blog
Top Mistakes to Avoid in MySQL Replication

Setting up replication in MySQL is easy, but managing it in production has never been an easy task. Even with the newer GTID auto-positioning, it still can go wrong if you don’t know what you are doing. After setting up replication, all sorts of things can go wrong. Mistakes can easily be made and can have a disastrous ending for your data.
This post will highlight some of the most common mistakes made with MySQL replication, and how you can prevent them.
Setting up Replication
When setting up MySQL replication, you need to prime the slave nodes with the dataset from the master. With solutions like Galera cluster, this is automatically handled for you with the method of your choice. For MySQL replication, you need to do this yourself, so naturally you take your standard backup tool.
For MySQL there is a huge variety of backup tools available, but the most commonly used one is mysqldump. Mysqldump outputs a logical backup of the dataset of your master. This means the copy of the data is not going to be a binary copy, but a big file containing queries to recreate your dataset. In most cases this should provide you with a (near) identical copy of your data, but there are cases where it will not – due to the dump being on a per object basis. This means that even before you start replicating data, your dataset is not the same as the one on the master.
There are a couple of tweaks you can do to make mysqldump more reliable like dump as a single transaction, and also don’t forget to include routines and triggers:
mysqldump -uuser -ppass --single-transaction --routines --triggers --all-databases > dumpfile.sqlA good practice is to check if your slave node is 100% the same, is by using pt-table-checksum after setting up the replication:
pt-table-checksum --replicate=test.checksums --ignore-databases mysql h=localhost,u=user,p=passThis tool will calculate a checksum for each table on the master, replicate the command to the slave and then the slave node will perform the same checksum operation. If any of the tables are not the same, this should be clearly visible in the checksum table.
Using the Wrong Replication Method
The default replication method of MySQL was the so called statement-based replication. This method is exactly what it is: a replication stream of every statement run on the master that will be replayed on the slave node. Since MySQL itself is multi-threaded but it’s (traditional) replication isn’t, the order of statements in the replication stream may not be 100% the same. Also replaying a statement may give different results when not executed on the exact same time.
This may result in different datasets between the master and slave, due to data drift. This wasn’t an issue for many years, as not many ran MySQL with many simultaneous threads, but with modern multi-CPU architectures, this actually has become highly probable on a normal day-to-day workload.
The answer from MySQL was the so called row-based replication. Row based replication will replicate the data whenever possible, but in some exceptional cases still use statements. A good example would be the DLL change of a table, where the replication then would have to copy every row in the table through replication. Since this is inefficient, such a statement will be replicated in the traditional way. When row based replication detects data drift, it will stop the slave thread to prevent making things worse.
Then there is a method in between these two: mixed mode replication. This type of replication will always replicate statements, except when the query contains the UUID() function, triggers, stored procedures, UDFs and a few other exceptions are used. Mixed mode will not solve the issue of data drift and, together with statement-based replication, should be avoided.
Circular Replication
Running MySQL replication with multi-master is often necessary if you have a multi-datacenter environment. Since the application can’t wait for the master in the other datacenter to acknowledge your write, a local master is preferred. Normally the auto increment offset is used to prevent data clashes between the masters. Having two masters perform writes to each other in this way is a broadly accepted solution.
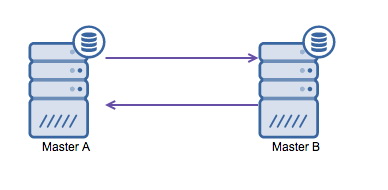
However if you need to write in multiple datacenters into the same database, you end up with multiple masters that need to write their data to each other. Before MySQL 5.7.6 there was no method to do a mesh type of replication, so the alternative would be to use a circular ring replication instead.
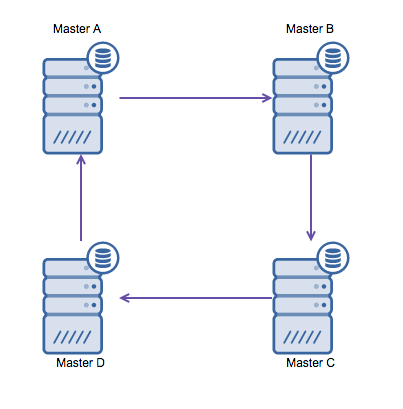
Ring replication in MySQL is problematic for the following reasons: latency, high availability and data drift. Writing some data to server A, it would take three hops to end up on server D (via server B and C). Since (traditional) MySQL replication is single threaded, any long running query in the replication may stall the whole ring. Also if any of the servers would go down, the ring would be broken and currently there is no failover software that can repair ring structures. Then data drift may occur when data is written to server A and is altered at the same time on server C or D.
