blog
Beyond Semantics: Enhancing Retrieval Augmented Generation with Hybrid Search (pgvector + Elasticsearch)

Large Language Models (LLMs) have shown incredible potential, but their reliance on static pre-trained knowledge has been a major limitation. To address this, Retrieval Augmented Generation (RAG) was developed as a solution to enhance LLMs by allowing them to access and incorporate relevant information from external sources in real-time.
However, relying solely on traditional retrieval methods, which often prioritize semantic matching, can be limiting when dealing with the nuances of language and meaning. This is where hybrid search comes in, offering a solution to improve the accuracy and comprehensiveness of information retrieval within RAG.
This blog will explore creating a RAG application that uses hybrid search to address the limitations of Semantic search-based RAG. We will walk you through building a chatbot assistant for an e-commerce website that uses hybrid search to provide accurate and informative responses to user queries about store items.
The role of semantic search in RAG
Semantic search plays a crucial role in the retrieval phase of RAG. Unlike traditional keyword-based search methods, semantic search aims to understand the context and intent behind a query, allowing for more nuanced and relevant information retrieval. It leverages advanced natural language processing techniques and vector representations of text to identify conceptually similar content.
This means that semantic search can:
- Understand synonyms and related concepts
- Interpret the context of words in a query
- Match queries with relevant information even when the exact keywords are not present
For instance, a semantic search for “affordable lightweight laptop” might return results about “budget-friendly ultrabooks” even if the exact terms of the search weren’t used in the product descriptions. Semantic Search plays an important role in the retrieval process and is at the heart of the RAG system.
Limitations of using semantic search for RAG
While Semantic Search has its advantages, it comes with its limitations, in situations where exact terminology is required like e-commerce; when a user searches for product names or technical specifications, a semantic search-based engine would simply try to find the most conceptually similar matches.
For queries requiring exact phrase matches or specific factual information, semantic search is unlikely to produce the necessary level of precision.
Consider a scenario where a customer searches for a specific product model, say “iPhone 13 Pro Max 256GB Sierra Blue“. A purely semantic search might return results for various high-end smartphones or even other iPhone models, missing the exact match the customer needs.
Hybrid search as a solution
To address these limitations, we turn to hybrid search, a powerful combination of keyword-based search and semantic search methodologies. Hybrid search aims to leverage the strengths of both approaches. Keyword-based search produces precision and exact matches, and semantic search provides an understanding of context and intent.
In the context of RAG, hybrid search enhances retrieval by ensuring that an LLM is provided with factually precise (keyword search) and conceptually relevant information (Semantic Search) for a particular query. By combining the contextual understanding of semantic search with the precision of keyword matching, we can create a more robust and accurate retrieval system for our RAG-powered chatbot.
Building an e-commerce chatbot with hybrid search for improved RAG
The e-commerce domain presents unique challenges for AI-powered customer support systems. An effective chatbot must handle a wide variety of queries, from general product information to specific technical details.
Let’s consider some of the challenges an e-commerce chatbot might face:
- Diverse product catalog: The store may offer thousands of products across multiple categories, each with its attributes and specifications.
- Technical specificity: Many products, especially electronics, have precise technical specifications that customers may inquire about.
- Natural language variations: Customers might ask about the same product or feature using different phrases or terms.
- Intent understanding: The chatbot needs to discern whether a customer is looking for general information, comparing products, or seeking a specific item.
In this section, we’ll dive into the technical implementation of our hybrid search system, showing how to combine PostgreSQL’s pgvector for semantic search and Elasticsearch for keyword search to create a powerful, flexible retrieval mechanism for an e-commerce chatbot.
