blog
Improving LLM Fidelity with Retrieval Augmented Generation using pgvector

Large language models (LLMs) have taken the world by storm, wowing us with their ability to generate remarkably human-like text. But for all their prowess, these AI marvels still face major roadblocks – especially when it comes to knowledge-intensive tasks requiring up-to-date, factual information.
While LLMs excel at generating human-like text based on the patterns and information they’ve learned during training, they face significant limitations when it comes to accessing and incorporating information outside of their training set or data created after their training cutoff date. This is a limitation of the technology itself as Transformers – a deep learning architecture that powers LLMs today – are essentially just a bunch of weight matrices and activation functions.
This blog will introduce Retrieval Augmented Generation (RAG) by highlighting the problems it solves before walking you through a hands-on demo showcasing how to implement a simple naive RAG application using PostgreSQL pgvector, Open AI and the LangChain framework.
LLMs, hallucinations, and their consequences
Large Language Models are exceptional at mimicking and recombining the data they’ve been exposed to during training, but they cannot actively seek out and integrate new information from external sources. This limitation can lead to hallucinations, where the model generates reasonable-sounding but factually incorrect or outdated responses, particularly when faced with queries that require up-to-date or specialized knowledge not covered in their training data.
Unfortunately, hallucinations are an intrinsic feature of Large Language Models; as former Head of AI at Tesla Andrej Karpathy once said, “Hallucinations are all language models do, they are dreaming machines.” Hallucinations can include everything from topic digression to factually incorrect output, which can pose downright dangerous consequences for essential use cases, like healthcare, hindering the broader adoption of LLMs.
Options for solving the LLM hallucination problem
There are currently two main paradigms for solving the hallucination problem:
- Fine-tuning
- In-context learning
Fine-tuning
Fine-tuning involves further training a pre-trained model on a particular task or dataset. Fine-tuning can be complex and expensive to operationalize and doesn’t guarantee what information gets parameterized in the model since a sample has to occur a certain number of times in training for a model to memorize it. It also usually requires expensive infrastructure and a large technical debt to operationalize.
For context, GPT-3.5 is a 170 billion parameter model that would require at least half a terabyte of VRAM to fit in memory for training. The model itself was trained on 1024 Nvidia V100 GPUs and the training process cost about 4 million dollars. Fine-tuning is a very expensive solution, even without considering the technical expertise and infrastructure needed to run 1024 computers in parallel.
Though fine-tuning has its use-cases in AI systems, since it changes the core knowledge and abilities of a language model, it is an overkill solution for solving hallucination, and its cost renders it infeasible for most.
In-context learning
In-context learning involves trying to control the behavior or output of a model through its input, prompting techniques, and few-shot examples.
Recent trends have seen larger context lengths in the most recent LLMs with GPT4 having a context length of 128k tokens, Anthropic’s Claude-3 200k tokens, and the recently announced infinite-context window by Google.
Increasing context window sizes in language models is far from the perfect solution, despite recent models boasting impressive context lengths. While expanded contexts can improve recall, the computation, memory, and financial costs rapidly become prohibitive. It has also been observed that the performance of language models degrades with increasing query lengths. For example, a single GPT-4 query over 10,000 pages would cost hundreds of dollars.
Another more efficient approach to in-context learning is Retrieval Augmented Generation (RAG). Retrieval Augmented Generation (RAG) offers a more pragmatic solution by maintaining a fixed context window for the language model while dynamically retrieving and conditioning on relevant external knowledge as required.
This allows RAG to provide customized, knowledge-grounded responses in a far more resource-efficient manner compared to simply expanding context windows. With its ability to scale seamlessly across broad domains without retraining or unreasonable costs, RAG emerges as a compelling alternative to the brute-force approach of exponentially growing context lengths.
