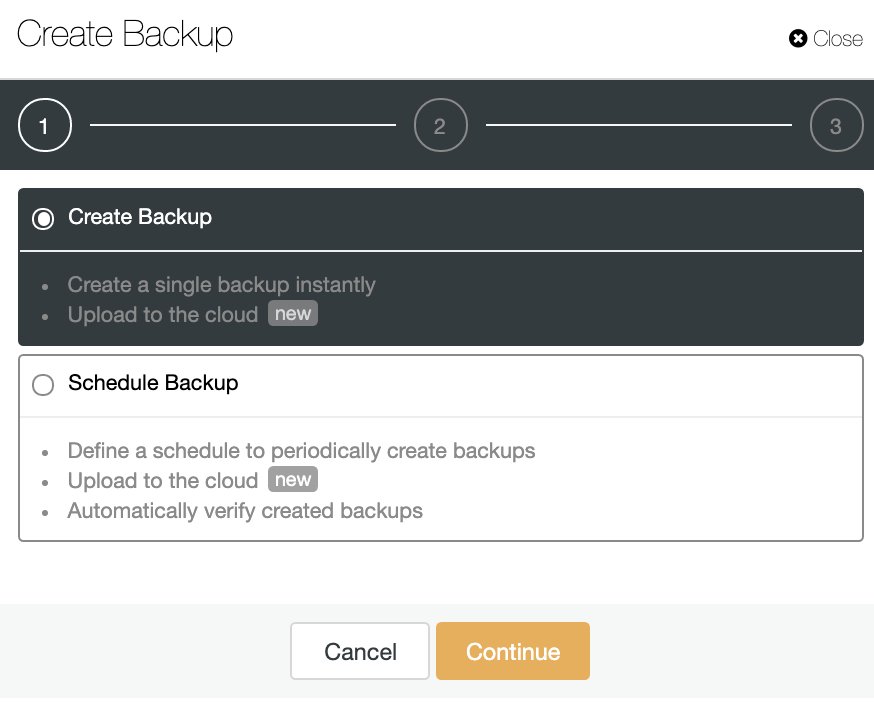
You can create a new backup or configure a scheduled one.
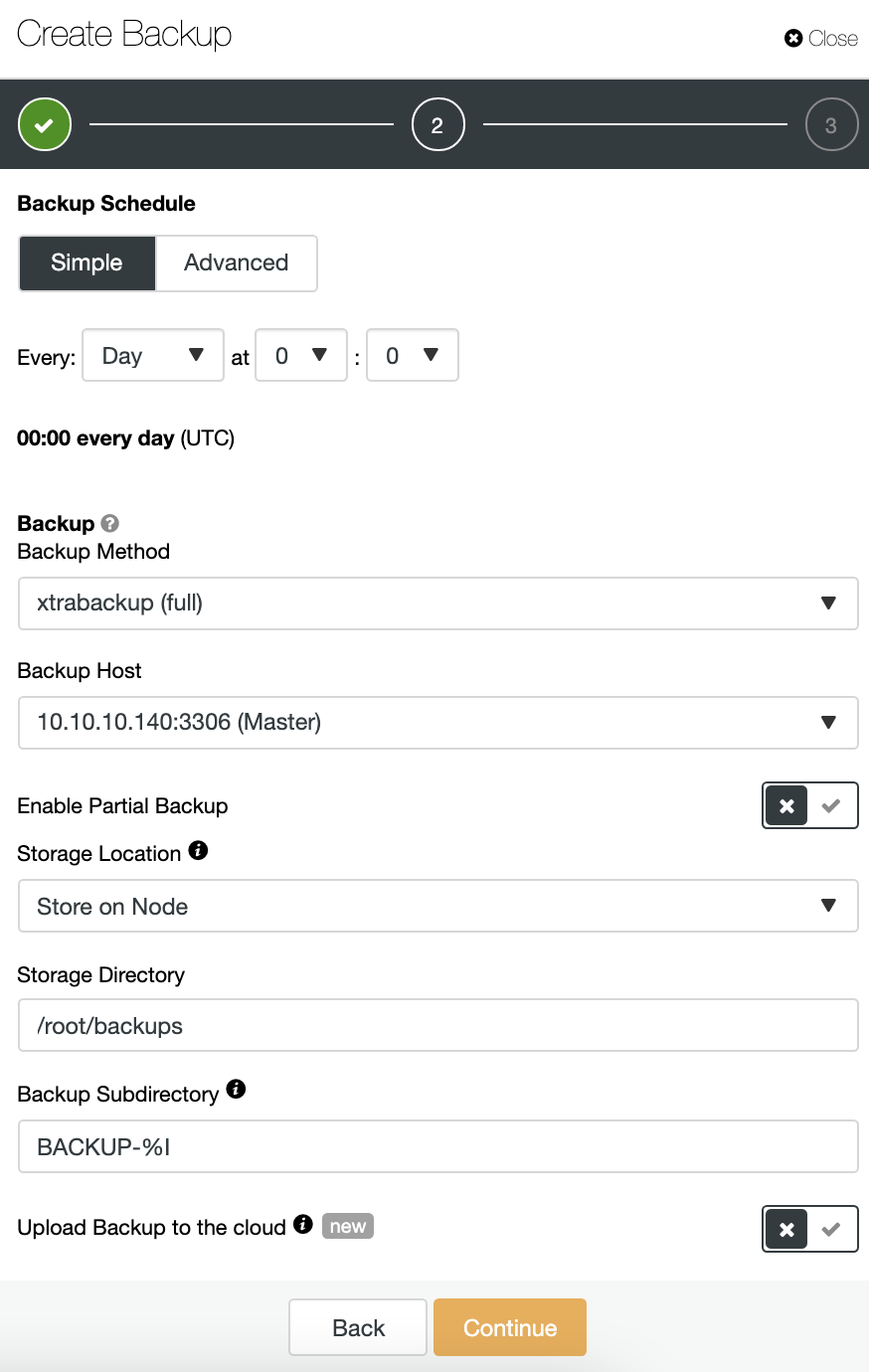
You can choose different backup methods, depending on the database technology, and, in the same section, you can choose the server from which to take