blog
Multi-Cloud Full Database Cluster Failover Options for PostgreSQL

Failover is the ability of a system to continue working even if some failure occurs. It suggests that the functions of the system are assumed by secondary components if the primary components fail or if it is needed. So, if you translate it to a PostgreSQL multi-cloud environment, it means that when your primary node fails (or another reason as we will mention in the next section) in your primary cloud provider, you must be able to promote the standby node in the secondary one to keep the systems running.
In general, all cloud providers give you a failover option in the same cloud provider, but it could be possible you need to failover to another different cloud provider. Of course, you can do it manually, but you can also use some of the ClusterControl features like auto-failover or promote slave action to make this in a friendly and easy way.
In this blog, you will see why you should need failover, how to do it manually, and how to use ClusterControl for this task. We will assume you have a ClusterControl installation running and have already your database cluster created in two different cloud providers.
What is Failover Used For?
There are several possible uses of failover.
Master Failure
If your primary node is down or even if your main Cloud Provider has some issues, you must failover to ensure your system availability. In this case, having an automatic way to do this could be necessary to decrease the downtime.
Migration
If you want to migrate your systems from one Cloud Provider to another one by minimizing your downtime, you can use failover. You can create a replica in the secondary Cloud Provider, and once it is synchronized, you must stop your system, promote your replica and failover, before you point your system to the new primary node in the secondary Cloud Provider.
Maintenance
If you need to perform any maintenance task on your PostgreSQL primary node, you can promote your replica, perform the task, and rebuild your old primary as a standby node.
After this, you can promote the old primary, and repeat the rebuild process on the standby node, returning to the initial state.
In this way, you could work on your server, without running the risk of being offline or losing information while performing any maintenance task.
Upgrades
It is possible to upgrade your PostgreSQL version (since PostgreSQL 10) or even upgrade your Operating System using logical replication with zero downtime, as it can be done with other engines.
The steps would be the same as to migrate to a new Cloud Provider, only that your replica would be in a newer PostgreSQL or OS version and you need to use logical replication as you can’t use streaming replication between different versions.
Failover is not just about the database, but also the application. How do they know which database to connect to? You probably don’t want to have to modify your application, as this will only extend your downtime, so, you can configure a Load Balancer that when your primary node is down, it will automatically point to the server that was promoted.
Having a single Load Balancer instance is not the best option as it can become a single point of failure. Therefore, you can also implement failover for the Load Balancer, using a service such as Keepalived. In this way, if you have a problem with your primary Load Balancer, Keepalived will migrate the Virtual IP to your secondary Load Balancer, and everything continues working transparently.
Another option is the use of DNS. By promoting the standby node in the secondary Cloud Provider, you directly modify the hostname IP address that points to the primary node. In this way, you avoid having to modify your application, and although it can’t be done automatically, it is an alternative if you don’t want to implement a Load Balancer.
How to Failover PostgreSQL Manually
Before performing a manual failover, you must check the replication status. It could be possible that, when you need to failover, the standby node is not up-to-date, due to a network failure, high load, or another issue, so you need to make sure your standby node has all (or almost all) the information. If you have more than one standby node, you should also check which one is the most advanced node and choose it to failover.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)When you choose the new primary node, first, you can run the pg_lsclusters command to get the cluster information:
$ pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
12 main 5432 online,recovery postgres /var/lib/postgresql/12/main log/postgresql-%Y-%m-%d_%H%M%S.logThen, you just need to run the pg_ctlcluster command with the promote action:
$ pg_ctlcluster 12 main promoteInstead of the previous command, you can run the pg_ctl command in this way:
$ /usr/lib/postgresql/12/bin/pg_ctl promote -D /var/lib/postgresql/12/main/
waiting for server to promote.... done
server promotedThen, your standby node will be promoted to primary, and you can validate it by running the following query in your new primary node:
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)If the result is “f”, it is your new primary node.
Now, you must change the primary database IP address in your application, Load Balancer, DNS, or the implementation that you’re using which, as we mentioned, changing this manually will increase the downtime. You need also to make sure your connectivity between the could providers is working properly, the application can access the new primary node, the application user has privileges to access it from a different cloud provider, and you should rebuild the standby node(s) in the remote or even in the local cloud provider, to replicate from the new primary, otherwise, you won’t have a new failover option if needed.
How to Failover PostgreSQL Using ClusterControl
ClusterControl has a number of features related to PostgreSQL replication and automated failover. We will assume you have your ClusterControl server installed and it is managing your Multi-Cloud PostgreSQL environment.