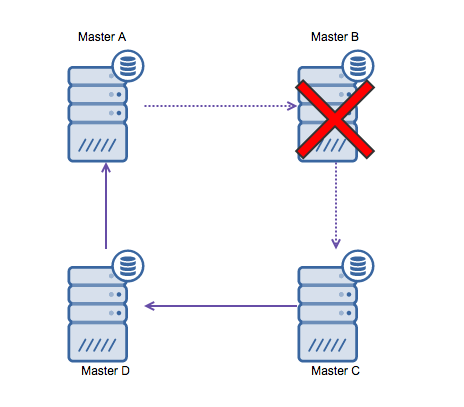
In general circular replication is not a good fit with MySQL and it should be avoided at all costs. Galera would be a good alternative for multi-datacenter writes, as it has been designed with that in mind.
Stalling your Replication with Large Updates
Often various housekeeping batch jobs will perform various tasks, ranging from cleaning up old data till calculating averages of ‘likes’ fetched from another source. This means at set intervals, a job will create a lot of database activity and, most likely, write a lot of data back to the database. Naturally this means the activity within the replication stream will increase equally.
Statement-based replication will replicate the exact queries used in the batch jobs, so if the query took half an hour to process on the master, the slave thread will be stalled for at least the same amount of time. This means no other data can replicate and the slave nodes will start lagging behind the master. If this exceeds the threshold of your failover tool or proxy, it may drop these slave nodes from the available nodes in the cluster. If you are using statement-based replication, you can prevent this by crunching the data for your job in smaller batches.
Now you may think row-based replication isn’t affected by this, as it will replicate the row information instead of the query. This is partly true, as for DDL changes, the replication reverts back to statement-based format. Also large numbers of CRUD operations will affect the replication stream: in most cases this is still a single threaded operation and thus every transaction will wait for the previous one to be replayed via replication. This means that if you have high concurrency on the master, the slave may stall on the overload of transactions during replication.
To get around this, both MariaDB and MySQL offer parallel replication. The implementation may differ per vendor and version. MySQL 5.6 offers parallel replication as long as the queries are separated by schema. MariaDB 10.0 and MySQL 5.7 both can handle parallel replication across schemas, but have other boundaries. Executing queries via parallel slave threads may speed up your replication stream if you are write heavy. However if you aren’t, it would be best to stick to the traditional single threaded replication.
Schema Changes
Performing schema changes on a running production setup is always a pain. This has to do with the fact that a DDL change will most of the time lock a table and only release this lock once the DDL change has been applied. It even gets worse once you start replicating these DDL changes through MySQL replication, where it will in addition stall the replication stream.
A frequently used workaround is to apply the schema change to the slave nodes first. For statement-based replication this works fine, but for row-based replication this can work up to a certain degree. Row-based replication allows extra columns to exist at the end of the table, so as long as it is able to write the first columns it will be fine. First apply the change to all slaves, then failover to one of the slaves and then apply the change to the master and attach that as a slave. If your change involves inserting a column in the middle or removal of a column this will work with row-based replication.
There are tools around that can perform online schema changes more reliably. The Percona Online Schema Change (as known as pt-osc) will create a shadow table with the new table structure, insert new data via triggers and backfill data in the background. Once it is done creating the new table, it will simply swap the old for the new table inside a transaction. This doesn’t work in all cases, especially if your existing table already has triggers.