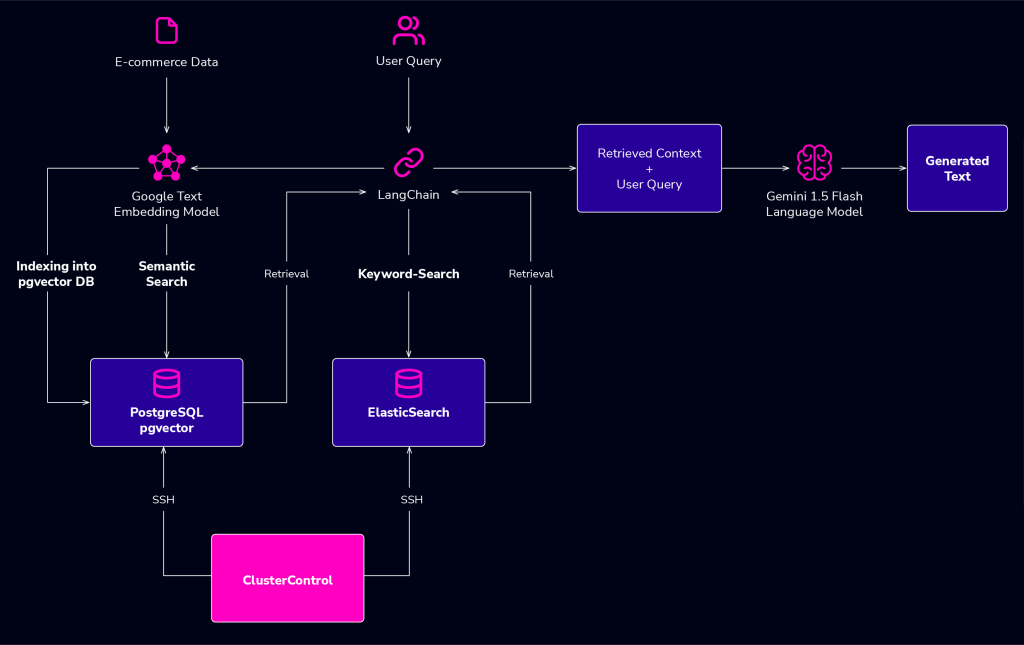
The core components of the RAG system
The following are the components that make up the RAG system:
- Knowledge Base — The knowledge base for this application is an e-commerce dataset of Amazon products.
- Large Language Model — Gemini 1.5 Flash by Google. This will be the AI responsible for the generation of text and reasoning in the application.
- LangChain — LangChain is an LLM tooling and orchestration library that provides tools for connecting LLMs to other tools (databases, interpreters, etc.), building advanced prompt templates, and orchestrating LLM-based applications and utilities.
- Embedding Model — the Google Text Embedding/004 embedding model converts texts into embeddings that can be indexed and searched in a vector database.
- Semantic search with PostgreSQL pgvector — helps the retrieval system find contexts that are conceptually and semantically relevant.
- Keyword Search Index with Elasticsearch — helps the retrieval system perform keyword-based search to find exact keyword matches.
- ClusterControl — In this demo, we use ClusterControl (CC) to set up the PostgreSQL pgvector database and Elasticsearch. ClusterControl is a database orchestration platform that lets anyone deploy and manage the world’s most advanced databases.
N.B. CC is not necessary, feel free to set up a standard PostgreSQL and Elasticsearch database using your preferred method.
These components together provide the mechanism for retrieving relevant information to a user’s query about store items which is then integrated with the language model’s input to generate accurate and factually grounded outputs.
Demo walkthrough
The following demo was implemented in Jupyter Notebook, an interactive coding environment that lets you combine code visualizations, and explanatory text in a single document.
You can test the demo on Google Colab’s free Jupyter Notebook service and follow the demo by running each cell in the notebook. The cells in the notebook are to be run sequentially and go hand-in-hand with the walkthrough below.
If you like to follow along with the blog, below are the prerequisites.
