blog
Scaling PostgreSQL for Large Amounts of Data

Nowadays, it’s common to see a large amount of data in a company’s database, but depending on the size, it could be hard to manage and the performance could be affected during high traffic if we don’t configure or implement it in a correct way. In general, if we have a huge database and we want to have a low response time, we’ll want to scale it. PostgreSQL is not the exception to this point. There are many approaches available to scale PostgreSQL, but first, let’s learn what scaling is.
Scalability is the property of a system/database to handle a growing amount of demands by adding resources.
The reasons for this amount of demands could be temporal, for example, if we’re launching a discount on a sale, or permanent, for an increase of customers or employees. In any case, we should be able to add or remove resources to manage these changes on the demands or increase in traffic.
In this blog, we’ll look at how we can scale our PostgreSQL database and when we need to do it.
Horizontal Scaling vs Vertical Scaling
There are two main ways to scale our database…
- Horizontal Scaling (scale-out): It’s performed by adding more database nodes creating or increasing a database cluster.
- Vertical Scaling (scale-up): It’s performed by adding more hardware resources (CPU, Memory, Disk) to an existing database node.
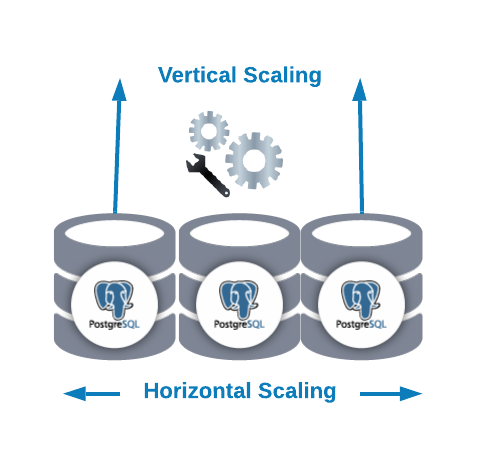
For Horizontal Scaling, we can add more database nodes as slave nodes. It can help us to improve the read performance balancing the traffic between the nodes. In this case, we’ll need to add a load balancer to distribute traffic to the correct node depending on the policy and the node state.
To avoid a single point of failure adding only one load balancer, we should consider adding two or more load balancer nodes and using some tool like “Keepalived”, to ensure the availability.
As PostgreSQL doesn’t have native multi-master support, if we want to implement it to improve the write performance we’ll need to use an external tool for this task.
For Vertical Scaling, it could be needed to change some configuration parameter to allow PostgreSQL to use a new or better hardware resource. Let’s see some of these parameters from the PostgreSQL documentation.
- work_mem: Specifies the amount of memory to be used by internal sort operations and hash tables before writing to temporary disk files. Several running sessions could be doing such operations concurrently, so the total memory used could be many times the value of work_mem.
- maintenance_work_mem: Specifies the maximum amount of memory to be used by maintenance operations, such as VACUUM, CREATE INDEX, and ALTER TABLE ADD FOREIGN KEY. Larger settings might improve performance for vacuuming and for restoring database dumps.
- autovacuum_work_mem: Specifies the maximum amount of memory to be used by each autovacuum worker process.
- autovacuum_max_workers: Specifies the maximum number of autovacuum processes that may be running at any one time.
- max_worker_processes: Sets the maximum number of background processes that the system can support. Specify the limit of the process like vacuuming, checkpoints, and more maintenance jobs.
- max_parallel_workers: Sets the maximum number of workers that the system can support for parallel operations. Parallel workers are taken from the pool of worker processes established by the previous parameter.
- max_parallel_maintenance_workers: Sets the maximum number of parallel workers that can be started by a single utility command. Currently, the only parallel utility command that supports the use of parallel workers is CREATE INDEX, and only when building a B-tree index.
- effective_cache_size: Sets the planner’s assumption about the effective size of the disk cache that is available to a single query. This is factored into estimates of the cost of using an index; a higher value makes it more likely index scans will be used, a lower value makes it more likely sequential scans will be used.
- shared_buffers: Sets the amount of memory the database server uses for shared memory buffers. Settings significantly higher than the minimum are usually needed for good performance.
- temp_buffers: Sets the maximum number of temporary buffers used by each database session. These are session-local buffers used only for access to temporary tables.
