blog
Using Kubernetes to Deploy PostgreSQL

Kubernetes is an open-source container orchestration system for automating deployment, scaling, and management of containerized applications. Running a PostgreSQL database on Kubernetes is a popular topic of discussion nowadays, as Kubernetes provides ways to provision stateful workloads using persistent volumes, StatefulSets, etc.
This blog will start with a quick overview on why you’d want to deploy PostgreSQL on Kubernetes; after that, introduce you to the top 3 Kubernetes PostgreSQL operators and walk you through the steps to deploy a PostgreSQL cluster on Kubernetes with the Zalando Postgres operator. At the end of this blog, you would have deployed a demo PostgreSQL cluster on Kubernetes.
Before we get started, you will need an active K8s cluster. If you don’t have one, read this Running Galera Cluster on Kubernetes post, which includes steps for installing and configuring one.
Why deploy a PostgreSQL database on Kubernetes?
Traditionally, you deploy databases on virtual machines (VMs), bare metal or mainframe systems. However, with the maturing of Kubernetes and its enhanced support for Persistent Volumes, StatefulSets, and Operators, deploying PostgreSQL on Kubernetes has become a viable and even preferable option. There are several reasons for this.
- Improved disaster recovery: Kubernetes offers built-in disaster recovery features that can be leveraged by PostgreSQL. By utilizing replication across availability zones and regions, PostgreSQL on Kubernetes can achieve high availability and minimize data loss in the event of failures.
- Greater efficiency: Kubernetes allows for resource optimization and automated scaling for PostgreSQL instances. This can lead to improved performance and cost savings compared to running PostgreSQL on VMs.
- Simplified management: With operators simplifying the management of PostgreSQL clusters in Kubernetes environments, you can automate tasks like deployment, scaling, and failover, reducing the burden on your IT staff.
Most potentially interesting however is that Kubernetes offers a standardized infrastructure that can be easily moved between public and private clouds, providing you almost unlimited flexibility in where and how you deploy your database workloads; thereby, avoiding vendor lock-in.
Ways to deploy a PostgreSQL database on Kubernetes?
We can split the ways of deploying a PostgreSQL database on Kubernetes in two — manually or via an operator.
- Manual deployment: In manual deployment, you configure and manage the PostgreSQL database components yourself using Kubernetes primitives like Deployments, Services, and Persistent Volumes. This approach offers maximum flexibility but requires a deep understanding of Kubernetes and PostgreSQL internals. It can be time-consuming and error-prone, especially for complex setups.
-
Operator-based deployment: An operator is a specialized extension that automates the management of a particular service on Kubernetes. Operators simplify the deployment and management of databases on Kubernetes. They can handle tasks such as:
- Deployment: Automatically creates and configures PostgreSQL clusters based on predefined templates.
- Scaling: Dynamically scales the cluster up or down based on workload demands.
- High availability: Automatically promotes replicas in the event of failures.
- Backup and restore: Manages backups and restores of the database.
- Monitoring: Provides insights into the health and performance of the database.
Operators offer a declarative approach to managing Postgres, allowing you to define the desired state of the database that the operator will ensure the actual state matches — this reduces the risk of errors and makes it easier to manage complex PG deployments.