the backup, where you want to store the backup, and if you want to upload the backup to the cloud (AWS, Azure, or Google Cloud) in the same job.
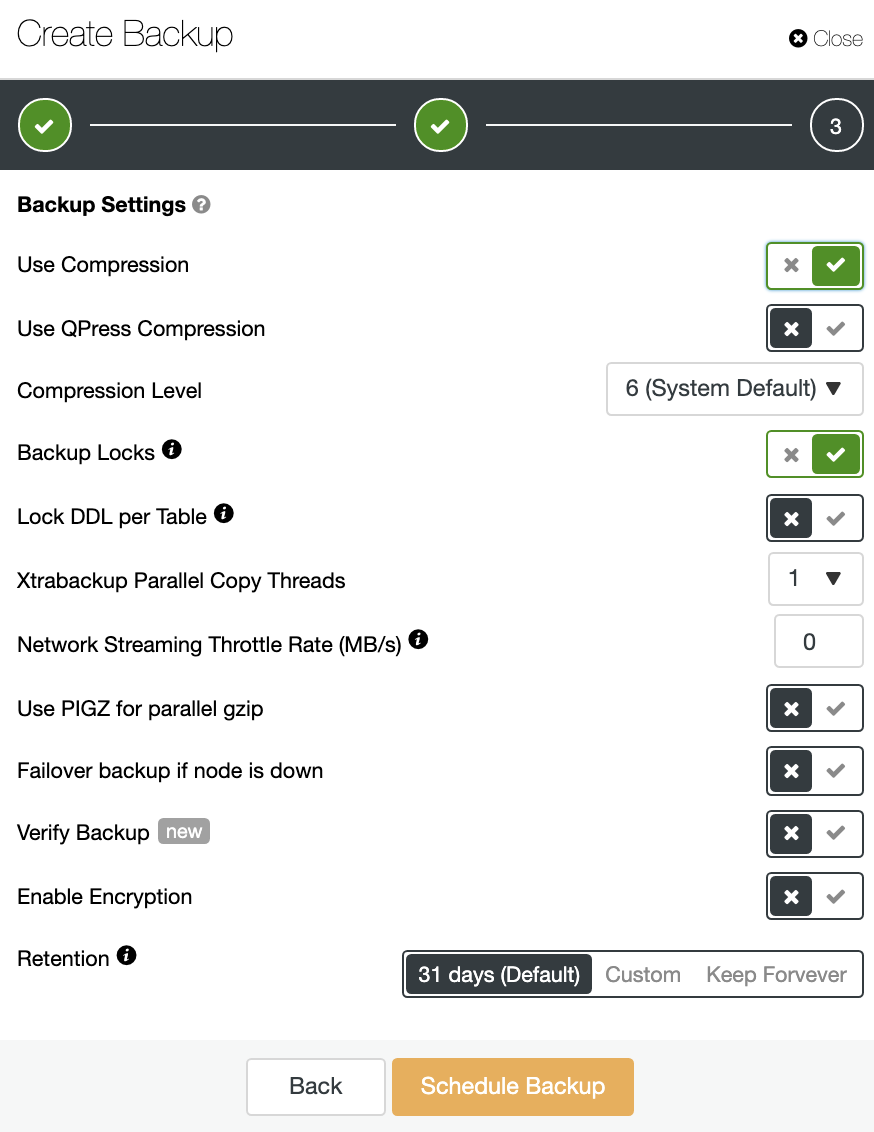
You can also compress and encrypt your backup, and specify the retention period, among other options.
