blog
Comparing Failover Times for Amazon Aurora, Amazon RDS, and ClusterControl

If your IT infrastructure is running on AWS, you have probably heard about Amazon Relational Database Service (RDS), an easy way to set up, operate, and scale a relational database in the cloud. It provides cost-effective and resizable capacity while automating time-consuming administration tasks such as hardware provisioning, database setup, patching, and backups. There are a number of database engine offerings for RDS like MySQL, MariaDB, PostgreSQL, Microsoft SQL Server and Oracle Server.
ClusterControl 1.7.3 acts similarly to RDS as it supports database cluster deployment, management, monitoring, and scaling on the AWS platform. It also supports a number of other cloud platforms like Google Cloud Platform and Microsoft Azure. ClusterControl understands the database topology and is capable of performing automatic recovery, topology management, and many more advanced features to take control of your database.
In this blog post, we are going to compare automatic failover times for Amazon Aurora, Amazon RDS for MySQL, and a MySQL Replication setup deployed and managed by ClusterControl. The type of failover that we are going to do is slave promotion in case that the master goes down. This is where the most up-to-date slave takes over the master role in the cluster to resume the database service.
Our Failover Test
To measure the failover time, we are going to run a simple MySQL connect-update test, with a loop to count the SQL statement status that connect to a single database endpoint. The script looks like this:
#!/bin/bash
_host='{MYSQL ENDPOINT}'
_user='sbtest'
_pass='password'
_port=3306
j=1
while true
do
echo -n "count $j : "
num=$(od -A n -t d -N 1 /dev/urandom |tr -d ' ')
timeout 1 bash -c "mysql -u${_user} -p${_pass} -h${_host} -P${_port} --connect-timeout=1 --disable-reconnect -A -Bse
"UPDATE sbtest.sbtest1 SET k = $num WHERE id = 1" > /dev/null 2> /dev/null"
if [ $? -eq 0 ]; then
echo "OK $(date)"
else
echo "Fail ---- $(date)"
fi
j=$(( $j + 1 ))
sleep 1
done
The above Bash script simply connects to a MySQL host and performs an update on a single row with a timeout of 1 second on both Bash and mysql client commands. The timeouts related parameters are required so we can measure the downtime in seconds correctly since mysql client defaults to always reconnect until it reaches the MySQL wait_timeout. We populated a test dataset with the following command beforehand:
$ sysbench
/usr/share/sysbench/oltp_common.lua
--db-driver=mysql
--mysql-host={MYSQL HOST}
--mysql-user=sbtest
--mysql-db=sbtest
--mysql-password=password
--tables=50
--table-size=100000
prepareThe script reports whether the above query succeeded (OK) or failed (Fail). Sample outputs are shown further down.
Failover with Amazon RDS for MySQL
In our test, we use the lowest RDS offering with the following specs:
- MySQL version: 5.7.22
- vCPU: 4
- RAM: 16 GB
- Storage type: Provisioned IOPS (SSD)
- IOPS: 1000
- Storage: 100Gib
- Multi-AZ Replication: Yes
After Amazon RDS provisions your DB instance, you can use any standard MySQL client application or utility to connect to the instance. In the connection string, you specify the DNS address from the DB instance endpoint as the host parameter, and specify the port number from the DB instance endpoint as the port parameter.
According to Amazon RDS documentation page, in the event of a planned or unplanned outage of your DB instance, Amazon RDS automatically switches to a standby replica in another Availability Zone if you have enabled Multi-AZ. The time it takes for the failover to complete depends on the database activity and other conditions at the time the primary DB instance became unavailable. Failover times are typically 60-120 seconds.
