blog
What is new in PostgreSQL 13?

PostgreSQL, also known as the world’s most advanced open source database, has a new release version since last September 24 2020, and now it is mature, we can check what is new there to start thinking about a migration plan. PostgreSQL 13 is available with many new features and enhancements. In this blog, we will mention some of these new features and see how to deploy or upgrade your current PostgreSQL version.
PostgreSQL 13 New Features and Improvements
Let’s start mentioning some of the new features and improvements of this PostgreSQL 13 version that you can see in the Official Documentation.
Partitioning
-
Allow pruning of partitions and partitionwise joins to happen in more cases
-
Support row-level BEFORE triggers on partitioned tables
-
Allow partitioned tables to be logically replicated via publication
-
Allow logical replication into partitioned tables on subscribers
-
Allow whole-row variables to be used in partitioning expressions
Indexes
-
More efficiently store duplicates in B-tree indexes
-
Allow GiST and SP-GiST indexes on box columns to support ORDER BY box <-> point queries
-
Allow GIN indexes to more efficiently handle ! (NOT) clauses in tsquery searches
-
Allow index operator classes to take parameters
Optimizer
-
Improve the optimizer’s selectivity estimation for containment/match operators
-
Allow setting the statistics target for extended statistics
-
Allow use of multiple extended statistics objects in a single query
-
Allow use of extended statistics objects for OR clauses and IN/ANY constant lists
-
Allow functions in FROM clauses to be pulled up (inlined) if they evaluate to constants
Performance
-
Implement incremental sorting and improve the performance of sorting inet values
-
Allow hash aggregation to use disk storage for large aggregation result sets
-
Allow inserts, not only updates and deletes, to trigger vacuuming activity in autovacuum
-
Add maintenance_io_concurrency parameter to control I/O concurrency for maintenance operations
-
Allow WAL writes to be skipped during a transaction that creates or rewrites a relation, if wal_level is minimal
-
Improve performance when replaying DROP DATABASE commands when many tablespaces are in use
-
Speed up conversions of integers to text
-
Reduce memory usage for query strings and extension scripts that contain many SQL statements
Monitoring
-
Allow EXPLAIN, auto_explain, autovacuum, and pg_stat_statements to track WAL usage statistics
-
Allow a sample of SQL statements, rather than all statements, to be logged
-
Add the backend type to csvlog and optionally log_line_prefix log output
-
Improve control of prepared statement parameter logging
-
Add leader_pid to pg_stat_activity to report a parallel worker’s leader process
-
Add system view pg_stat_progress_basebackup to report the progress of streaming base backups
-
Add system view pg_stat_progress_analyze to report ANALYZE progress
-
Add system view pg_shmem_allocations to display shared memory usage
Replication And Recovery
-
Allow streaming replication configuration settings to be changed by reloading
-
Allow WAL receivers to use a temporary replication slot when a permanent one is not specified
-
Allow WAL storage for replication slots to be limited by max_slot_wal_keep_size
-
Allow standby promotion to cancel any requested pause
-
Generate an error if recovery does not reach the specified recovery target
-
Allow control over how much memory is used by logical decoding before it is spilled to disk
-
Allow recovery to continue even if invalid pages are referenced by WAL
Utility Commands
-
Allow VACUUM to process a table’s indexes in parallel
-
Report planning-time buffer usage in EXPLAIN’s BUFFER output
-
Make CREATE TABLE LIKE propagate a CHECK constraint’s NO INHERIT property to the created table
-
Add ALTER TABLE … DROP EXPRESSION to allow removing the GENERATED property from a column
-
Add ALTER VIEW syntax to rename view columns
-
Add ALTER TYPE options to modify a base type’s TOAST properties and support functions
-
Add CREATE DATABASE LOCALE option
-
Allow DROP DATABASE to disconnect sessions using the target database, allowing the drop to succeed
And many more changes. We just mentioned some of them to avoid a larger blog post. Now, let’s see how to deploy this new version.
How to Deploy PostgreSQL 13
For this, we will assume that you have ClusterControl installed, otherwise, you can follow the corresponding documentation to install it.