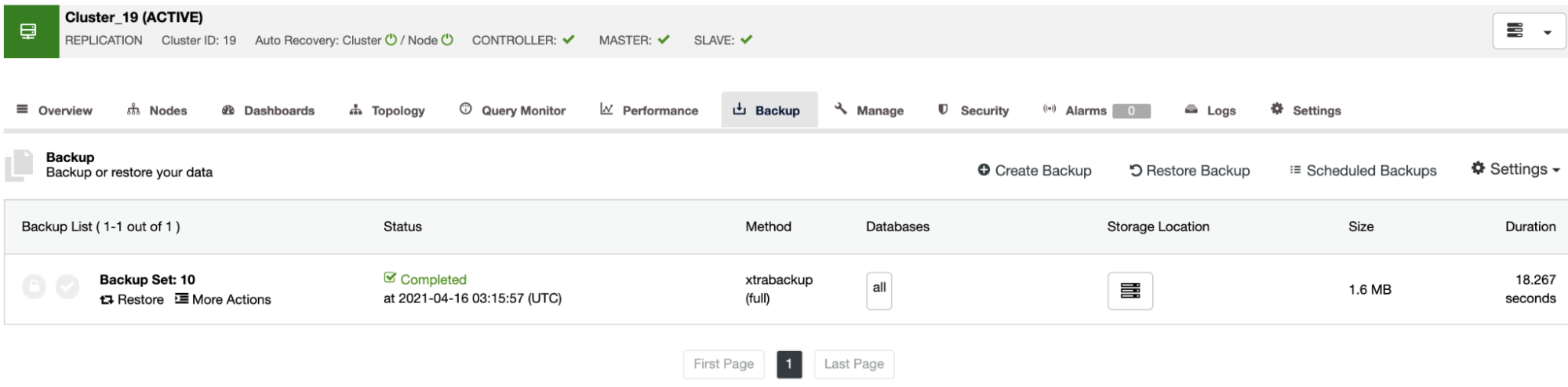
On the backup section, you can see the progress of the backup, and information like the method, size, location, and more.
Deploying a Test Environment
For this, you don’t need to create everything from scratch. Instead of this, you can use ClusterControl for doing this in a manual or automated way.
Restore Backup on Standalone Host
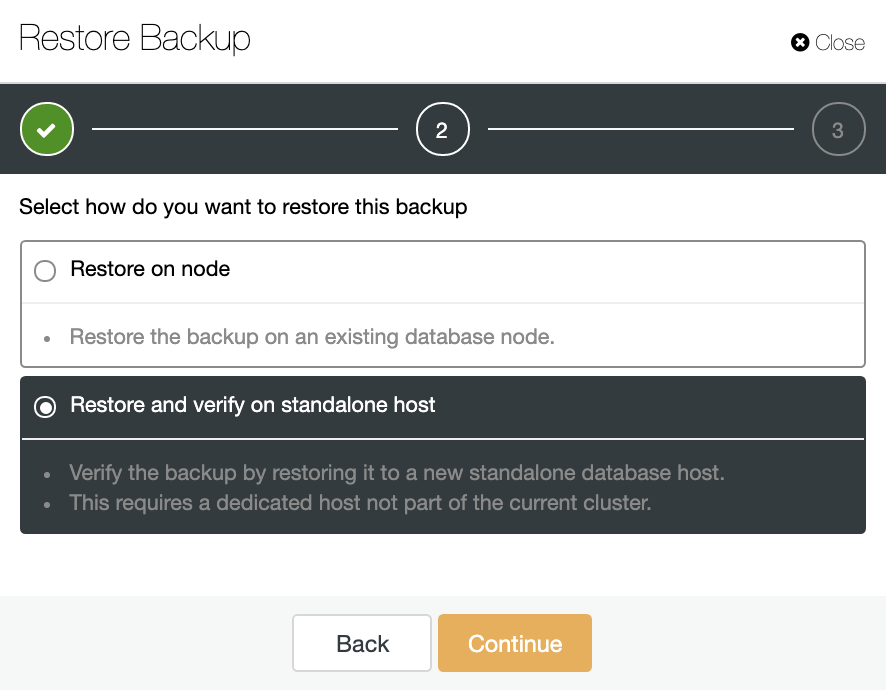
In the Backup section, you can choose the option “Restore and verify on standalone host” to restore a backup in a separate node.
