blog
An Overview of Streaming Replication for TimescaleDB

Nowadays, replication is a given in a high availability and fault tolerant environment for pretty much any database technology that you’re using. It is a topic that we have seen over and over again, but that never gets old.
If you’re using TimescaleDB, the most common type of replication is streaming replication, but how does it work?
In this blog, we are going to review some concepts related to replication and we’ll focus on streaming replication for TimescaleDB, which is a functionality inherited from the underlying PostgreSQL engine. Then, we’ll see how ClusterControl can help us to configure it.
So, streaming replication is based on shipping the WAL records and having them applied to the standby server. So, first, let’s see what WAL is.
WAL
Write Ahead Log (WAL) is a standard method for ensuring data integrity, it is automatically enabled by default.
The WALs are the REDO logs in TimescaleDB. But, what are the REDO logs?
REDO logs contain all changes that were made in the database and they are used by replication, recovery, online backup and point in time recovery (PITR). Any changes that have not been applied to the data pages can be redone from the REDO logs.
Using WAL results in a significantly reduced number of disk writes, because only the log file needs to be flushed to disk to guarantee that a transaction is committed, rather than every data file changed by the transaction.
A WAL record will specify, bit by bit, the changes made to the data. Each WAL record will be appended into a WAL file. The insert position is a Log Sequence Number (LSN) that is a byte offset into the logs, increasing with each new record.
The WALs are stored in the pg_wal directory, under the data directory. These files have a default size of 16MB (the size can be changed by altering the –with-wal-segsize configure option when building the server). They have a unique incremental name, in the following format: “00000001 00000000 00000000”.
The number of WAL files contained in pg_wal will depend on the value assigned to the min_wal_size and max_wal_size parameters in the postgresql.conf configuration file.
One parameter that we need to setup when configuring all our TimescaleDB installations is the wal_level. It determines how much information is written to the WAL. The default value is minimal, which writes only the information needed to recover from a crash or immediate shutdown. Archive adds logging required for WAL archiving; hot_standby further adds information required to run read-only queries on a standby server; and, finally logical adds information necessary to support logical decoding. This parameter requires a restart, so, it can be hard to change on running production databases if we have forgotten that.
Streaming Replication
Streaming replication is based on the log shipping method. The WAL records are directly moved from one database server into another to be applied. We can say that it is a continuous PITR.
This transfer is performed in two different ways, by transferring WAL records one file (WAL segment) at a time (file-based log shipping) and by transferring WAL records (a WAL file is composed of WAL records) on the fly (record based log shipping), between a master server and one or several slave servers, without waiting for the WAL file to be filled.
In practice, a process called WAL receiver, running on the slave server, will connect to the master server using a TCP/IP connection. In the master server, another process exists, named WAL sender, and is in charge of sending the WAL registries to the slave server as they happen.