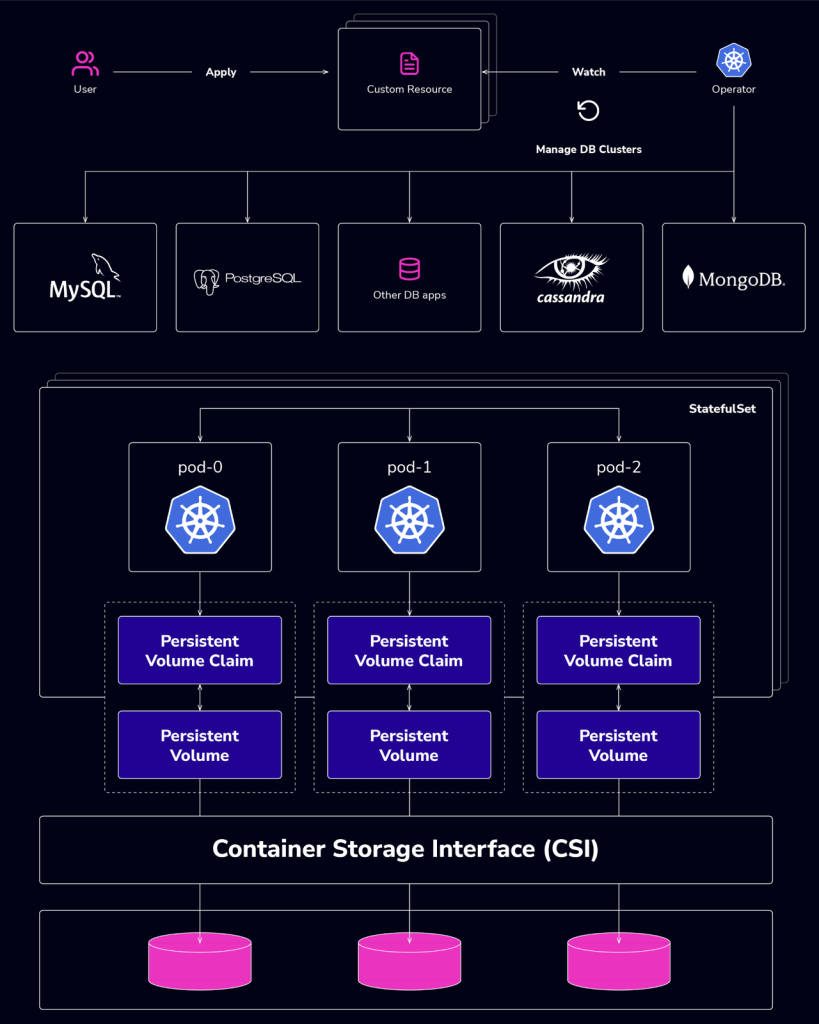
In summary, while manual deployment offers maximum flexibility, operator-based deployment provides a more streamlined and stable experience. The choice between the two depends on your specific needs, team expertise, and the complexity of your PostgreSQL deployment.
Top 3 Kubernetes Operators for PostgreSQL
There are several Kubernetes operators for PostgreSQL, each offering some unique feature set and benefits. The following are the top 3 Kubernetes operators for PostgreSQL. Please note that this list is by no means rank ordered and you should not take it into consideration when deciding.
- Zalando Postgres Operator
The Zalando Postgres Operator is a powerful and flexible operator developed by Zalando, a leading European online fashion retailer. It offers a wide range of features, including automatic backups, failover, and performance optimization.
Zalando uses the operator internally to manage its own PostgreSQL databases, and they also made the operator open-source for the community to use. - Percona Operator for PostgreSQL
The Percona Operator for PostgreSQL is a Kubernetes operator backed by Percona, a well-known database services company.
- CloudNativePG
CloudNativePG is a community-driven operator that offers comprehensive features for deploying and managing PostgreSQL on Kubernetes. It supports various deployment patterns, including single-node, replica clusters, and multi-region replication.
Next, I’ll walk you through PostgreSQL database cluster deployment using Zalando’s Operator.
Deploying a PostgresQL database cluster with the Zalando Postgres Operator
One of the first production- level database operators in the Kubernetes ecosystem, Zalando has used this operator to deploy and manage 500+ PostgreSQL HA clusters since as far back as 2018.
We also use the Zalando Postgres Operator in our CCX architecture. CCX is a multi-line Kubernetes-based DBaaS product that enables organizations to consume or provide DBaaS to their end users.
Prerequisites
To follow along in this demo, you should have the following prerequisites:
- Working Kubernetes Cluster. This demo uses a DigitalOcean cluster, but you can use minikube — a local single node Kubernetes cluster.
- The kubectl command-line tool configured to communicate with the cluster.
- Git installed on your terminal.
- Helm installed on your terminal.
Zalando makes it very easy to quickly get a minimal PostgreSQL cluster up and running with their Github repository. The first step for you in this demo is to deploy the operator.