Prerequisites:
- Google AI Studio Developer API Key
- Python (3.8 and above)
- A Jupyter Notebook
Install the necessary Python libraries:
%pip install --upgrade --quiet langchain-elasticsearch elasticsearch
%pip install --upgrade --quiet langchain langchain-postgres langchain-google-genai langchain-communityDeploying PostgreSQL pgvector and Elasticsearch with ClusterControl
With ClusterControl, anyone can deploy high-availability databases in minutes in any environment. To deploy databases with ClusterControl, you self-host it in a Linux node with the following specs:
- x86_64 Arch
- >2 GB RAM
- >2 cores CPU
- >40 GB disk space
- SSH connectivity (so CC can connect to your target database nodes)
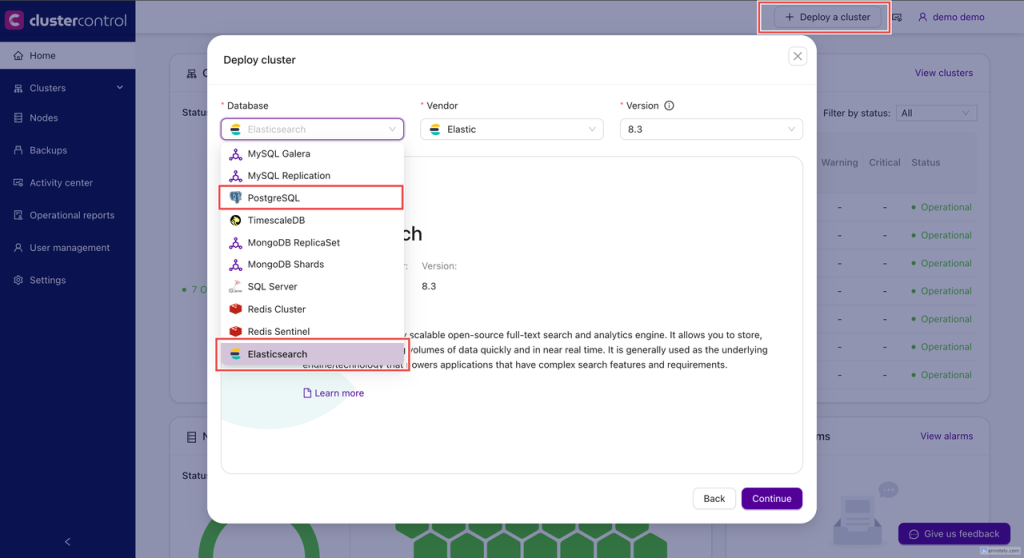
Download and install ClusterControl using one of the available methods (script, Docker, Helm, etc). After installing ClusterControl, click “Deploy a cluster” to get a deployment wizard with several database flavors to choose from. Follow the deployment wizard to deploy PostgreSQL with pgvector and Elasticsearch as highlighted in the image below.
Connecting to the PostgreSQL pgvector database
The Langchain Postgres wrapper is the easiest way to connect to a PostgreSQL pgvector database in the context of our application. Since Langchain provides a lot of tools that ease connecting all of our components to the LLMs, It is only natural to use Langchain’s Postgres PGVector class.
from langchain_postgres.vectorstores import PGVectorTo connect to your vector database you just set up, you only need your connection string and the collection name (also called the server group that hosts your database). These credentials can be found in your PostgreSQL database.
Your connection string should be in the following format:
postgresql://username:password@host:port/database_nameThe LangChain PGVector class gives you complete control over your database and lets you index and query the database directly from the Python environment.
Connecting to the PostgreSQL pgvector database
LangChain also provides an Elasticsearch integration for connecting to and creating Elasticsearch indexes. To connect an Elasticsearch index, the following information is required:
- The IP address and port (defaults to 9200) of your Elasticsearch server.
- ElasticSearch username (defaults to ‘elastic’)
- ElasticSearch Password
We will use these credentials later on to connect to the database.
Step 1: Loading the dataset
Before connecting to the databases, you need to prepare the data for indexing into both databases. In the e-commerce dataset, each row of the dataset describes a product with columns providing information such as the product’s name, the ‘product-id’, and descriptions of the product. The Pandas python library is used to convert the CSV format to a Pandas DataFrame object suitable for performing simple data analysis and having a better objective view of the dataset.
The Pandas library comes bundled with any Jupyter Notebook distribution by default and doesn’t have to be installed.
import pandas as pd
data = pd.read_csv('e-commerce.csv')
We can view some rows of the dataset by running:
data.head(3)
The dataset has the following columns:
(['item_id', 'marketplace', 'country', 'main_image_id', 'domain_name',
'bullet_point', 'item_keywords', 'material', 'brand', 'color',
'item_name', 'model_name', 'model_number', 'product_type'],
dtype='object')Each row of the dataset contains information about the item-id, country, description e.t.c about a product in the store.
Before indexing, you need to create a LangChain document object from the dataset:
from langchain_community.document_loaders.csv_loader import CSVLoader
loader = CSVLoader('e-commerce.csv')
docs = loader.load()The CSVLoader class is used to convert the CSV dataset to a document object which is the smallest unit of information LangChain is built on. Now the entire dataset has been transformed into a document object suitable for working with the rest of the langchain environment.
Step 2: Chunking
Next, the document is split into smaller chunks using the RecursiveCharacterTextSplitter library to split text along each column based on character count, allowing for overlap between chunks to preserve context. The length_function parameter specifies a function the text splitter uses for calculating the length of chunks, in this example we use Python’s default ‘len()’ function.