Streaming replication can be represented as following:
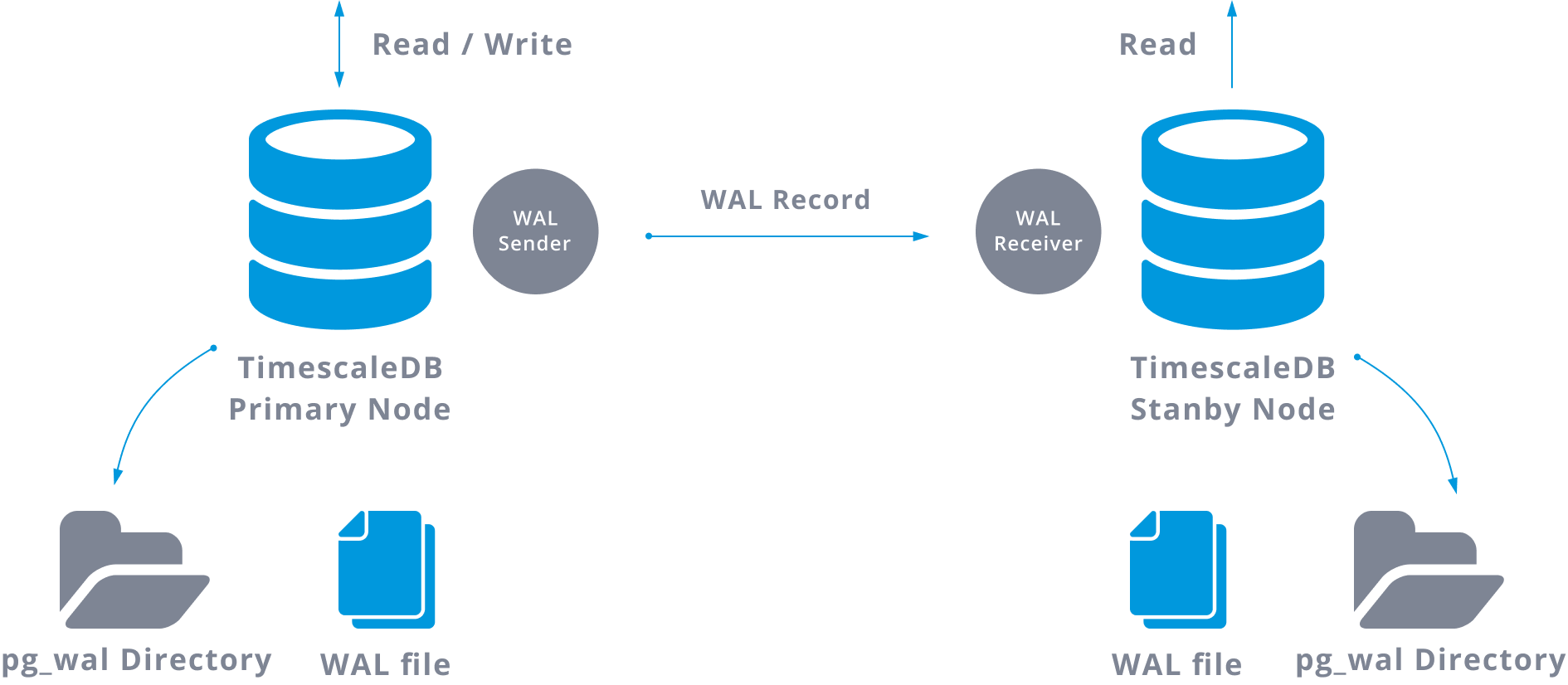
By looking at the above diagram we can think, what happens when the communication between the WAL sender and the WAL receiver fails?
When configuring streaming replication, we have the option to enable WAL archiving.
This step is actually not mandatory, but is extremely important for robust replication setup, as it is necessary to avoid the main server to recycle old WAL files that have not yet being applied to the slave. If this occurs we will need to recreate the replica from scratch.
When configuring replication with continuous archiving, we are starting from a backup and, to reach the on sync state with the master, we need to apply all the changes hosted in the WAL that happened after the backup. During this process, the standby will first restore all the WAL available in the archive location (done by calling restore_command). The restore_command will fail when we reach the last archived WAL record, so after that, the standby is going to look on the pg_wal directory to see if the change exists there (this is actually made to avoid data loss when the master servers crashes and some changes that have already been moved into the replica and applied there have not yet been archived).
If that fails, and the requested record does not exist there, then it will start communicating with the master through streaming replication.
Whenever streaming replication fails, it will go back to step 1 and restore the records from archive again. This loop of retrieving from the archive, pg_wal, and via streaming replication goes on until the server is stopped or failover is triggered by a trigger file.