Deploying the Postgres Operator
There are three ways to deploy the Postgres Operator:
- Manual deployment
- Kustomization
- Helm chart
For this quick demo, you will deploy the operator using Helm. In your terminal, add the operator’s helm chart repository with the following command.
helm repo add postgres-operator-charts https://opensource.zalando.com/postgres-operator/charts/postgres-operatorAfter that, install the helm chart on your Kubernetes cluster with the following command:
helm install postgres-operator postgres-operator-charts/postgres-operator To check the installation, run the kubectl get deployments command, and you will see that the operator has been deployed.

Now that you have the operator deployed and running, next is to deploy the demo cluster.
Creating a PostgreSQL cluster
As mentioned earlier, Zalando provides configurations for a minimal cluster, to get them, pull the Github repository with the following command:
git clone https://github.com/zalando/postgres-operator.git
cd postgres-operatorAfter pulling the repository and changing into the directory, you can view the YAML configuration of the cluster in the manifests/minimal-postgres-manifest.yaml directory.
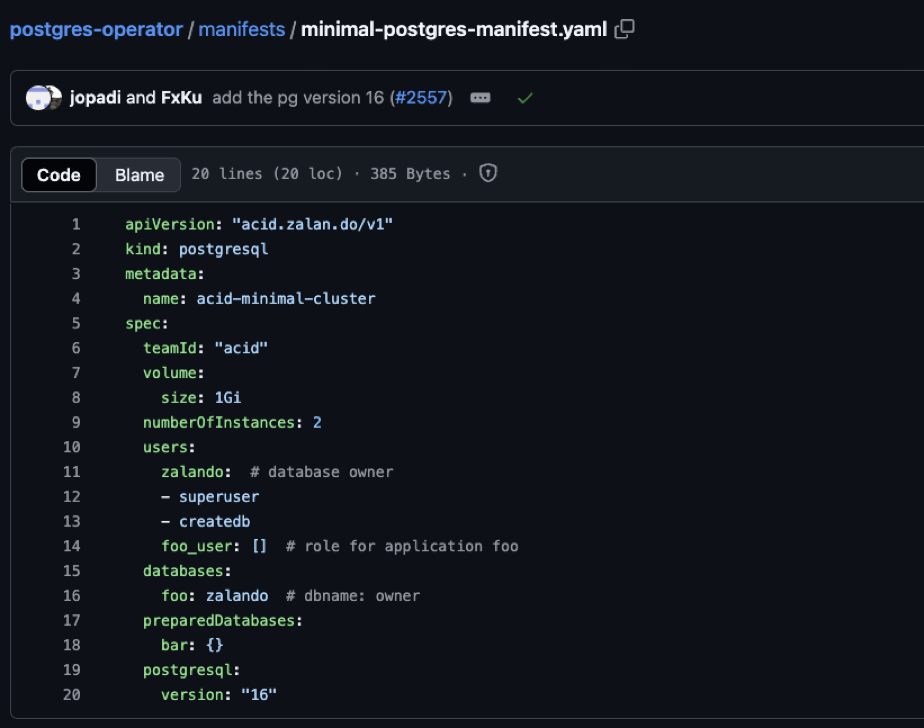
To create the cluster, apply the following command:
kubectl create -f manifests/minimal-postgres-manifest.yaml
After running the above command, the operator will create Service and Endpoint resources and a StatefulSet which spins up new Pod(s) — depending the number of instances specified in the manifest — which is 2 in this case. All resources are named like the cluster name acid-minimal-cluster.
The database pods run the Spilo container image that provides PostgreSQL and Patroni bundled together.
To check if all components are coming up, with the label application=spilo you can filter and list the label spilo-role to see the pods and services created.