To perform a deployment from ClusterControl, simply select the option Deploy and follow the instructions that appear.
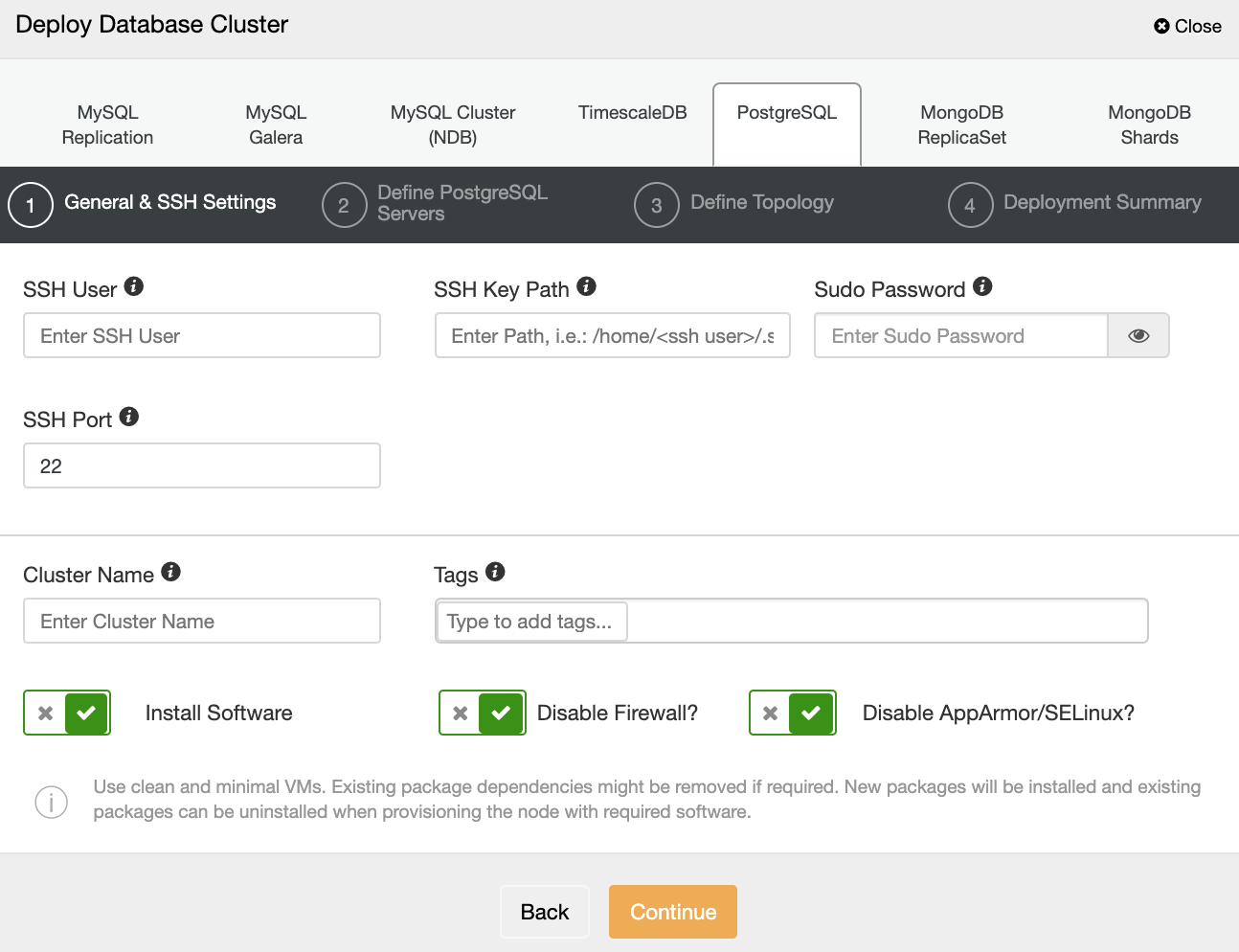
When selecting PostgreSQL, you must specify User, Key or Password, and Port to connect by SSH to your servers. You can also add a name for your new cluster and if you want ClusterControl to install the corresponding software and configurations for you.