- effective_io_concurrency: Sets the number of concurrent disk I/O operations that PostgreSQL expects can be executed simultaneously. Raising this value will increase the number of I/O operations that any individual PostgreSQL session attempts to initiate in parallel. Currently, this setting only affects bitmap heap scans.
- max_connections: Determines the maximum number of concurrent connections to the database server. Increasing this parameter allows PostgreSQL running more backend process simultaneously.
At this point, there is a question that we must ask. How can we know if we need to scale our database and how can we know the best way to do it?
Monitoring
Scaling our PostgreSQL database is a complex process, so we should check some metrics to be able to determine the best strategy to scale it.
We can monitor the CPU, Memory and Disk usage to determine if there is some configuration issue or if actually, we need to scale our database. For example, if we’re seeing a high server load but the database activity is low, it’s probably not needed to scale it, we only need to check the configuration parameters to match it with our hardware resources.
Checking the disk space used by the PostgreSQL node per database can help us to confirm if we need more disk or even a table partitioning. To check the disk space used by a database/table we can use some PostgreSQL function like pg_database_size or pg_table_size.
From the database side, we should check
- Amount of connection
- Running queries
- Index usage
- Bloat
- Replication Lag
These could be clear metrics to confirm if the scaling of our database is needed.
ClusterControl as a Scaling and Monitoring System
ClusterControl can help us to cope with both scaling ways that we saw earlier and to monitor all the necessary metrics to confirm the scaling requirement. Let’s see how…
If you’re not using ClusterControl yet, you can install it and deploy or import your current PostgreSQL database selecting the “Import” option and follow the steps, to take advantage of all the ClusterControl features like backups, automatic failover, alerts, monitoring, and more.
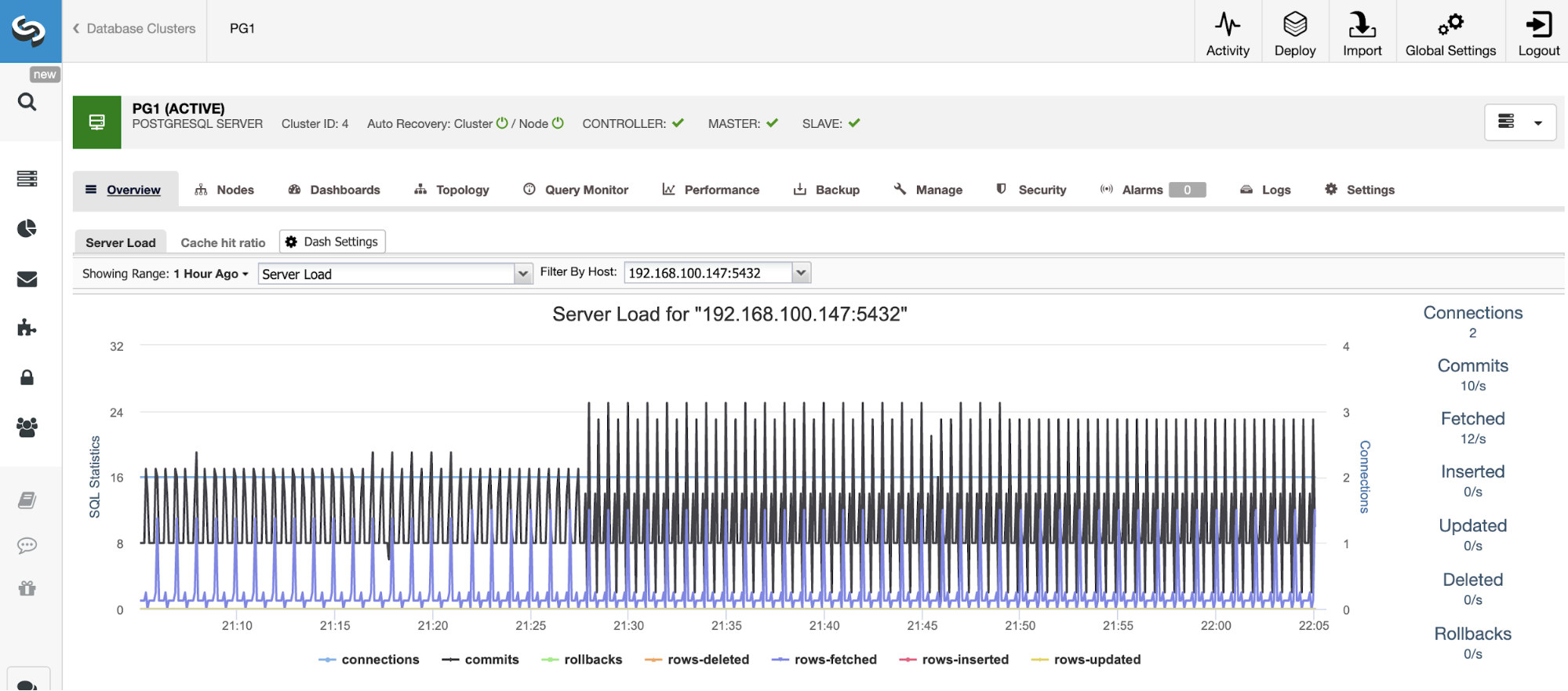
Horizontal Scaling
For horizontal scaling, if we go to cluster actions and select “Add Replication Slave”, we can either create a new replica from scratch or add an existing PostgreSQL database as a replica.