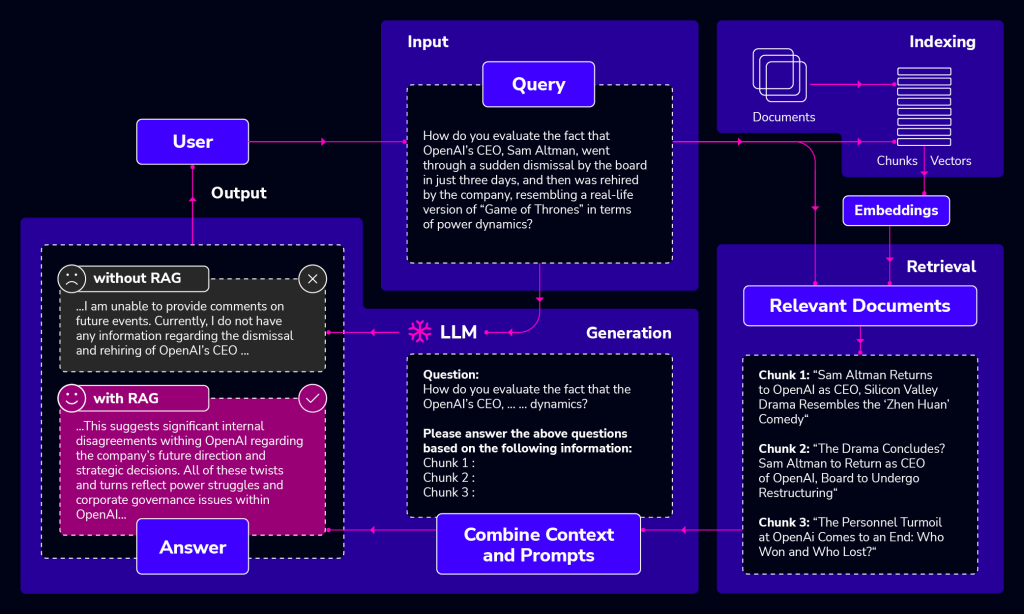
Demoing Retrieval Augmented Generation (RAG) with OpenAI, LangChain, and pgvector
To showcase the capabilities RAG unlocks for LLMs, I will walk you through building a naive RAG application. Through this hands-on example, you’ll see how RAG transcends the limitations of LLMs on unparameterized knowledge, allowing them to break free from the boundaries of their training data and deliver accurate, informative responses by seamlessly integrating external knowledge sources.
We will integrate a large language model with the Magna Carta – one of history’s most pivotal documents. By providing contextual excerpts from the Magna Carta as input, you will see how the model can accurately generate information grounded in contexts relevant to the user’s query.
The core components of the RAG System
The following are the components that make up the RAG system:
- Knowledge base — Magna Carta – the knowledge base contains the documents/information to be semantically searched and retrieved for augmenting the language model.
- Large Language Model — GPT-3.5 by OpenAI – GPT-3.5 is responsible for the generation aspect, producing outputs based on the provided inputs. It has a 175 billion parameter model and a knowledge cut-off date of September 2021.
- LangChain — LangChain is an LLM tooling and orchestration library that provides tools for connecting LLMs to other tools (such as calculators, databases, and interpreters), building advanced prompt templates, and orchestrating LLM-based applications and utilities.
- Embedding model — OpenAI Ada-002 embedding model – OpenAI’s Ada-002 converts texts into embeddings that can be indexed and searched in a vector database. The Embedding model is a Sentence-Transformer model that creates an embedding (essentially a vector in n-dimensions) that captures the semantic meaning of a piece of text.
embeddings = OpenAIEmbeddings()Vector database — PostgreSQL pgvector – at the core of every Retrieval Augmented Generation (RAG) application lies a vector database, responsible for the retrieval stage. The role of a fast and scalable vector database cannot be overstated in RAG applications and this is where pgvector comes to play. pgvector will store the embeddings and perform semantic searches to retrieve the most contextually relevant results for a given query. The input query, along with the retrieved context, is then fed into a language model to generate an answer.
Together, these components enable semantic retrieval of relevant knowledge from the database, which is then integrated with the language model’s input to generate accurate, knowledge-grounded outputs.