With ClusterControl, you can add as many standby nodes or Load Balancer nodes as you need without any network IP restriction. It means that it is not necessary that the standby node is in the same primary node network or even in the same cloud provider. In terms of failover, ClusterControl allows you to do it manually or automatically.
Manual Failover
To perform a manual failover, go to ClusterControl -> Select Cluster -> Nodes, and in the Node Actions of one of your standby nodes, select “Promote Slave”.
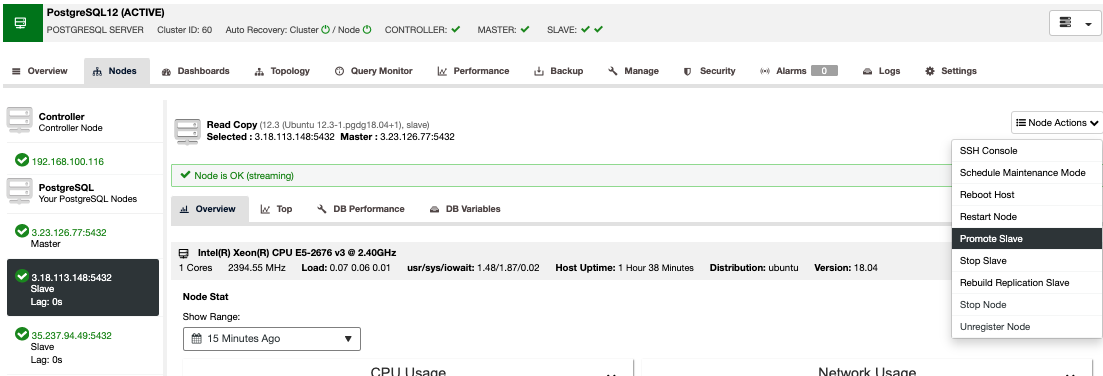
In this way, after a few seconds, your standby node becomes primary, and what was your primary previously, is turned to a standby one. So, if your replica was in another cloud provider, your new primary node will be there, up and running.
Automatic Failover
In the case of automatic failover, ClusterControl detects failures in the primary node and promotes a standby node with the most current data as the new primary. It also works on the rest of the standby nodes to have them replicate from this new primary.
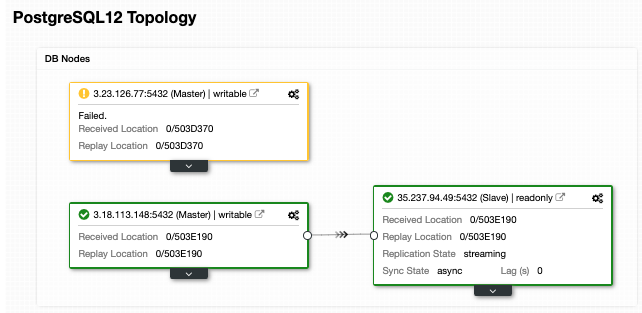
Having the “Autorecovery” option ON, ClusterControl will perform an automatic failover as well as notify you of the problem. In this way, your systems can recover in seconds, and without your intervention.
ClusterControl offers you the possibility to configure a whitelist/blacklist to define how you want your servers to be taken (or not to be taken) into account when deciding on a primary candidate.
ClusterControl also performs several checks over the failover process, for example, by default, if you manage to recover your old failed primary node, it will not be reintroduced automatically to the cluster, neither as a primary nor as a standby, you will need to do it manually. This will avoid the possibility of data loss or inconsistency in the case that your standby (that you promoted) was delayed at the time of the failure. You might also want to analyze the issue in detail, but when adding it to your cluster, you would possibly lose diagnostic information.
Load Balancers
As we mentioned earlier, the Load Balancer is an important tool to consider for your failover, especially if you want to use automatic failover in your database topology.
In order for the failover to be transparent for both the user and the application, you need a component in-between, since it is not enough to promote a new primary node. For this, you can use HAProxy + Keepalived.
To implement this solution with ClusterControl go to the Cluster Actions -> Add Load Balancer -> HAProxy on your PostgreSQL cluster. In the case that you want to implement failover for your Load Balancer, you must configure at least two HAProxy instances, and then, you can configure Keepalived (Cluster Actions -> Add Load Balancer -> Keepalived). You can find more information about this implementation in this blog post.