Let’s see how adding a new replication slave can be a really easy task.
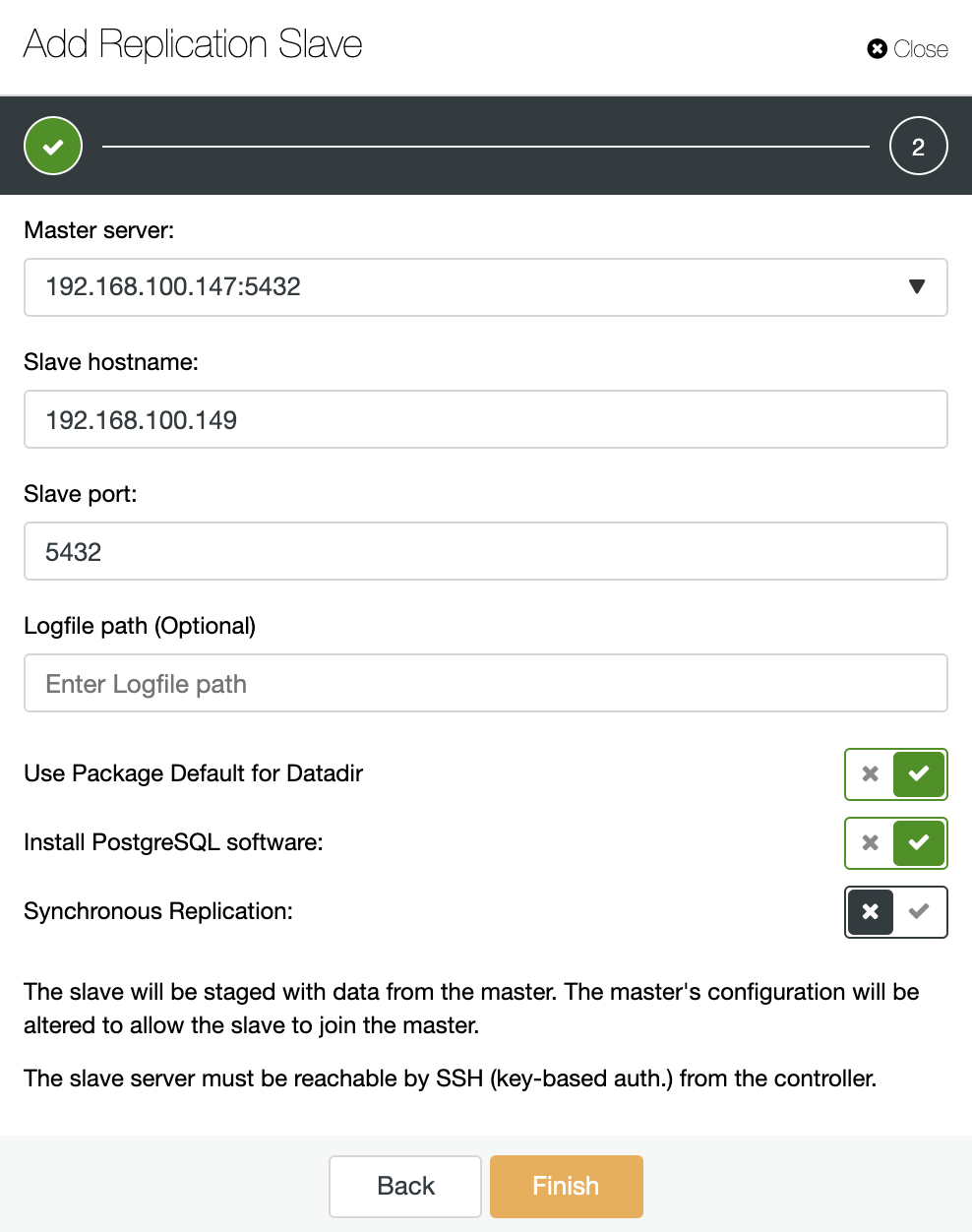
As you can see in the image, we only need to choose our Master server, enter the IP address for our new slave server and the database port. Then, we can choose if we want ClusterControl to install the software for us and if the replication slave should be Synchronous or Asynchronous.