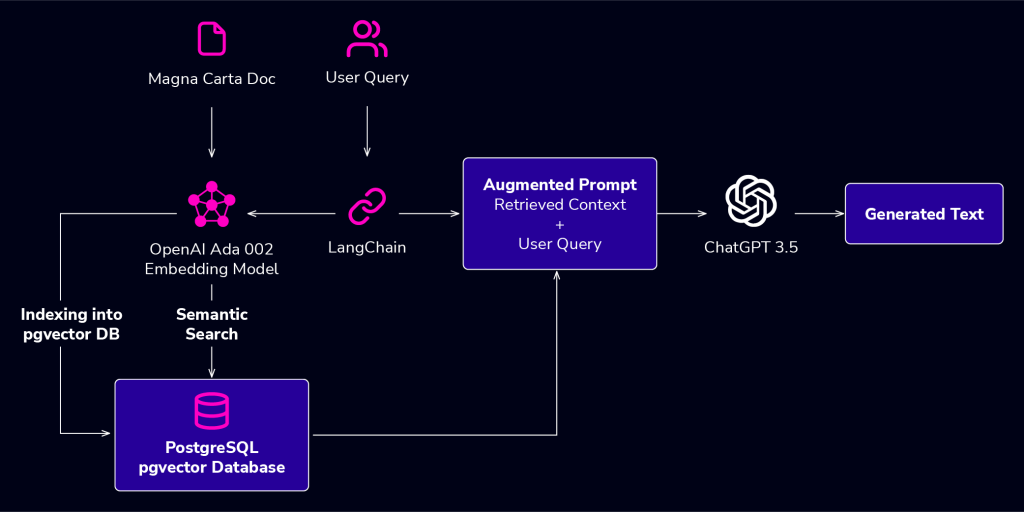
Demo walkthrough
The following demo was implemented with Jupyter Notebook, which is an interactive coding environment that allows you to combine code, visualizations, and explanatory text in a single document.
You can test out the demo on Google Colab’s free Jupyter Notebook service. The cells in the notebook are to be run sequentially and go hand-in-hand with the walkthrough below.
If you like to follow along with the demo, below are the prerequisites.
Prerequisites:
- Your OpenAI API key.
- Python (3.8 or above) and pip installed locally.
- Jupyter Notebook installed.
- Download the Magna Carta document.
Installing necessary libraries:
pip install -qU langchain langchain-postgres langchain-openaiSetting up a PostgreSQL cluster with pgvector
The PostgreSQL pgvector database used in this demo is set up with ClusterControl.
N.B. CC is not necessary, feel free to set up a standard PostgreSQL database using your preferred method.
ClusterControl can help you deploy a high availability PostgreSQL database in minutes on any environment.
ClusterControl supports pgvector, letting you enable it within its PostgreSQL deployment wizard.
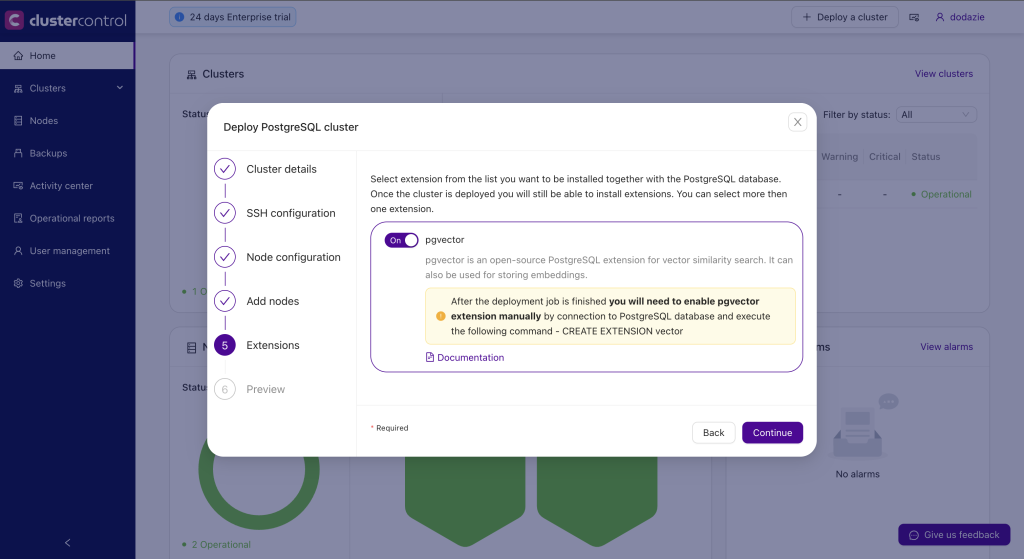
To deploy a PostgreSQL pgvector database with ClusterControl, you self host it in a Linux node – with x86_64 Arch, >2 GB RAM, >2 cores CPU, >40 GB disk space – and then connect it to your target database nodes via SSH.
Download and install ClusterControl using one of the available methods (script, Docker, Helm, etc). Once set up, follow the pgvector set up instructions.