Here you can specify if you want ClusterControl to install the software in the new node, and disable the firewall or AppArmor/SELinux (depending on the OS). For this, you need a dedicated host (or VM) that is not part of the cluster.
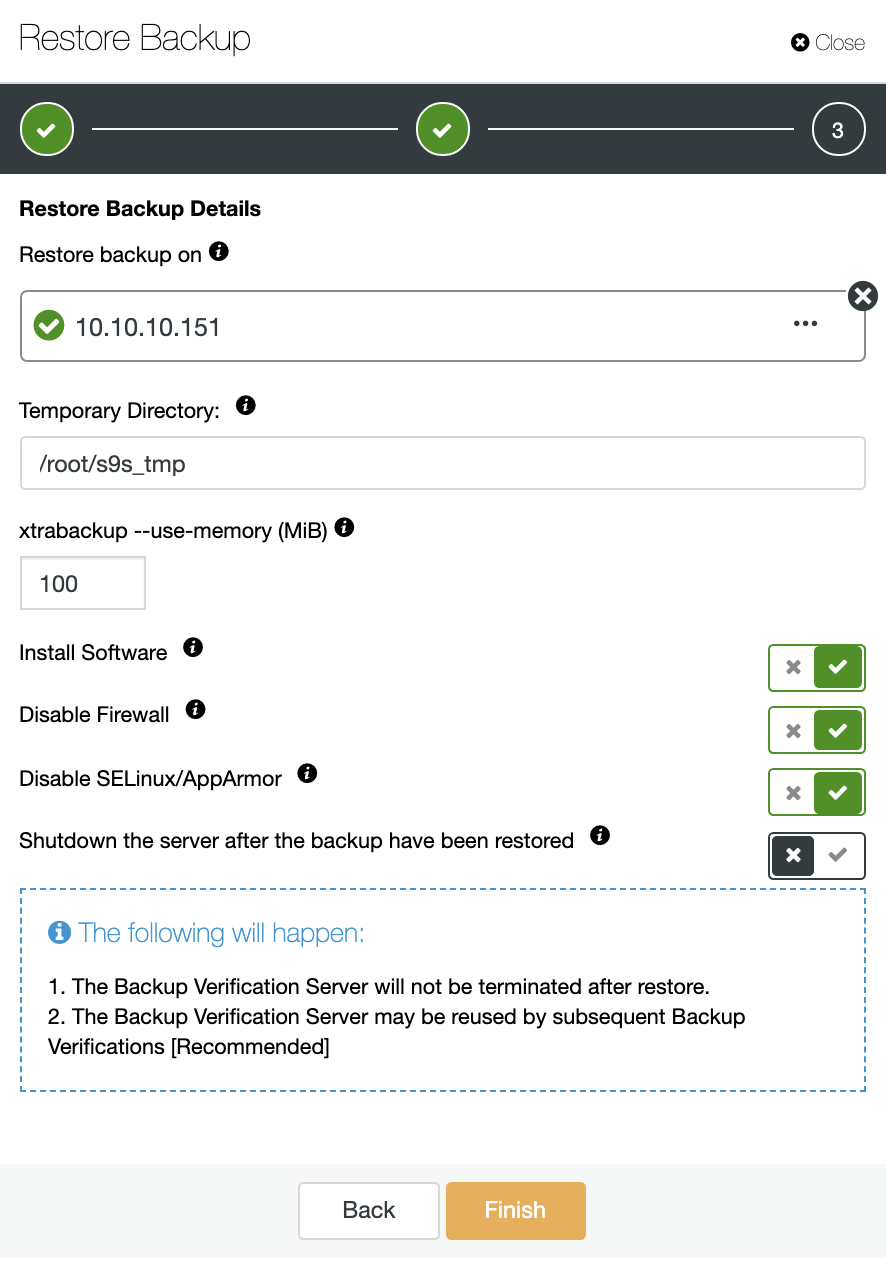
You can keep the node up and running, or ClusterControl can shutdown the database service until the next restore job. When it finishes, you will see the restored/verified backup in the backup list marked with a tick.
