blog
An Overview of Logical Replication in PostgreSQL

PostgreSQL is one of the most advanced open source databases in the world with a lot of great features. One of them is Streaming Replication (Physical Replication) which was introduced in PostgreSQL 9.0. It is based on XLOG records which get transferred to the destination server and get applied there. However, it is cluster based and we cannot do a single database or single object (selective replication) replication. Over the years, we have been dependent on external tools like Slony, Bucardo, BDR, etc for selective or partial replication as there was no feature at the core level until PostgreSQL 9.6. However, PostgreSQL 10 came up with a feature called Logical Replication, through which we can perform database/object level replication.
Logical Replication replicates changes of objects based on their replication identity, which is usually a primary key. It is different to physical replication, in which replication is based on blocks and byte-by-byte replication. Logical Replication does not need an exact binary copy at the destination server side, and we have the ability to write on destination server unlike Physical Replication. This feature originates from the pglogical module.
In this blog post, we are going to discuss:
- How it works – Architecture
- Features
- Use cases – when it is useful
- Limitations
- How to achieve it
How it Works – Logical Replication Architecture
Logical Replication implements a publish and subscribe concept (Publication & Subscription). Below is a higher level architectural diagram on how it works.
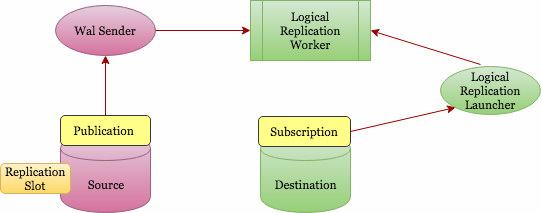
Basic Logical Replication Architecture
Publication can be defined on the master server and the node on which it is defined is referred to as the “publisher”. Publication is a set of changes from a single table or group of tables. It is at database level and each publication exists in one database. Multiple tables can be added to a single publication and a table can be in multiple publications. You should add objects explicitly to a publication except if you choose the “ALL TABLES” option which needs a superuser privilege.
You can limit the changes of objects (INSERT, UPDATE, and DELETE) to be replicated. By default, all operation types are replicated. You must have a replication identity configured for the object that you want to add to a publication. This is in order to replicate UPDATE and DELETE operations. The replication identity can be a primary key or unique index. If the table does not have a primary key or unique index, then it can be set to replica identity “full” in which it takes all columns as key (entire row becomes key).
You can create a publication using CREATE PUBLICATION. Some practical commands are covered in the “How to achieve it” section.
Subscription can be defined on the destination server and the node on which it is defined is referred to as the “subscriber”. The connection to the source database is defined in subscription. The subscriber node is the same as any other stand alone postgres database, and you can also use it as a publication to further subscriptions.
The subscription is added using CREATE SUBSCRIPTION and can be stopped/resumed at any time using the ALTER SUBSCRIPTION command and removed using DROP SUBSCRIPTION.
Once a subscription is created, Logical replication copies a snapshot of the data on the publisher database. Once that is done, it waits for delta changes and sends them to the subscription node as soon as they occur.
However, how are the changes collected? Who sends them to the target? And who applies them at the target? Logical replication is also based on the same architecture as physical replication. It is implemented by “walsender” and “apply” processes. As it is based on WAL decoding, who starts the decoding? The walsender process is responsible to start logical decoding of the WAL, and loads the standard logical decoding plugin (pgoutput). The plugin transforms the changes read from WAL to the logical replication protocol, and filters the data according to the publication specification. The data is then continuously transferred using the streaming replication protocol to the apply worker, which maps the data to local tables and applies the individual changes as they are received, in correct transactional order.
It logs all these steps in log files while setting it up. We can see the messages in “How to achieve it” section later in the post.
Features Of Logical Replication
- Logical Replication replicates data objects based upon their replication identity (generally a
- primary key or unique index).
- Destination server can be used for writes. You can have different indexes and security definition.
- Logical Replication has cross-version support. Unlike Streaming Replication, Logical Replication can be set between different versions of PostgreSQL (> 9.4, though)
- Logical Replication does Event-based filtering
- When compared, Logical Replication has less write amplification than Streaming Replication
- Publications can have several subscriptions
- Logical Replication provides storage flexibility through replicating smaller sets (even partitioned tables)
- Minimum server load compared with trigger based solutions
- Allows parallel streaming across publishers
- Logical Replication can be used for migrations and upgrades
- Data transformation can be done while setting up.
Use Cases – When is Logical Replication Useful?
It is very important to know when to use Logical Replication. Otherwise, you will not get much benefit if your use case does not match. So, here are some use cases on when to use Logical Replication:
- If you want to consolidate multiple databases into a single database for analytical purposes.
- If your requirement is to replicate data between different major versions of PostgreSQL.