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)# Split documents
split_docs = text_splitter.split_documents(documents)Step 3: Indexing the PGVector database
Before sending embeddings to the PGVector database, some considerations have to be made. Firstly, we had to choose the column of data to perform a semantic search against. Since the bullet_point column contains a brief description of each product, it makes more sense to use this column to generate embeddings that will be stored in the vector database. This implies that our semantic search retrieval finds products whose descriptions are most similar in meaning to a user’s query.
For example, if a user asks about “ultra-fast cheap notebooks”, our semantic search system will find products whose descriptions are similar to that query. To do this, you need to create a new document object that stores the content of the bullet_point column (contains the description of a product) and the other columns such as item-name, country, etc. as metadata. The following code block does exactly that:
# code for indexing
documents = [
Document(
page_content=row['bullet_point'],
metadata={
'source': 'e-commerce.csv',
'row': idx,
'item_id': row['item_id'],
'item_name': row['item_name'],
'keywords': row['item_keywords'],
'country': row['country'],
'product_type': row['product_type'],
'marketplace': row['marketplace'],
'country': row['country'],
'bullet_point': row['bullet_point'],
'domain_name': row['domain_name'],
}
) for idx, row in data.iterrows() if pd.notna(row['bullet_point'])
]Next, we wrote a function for iterating through the docs and upserting them to the vector database in batches using the PGVector class mentioned earlier.
def insert_documents_in_batches(docs, batch_size=100):
for i in tqdm(range(0, len(docs), batch_size), desc="Inserting batches"):
batch = docs[i:i+batch_size]
try:
PGVector.from_documents(
batch,
embeddings,
collection_name="E-commerce",
connection=conn_string
)
except Exception as e:
print(f"Error inserting batch {i//batch_size + 1}: {str(e)}")
continueThe PGVector.from_documents() function takes embeddings as an argument. This function is the embedding model that creates the vector representation of documents stored in the vector database for semantic search. This application uses the Google embedding/001 model as specified earlier.
embeddings = GoogleGenerativeAIEmbeddings(model="models/embedding-001",google_api_key=GOOGLE_API_KEY)Now you can index the vector database by calling the insert_document_in_batches function on the documents we chunked earlier in split_docs.
insert_documents_in_batches(split_docs)Step 4: Creating the ElasticSearch index
Using the elasticsearch library provided by Elasticsearch and the LangChain Elasticsearch integrations, you can populate your search index with your data. First, import the necessary libraries:
from elasticsearch import Elasticsearch
from langchain_elasticsearch import ElasticsearchRetriever
from langchain_elasticsearch import ElasticsearchStoreThe next step involves connecting to the Elasticsearch database index you created earlier with your credentials:
es_client = Elasticsearch(
[f"http://es_host:es_port"],
http_auth=(es_user, es_password)
)
es_client.info()The es_host variable holds the IP address of the server the Elasticsearch instance is hosted on. The es_port variable holds the port Elasticsearch runs on. By default, Elasticsearch always runs on port 9200 on any machine.
Your credentials should look like this:
es_host = "13.42.34.146" #could be "localhost"
es_port = "9200"
es_user = 'elastic'
es_password = "" #your elasticsearch cluster passwordAfter successfully creating an Elasticsearch instance, you should have the following running at your localhost:9200:
As we did for the PostgreSQL pgvector database, the Elasticsearch index is created by iterating through the dataset (this time the Pandas dataset object called data) and upserting its content to the Elasticsearch Index.
for _, row in data.iterrows():
doc = {
"item_id": row['item_id'],
"marketplace": row['marketplace'],
"country": row['country'],
"main_image_id": row['main_image_id'],
"domain_name": row['domain_name'],
"bullet_point": row['bullet_point']
}
es_client.index(index=ES_INDEX, body=doc)You can confirm the process was successful by running:
es_client.indices.refresh(index=ES_INDEX)The above code will return:
ObjectApiResponse({'_shards': {'total': 2, 'successful': 1, 'failed': 0}})Now, you can use the Langchain ElastcsearchRetriever.from_es_params class to perform a keyword search on your index.
