blog
How Does a Database Load Balancer Work?

A database Load Balancer is a middleware service that stands between applications and databases. It distributes the workload across multiple database servers running behind it. The goals of having database load balancing are to provide a single database endpoint to applications to connect to, increase queries throughput, minimize latency and maximize resource utilization of the database servers.
In this blog, we will discuss how a database load balancer works, how it fits in a load balanced architecture, and what its advantages are. We will also look briefly at database replication strategies that ensure data consistency across the database servers. While this is not strictly related to the load balancer, consistent data across database servers is usually a prerequisite for including them in a load balancing set.
Load Balanced Architecture
Database load balancers sit between applications and database servers. They accept traffic from applications, and distribute the traffic to databases as shown below:
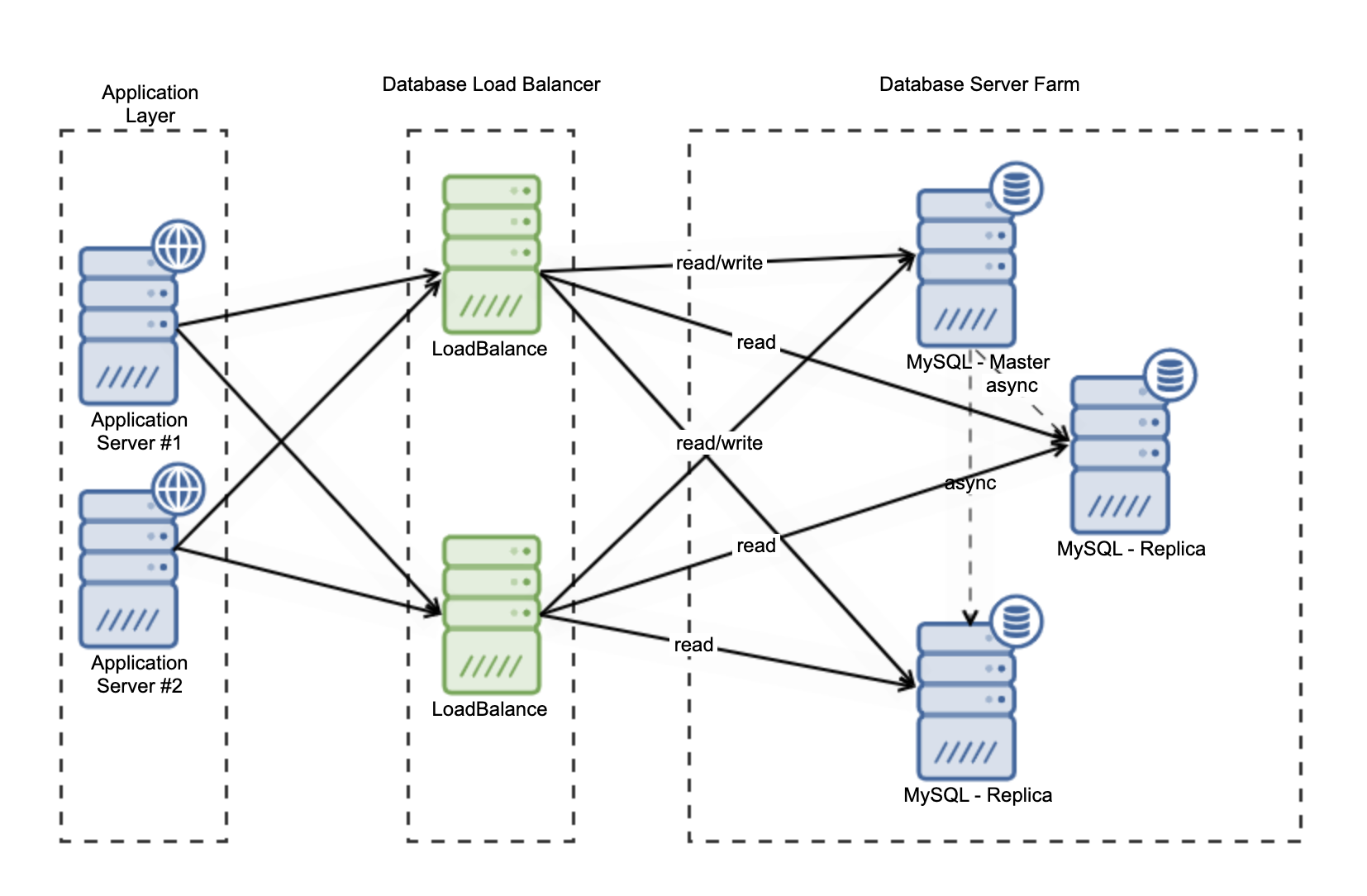
There are two categories of database load balancers that work based on interconnection models; for load balancing that works on TCP/UDP layer (transport layer in OSI model), the communication happens on an intermediate level between application and Internet Protocol (IP). TCP load balancing provides error check streams of packets. A unique TCP port will be assigned to the application to make the delivery correct and provide the health check. A great example of a layer 4 load balancer is HAProxy. You need to define two ports if you want to split write/read queries traffic.