- If you want to send incremental changes in a single database or a subset of a database to other databases.
- If giving access to replicated data to different groups of users.
- If sharing a subset of the database between multiple databases.
Limitations Of Logical Replication
Logical Replication has some limitations on which the community is continuously working on to overcome:
- Tables must have the same full qualified name between publication and subscription.
- Tables must have primary key or unique key
- Mutual (bi-directional) Replication is not supported
- Does not replicate schema/DDL
- Does not replicate sequences
- Does not replicate TRUNCATE
- Does not replicate Large Objects
- Subscriptions can have more columns or different order of columns, but the types and column names must match between Publication and Subscription.
- Superuser privileges to add all tables
- You cannot stream over to the same host (subscription will get locked).
How to Achieve Logical Replication
Here are the steps to achieve basic Logical Replication. We can discuss about more complex scenarios later.
-
Initialize two different instances for publication and subscription and start.
C1MQV0FZDTY3:bin bajishaik$ export PATH=$PWD:$PATH C1MQV0FZDTY3:bin bajishaik$ which psql /Users/bajishaik/pg_software/10.2/bin/psql C1MQV0FZDTY3:bin bajishaik$ ./initdb -D /tmp/publication_db C1MQV0FZDTY3:bin bajishaik$ ./initdb -D /tmp/subscription_db -
Parameters to be changed before you start the instances (for both publication and subscription instances).
C1MQV0FZDTY3:bin bajishaik$ tail -3 /tmp/publication_db/postgresql.conf listen_addresses='*' port = 5555 wal_level= logical C1MQV0FZDTY3:bin bajishaik$ pg_ctl -D /tmp/publication_db/ start waiting for server to start....2018-03-21 16:03:30.394 IST [24344] LOG: listening on IPv4 address "0.0.0.0", port 5555 2018-03-21 16:03:30.395 IST [24344] LOG: listening on IPv6 address "::", port 5555 2018-03-21 16:03:30.544 IST [24344] LOG: listening on Unix socket "/tmp/.s.PGSQL.5555" 2018-03-21 16:03:30.662 IST [24345] LOG: database system was shut down at 2018-03-21 16:03:27 IST 2018-03-21 16:03:30.677 IST [24344] LOG: database system is ready to accept connections done server started C1MQV0FZDTY3:bin bajishaik$ tail -3 /tmp/subscription_db/postgresql.conf listen_addresses='*' port=5556 wal_level=logical C1MQV0FZDTY3:bin bajishaik$ pg_ctl -D /tmp/subscription_db/ start waiting for server to start....2018-03-21 16:05:28.408 IST [24387] LOG: listening on IPv4 address "0.0.0.0", port 5556 2018-03-21 16:05:28.408 IST [24387] LOG: listening on IPv6 address "::", port 5556 2018-03-21 16:05:28.410 IST [24387] LOG: listening on Unix socket "/tmp/.s.PGSQL.5556" 2018-03-21 16:05:28.460 IST [24388] LOG: database system was shut down at 2018-03-21 15:59:32 IST 2018-03-21 16:05:28.512 IST [24387] LOG: database system is ready to accept connections done server startedOther parameters can be at default for basic setup.
-
Change pg_hba.conf file to allow replication. Note that these values are dependent on your environment, however, this is just a basic example (for both publication and subscription instances).
C1MQV0FZDTY3:bin bajishaik$ tail -1 /tmp/publication_db/pg_hba.conf host all repuser 0.0.0.0/0 md5 C1MQV0FZDTY3:bin bajishaik$ tail -1 /tmp/subscription_db/pg_hba.conf host all repuser 0.0.0.0/0 md5 C1MQV0FZDTY3:bin bajishaik$ psql -p 5555 -U bajishaik -c "select pg_reload_conf()" Timing is on. Pager usage is off. 2018-03-21 16:08:19.271 IST [24344] LOG: received SIGHUP, reloading configuration files pg_reload_conf ---------------- t (1 row) Time: 16.103 ms C1MQV0FZDTY3:bin bajishaik$ psql -p 5556 -U bajishaik -c "select pg_reload_conf()" Timing is on. Pager usage is off. 2018-03-21 16:08:29.929 IST [24387] LOG: received SIGHUP, reloading configuration files pg_reload_conf ---------------- t (1 row) Time: 53.542 ms C1MQV0FZDTY3:bin bajishaik$ -
Create a couple of test tables to replicate and insert some data on Publication instance.