In this way, we can add as many replicas as we want and spread read traffic between them using a load balancer, which we can also implement with ClusterControl.
Now, if we go to cluster actions and select “Add Load Balancer”, we can deploy a new HAProxy Load Balancer or add an existing one.
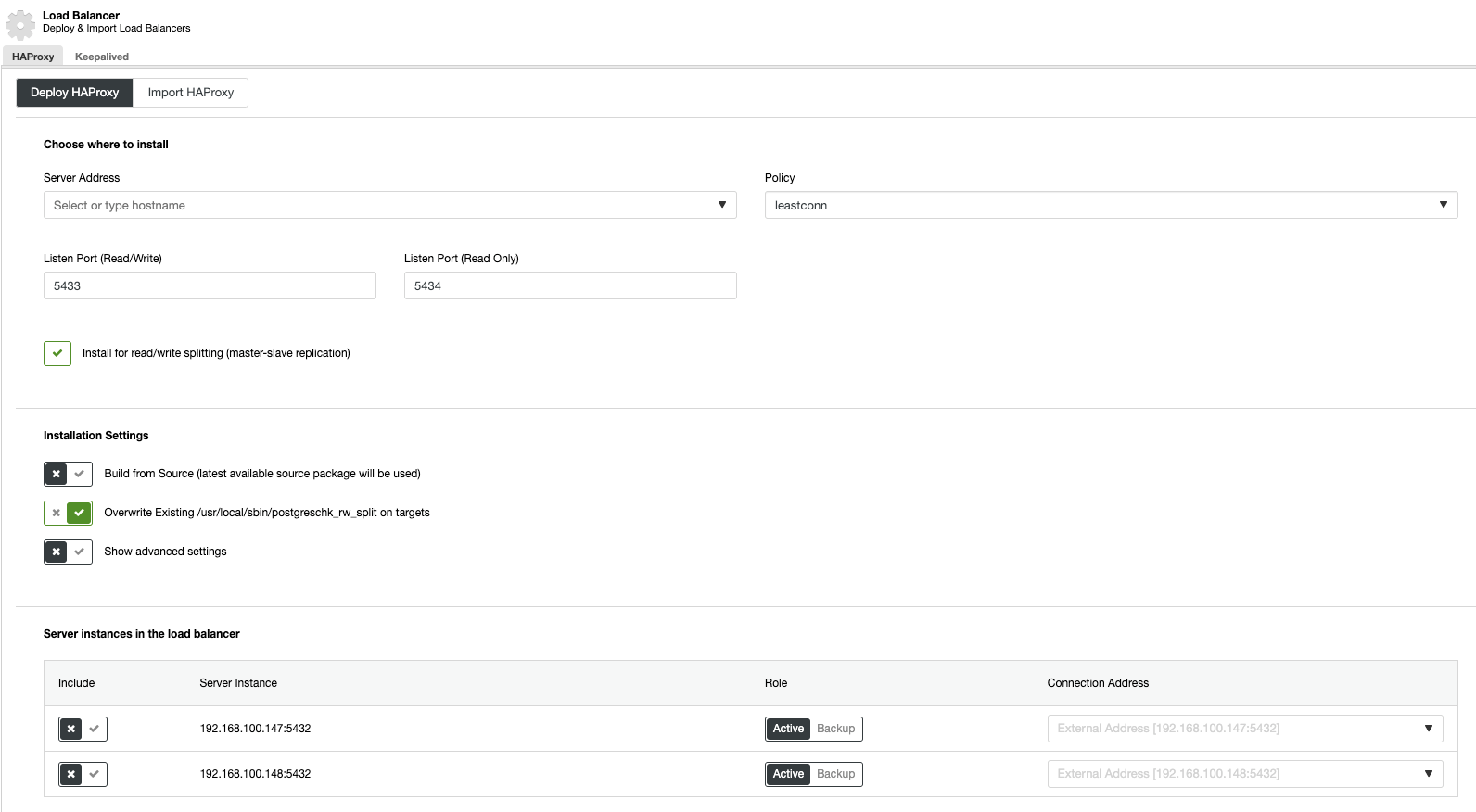
And then, in the same load balancer section, we can add a Keepalived service running on the load balancer nodes for improving our high availability environment.