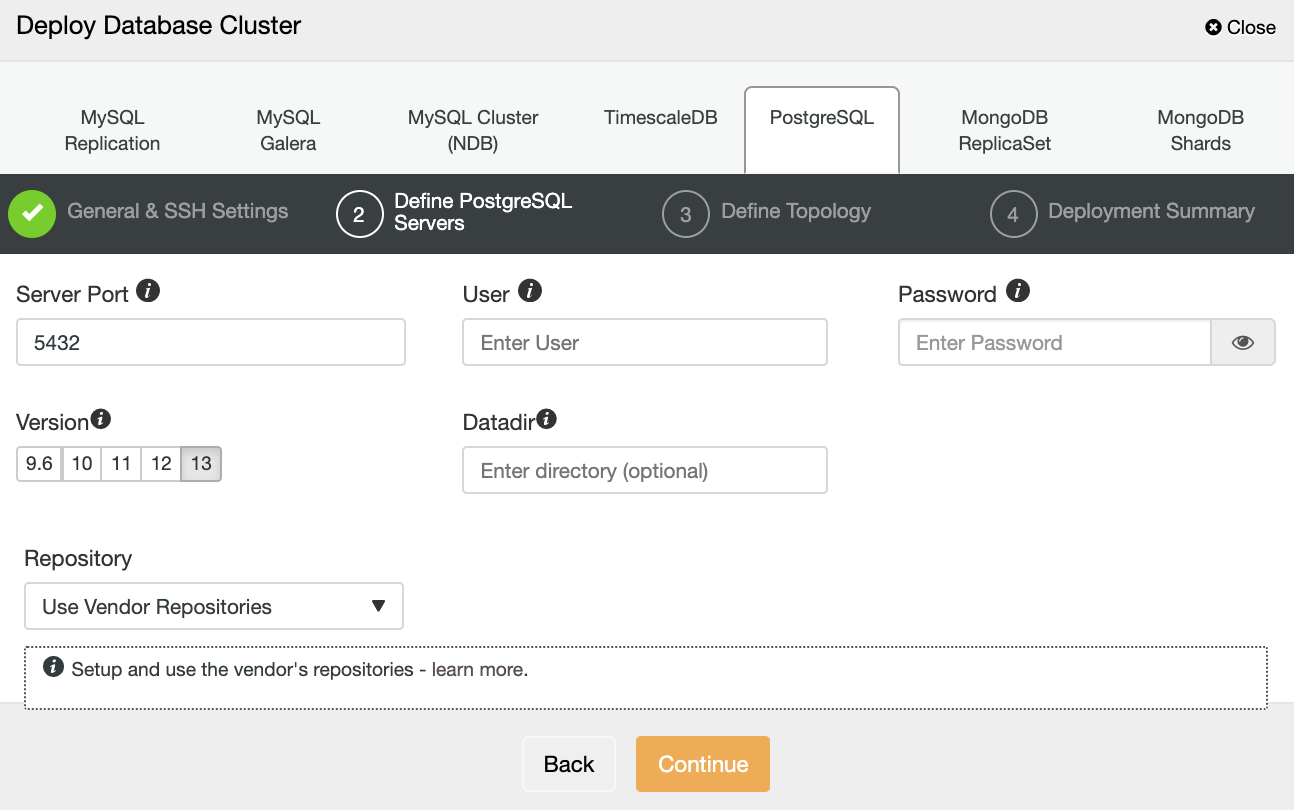
After setting up the SSH access information, you need to define the database credentials, version, and datadir (optional). You can also specify which repository to use.