After this, you will have the following topology:
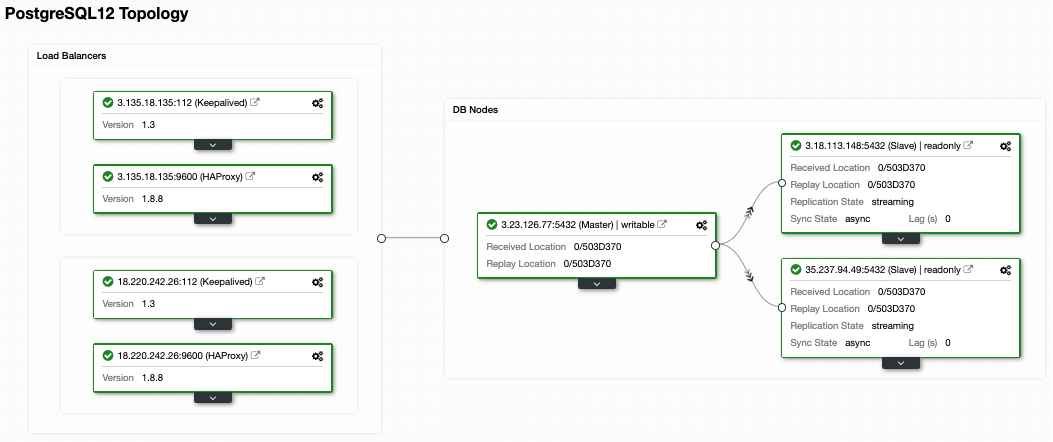
HAProxy is configured by default with two different ports, one read-write and one read-only.
In the read-write port, you have your primary node as online and the rest of the nodes as offline. In the read-only port, you have both the primary and the standby nodes online. In this way, you can balance the reading traffic between the nodes. When writing, the read-write port will be used, which will point to the current primary node.
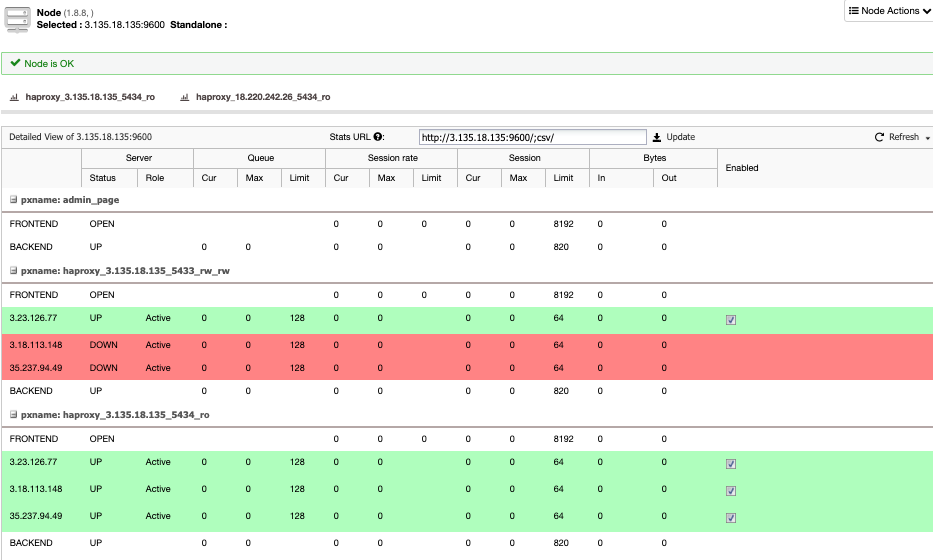
When HAProxy detects that one of the nodes, either primary or standby, is not accessible, it automatically marks it as offline. HAProxy will not send any traffic to it. This check is done by health check scripts that are configured by ClusterControl at the time of deployment. These check whether the instances are up, whether they are undergoing recovery, or are read-only.
When ClusterControl promotes a new primary node, HAProxy marks the old one as offline (for both ports) and puts the promoted node online in the read-write port. In this way, your systems continue to operate normally.
If the active HAProxy (which has assigned a Virtual IP address to which your systems connect) fails, Keepalived migrates this Virtual IP to the passive HAProxy automatically. This means that your systems are then able to continue to function normally.
Cluster-to-Cluster Replication in the Cloud
To have a Multi-Cloud environment, you can use the ClusterControl Add Slave action over your PostgreSQL cluster, but also the Cluster-to-Cluster Replication feature. At the moment, this feature has a limitation for PostgreSQL that allows you to have only one remote node, but we are working to remove that limitation soon in a future release.
To deploy it, you can check the “Cluster-to-Cluster Replication in the Cloud” section in this blog post.