To initiate a multi-AZ failover in RDS, we performed a reboot operation with “Reboot with Failover” checked, as shown in the following screenshot:
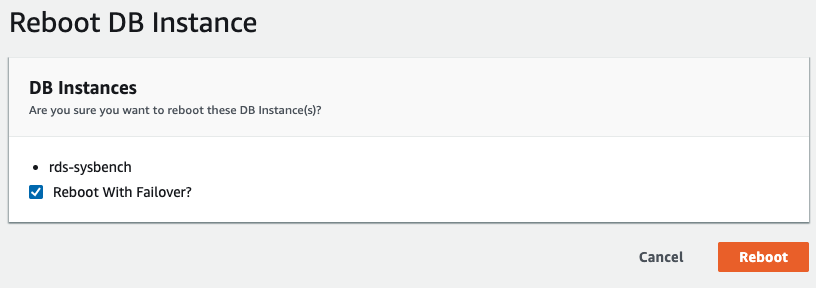
The following is what being observed by our application:
...
count 30 : OK Wed Aug 28 03:41:06 UTC 2019
count 31 : OK Wed Aug 28 03:41:07 UTC 2019
count 32 : Fail ---- Wed Aug 28 03:41:09 UTC 2019
count 33 : Fail ---- Wed Aug 28 03:41:11 UTC 2019
count 34 : Fail ---- Wed Aug 28 03:41:13 UTC 2019
count 35 : Fail ---- Wed Aug 28 03:41:15 UTC 2019
count 36 : Fail ---- Wed Aug 28 03:41:17 UTC 2019
count 37 : Fail ---- Wed Aug 28 03:41:19 UTC 2019
count 38 : Fail ---- Wed Aug 28 03:41:21 UTC 2019
count 39 : Fail ---- Wed Aug 28 03:41:23 UTC 2019
count 40 : Fail ---- Wed Aug 28 03:41:25 UTC 2019
count 41 : Fail ---- Wed Aug 28 03:41:27 UTC 2019
count 42 : Fail ---- Wed Aug 28 03:41:29 UTC 2019
count 43 : Fail ---- Wed Aug 28 03:41:31 UTC 2019
count 44 : Fail ---- Wed Aug 28 03:41:33 UTC 2019
count 45 : Fail ---- Wed Aug 28 03:41:35 UTC 2019
count 46 : OK Wed Aug 28 03:41:36 UTC 2019
count 47 : OK Wed Aug 28 03:41:37 UTC 2019
...The MySQL downtime as seen by the application side was started from 03:41:09 until 03:41:36 which is around 27 seconds in total. From the RDS events, we can see the multi-AZ failover only happened 15 seconds after actual downtime:
Wed, 28 Aug 2019 03:41:24 GMT Multi-AZ instance failover started.
Wed, 28 Aug 2019 03:41:33 GMT DB instance restarted
Wed, 28 Aug 2019 03:41:59 GMT Multi-AZ instance failover completed.Once the new database instance restarted around 03:41:33, the MySQL service was then accessible around 3 seconds later.
Failover with Amazon Aurora for MySQL
Amazon Aurora can be considered as a superior version of RDS, with a lot of notable features like faster replication with shared storage, no data loss during failover, and up to 64TB of a storage limit. Amazon Aurora for MySQL is based on the open source MySQL Edition, but is not open source by itself; it is a proprietary, closed-source database. It works similarly with MySQL replication (one and only one master, with multiple slaves) and failover is automatically handled by Amazon Aurora.
According to Amazon Aurora FAQS, if you have an Amazon Aurora Replica, in the same or a different Availability Zone, when failing over, Aurora flips the canonical name record (CNAME) for your DB Instance to point at the healthy replica, which is in turn is promoted to become the new primary. Start-to-finish, failover typically completes within 30 seconds.
If you do not have an Amazon Aurora Replica (i.e. single instance), Aurora will first attempt to create a new DB Instance in the same Availability Zone as the original instance. If unable to do so, Aurora will attempt to create a new DB Instance in a different Availability Zone. From start to finish, failover typically completes in under 15 minutes.
Your application should retry database connections in the event of connection loss.