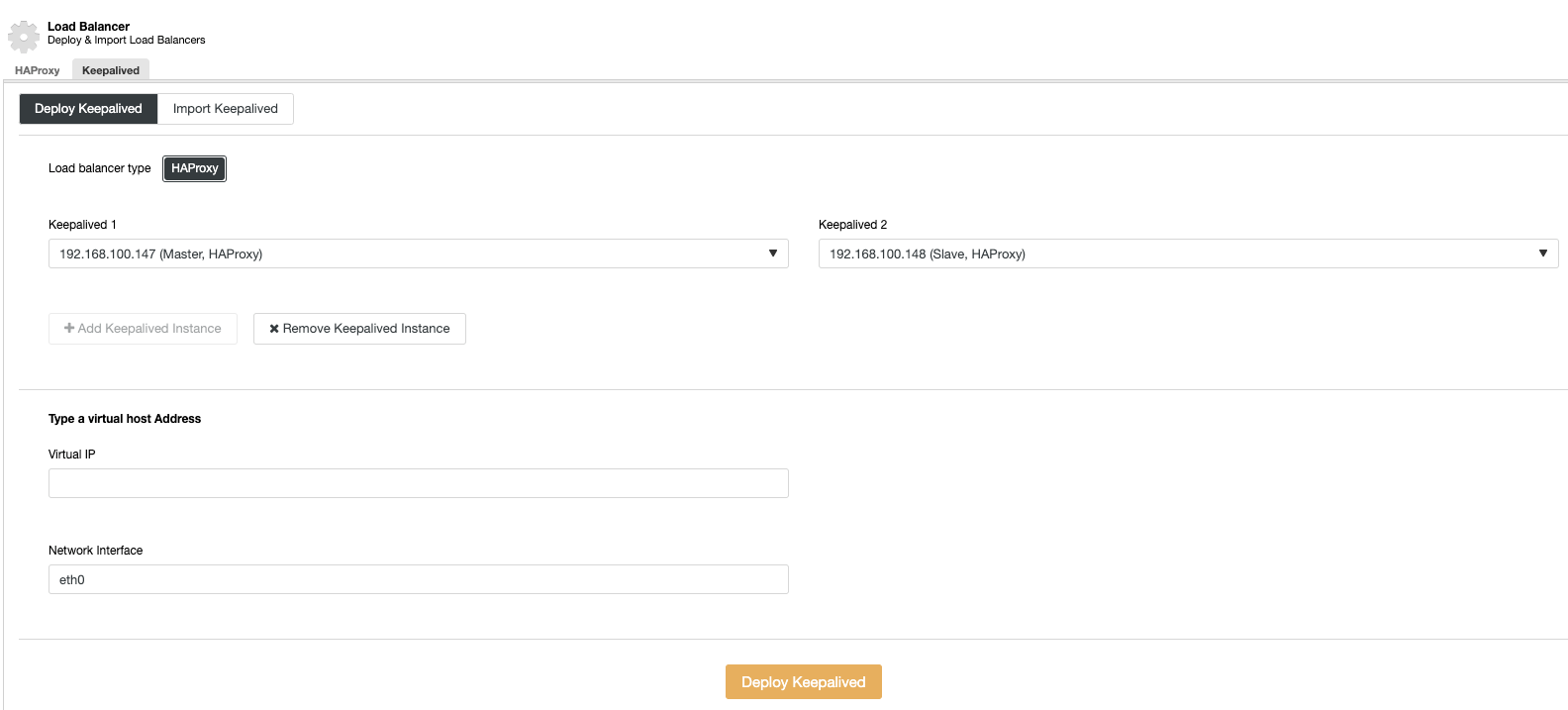
Vertical Scaling
For vertical scaling, with ClusterControl we can monitor our database nodes from both the operating system and the database side. We can check some metrics like CPU usage, Memory, connections, top queries, running queries, and even more. We can also enable the Dashboard section, which allows us to see the metrics in more detailed and in a friendlier way our metrics.