Define a function that specifies the schema the search index uses:
def query_function(search_query: str):
return {
"query": {
"multi_match": {
"query": search_query,
"fields": ["item_name", "item_id", "bullet_point"],
}
}
}
The query_function searches through the item_name,item_id, and bullet_point columns of the dataset. This function is passed as an argument to the ElasticsearchRetriver.from_es_params class provided by LangChain. This class connects Langchain to your index.
keyword_retriever = ElasticsearchRetriever.from_es_params(
url=f"https://{es_host}:{es_port}",
username = es_user,
password = es_password,
index_name=ES_INDEX,
body_func=query_function,
# content_field={
# "item_name": "Name",
# "item_id": "ID",
# "bullet_point": "Description"
# },
document_mapper=custom_document_mapper,
)
The keyword_retriever will be used by your application for connecting and searching through the Elasticsearch index created by the es_client on your server.
You can test out a simple keyword search through the database by using the invoke() method of the keyword_retriever you created and searching for a product in the database.
query = "Micromax Yu Yureka Black"
results = keyword_retriever.invoke(query)
for doc in results:
print(doc.page_content)
print(doc.metadata)
print("---")
Which returns all products in the dataset containing the input query “Micromax Yu Yureka Black”.

Step 5. Instantiating the LLM
As mentioned earlier, the Large Language Model used in this demo is the Google Gemini 1.5 Flash (the perfect balance between performance and efficiency among the models provided by Google).
llm = ChatGoogleGenerativeAI(
model="gemini-1.5-flash",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
# other params...
)
The final part of the application involves providing the Large Language model with information from the Hybrid Search Retrieval system to answer user queries during conversations.
The LLM must be prompted to assume the role of a Shopping Assistant. This is done by creating a system prompt which is just a message sent to the large language model describing its role in the conversation to customers.
system_prompt = """
You are an intelligent e-commerce shop assistant for a large online retailer. Your role is to provide helpful, accurate, and relevant information to customers about products in our inventory. Use the following guidelines:
1. Always base your responses on the product information provided in the context. Do not invent or assume details that are not explicitly stated.
2. If asked about a specific product, provide details such as the product name, ID, and key features from the bullet points.
3. When comparing products or suggesting alternatives, only reference products mentioned in the given context.
4. If the user asks about pricing, availability, or shipping, provide the information if it's available in the context. If it's not available, politely inform the user that you'd need to check the latest information.
5. Be concise but informative. Organize information in a clear, easy-to-read format when appropriate.
6. If the user's query cannot be fully answered with the information provided, acknowledge this and offer to help find more details or suggest contacting customer service.
7. Maintain a friendly, professional tone. Be helpful and courteous, but remember that you are an AI assistant, not a human.
8. If asked about personal opinions on products, politely explain that as an AI assistant, you don't have personal preferences, but you can provide factual information to help the customer make an informed decision.
9. If the user's query is unclear or could have multiple interpretations, ask for clarification to ensure you provide the most relevant information.
Remember, your primary goal is to assist customers in finding the right products and information, enhancing their shopping experience with our e-commerce platform.
"""The system prompt is sent to the LLM as the first message in a format created by LangChain’s SystemMessage function:
messages = [
SystemMessage(content=system_prompt),
HumanMessage(content="Hi,"),
AIMessage(content="hello")
]
Subsequent responses from the LLM are stored as AIMessage objects and Human messages or user queries are stored as HumanMessage.
The final part of the RAG application is a function that takes a user query, performs a hybrid search, and passes the relevant context together with the user’s query to the LLM as a single message.
def hybrid_search(query: str, k: int = 5):
# Perform keyword search
db = PGVector(
connection=conn_string,
embeddings=embeddings,
collection_name=collection_name
)
keyword_results = keyword_retriever.invoke(query)
# Perform semantic search
semantic_results = db.similarity_search(query)
# Combine and rank results
combined_results = []
seen_ids = set()
# Add keyword results first
for doc in keyword_results:
if doc.metadata['item_id'] not in seen_ids:
combined_results.append({
'item_name': doc.metadata['item_name'],
'item_id': doc.metadata['item_id'],
'description': doc.page_content.split('Description: ')[-1],
'score': doc.metadata['score'],
'source': 'keyword'
})
seen_ids.add(doc.metadata['item_id'])
# Add semantic results
for doc in semantic_results:
if doc.metadata['item_id'] not in seen_ids:
combined_results.append({
'item_name': doc.metadata['item_name'],
'item_id': doc.metadata['item_id'],
'description': doc.page_content,
'score': doc.metadata.get('score', 0), # Semantic search might not have a score
'source': 'semantic'
})
seen_ids.add(doc.metadata['item_id'])
# Sort results by score in descending order
combined_results.sort(key=lambda x: x['score'], reverse=True)
# Return top k results
return combined_results[:k]
The function above performs semantic and keyword searches on the Elasticsearch index and PostgreSQL pgvector database.