This will be a diagram of such configuration:
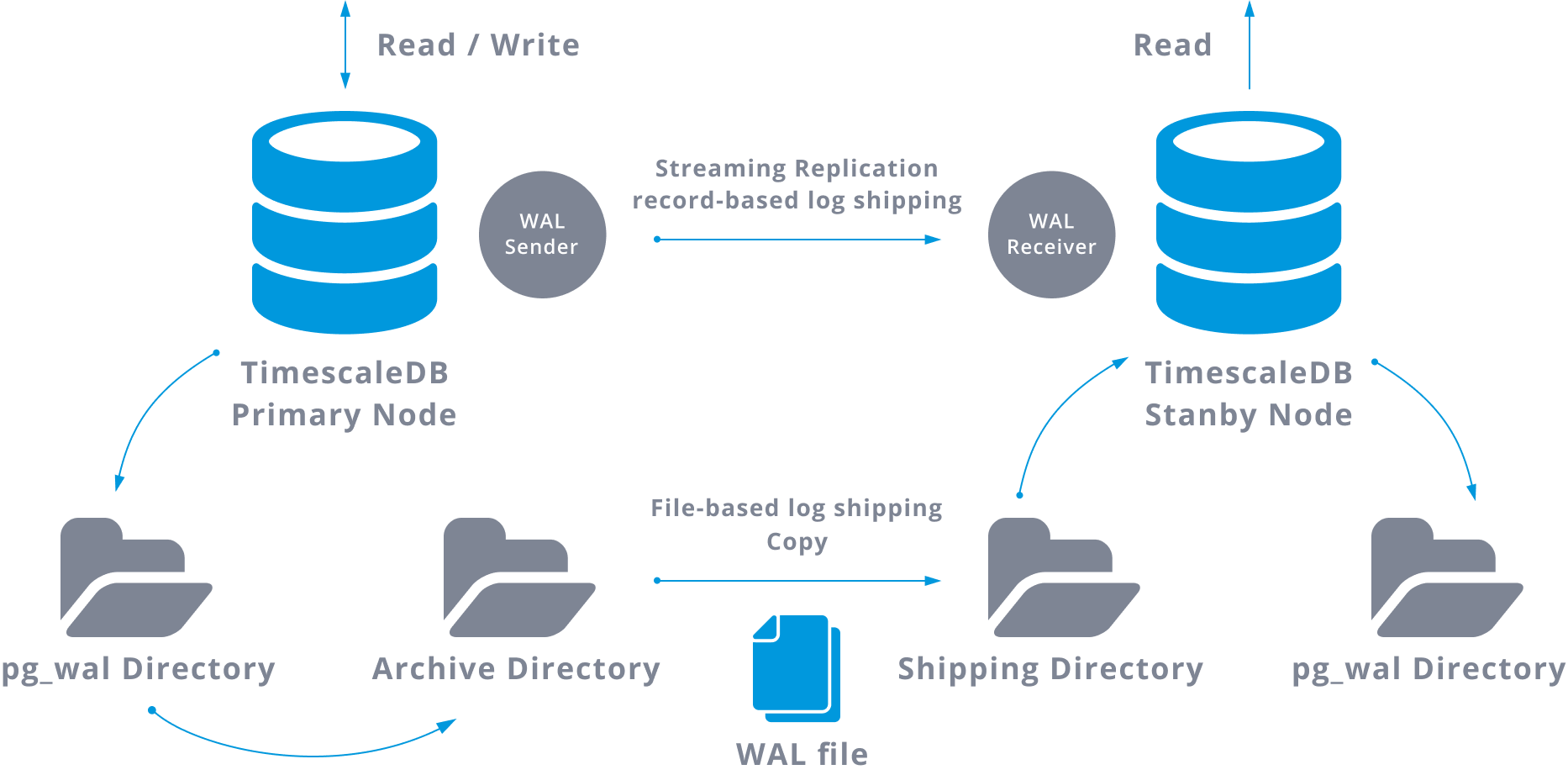
Streaming replication is asynchronous by default, so at some given moment we can have some transactions that can be committed in the master and not yet replicated into the standby server. This implies some potential data loss.
However, this delay between the commit and impact of the changes in the replica is supposed to be really small (some milliseconds), assuming of course that the replica server is powerful enough to keep up with the load.
For the cases when even the risk of a small data loss is not tolerable, we can use the synchronous replication feature.