postgres=# create database source_rep; CREATE DATABASE Time: 662.342 ms postgres=# c source_rep You are now connected to database "source_rep" as user "bajishaik". source_rep=# create table test_rep(id int primary key, name varchar); CREATE TABLE Time: 63.706 ms source_rep=# create table test_rep_other(id int primary key, name varchar); CREATE TABLE Time: 65.187 ms source_rep=# insert into test_rep values(generate_series(1,100),'data'||generate_series(1,100)); INSERT 0 100 Time: 2.679 ms source_rep=# insert into test_rep_other values(generate_series(1,100),'data'||generate_series(1,100)); INSERT 0 100 Time: 1.848 ms source_rep=# select count(1) from test_rep; count ------- 100 (1 row) Time: 0.513 ms source_rep=# select count(1) from test_rep_other ; count ------- 100 (1 row) Time: 0.488 ms source_rep=# -
Create structure of the tables on Subscription instance as Logical Replication does not replicate the structure.
postgres=# create database target_rep; CREATE DATABASE Time: 514.308 ms postgres=# c target_rep You are now connected to database "target_rep" as user "bajishaik". target_rep=# create table test_rep_other(id int primary key, name varchar); CREATE TABLE Time: 9.684 ms target_rep=# create table test_rep(id int primary key, name varchar); CREATE TABLE Time: 5.374 ms target_rep=# -
Create publication on Publication instance (port 5555).
source_rep=# CREATE PUBLICATION mypub FOR TABLE test_rep, test_rep_other; CREATE PUBLICATION Time: 3.840 ms source_rep=# -
Create subscription on Suscription instance (port 5556) to the publication created in step 6.
target_rep=# CREATE SUBSCRIPTION mysub CONNECTION 'dbname=source_rep host=localhost user=bajishaik port=5555' PUBLICATION mypub; NOTICE: created replication slot "mysub" on publisher CREATE SUBSCRIPTION Time: 81.729 msFrom log:
2018-03-21 16:16:42.200 IST [24617] LOG: logical decoding found consistent point at 0/1616D80 2018-03-21 16:16:42.200 IST [24617] DETAIL: There are no running transactions. target_rep=# 2018-03-21 16:16:42.207 IST [24618] LOG: logical replication apply worker for subscription "mysub" has started 2018-03-21 16:16:42.217 IST [24619] LOG: starting logical decoding for slot "mysub" 2018-03-21 16:16:42.217 IST [24619] DETAIL: streaming transactions committing after 0/1616DB8, reading WAL from 0/1616D80 2018-03-21 16:16:42.217 IST [24619] LOG: logical decoding found consistent point at 0/1616D80 2018-03-21 16:16:42.217 IST [24619] DETAIL: There are no running transactions. 2018-03-21 16:16:42.219 IST [24620] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep" has started 2018-03-21 16:16:42.231 IST [24622] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep_other" has started 2018-03-21 16:16:42.260 IST [24621] LOG: logical decoding found consistent point at 0/1616DB8 2018-03-21 16:16:42.260 IST [24621] DETAIL: There are no running transactions. 2018-03-21 16:16:42.267 IST [24623] LOG: logical decoding found consistent point at 0/1616DF0 2018-03-21 16:16:42.267 IST [24623] DETAIL: There are no running transactions. 2018-03-21 16:16:42.304 IST [24621] LOG: starting logical decoding for slot "mysub_16403_sync_16393" 2018-03-21 16:16:42.304 IST [24621] DETAIL: streaming transactions committing after 0/1616DF0, reading WAL from 0/1616DB8 2018-03-21 16:16:42.304 IST [24621] LOG: logical decoding found consistent point at 0/1616DB8 2018-03-21 16:16:42.304 IST [24621] DETAIL: There are no running transactions. 2018-03-21 16:16:42.306 IST [24620] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep" has finished 2018-03-21 16:16:42.308 IST [24622] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep_other" has finishedAs you can see in the NOTICE message, it created a replication slot which ensures the WAL cleanup should not be done until initial snapshot or delta changes are transferred to the target database. Then the WAL sender started decoding the changes, and logical replication apply worked as both pub and sub are started. Then it starts the table sync.
-
Verify data on Subscription instance.
target_rep=# select count(1) from test_rep; count ------- 100 (1 row) Time: 0.927 ms target_rep=# select count(1) from test_rep_other ; count ------- 100 (1 row) Time: 0.767 ms target_rep=#As you see, data has been replicated through initial snapshot.
-
Verify delta changes.
C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5555 -d source_rep -c "insert into test_rep values(generate_series(101,200), 'data'||generate_series(101,200))" INSERT 0 100 Time: 3.869 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5555 -d source_rep -c "insert into test_rep_other values(generate_series(101,200), 'data'||generate_series(101,200))" INSERT 0 100 Time: 3.211 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5556 -d target_rep -c "select count(1) from test_rep" count ------- 200 (1 row) Time: 1.742 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5556 -d target_rep -c "select count(1) from test_rep_other" count ------- 200 (1 row) Time: 1.480 ms C1MQV0FZDTY3:bin bajishaik$
These are the steps for a basic setup of Logical Replication.