After Amazon Aurora provisions your DB instance, you will get two endpoints one for the writer and one for the reader. The reader endpoint provides load-balancing support for read-only connections to the DB cluster. The following endpoints are taken from our test setup:
- writer – aurora-sysbench.cluster-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
- reader – aurora-sysbench.cluster-ro-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
In our test, we used the following Aurora specs:
- Instance type: db.r5.large
- MySQL version: 5.7.12
- vCPU: 2
- RAM: 16 GB
- Multi-AZ Replication: Yes
To trigger a failover, simply pick the writer instance -> Actions -> Failover, as shown in the following screenshot:
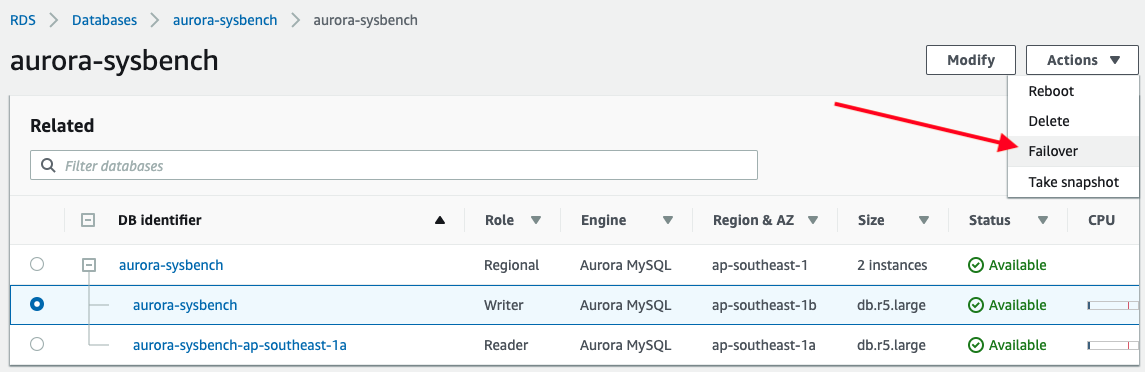
The following output is reported by our application while connecting to the Aurora writer endpoint:
...
count 37 : OK Wed Aug 28 12:35:47 UTC 2019
count 38 : OK Wed Aug 28 12:35:48 UTC 2019
count 39 : Fail ---- Wed Aug 28 12:35:49 UTC 2019
count 40 : Fail ---- Wed Aug 28 12:35:50 UTC 2019
count 41 : Fail ---- Wed Aug 28 12:35:51 UTC 2019
count 42 : Fail ---- Wed Aug 28 12:35:52 UTC 2019
count 43 : Fail ---- Wed Aug 28 12:35:53 UTC 2019
count 44 : Fail ---- Wed Aug 28 12:35:54 UTC 2019
count 45 : Fail ---- Wed Aug 28 12:35:55 UTC 2019
count 46 : OK Wed Aug 28 12:35:56 UTC 2019
count 47 : OK Wed Aug 28 12:35:57 UTC 2019
...The database downtime was started at 12:35:49 until 12:35:56 with total amount of 7 seconds. That’s pretty impressive.
Looking at the database event from Aurora management console, only these two events happened:
Wed, 28 Aug 2019 12:35:50 GMT A new writer was promoted. Restarting database as a reader.
Wed, 28 Aug 2019 12:35:55 GMT DB instance restartedIt doesn’t take much time for Aurora to promote a slave to become a master, and demote the master to become a slave. Note that all Aurora replicas share the same underlying volume with the primary instance and this means that replication can be performed in milliseconds as updates made by the primary instance are instantly available to all Aurora replicas. Therefore, it has minimal replication lag (Amazon claimed to be 100 milliseconds and less). This will greatly reduce the health check time and improve the recovery time significantly.
Failover with ClusterControl
In this example, we imitate a similar setup with Amazon RDS using m5.xlarge instances, with a ProxySQL in between to automate the failover from application using a single endpoint access just like RDS. The following diagram illustrates our architecture:
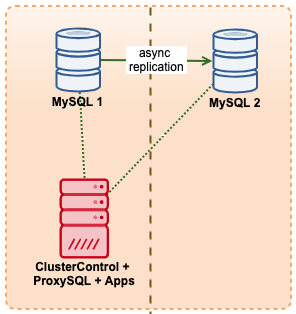
Since we are having direct access to the database instances, we would trigger an automatic failover by simply killing the MySQL process on the active master:
$ kill -9 $(pidof mysqld)The above command triggered an automatic recovery inside ClusterControl:
[11:08:49]: Job Completed.
[11:08:44]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: Failover Complete. New master is 10.15.3.141:3306.
[11:08:39]: Attaching slaves to new master.
[11:08:39]: 10.15.3.141:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.
[11:08:39]: 10.15.3.141:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: 10.15.3.141:3306: Setting read_only=OFF and super_read_only=OFF.
[11:08:38]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:38]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: Stopping slaves.