Connect to the PostgreSQL pgvector database
Next, you will need to establish a connection between your application and the PostgreSQL database.
Luckily, LangChain provides integration with pgvector, making life easier.
from langchain_postgres.vectorstores import PGVectorTo connect to your vector database, you need your connection string and the collection name (also known as a server group that stores your current database).
The LangChain `PGVector` class allows us to create a database object for indexing and querying your vector database using the connection string of your database instance.
Your connection string should be in the following format:
postgresql://username:password@host:port/database_name
Replace the placeholders with your actual credentials and database details.
With the connection string in hand, you will be able to create an instance of the `PGVector` database class later.
import os
# Retrieve the connection string from an environment variable
CONNECTION_STRING = os.environ.get('POSTGRES_CONNECTION_STRING')Preparing the knowledge source for indexing
The next crucial stage involves preparing your knowledge source, the Magna Carta document, for indexing in the vector database. To achieve this, you need to split the document into smaller chunks. Chunking is essential for several reasons:
- It allows for efficient storage and retrieval of relevant information from the document.
- It enables you to work with manageable units of text, rather than the entire document at once.
- It facilitates better context understanding and ensures relevant passages are retrieved during the querying process.
Fortunately, Langchain provides powerful tools to simplify this chunking process.
Step 1: Loading the document
LangChain offers the PyPDFLoader class, which can read data from PDF files and convert them into a Document object, a custom Langchain object that allows for useful features like chunking.
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader('/path/to/magna-carta.pdf')
docs = loader.load()
Step 2: Splitting the document into chunks
Once you have the document loaded, you can use LangChain’s RecursiveCharacterTextSplitter to split it into smaller chunks. This class splits the text based on character count, allowing for a specified overlap between chunks to preserve context.
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=50)
texts = text_splitter.split_documents(docs)In this example, you’ve split the Magna Carta document into text chunks of 1000 characters each, with a 50-character overlap between adjacent chunks.
Step 3: Indexing the chunks in pgvector
With the document chunked, you can now embed these text chunks and send them to your PostgreSQL pgvector database using the PGVector class from LangChain.
from langchain.embeddings import OpenAIEmbeddings
from langchain_postgres import PGVector
embeddings = OpenAIEmbeddings()
db = PGVector.from_documents(
embedding=embeddings,
documents=texts,
connection_string=CONNECTION_STRING,
collection_name="magna_carta_collection"
)Here, you are using OpenAI’s embedding model to generate vector representations of text chunks. These embeddings, along with the corresponding text chunks, are then indexed in your PostgreSQL vector database using the LangChain PGVector.from_documents method.
Querying the knowledge base and generating responses
With your knowledge base (the Magna Carta document) indexed in the pgvector, you’re now ready to integrate it with a Large Language Model to generate accurate, knowledge-grounded responses.
Setting up the LLM
Langchain provides a convenient interface for interacting with LLMs, such as OpenAI’s GPT-3.5. You will use the ChatOpenAI class to establish a connection with the GPT-3.5 chat endpoint.
Note: to run the ChatOpenAI() function, you need to set your OpenAI API key as an environment variable or pass it directly to the function as shown below.
chat = ChatOpenAI(
model = 'gpt-3.5-turbo-0125'
#openai_api_key = 'your api key here'
)
The ChatOpenAI class expects messages in the following format using the langchain schemas imported below:
from langchain.schema import (
SystemMessage,
HumanMessage,
AIMessage
)
messages = [
SystemMessage(content="You are a helpful assistant."),
HumanMessage(content="Hi AI, how are you today?"),
AIMessage(content="I'm great thank you. How can I help you?"),
HumanMessage(content="I'd like to understand string theory.")
]
We generate the next response from the AI by passing these messages to the ChatOpenAI object.
res = chat(messages)
Subsequent conversations are continued by simply appending responses and queries to the message object as in the following case:
messages.append(res)
prompt = HumanMessage(
content="Why do physicists believe it can produce a 'unified theory'?"