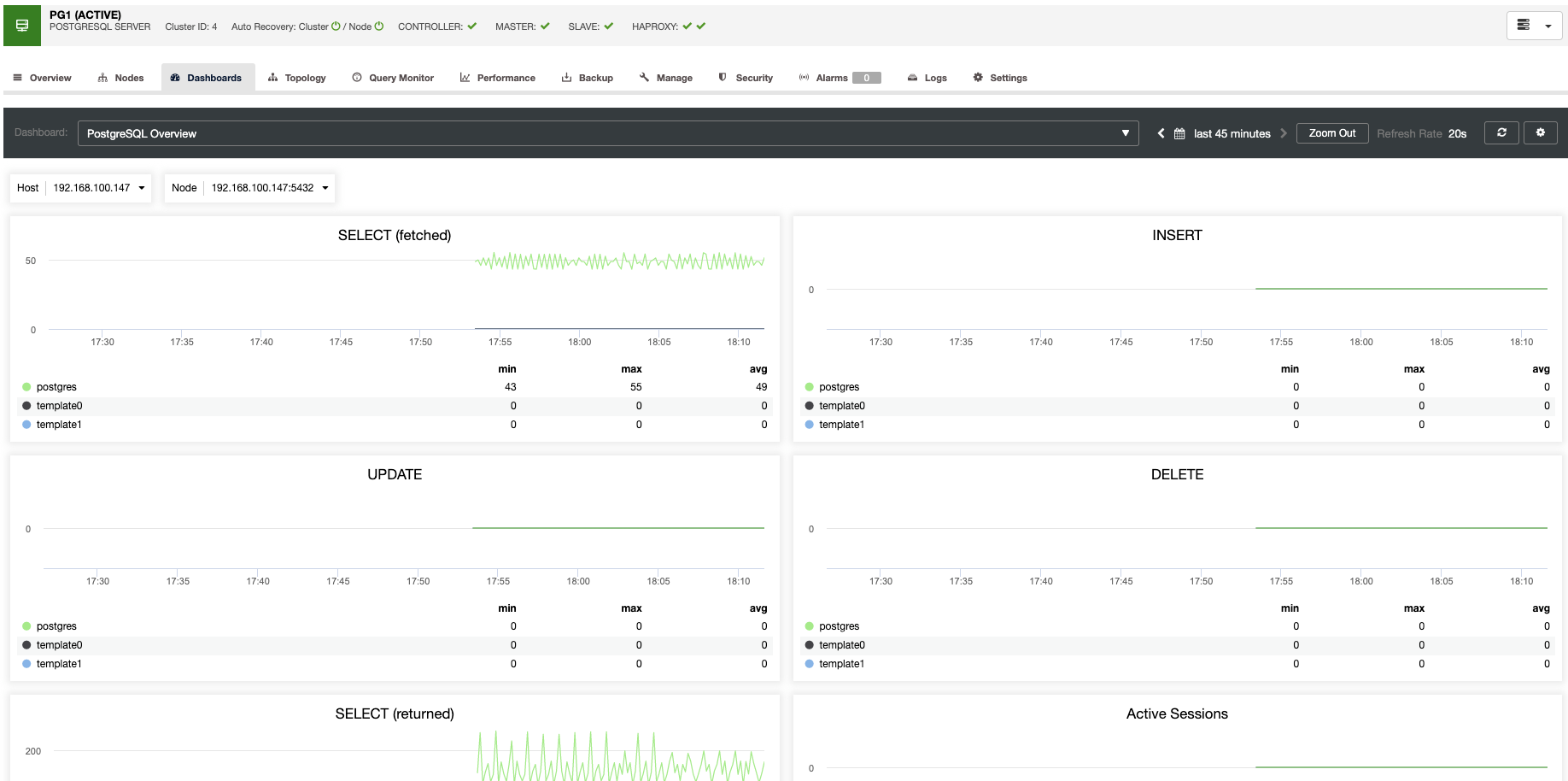
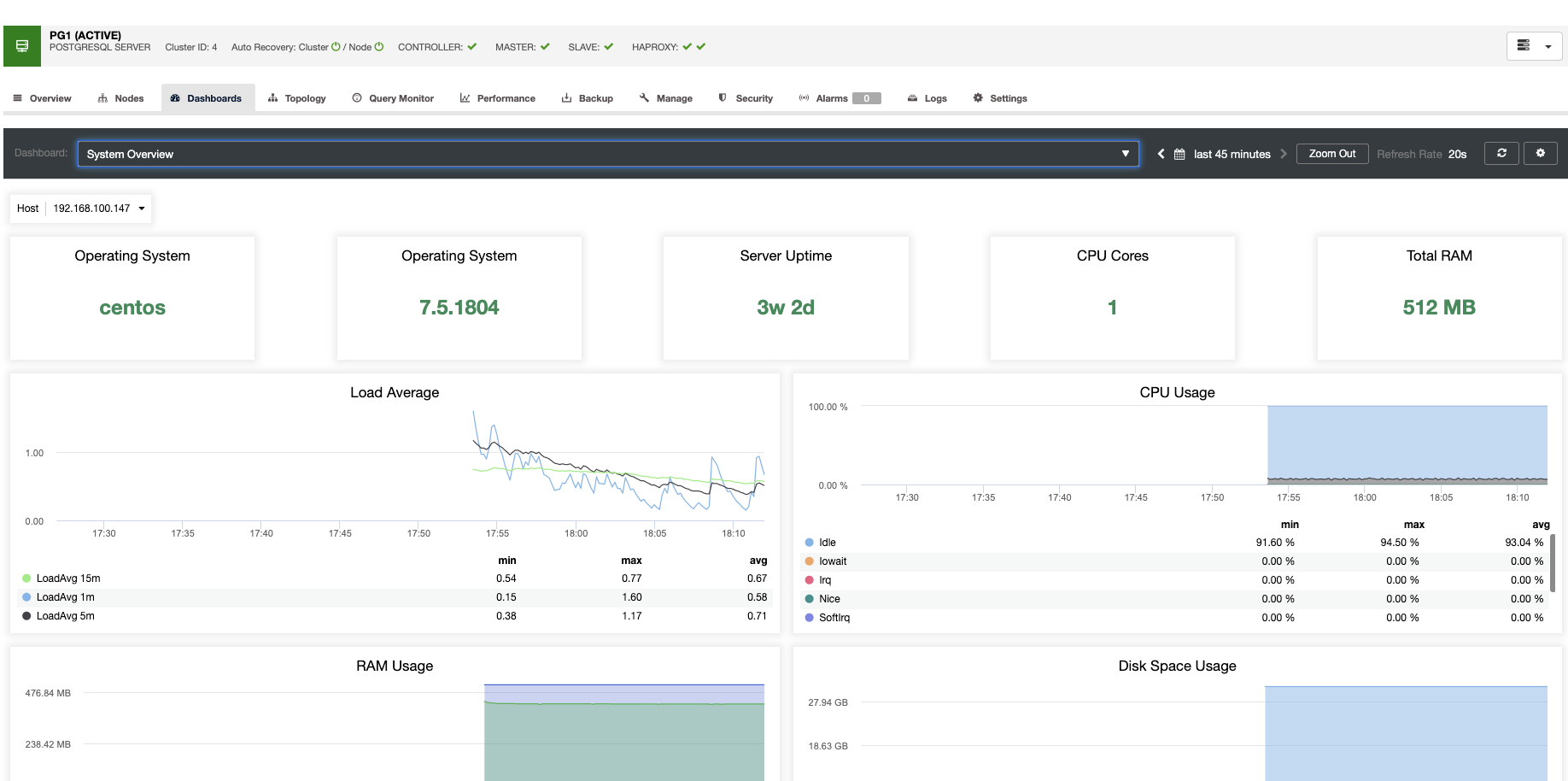
From ClusterControl, you can also perform different management tasks like Reboot Host, Rebuild Replication Slave or Promote Slave, with one click.
Conclusion
Scaling out PostgreSQL databases can be a time consuming task. We need to know what we need to scale and what the best way is to do it. Ultimately, managing and scaling clusters manually becomes quite burdensome past a certain point so most turn to tools like ours.
If you choose the manual route, check out when to consider adding an extra node to your cluster. Want to avoid the hassle? Evaluate ClusterControl for free for 30 days to see how its features make dealing with large-scale, open-source simple and efficient.
However you want to manage and scale your databases, follow us on Twitter or LinkedIn, or subscribe to our newsletter to get the latest news and best practices when managing open-source based database infrastructure, and we’ll see you soon!