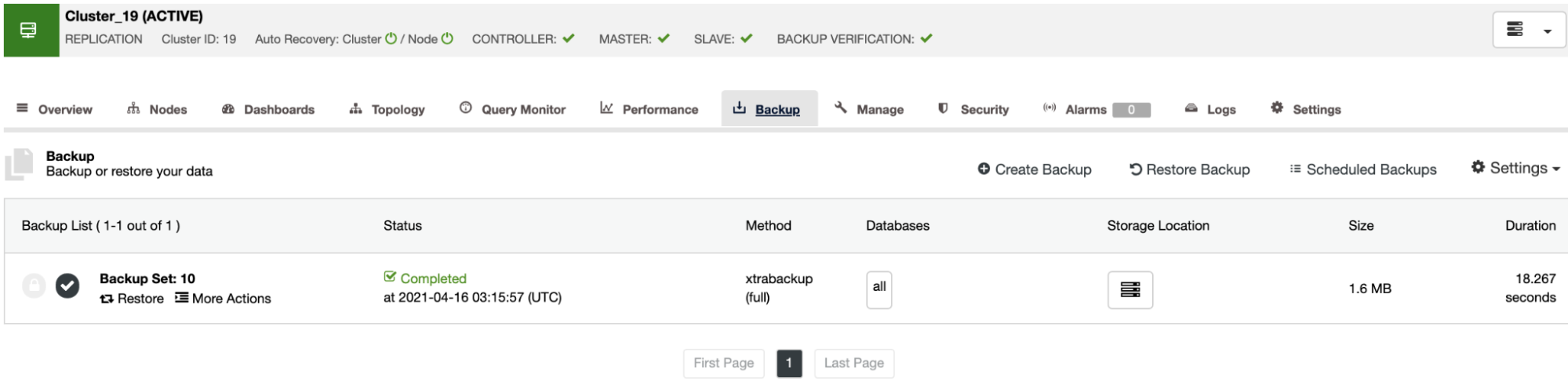
If you don’t want to do this task manually, you can schedule this process using the Verify Backup Feature, to repeat this job periodically in a Backup Job. We are going to see how to do this in the next section.
Automatic ClusterControl Backup Verification
To automate this task, go to ClusterControl -> Select your Cluster -> Backup -> Create Backup, and choose the Scheduled Backup option.
The automatic Verify Backup feature is only available for scheduled backups, and the process is the same that we described in a previous section. In the second step, make sure you have enabled the Verify Backup option, and complete the required information.
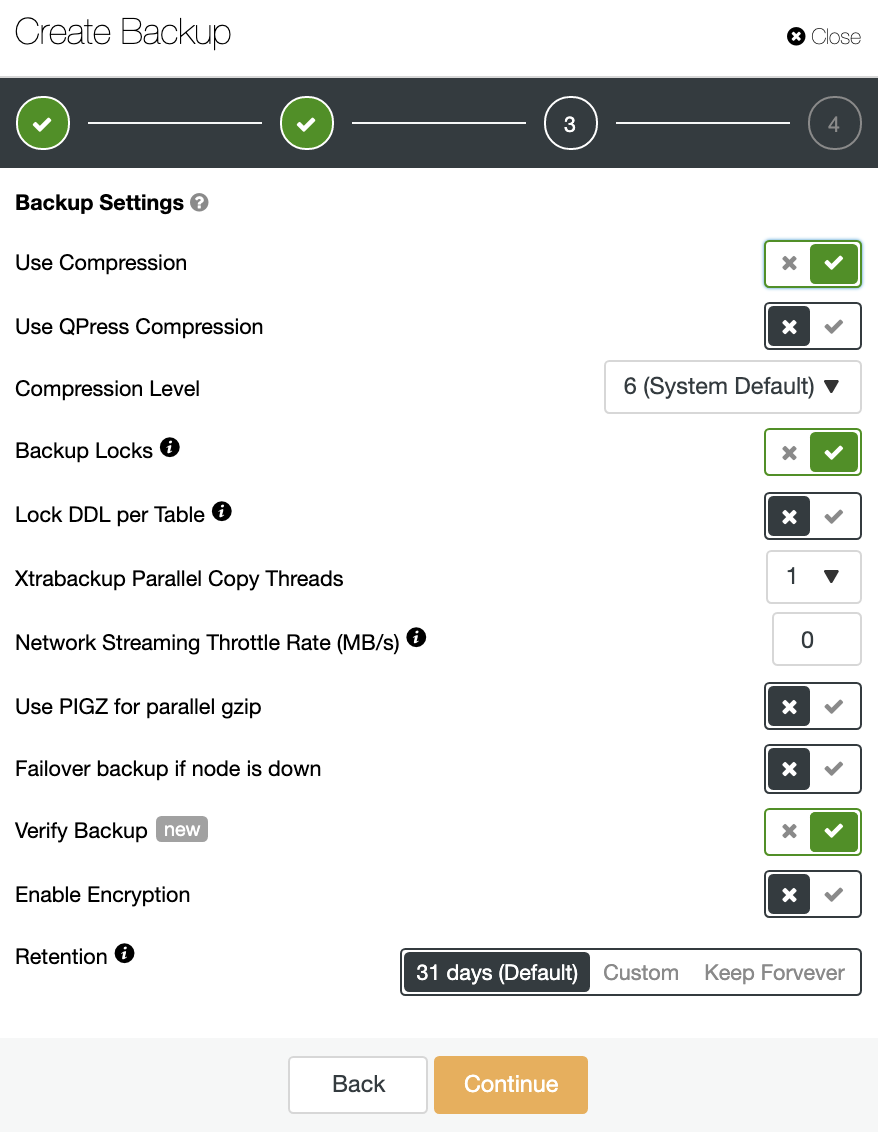
When the job is finished, you can see the verification icon in the ClusterControl Backup section, the same that you will have by doing the verification in the manual way, with the difference that you don’t need to worry about the restoration task. ClusterControl will restore the backup every time automatically, and you can test your application with the most recent data.
Autorecovery and Failover
Having the Autorecovery feature enabled, in case of failure, ClusterControl will promote the most advanced slave node to master as well as notify you of the problem. It also fails over the rest of the slave nodes to replicate from the new master server.
If there are Load Balancers in the topology, ClusterControl will reconfigure them to apply the topology changes.
You can also run a Failover manually if needed. Go to ClusterControl -> Select the Cluster -> Nodes -> Select the Node to be promoted -> Node Actions -> Promote Slave.