)
messages.append(prompt)
# send to chat-gpt
res = chat(messages)
print(res.content)The final step of the RAG system involves implementing a function that performs the following tasks:
1. Conduct a similarity search on pgvector using the user’s query.
2. Retrieves the most relevant context from the indexed knowledge base.
3. Appends the retrieved context to the user’s query, creating an augmented prompt.
4. Pass the augmented prompt to the language model.
def augment_prompt(query):
# Perform similarity search and retrieve relevant documents
docs = db.similarity_search(query, k=5)
# Join the page content of the retrieved documents
source_knowledge = '\n'.join([doc.page_content for doc in docs])
# Create the augmented prompt
augmented_prompt = f"""Using the contexts below, answer the query:
Contexts:
{source_knowledge}
Query: {query}
"""
return augmented_promptThe above function:
- Finds relevant documents by performing a similarity search on the vector database using the user’s query, retrieving the top `k`(here k = 5 is arbitrary and is the number of chunks we would like to retrieve from the vector database) most relevant documents.
- The page content of these retrieved documents is concatenated to form the source knowledge.
- An augmented prompt is created, instructing the language model to use the provided contexts to answer the query.
- The augmented prompt is passed to the `chat_model` (GPT-3.5), which generates a response.
Putting it all together
The augment_prompt function above chains the whole application together. It passes the user’s query to the embedding which returns an embedding vector of the query. This vector is then used to perform a semantic search on the pgvector database and the relevant contexts are retrieved. The contexts are then added to the user’s query together with a prompt that instructs the language model to generate a response only using the provided context.
With these components in place, you can now query the Magna Carta knowledge base and receive accurate, context-aware responses generated by the language model. Here’s an example:
messages = [
SystemMessage(content="You are a helpful assistant."),
HumanMessage(content="Hi AI, how are you today?"),
AIMessage(content="I'm great thank you. How can I help you?"),
]The SystemMessage tells GPT-3.5 what role to assume in the conversation.
The AIMessage is GPT- 3.5’s response and the HumanMessage contains the user’s input.
Your augmented query is appended to the HumanMessage and sent to the GPT-3.5 API endpoint.
query = "What happens if a man dies owing money to a foreigner according to the magna carta"
prompt = HumanMessage(
content=augment_prompt(query)
)
messages.append(prompt)
res = chat(messages)
print(res.content)GPT3.5’s response
Without RAG:
The Magna Carta, signed in 1215, was a foundational document in English law that established certain rights and principles. While it did not specifically address debts owed to foreigners, it did contain provisions related to debt collection and inheritance. \n\nIn general, if a person died owing money to a foreign individual, the debt would typically be considered part of the deceased person's estate. The Magna Carta included provisions related to the protection of property rights and the rights of heirs, so the debt would likely need to be settled as part of the estate administration process.\n\nIt's important to note that laws and practices have evolved significantly since the time of the Magna Carta, and modern laws regarding debt collection, inheritance, and estate administration are governed by a different legal framework.With RAG:
If a man dies owing money to a foreigner according to the Magna Carta document, his wife shall have her dower and pay nothing of that debt. If there are children of the deceased who are left underage, necessaries shall be provided for them in line with the holding of the deceased. Out of the residue of the deceased's estate, the debt to the foreigners shall be paid, while reserving service due to feudal lords. This provision is also applied to debts owed to individuals other than foreigners.The actual content of the Magna Carta:
(7) At her husband's death, a widow may have her marriage portion and inheritance at
once and without trouble. She shall pay nothing for her dower, marriage portion, or any
inheritance that she and her husband held jointly on the day of his death. She may
remain in her husband's house for forty days after his death, and within this period her
dower shall be assigned to her.This query will trigger the retrieval of relevant passages from the indexed Magna Carta document, which will be appended to the query prompt. The language model will then generate a response, drawing upon the provided context to deliver an informed and accurate answer.
Unlocking the frontier of context-aware AI assistants
Whether it’s engaging with studies like the Magna Carta or navigating complex domains like healthcare and finance, or creating a personalized experience with your own files. RAG unlocks new frontiers for AI assistants, fostering more meaningful and informed interactions.
As you have explored in this article, building a RAG system involves carefully orchestrating the interplay between language models, embedding models, vector databases, and knowledge bases. pgvector, the vector database in this RAG system, makes it easy for organizations who already use PostgreSQL to build AI systems within their existing or new database — this eliminates the need for separate vector databases or complex workarounds.
ClusterControl simplifies the process of setting up pgvector, and you can explore its functionality with a free 30 day trial.
Follow us on LinkedIn and Twitter for more great content in the coming weeks. Stay tuned!