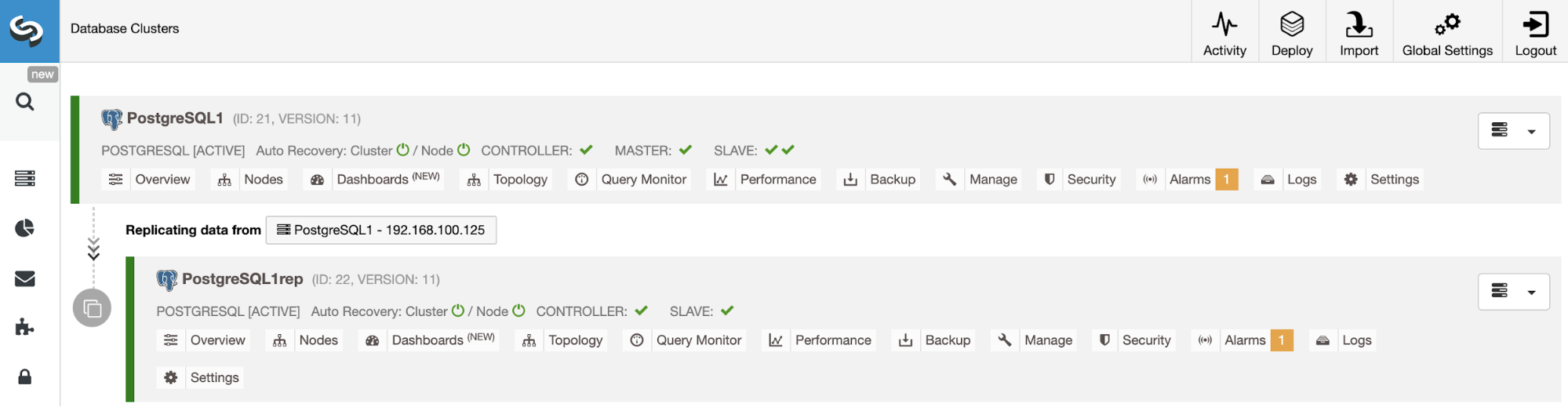
When it is in place, you can promote the remote cluster which will generate an independent PostgreSQL cluster with a primary node running on the secondary cloud provider.
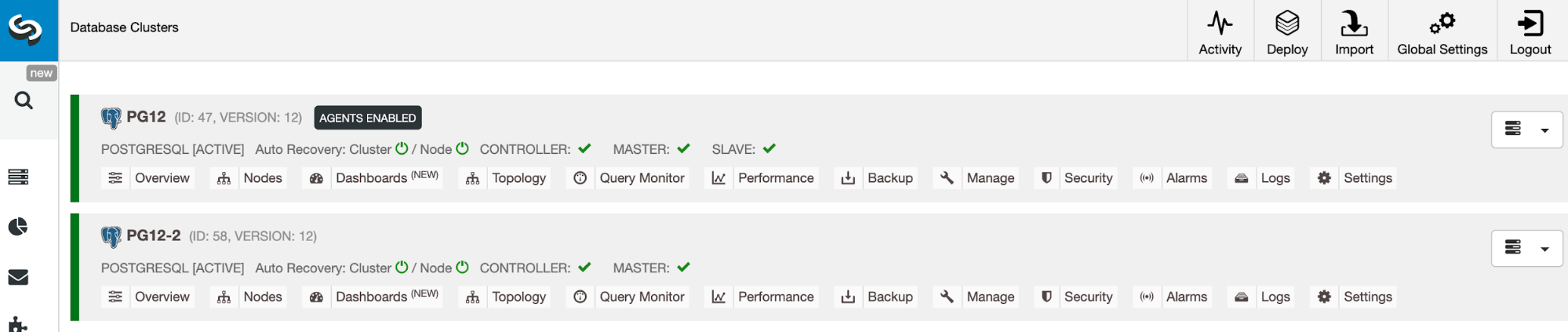
So, in case you need it, you will have the same cluster running in a new cloud provider in just a few seconds.
Conclusion
Having an automatic failover process is mandatory if you want to have less downtime as possible, and also using different technologies like HAProxy and Keepalived will improve this failover.
The ClusterControl features that we mentioned above will allow you to quickly failover between different Cloud Providers and manage the setup in an easy and friendly way.
The most important thing to take into consideration before performing a failover process between different Cloud Providers is the connectivity. You must make sure that your application or your database connections will work as usual using the main but also the secondary cloud provider in case of failover, and, for security reasons, you must restrict the traffic only from known sources, so only between the Cloud Providers and not allow it from any external source.