In this way, if something goes wrong during the upgrade, you can use ClusterControl to fix it ASAP.
Automating Things with ClusterControl CLI
ClusterControl CLI, also known as s9s, is a command-line tool introduced in ClusterControl version 1.4.1 to interact, control, and manage database clusters using the ClusterControl system. ClusterControl CLI opens a door for cluster automation where you can easily integrate it with existing deployment automation tools like Ansible, Puppet, Chef, etc. Let’s see now some examples of this tool.
Upgrade
$ s9s cluster --cluster-id=19
--check-pkg-upgrades
--log
$ s9s cluster --cluster-id=19
--available-upgrades
--nodes='10.10.10.146'
--log
--print-json
$ s9s cluster --cluster-id=19
--upgrade-cluster
--nodes='10.10.10.146'
--logCreate Backup
$ s9s backup --create
--backup-method=mysqldump
--cluster-id=2
--nodes=10.10.10.146:3306
--on-controller
--backup-directory=/storage/backups
--logRestore Backup
$ s9s backup --restore
--cluster-id=19
--backup-id=3
--waitVerify Backups
$ s9s backup --verify
--backup-id=3
--test-server=10.10.10.151
--cluster-id=19
--logPromote Slave Node
$ s9s cluster --promote-slave
--cluster-id=19
--nodes='10.10.10.146'
--logConclusion
Upgrades are necessary but time-consuming tasks. Deploying a test environment every time you need to upgrade could be a nightmare, and it is hard to maintain this up-to-date without any automatization tool.
ClusterControl allows you to perform minor upgrades or even deploy the test environment to make the upgrade task easier and safer. You can also integrate it with different automation tools like Ansible, Puppet, and more.