[11:08:38]: 10.15.3.141:3306: Completed preparations of candidate.
[11:08:38]: 10.15.3.141:3306: Applied 0 transactions. Remaining: .
[11:08:38]: 10.15.3.141:3306: waiting up to 4294967295 seconds before timing out.
[11:08:38]: 10.15.3.141:3306: Checking if the candidate has relay log to apply.
[11:08:38]: 10.15.3.141:3306: preparing candidate.
[11:08:38]: No errant transactions found.
[11:08:38]: 10.15.3.141:3306: Skipping, same as slave 10.15.3.141:3306
[11:08:38]: Checking for errant transactions.
[11:08:37]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Can't connect to MySQL server on '10.15.3.69' (115)
[11:08:37]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Failed to CREATE USER rpl_user. Error: 10.15.3.69:3306: Query failed: Can't connect to MySQL server on '10.15.3.69' (115).
[11:08:36]: 10.15.3.69:3306: Creating user 'rpl_user'@'10.15.3.141.
[11:08:36]: 10.15.3.141:3306: Executing GRANT REPLICATION SLAVE 'rpl_user'@'10.15.3.69'.
[11:08:36]: 10.15.3.141:3306: Creating user 'rpl_user'@'10.15.3.69.
[11:08:36]: 10.15.3.141:3306: Elected as the new Master.
[11:08:36]: 10.15.3.141:3306: Slave lag is 0 seconds.
[11:08:36]: 10.15.3.141:3306 to slave list
[11:08:36]: 10.15.3.141:3306: Checking if slave can be used as a candidate.
[11:08:33]: 10.15.3.69:3306: Trying to shutdown the failed master if it is up.
[11:08:32]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:31]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.141:3306: ioerrno=2003 io running 0
[11:08:30]: Checking 10.15.3.141:3306
[11:08:30]: 10.15.3.69:3306: REPL_UNDEFINED
[11:08:30]: 10.15.3.69:3306
[11:08:30]: Failover to a new Master.
Job spec: Failover to a new Master.While from our test application point-of-view, the downtime happened at the following time while connecting to ProxySQL host port 6033:
...
count 1 : OK Wed Aug 28 11:08:24 UTC 2019
count 2 : OK Wed Aug 28 11:08:25 UTC 2019
count 3 : OK Wed Aug 28 11:08:26 UTC 2019
count 4 : Fail ---- Wed Aug 28 11:08:28 UTC 2019
count 5 : Fail ---- Wed Aug 28 11:08:30 UTC 2019
count 6 : Fail ---- Wed Aug 28 11:08:32 UTC 2019
count 7 : Fail ---- Wed Aug 28 11:08:34 UTC 2019
count 8 : Fail ---- Wed Aug 28 11:08:36 UTC 2019
count 9 : Fail ---- Wed Aug 28 11:08:38 UTC 2019
count 10 : OK Wed Aug 28 11:08:39 UTC 2019
count 11 : OK Wed Aug 28 11:08:40 UTC 2019
...By looking at both the recovery job events and the output from our application, the MySQL database node was down 4 seconds before the cluster recovery job starts, from 11:08:28 until 11:08:39, with total MySQL downtime of 11 seconds. One of the most impressive things about ClusterControl is, you can track the recovery progress on what action being taken and performed by ClusterControl during the failover. It provides a level of transparency that you won’t be able to get with any database offerings by cloud providers.
For MySQL/MariaDB/PostgreSQL replication, ClusterControl allows you to have a more fine-grained against your databases with the support of the following advanced configuration and parameters:
- Master-master replication topology management
- Chain replication topology management
- Topology viewer
- Whitelist/Blacklist slaves to be promoted as master
- Errant transaction checker
- Pre/post, success/fail failover/switchover events hook with external script
- Automatic rebuild slave on error
- Scale out slave from existing backup
Failover Time Summary
In terms of failover time, Amazon RDS Aurora for MySQL is the clear winner with 7 seconds, followed by ClusterControl 11 seconds and Amazon RDS for MySQL with 27 seconds.
Note that this is just a simple test, with one client and one transaction per second to measure the fastest recovery time. Large transactions or a lengthy recovery process can increase failover time e.g, long running transactions may take long time rolling back when shutting down MySQL.