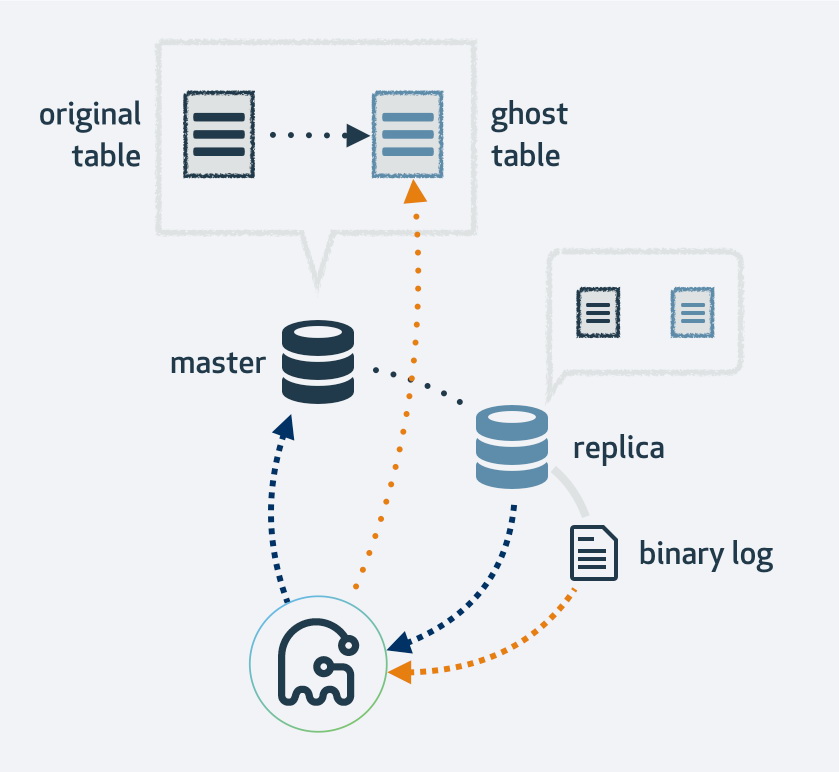
An alternative is the new Gh-ost tool by Github. This online schema change tool will first make a copy of your existing table layout, alter the table to the new layout and then hook up the process as a MySQL replica. It will make use of the replication stream to find new rows that have been inserted into the original table and at the same time it backfills the table. Once it is done backfilling, the original and new tables will switch. Naturally all operations to the new table will end up in the replication stream as well, thus on each replica the migration happens at the same time.
Memory Tables and Replication
While we are on the subject of DDLs, a common issue is the creation of memory tables. Memory tables are non-persistent tables, their table structure remains but they lose their data after a restart of MySQL. When creating a new memory table on both a master and a slave, both will have an empty table and this will work perfectly fine. Once either one gets restarted, the table will be emptied and replication errors will occur.
Row-based replication will break once the data in the slave node returns different results, and statement-based replication will break once it attempts to insert data that already exists. For memory tables this is a frequent replication-breaker. The fix is easy: simply make a fresh copy of the data, change the engine to InnoDB and it should now be replication safe.
Setting the read_only Variable to True
As we described earlier, not having the same data in the slave nodes can break replication. Often this has been caused by something (or someone) altering the data on the slave node, but not on the master node. Once the master node’s data gets altered, this will be replicated to the slave where it can’t apply the change and this causes the replication to break.
There is an easy prevention for this: setting the read_only variable to true. This will disallow anyone to make changes to the data, except for the replication and root users. Most failover managers set this flag automatically to prevent users to write to the used master during failover. Some of them even retain this after the failover.
This still leaves the root user to execute an errant CRUD query on the slave node. To prevent this from happening, there is a super_read_only variable since MySQL 5.7.8 that even locks out the root user from updating data.
Enabling GTID
In MySQL replication, it is essential to start the slave from the correct position in the binary logs. Obtaining this position can be done when making a backup (xtrabackup and mysqldump support this) or when you have stopped slaving on a node that you are making a copy of. Starting replication with the CHANGE MASTER TO command would look like this:
mysql> CHANGE MASTER TO MASTER_HOST='x.x.x.x',MASTER_USER='replication_user', MASTER_PASSWORD='password', MASTER_LOG_FILE='master-bin.0001', MASTER_LOG_POS= 04;Starting replication at the wrong spot can have disastrous consequences: data may be double written or not updated. This causes data drift between the master and the slave node.
Also when failing over a master to a slave involves finding the correct position and changing the master to the appropriate host. MySQL doesn’t retain the binary logs and positions from its master, but rather creates its own binary logs and positions. For re-aligning a slave node to the new master this could become a serious problem: the exact position of the master on failover has to be found on the new master, and then all slaves can be re-aligned.
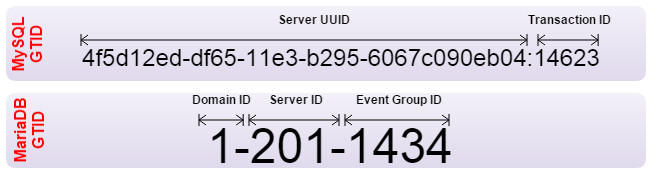
To solve this issue, the Global Transaction Identifier (GTID) has been implemented by both Oracle and MariaDB. GTIDs allow auto aligning of slaves, and in both MySQL and MariaDB the server figures out by itself what the correct position is. However both have implemented the GTID in a different way and are therefore incompatible. If you need to set up replication from one to another, the replication should be set up with traditional binary log positioning. Also your failover software should be made aware not to make use of GTIDs.
Conclusion
We hope to have given you enough tips to stay out of trouble. These are all common practices by the experts in MySQL. They had to learn it the hard way and with these tips we ensure you don’t have to.
We have some additional white papers that might be useful if you’d like to read more about MySQL replication.