The augment_prompt function below adds the retrieved information to the user query sent to the Large Language Model.
def augment_prompt(query):
retrieved_context = hybrid_search(query)
source_knowledge = "\n".join([f"Description: {doc['description']}\nItem Name: {doc['item_name']}\nItem ID: {doc['item_id']}\nScore: {doc['score']}\nSource: {doc['source']}" for doc in retrieved_context])
augmented_prompt = f"""Query: {query}
Retrieved Context:
{source_knowledge}
Based on the above context, please provide a detailed and accurate response to the query."""
return augmented_prompt
When a user enters a query, the query is first passed to the augment_query function that adds relevant context before it is added to the rest of the conversation;
user_query = "Find me a hard back case for a Lenovo K4 Note"
messages.append(HumanMessage(augment_prompt(user_query)))
User workflow
The components of the RAG system are now in place and here’s a simple workflow for how the application works :
- A user enters a query about a product.
- The query is converted to an embedding vector used for semantic search against the vectors in the PostgreSQL pgvector database where the most semantically and contextually similar documents to the user query are returned.
- The user query is also used for keyword searches against the ElasticSearch Index to find keyword matches in cases where specific product names are mentioned.
- The returned documents from the Semantic Search and Keyword Search are fed to the large language model with the user’s query to provide factually grounded context for answering questions about a product.
An example scenario
In the following conversation, a user asks the assistant a question about the availability and price of a specific product. The user’s query:
"Find me a hard back case for a Lenovo K4 Note"
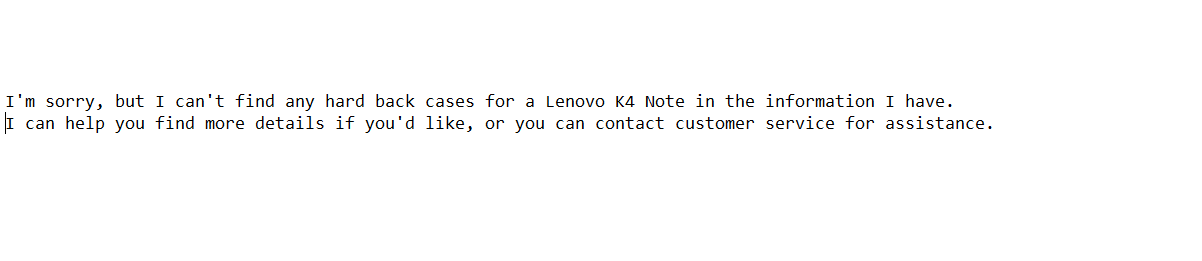
In the example above if using just semantic search-based RAG, the LLM won’t provide the relevant context to correctly answer the user’s request. The hybrid search retrieval system provided the LLM with the right context to provide the best answer to the user’s query given the information in the database. As can be seen in the LLM’s output, the user requests an item that isn’t available in the store’s database.
Going through the database, you can see that there are only soft-back cases available and not the hard-back cases that the user requested.

Another example scenario
With the Hybrid search system, users can also make descriptive queries if they don’t know exactly what they want since the semantic search component of the retrieval system will still provide the necessary context. The LLM can now provide accurate answers to questions like:
"are in-ear headphones available"LLM’s response:

Scaling RAG systems with open source software
The implementation of our hybrid search RAG system marks a significant leap forward in the capabilities of an e-commerce chatbot, substantially improving the shopping experience for users. This advanced approach combines the strengths of both keyword-based and semantic search methodologies, resulting in a more versatile and user-friendly interface.
Open-source tools remain highly relevant in the AI landscape, particularly in the realm of customization. Unlike proprietary tools, open source tool enable organizations to innovate in their use cases contributing to the advancement of AI.
While our demonstration focuses on a simplified implementation, it’s important to note that as the system scales, the underlying infrastructure (models, databases, etc) needs scale too. This is where tools like ClusterControl become invaluable, streamlining the setup, maintenance and scaling of open-source databases like PostgreSQL pgvector and Elasticsearch, ensuring optimal performance and reliability as RAG systems grows to handle larger datasets and increased user traffic.
Try out ClusterControl with a free 30-day trial.