In synchronous replication, each commit of a write transaction will wait until confirmation is received that the commit has been written to the write-ahead log on disk of both the primary and standby server.
This method minimizes the possibility of data loss, as for that to happen we will need for both the master and the standby to fail at the same time.
The obvious downside of this configuration is that the response time for each write transaction increases, as we need to wait until all parties have responded. So the time for a commit is, at minimum, the round trip between the master and the replica. Read-only transactions will not be affected by that.
To setup synchronous replication we need for each of the standby servers to specify an application_name in the primary_conninfo of the recovery.conf file: primary_conninfo = ‘…aplication_name=slaveX’ .
We also need to specify the list of the standby servers that are going to take part in the synchronous replication: synchronous_standby_name = ‘slaveX,slaveY’.
We can setup one or several synchronous servers, and this parameter also specifies which method (FIRST and ANY) to choose synchronous standbys from the listed ones.
To deploy TimescaleDB with streaming replication setups (synchronous or asynchronous), we can use ClusterControl, as we can see here.
After we have configured our replication, and it is up and running, we will need to have some additional features for monitoring and backup management. ClusterControl allows us to monitor and manage backups/retention of our TimescaleDB cluster from the same place without any external tool.
How to Configure Streaming Replication on TimescaleDB
Setting up streaming replication is a task that requires some steps to be followed thoroughly. If you want to configure it manually, you can follow our blog about this topic.
However, you can deploy or import your current TimescaleDB on ClusterControl, and then, you can configure streaming replication with a few clicks. Let’s see how can we do it.
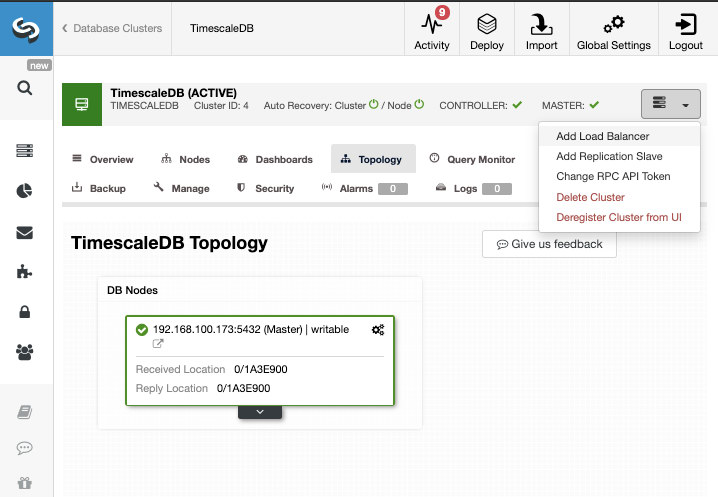
For this task, we’ll assume you have your TimescaleDB cluster managed by ClusterControl. Go to ClusterControl -> Select Cluster -> Cluster Actions -> Add Replication Slave.
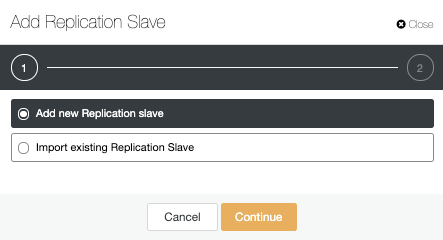
We can create a new replication slave (standby) or we can import an existing one. In this case, we’ll create a new one.
Now, we must select the Master node, add the IP Address or hostname for the new standby server, and the database port. We can also specify if we want ClusterControl to install the software and if we want to configure synchronous or asynchronous streaming replication.