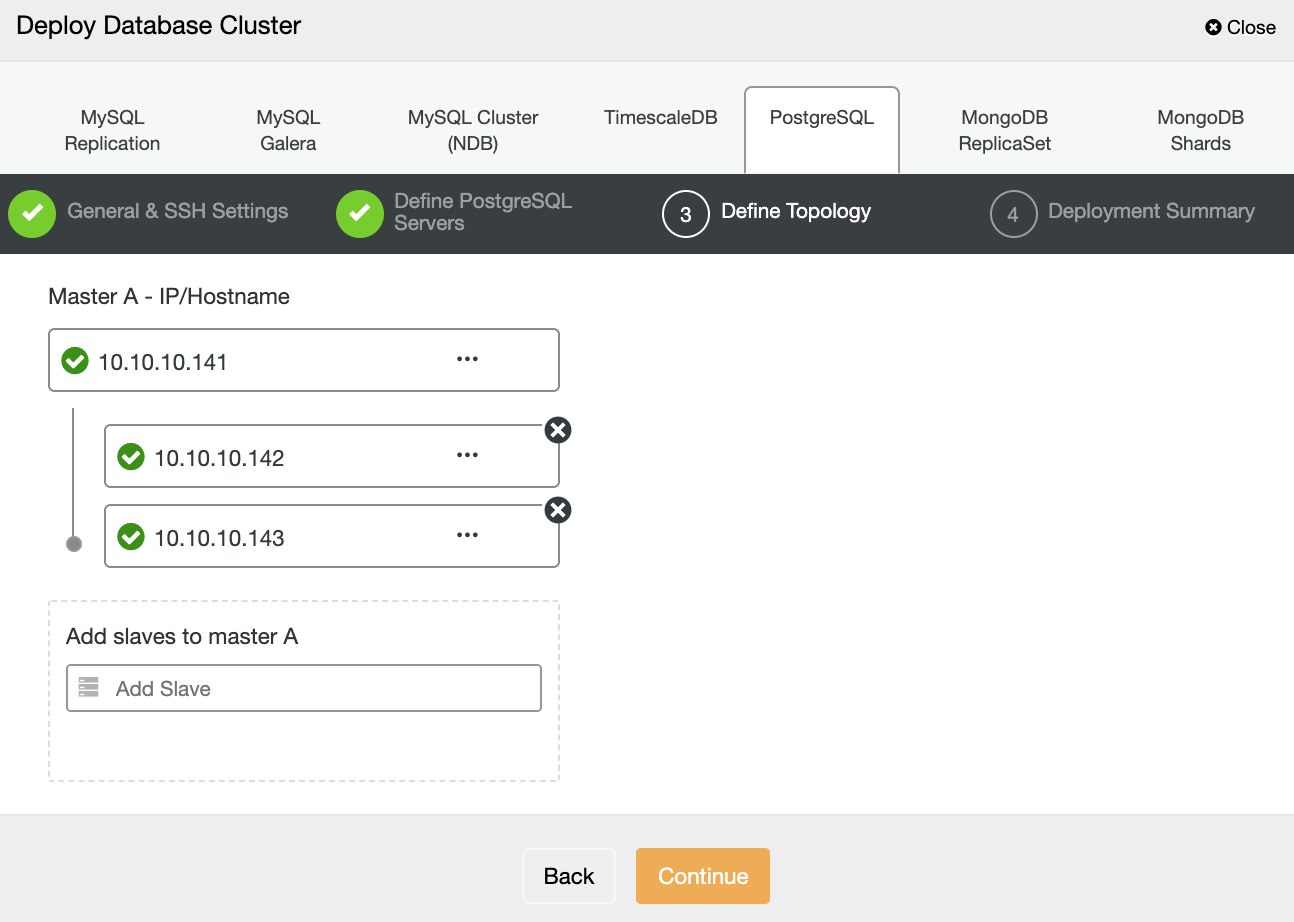
In the next step, you need to add your servers to the cluster that you are going to create using the IP Address or Hostname.