A layer 7 load balancer sits on the application layer, it gives you more features from a database perspective, e.g., database connection pooling, query caching, read-write splitting. It depends what database load balancer you use too. For example; ProxySQL has capabilities for connection pooling, query cache, connection multiplexing. Another database load balancer that sits on layer 7 is pgbouncer, which has similar capabilities to ProxySQL.
Load Balancer Algorithms
There are a few load balancing algorithms you can choose from, based on how you would like your traffic to be distributed. Typical algorithms are:
Round Robin
This is perhaps the simplest type of load balancing. It forwards the requests to each database server, one after the other. All database nodes behind the load balancer will get an equal amount of requests.
Weight-based Load Balancing
With this algorithm, each database server is pre-assigned a weight, which is the proportion of traffic that it can handle relative to the other servers. The reason to use weight based load balancing is when for instance some servers have more capacity than others, and therefore can handle more requests.
Least Connection
The least connection algorithm selects the database server with the fewest active connections. In circumstances where the requests are similar in nature, it can provide the best performance.
Advantage Using Database Load Balancing
There are advantages to using a load balancer in front of your database servers, these include:
- Single database endpoint for applications – This is important in distributed setups where there are multiple database instances. Applications should not need to be aware of the database topology, whether the master role has moved from one server to another, whether new database instances have been introduced, and so on.
- Redundancy – Load balancers are typically running health checks on the backend database servers, to ensure they are up and running and are able to serve traffic. Malfunctioning servers are blacklisted, so traffic is not forwarded to these. This ensures that database requests are always forwarded to healthy database servers.
- Scalability – A load balancer enables your applications to send traffic to multiple database servers, and allows the infrastructure to scale. More servers can be added as traffic grows.
- Zero downtime – Having a load balancer hides non functioning databases. Servers can be removed from traffic for maintenance, without impacting applications. So in many cases, application downtime can be avoided.
Load balancing has a prerequisite – that the database servers are somewhat synchronized, and have the same data. Because it would not be great if every database would answer differently to the same query. So let’s look briefly at the different ways of keeping the databases synchronized.
Database Replication Method
The common replication methods for databases like MySQL, MariaDB or PostgreSQL are:
Asynchronous Replication
The primary database node that gets the update will give confirmation to the application after the data received and written into the database. After that, the data will be replicated to the replicas (or secondaries, or slaves). In this scenario, there is a risk that the secondary servers do not yet have the latest updates, i.e., they lag behind.
Synchronous Replication
Using this replication method, after the primary database node gets the write request from the application, it will ensure all the database instances that contain that data are updated. It will wait until the acknowledgement by the replicas before confirming the application.
Semi-sync Replication
Using this method, updates to the primary database are sent to the replicas. The replicas only need to confirm that they received the update (and not necessarily applied the update), before the primary can confirm the application.