kubectl get postgresql
kubectl get pods -l application=spilo -L spilo-role
kubectl get svc -l application=spilo -L spilo-role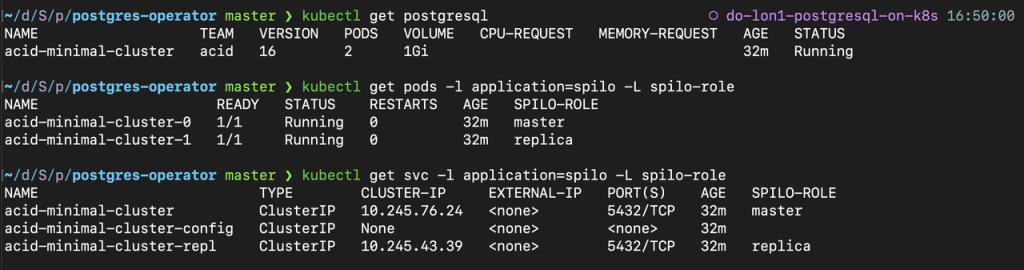
Connecting to the Postgres cluster
To connect to the cluster, you can create a port-forward on pod. Seeing the name of the master pod in this demo is acid-minimal-cluster-0, you can create a port forward with the following command:
kubectl port-forward acid-minimal-cluster-0 6432:5432 -n default
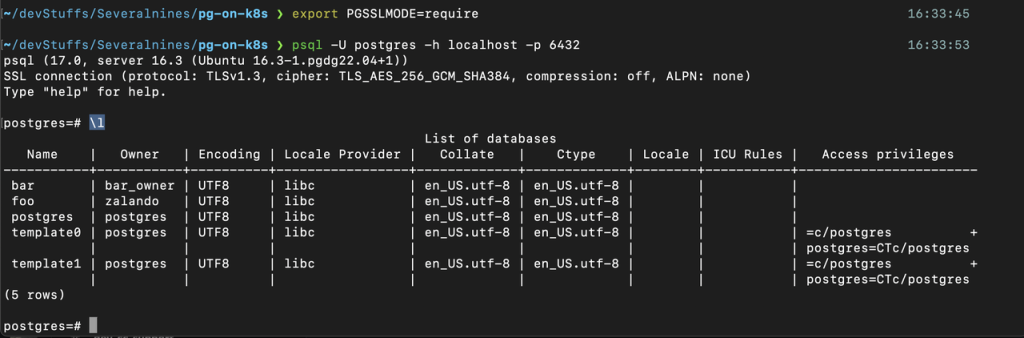
With the port forwarding running, open another CLI and connect to the database using psql client. To connect with the demo manifest role foo_user user, with the following commands, read its password from the K8s secret which was generated during cluster creation as non-encrypted connections are rejected by default set SSL mode to require.
export PGPASSWORD=$(kubectl get secret postgres.acid-minimal-cluster.credentials.postgresql.acid.zalan.do -o 'jsonpath={.data.password}' | base64 -d)
export PGSSLMODE=require
psql -U postgres -h localhost -p 6432After running the psql command, and the interactive shell opens, you can test by running \l to list all the default databases in the cluster as in the image below.
Deleting a PostgreSQL cluster
To delete the cluster, delete the postgresql custom resource.
kubectl delete postgresql acid-minimal-clusterThe above command would remove the associated StatefulSet, database Pods, Services and Endpoints. The PersistentVolumes are released and the PodDisruptionBudget is deleted. Secrets however are not deleted and backups will remain in place. To delete them, you would have to manually do so with the kubectl delete command.
Wrapping up
This article provided a quick overview on why you’d want to deploy PostgreSQL on Kubernetes, introduced you to the top 3 Kubernetes PostgreSQL operators and walked you through the steps to deploy a PostgreSQL cluster on Kubernetes with the Zalando Postgres operator.
Running PostgreSQL on Kubernetes can offer immense benefits from improved scalability and portability to disaster recovery. Though running databases on Kubernetes has matured over the years, a lot of organizations still have valid concerns with the approach. At Severalnines, we brought together the best of both worlds with CCX.
CCX helps organizations to give their end users that optionality over where their data stack is located with the ability to provision high availability databases on VMs (AWS, GCP), VMware, OpenStack infrastructure, etc.
To learn more about CCX, explore our CCX for CSP page, or reach out today to discover how CCX can elevate your business to new heights!
References
- Kubernetes: https://kubernetes.io
- Kubectl setup: https://kubernetes.io/docs/tasks/tools/install-kubectl
- Zalando Postgres Operator quickstart: https://github.com/zalando/postgres-operator/blob/master/docs/quickstart.md