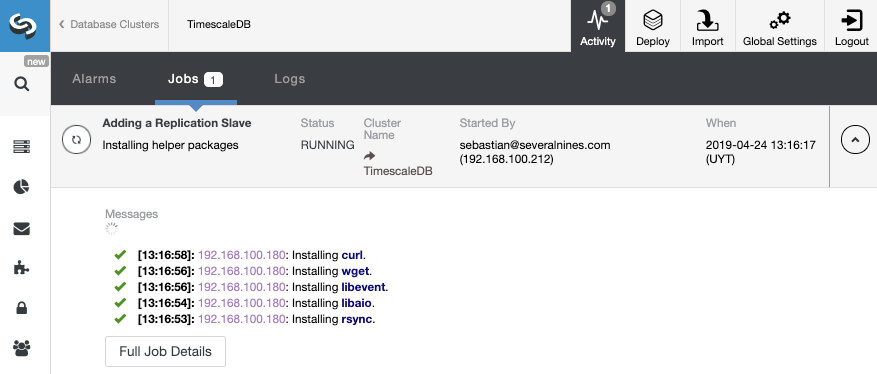
That’s all. We only need to wait until ClusterControl finishes the job. We can monitor the status from the Activity section.
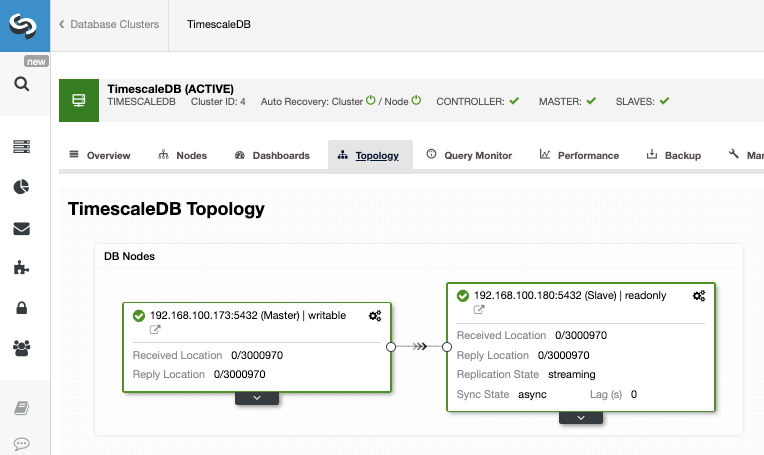
After the job has finished, we should have the streaming replication configured and we can check the new topology in the ClusterControl Topology View section.
By using ClusterControl, you can also perform several management tasks on your TimescaleDB like backup, monitor and alert, automatic failover, add nodes, add load balancers, and even more.
Failover
As we could see, TimescaleDB uses a stream of write-ahead log (WAL) records to keep the standby databases synchronized. If the main server fails, the standby contains almost all of the data of the main server and can be quickly made the new master database server. This can be synchronous or asynchronous and can only be done for the entire database server.
To effectively ensure high availability, it is not enough to have a master-standby architecture. We also need to enable some automatic form of failover, so if something fails we can have the smallest possible delay in resuming normal functionality.
TimescaleDB does not include an automatic failover mechanism to identify failures on the master database and notify the slave to take ownership, so that will require a little bit of work on the DBA’s side. You will also have only one server working, so re-creation of the master-standby architecture needs to be done, so we get back to the same normal situation that we had before the issue.
ClusterControl includes an automatic failover feature for TimescaleDB to improve mean time to repair (MTTR) in your high availability environment. In case of failure, ClusterControl will promote the most advanced slave to master, and it’ll reconfigure the remaining slave(s) to connect to the new master. HAProxy can also be automatically deployed in order to offer a single database endpoint to applications, so they are not impacted by a change of the master server.
Limitations
We have some well-known limitations when using Streaming Replication:
- We cannot replicate into a different version or architecture
- We cannot change anything on the standby server
- We do not have much granularity on what we can replicate
So, to overcome these limitations, we have the logical replication feature. To know more about this replication type, you can check the following blog.
Conclusion
A master-standby topology has many different usages like analytics, backup, high availability, failover. In any case, it’s necessary to understand how the streaming replication works on TimescaleDB. It’s also useful to have a system to manage all the cluster and to give you the possibility to create this topology in an easy way. In this blog, we saw how to achieve it by using ClusterControl, and we reviewed some basic concepts about streaming replication.