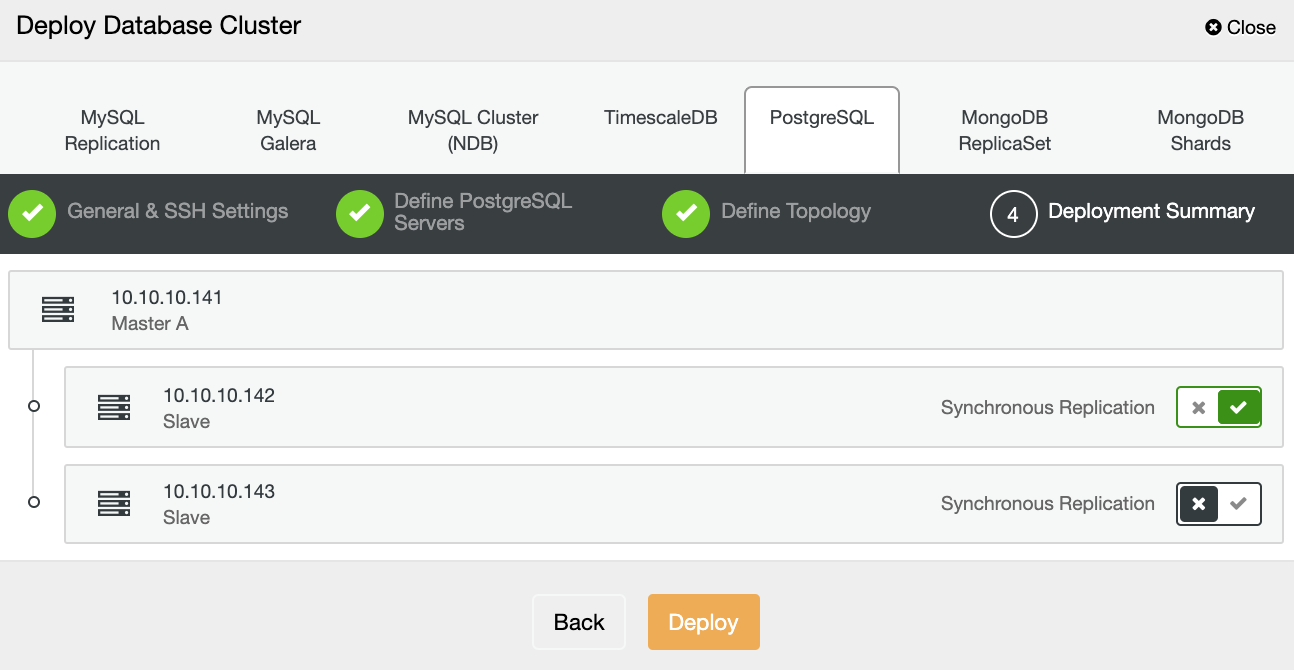
In the last step, you can choose if your replication will be Synchronous or Asynchronous, and then just press on Deploy.
Once the task is finished, you can see your new PostgreSQL cluster in the main ClusterControl screen.

Now you have your cluster created, you can perform several tasks on it, like adding load balancers (HAProxy), connection poolers (PgBouncer), or new replication slaves from the same ClusterControl UI.
Upgrading to PostgreSQL 13
If you want to upgrade your current PostgreSQL version to this new one, you have three main options which will perform this task.
-
Pg_dump: It is a logical backup tool that allows you to dump your data and restore it in the new PostgreSQL version. Here you will have a downtime period that will vary according to your data size. You need to stop the system or avoid new data in the primary node, run the pg_dump, move the generated dump to the new database node, and restore it. During this time, you can’t write into your primary PostgreSQL database to avoid data inconsistency.
-
Pg_upgrade: It is a PostgreSQL tool to upgrade your PostgreSQL version in-place. It could be dangerous in a production environment and we don’t recommend this method in that case. Using this method you will have downtime too, but probably it will be considerably less than using the previous pg_dump method.
-
Logical Replication: Since PostgreSQL 10, you can use this replication method which allows you to perform major version upgrades with zero (or almost zero) downtime. In this way, you can add a standby node in the last PostgreSQL version, and when the replication is up-to-date, you can perform a failover process to promote the new PostgreSQL node.
For more detailed information about the new PostgreSQL 13 features, you can refer to the Official Documentation.



